195 lines
8.5 KiB
Markdown
195 lines
8.5 KiB
Markdown
# Architecture
|
|
|
|
This document describes the high-level architecture of rust-analyzer.
|
|
If you want to familiarize yourself with the code base, you are just
|
|
in the right place!
|
|
|
|
See also the [guide](./guide.md), which walks through a particular snapshot of
|
|
rust-analyzer code base.
|
|
|
|
## The Big Picture
|
|
|
|
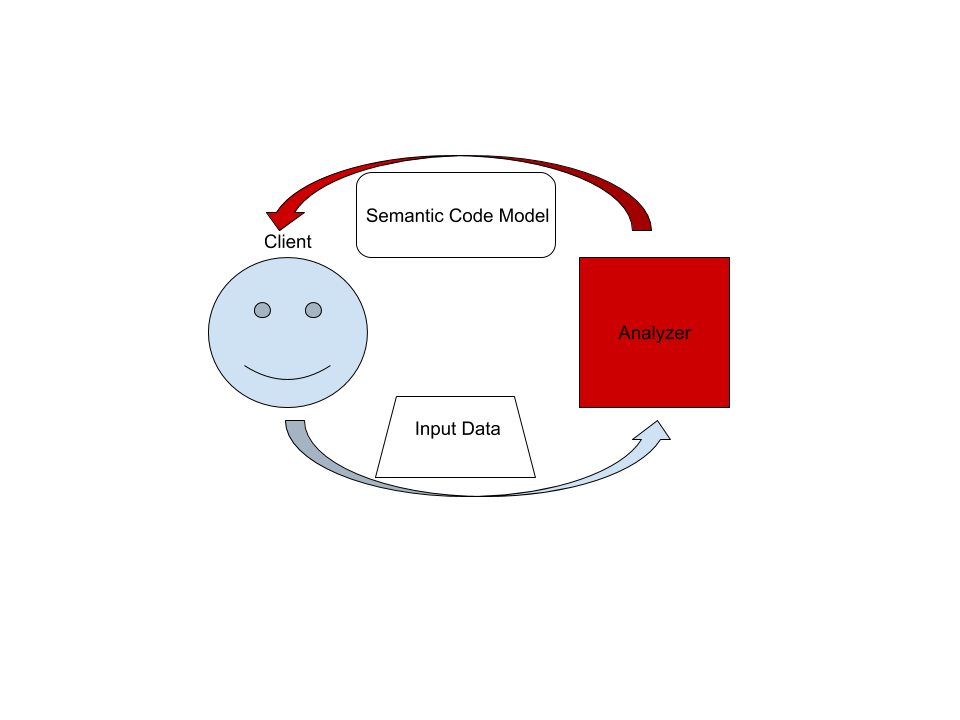
|
|
|
|
On the highest level, rust-analyzer is a thing which accepts input source code
|
|
from the client and produces a structured semantic model of the code.
|
|
|
|
More specifically, input data consists of a set of test files (`(PathBuf,
|
|
String)` pairs) and information about project structure, captured in the so called
|
|
`CrateGraph`. The crate graph specifies which files are crate roots, which cfg
|
|
flags are specified for each crate (TODO: actually implement this) and what
|
|
dependencies exist between the crates. The analyzer keeps all this input data in
|
|
memory and never does any IO. Because the input data is source code, which
|
|
typically measures in tens of megabytes at most, keeping all input data in
|
|
memory is OK.
|
|
|
|
A "structured semantic model" is basically an object-oriented representation of
|
|
modules, functions and types which appear in the source code. This representation
|
|
is fully "resolved": all expressions have types, all references are bound to
|
|
declarations, etc.
|
|
|
|
The client can submit a small delta of input data (typically, a change to a
|
|
single file) and get a fresh code model which accounts for changes.
|
|
|
|
The underlying engine makes sure that model is computed lazily (on-demand) and
|
|
can be quickly updated for small modifications.
