Move jointness censoring to proc_macro
Proc-macro API currently exposes jointness in `Punct` tokens. That is,
`+` in `+one` is **non** joint.
Our lexer produces jointness info for all tokens, so we need to censor
it *somewhere*
Previously we did this in a lexer, but it makes more sense to do this
in a proc-macro server.
r? @petrochenkov
inliner: Check for codegen fn attributes compatibility
* Check for target features compatibility
* Check for no_sanitize attribute compatibility
Fixes#76259.
Fix intra-doc links on pub re-exports
Partial fix for https://github.com/rust-lang/rust/issues/76073 - This removes the incorrect error, but doesn't show the documentation anywhere.
r? @GuillaumeGomez
Remove disambiguators from intra doc link text
Closes https://github.com/rust-lang/rust/issues/65354.
r? @Manishearth
The commits are mostly atomic, but there might be some mix between them here and there. I recommend reading 'refactor ItemLink' and 'refactor RenderedLink' on their own though, lots of churn without any logic changes.
Refactor byteorder to std in rustc_middle
Use std::io::{Read, Write} and {to, from}_{le, be}_bytes methods in
order to remove byteorder from librustc_middle's dependency graph.
Add a regression test for issue-72793
Adds a regression test for #72793, which is fixed by #75443. Note that this won't close the issue as the snippet still shows ICE with `-Zmir-opt-level=2`. But it makes sense to add a test anyway.
do not apply DerefMut on union field
This implements the part of [RFC 2514](https://github.com/rust-lang/rfcs/blob/master/text/2514-union-initialization-and-drop.md) about `DerefMut`. Unlike described in the RFC, we only apply this warning specifically when doing `DerefMut` of a `ManuallyDrop` field; that is really the case we are worried about here.
@matthewjasper suggested I patch `convert_place_derefs_to_mutable` and `convert_place_op_to_mutable` for this, but I could not find anything to do in `convert_place_op_to_mutable` and this is sufficient to make the test pass. However, maybe there are some other cases this misses? I have no familiarity with this code.
This is a breaking change *in theory*, if someone used `ManuallyDrop<T>` in a union field and relied on automatic `DerefMut`. But on stable this means `T: Copy`, so the `ManuallyDrop` is rather pointless.
Cc https://github.com/rust-lang/rust/issues/55149
Upgrade Chalk to 0.21
Two commits here. First commit actually does the upgrade. Second commit has some changes to make more tests in compare-mode=chalk pass.
The `PlaceholdersCollector` and `RegionsSubstitutor` bits are bit a hacky, but only insomuch as `ParamsSubstitutor` is. These won't be needed eventually.
r? @nikomatsakis
BTreeMap: introduce marker::ValMut and reserve Mut for unique access
The mutable BTreeMap iterators (apart from `DrainFilter`) are double-ended, meaning they have to rely on a front and a back handle that each represent a reference into the tree. Reserve a type category `marker::ValMut` for them, so that we guarantee that they cannot reach operations on handles with borrow type `marker::Mut`and that these operations can assume unique access to the tree.
Including #75195, benchmarks report no genuine change:
```
benchcmp old new --threshold 5
name old ns/iter new ns/iter diff ns/iter diff % speedup
btree::map::iter_100 3,333 3,023 -310 -9.30% x 1.10
btree::map::range_unbounded_vs_iter 36,624 31,569 -5,055 -13.80% x 1.16
```
r? @Mark-Simulacrum
Respect `-Z proc-macro-backtrace` flag for panics inside libproc_macro
Fixes#76270
Previously, any panic occuring during a call to a libproc_macro method
(e.g. calling `Ident::new` with an invalid identifier) would always
cause an ICE message to be printed.
Disable zlib in LLVM on Haiku
PR #72696 enabled the option LLVM_ENABLE_ZLIB for the LLVM builds. Like NetBSD and aarch64-apple-darwin (see PR #75500), the LLVM build system not explicitly linking to libz on these platforms cause issues. For Haiku, this meant the runtime loader complaining about undefined symbols..