|
|
|
|
|
|
## Code generation
|
|
|
|
Some of the components of this repository are generated through automatic
|
|
processes. These are outlined below:
|
|
|
|
- `gen-syntax`: The kinds of tokens that are reused in several places, so a generator
|
|
is used. We use tera templates to generate the files listed below, based on
|
|
the grammar described in [grammar.ron]:
|
|
- [ast/generated.rs][ast generated] in `ra_syntax` based on
|
|
[ast/generated.tera.rs][ast source]
|
|
- [syntax_kinds/generated.rs][syntax_kinds generated] in `ra_syntax` based on
|
|
[syntax_kinds/generated.tera.rs][syntax_kinds source]
|
|
|
|
[tera]: https://tera.netlify.com/
|
|
[grammar.ron]: ./crates/ra_syntax/src/grammar.ron
|
|
[ast generated]: ./crates/ra_syntax/src/ast/generated.rs
|
|
[ast source]: ./crates/ra_syntax/src/ast/generated.rs.tera
|
|
[syntax_kinds generated]: ./crates/ra_syntax/src/syntax_kinds/generated.rs
|
|
[syntax_kinds source]: ./crates/ra_syntax/src/syntax_kinds/generated.rs.tera
|
|
|
|
|
|
## Code Walk-Through
|
|
|
|
### `crates/ra_syntax`
|
|
|
|
Rust syntax tree structure and parser. See
|
|
[RFC](https://github.com/rust-lang/rfcs/pull/2256) for some design notes.
|
|
|
|
- [rowan](https://github.com/rust-analyzer/rowan) library is used for constructing syntax trees.
|
|
- `grammar` module is the actual parser. It is a hand-written recursive descent parser, which
|
|
produces a sequence of events like "start node X", "finish not Y". It works similarly to [kotlin's parser](https://github.com/JetBrains/kotlin/blob/4d951de616b20feca92f3e9cc9679b2de9e65195/compiler/frontend/src/org/jetbrains/kotlin/parsing/KotlinParsing.java),
|
|
which is a good source of inspiration for dealing with syntax errors and incomplete input. Original [libsyntax parser](https://github.com/rust-lang/rust/blob/6b99adeb11313197f409b4f7c4083c2ceca8a4fe/src/libsyntax/parse/parser.rs)
|
|
is what we use for the definition of the Rust language.
|
|
- `parser_api/parser_impl` bridges the tree-agnostic parser from `grammar` with `rowan` trees.
|
|
This is the thing that turns a flat list of events into a tree (see `EventProcessor`)
|
|
- `ast` provides a type safe API on top of the raw `rowan` tree.
|
|
- `grammar.ron` RON description of the grammar, which is used to
|
|
generate `syntax_kinds` and `ast` modules, using `cargo gen-syntax` command.
|
|
- `algo`: generic tree algorithms, including `walk` for O(1) stack
|
|
space tree traversal (this is cool) and `visit` for type-driven
|
|
visiting the nodes (this is double plus cool, if you understand how
|
|
`Visitor` works, you understand the design of syntax trees).
|
|
|
|
Tests for ra_syntax are mostly data-driven: `tests/data/parser` contains a bunch of `.rs`
|
|
(test vectors) and `.txt` files with corresponding syntax trees. During testing, we check
|
|
`.rs` against `.txt`. If the `.txt` file is missing, it is created (this is how you update
|
|
tests). Additionally, running `cargo gen-tests` will walk the grammar module and collect
|
|
all `//test test_name` comments into files inside `tests/data` directory.
|
|
|
|
See [#93](https://github.com/rust-analyzer/rust-analyzer/pull/93) for an example PR which
|
|
fixes a bug in the grammar.
|
|
|
|
### `crates/ra_db`
|
|
|
|
We use the [salsa](https://github.com/salsa-rs/salsa) crate for incremental and
|
|
on-demand computation. Roughly, you can think of salsa as a key-value store, but
|
|
it also can compute derived values using specified functions. The `ra_db` crate
|
|
provides basic infrastructure for interacting with salsa. Crucially, it
|
|
defines most of the "input" queries: facts supplied by the client of the
|
|
analyzer. Reading the docs of the `ra_db::input` module should be useful:
|
|
everything else is strictly derived from those inputs.
|
|
|
|
### `crates/ra_hir`
|
|
|
|
HIR provides high-level "object oriented" access to Rust code.
|
|
|
|
The principal difference between HIR and syntax trees is that HIR is bound to a
|
|
particular crate instance. That is, it has cfg flags and features applied (in
|
|
theory, in practice this is to be implemented). So, the relation between
|
|
syntax and HIR is many-to-one. The `source_binder` module is responsible for
|
|
guessing a HIR for a particular source position.
|
|
|
|
Underneath, HIR works on top of salsa, using a `HirDatabase` trait.
|
|
|
|
### `crates/ra_ide_api`
|
|
|
|
A stateful library for analyzing many Rust files as they change. `AnalysisHost`
|
|
is a mutable entity (clojure's atom) which holds the current state, incorporates
|
|
changes and hands out `Analysis` --- an immutable and consistent snapshot of
|
|
the world state at a point in time, which actually powers analysis.
|
|
|
|
One interesting aspect of analysis is its support for cancellation. When a
|
|
change is applied to `AnalysisHost`, first all currently active snapshots are
|
|
canceled. Only after all snapshots are dropped the change actually affects the
|
|
database.
|
|
|
|
APIs in this crate are IDE centric: they take text offsets as input and produce
|
|
offsets and strings as output. This works on top of rich code model powered by
|
|
`hir`.
|
|
|
|
### `crates/ra_ide_api_light`
|
|
|
|
All IDE features which can be implemented if you only have access to a single
|
|
file. `ra_ide_api_light` could be used to enhance editing of Rust code without
|
|
the need to fiddle with build-systems, file synchronization and such.
|
|
|
|
In a sense, `ra_ide_api_light` is just a bunch of pure functions which take a
|
|
syntax tree as input.
|
|
|
|
The tests for `ra_ide_api_light` are `#[cfg(test)] mod tests` unit-tests spread
|
|
throughout its modules.
|
|
|
|
|
|
### `crates/ra_lsp_server`
|
|
|
|
An LSP implementation which wraps `ra_ide_api` into a langauge server protocol.
|
|
|
|
### `crates/ra_vfs`
|
|
|
|
Although `hir` and `ra_ide_api` don't do any IO, we need to be able to read
|
|
files from disk at the end of the day. This is what `ra_vfs` does. It also
|
|
manages overlays: "dirty" files in the editor, whose "true" contents is
|
|
different from data on disk.
|
|
|
|
### `crates/gen_lsp_server`
|
|
|
|
A language server scaffold, exposing a synchronous crossbeam-channel based API.
|
|
This crate handles protocol handshaking and parsing messages, while you
|
|
control the message dispatch loop yourself.
|
|
|
|
Run with `RUST_LOG=sync_lsp_server=debug` to see all the messages.
|
|
|
|
### `crates/ra_cli`
|
|
|
|
A CLI interface to rust-analyzer.
|
|
|
|
### `crate/tools`
|
|
|
|
Custom Cargo tasks used to develop rust-analyzer:
|
|
|
|
- `cargo gen-syntax` -- generate `ast` and `syntax_kinds`
|
|
- `cargo gen-tests` -- collect inline tests from grammar
|
|
- `cargo install-code` -- build and install VS Code extension and server
|
|
|
|
### `editors/code`
|
|
|
|
VS Code plugin
|
|
|
|
|
|
## Common workflows
|
|
|
|
To try out VS Code extensions, run `cargo install-code`. This installs both the
|
|
`ra_lsp_server` binary and the VS Code extension. To install only the binary, use
|
|
`cargo install --path crates/ra_lsp_server --force`
|
|
|
|
To see logs from the language server, set `RUST_LOG=info` env variable. To see
|
|
all communication between the server and the client, use
|
|
`RUST_LOG=gen_lsp_server=debug` (this will print quite a bit of stuff).
|
|
|
|
There's `Status of rust-analyzer` command which prints common high-level debug info.
|
|
|
|
To run tests, just `cargo test`.
|
|
|
|
To work on the VS Code extension, launch code inside `editors/code` and use `F5` to
|
|
launch/debug. To automatically apply formatter and linter suggestions, use `npm
|
|
run fix`.
|
|
|