- Preserve suffixes when displaying
- Rename test file to match `intra-link*`
- Remove unnecessary .clone()s
- Improve comments and naming
- Fix more bugs and add tests
- Escape intra-doc link example in public documentation
Tools, tests, and experimenting with MIR-derived coverage counters
Leverages the new mir_dump output file in HTML+CSS (from #76074) to visualize coverage code regions
and the MIR features that they came from (including overlapping spans).
See example below.
The `run-make-fulldeps/instrument-coverage` test has been refactored to maximize test coverage and reduce code duplication. The new tests support testing with and without `-Clink-dead-code`, so Rust coverage can be tested on MSVC (which, currently, only works with `link-dead-code` _disabled_).
New tests validate coverage region generation and coverage reports with multiple counters per function. Starting with a simple `if-else` branch tests, coverage tests for each additional syntax type can be added by simply dropping in a new Rust sample program.
Includes a basic, MIR-block-based implementation of coverage injection,
available via `-Zexperimental-coverage`. This implementation has known
flaws and omissions, but is simple enough to validate the new tools and
tests.
The existing `-Zinstrument-coverage` option currently enables
function-level coverage only, which at least appears to generate
accurate coverage reports at that level.
Experimental coverage is not accurate at this time. When branch coverage
works as intended, the `-Zexperimental-coverage` option should be
removed.
This PR replaces the bulk of PR #75828, with the remaining parts of
that PR distributed among other separate and indentpent PRs.
This PR depends on two of those other PRs: #76002, #76003 and #76074
Rust compiler MCP rust-lang/compiler-team#278
Relevant issue: #34701 - Implement support for LLVMs code coverage
instrumentation
r? @tmandry
FYI: @wesleywiser
diagnostics: shorten paths of unique symbols
This is a step towards implementing a fix for #50310, and continuation of the discussion in [Pre-RFC: Nicer Types In Diagnostics - compiler - Rust Internals](https://internals.rust-lang.org/t/pre-rfc-nicer-types-in-diagnostics/11139). Impressed upon me from previous discussion in #21934 that an RFC for this is not needed, and I should just come up with code.
The recent improvements to `use` suggestions that I've contributed have given rise to this implementation. Contrary to previous suggestions, it's rather simple logic, and I believe it only reduces the amount of cognitive load that a developer would need when reading type errors.
-----
If a symbol name can only be imported from one place, and as long as it was not glob-imported anywhere in the current crate, we can trim its printed path to the last component.
This has wide implications on error messages with types, for example, shortening `std::vec::Vec` to just `Vec`, as long as there is no other `Vec` importable from anywhere.
specialize some collection and iterator operations to run in-place
This is a rebase and update of #66383 which was closed due inactivity.
Recent rustc changes made the compile time regressions disappear, at least for webrender-wrench. Running a stage2 compile and the rustc-perf suite takes hours on the hardware I have at the moment, so I can't do much more than that.
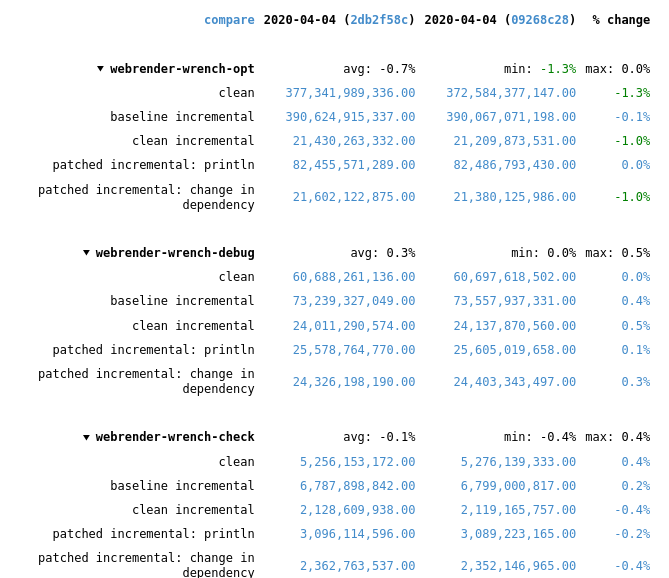
In the best case of the `vec::bench_in_place_recycle` synthetic microbenchmark these optimizations can provide a 15x speedup over the regular implementation which allocates a new vec for every benchmark iteration. [Benchmark results](https://gist.github.com/the8472/6d999b2d08a2bedf3b93f12112f96e2f). In real code the speedups are tiny, but it also depends on the allocator used, a system allocator that uses a process-wide mutex will benefit more than one with thread-local pools.
## What was changed
* `SpecExtend` which covered `from_iter` and `extend` specializations was split into separate traits
* `extend` and `from_iter` now reuse the `append_elements` if passed iterators are from slices.
* A preexisting `vec.into_iter().collect::<Vec<_>>()` optimization that passed through the original vec has been generalized further to also cover cases where the original has been partially drained.
* A chain of *Vec<T> / BinaryHeap<T> / Box<[T]>* `IntoIter`s through various iterator adapters collected into *Vec<U>* and *BinaryHeap<U>* will be performed in place as long as `T` and `U` have the same alignment and size and aren't ZSTs.
* To enable above specialization the unsafe, unstable `SourceIter` and `InPlaceIterable` traits have been added. The first allows reaching through the iterator pipeline to grab a pointer to the source memory. The latter is a marker that promises that the read pointer will advance as fast or faster than the write pointer and thus in-place operation is possible in the first place.
* `vec::IntoIter` implements `TrustedRandomAccess` for `T: Copy` to allow in-place collection when there is a `Zip` adapter in the iterator. TRA had to be made an unstable public trait to support this.
## In-place collectible adapters
* `Map`
* `MapWhile`
* `Filter`
* `FilterMap`
* `Fuse`
* `Skip`
* `SkipWhile`
* `Take`
* `TakeWhile`
* `Enumerate`
* `Zip` (left hand side only, `Copy` types only)
* `Peek`
* `Scan`
* `Inspect`
## Concerns
`vec.into_iter().filter(|_| false).collect()` will no longer return a vec with 0 capacity, instead it will return its original allocation. This avoids the cost of doing any allocation or deallocation but could lead to large allocations living longer than expected.
If that's not acceptable some resizing policy at the end of the attempted in-place collect would be necessary, which in the worst case could result in one more memcopy than the non-specialized case.
## Possible followup work
* split liballoc/vec.rs to remove `ignore-tidy-filelength`
* try to get trivial chains such as `vec.into_iter().skip(1).collect::<Vec<)>>()` to compile to a `memmove` (currently compiles to a pile of SIMD, see #69187 )
* improve up the traits so they can be reused by other crates, e.g. itertools. I think currently they're only good enough for internal use
* allow iterators sourced from a `HashSet` to be in-place collected into a `Vec`
The InPlaceIterable debug assert checks that the write pointer
did not advance beyond the read pointer. But TrustedRandomAccess
never advances the read pointer, thus triggering the assert.
Skip the assert if the source pointer did not change during iteration.
Often when modifying compiler code you'll miss that you've changed an API used
by unit tests, since x.py check didn't previously catch that.
It's also useful to have this for editing with rust-analyzer and similar tooling
where editing tests previously didn't notify you of errors in test files.
rustdoc: do not use plain summary for trait impls
Fixes#38386.
Fixes#48332.
Fixes#49430.
Fixes#62741.
Fixes#73474.
Unfortunately this is not quite ready to go because the newly-working links trigger a bunch of linkcheck failures. The failures are tough to fix because the links are resolved relative to the implementor, which could be anywhere in the module hierarchy.
(In the current docs, these links end up rendering as uninterpreted markdown syntax, so I don't think these failures are any worse than the status quo. It might be acceptable to just add them to the linkchecker whitelist.)
Ideally this could be fixed with intra-doc links ~~but it isn't working for me: I am currently investigating if it's possible to solve it this way.~~ Opened #73829.
EDIT: This is now ready!
{kind=link}
{kind=link}