macros: `LintDiagnostic` derive
- Move `LintDiagnosticBuilder` into `rustc_errors` so that a diagnostic derive can refer to it.
- Introduce a `DecorateLint` trait, which is equivalent to `SessionDiagnostic` or `AddToDiagnostic` but for lints. Necessary without making more changes to the lint infrastructure as `DecorateLint` takes a `LintDiagnosticBuilder` and re-uses all of the existing logic for determining what type of diagnostic a lint should be emitted as (e.g. error/warning).
- Various refactorings of the diagnostic derive machinery (extracting `build_field_mapping` helper and moving `sess` field out of the `DiagnosticDeriveBuilder`).
- Introduce a `LintDiagnostic` derive macro that works almost exactly like the `SessionDiagnostic` derive macro except that it derives a `DecorateLint` implementation instead. A new derive is necessary for this because `SessionDiagnostic` is intended for when the generated code creates the diagnostic. `AddToDiagnostic` could have been used but it would have required more changes to the lint machinery.
~~At time of opening this pull request, ignore all of the commits from #98624, it's just the last few commits that are new.~~
r? `@oli-obk`
Fix repr(align) enum handling
`enum`, for better or worse, supports `repr(align)`. That has already caused a bug in https://github.com/rust-lang/rust/issues/92464, which was "fixed" in https://github.com/rust-lang/rust/pull/92932, but it turns out that that fix is wrong and caused https://github.com/rust-lang/rust/issues/96185.
So this reverts #92932 (which fixes#96185), and attempts another strategy for fixing #92464: special-case enums when doing a cast, re-using the code to load the discriminant rather than assuming that the enum has scalar layout. This works fine for the interpreter.
However, #92464 contained another testcase that was previously not in the test suite -- and after adding it, it ICEs again. This is not surprising; codegen needs the same patch that I did in the interpreter. Probably this has to happen [around here](d32ce37a17/compiler/rustc_codegen_ssa/src/mir/rvalue.rs (L276)). Unfortunately I don't know how to do that -- the interpreter can load a discriminant from an operand, but codegen can only do that from a place. `@oli-obk` `@eddyb` `@bjorn3` any idea?
lints: mostly translatable diagnostics
As lints are created slightly differently than other diagnostics, intended to try make them translatable first and then look into the applicability of diagnostic structs but ended up just making most of the diagnostics in the crate translatable (which will still be useful if I do make a lot of them structs later anyway).
r? ``@compiler-errors``
Change enum->int casts to not go through MIR casts.
follow-up to https://github.com/rust-lang/rust/pull/96814
this simplifies all backends and even gives LLVM more information about the return value of `Rvalue::Discriminant`, enabling optimizations in more cases.
Interpret: AllocRange Debug impl, and use it more consistently
The two commits are pretty independent but it did not seem worth having two PRs for them.
r? ``@oli-obk``
Add method to mutate MIR body without invalidating CFG caches.
In addition to adding this method, a handful of passes are updated to use it. There's still quite a few passes that could in principle make use of this as well, but do not at the moment because they use `VisitorMut` or `MirPatch`, which needs additional support for this.
The method name is slightly unwieldy, but I don't expect anyone to be writing it a lot, and at least it says what it does. If anyone has a suggestion for a better name though, would be happy to rename.
r? rust-lang/mir-opt
CTFE interning: don't walk allocations that don't need it
The interning of const allocations visits the mplace looking for references to intern. Walking big aggregates like big static arrays can be costly, so we only do it if the allocation we're interning contains references or interior mutability.
Walking ZSTs was avoided before, and this optimization is now applied to cases where there are no references/relocations either.
---
While initially looking at this in the context of #93215, I've been testing with smaller allocations than the 16GB one in that issue, and with different init/uninit patterns (esp. via padding).
In that example, by default, `eval_to_allocation_raw` is the heaviest query followed by `incr_comp_serialize_result_cache`. So I'll show numbers when incremental compilation is disabled, to focus on the const allocations themselves at 95% of the compilation time, at bigger array sizes on these minimal examples like `static ARRAY: [u64; LEN] = [0; LEN];`.
That is a close construction to parts of the `ctfe-stress-test-5` benchmark, which has const allocations in the megabytes, while most crates usually have way smaller ones. This PR will have the most impact in these situations, as the walk during the interning starts to dominate the runtime.
Unicode crates (some of which are present in our benchmarks) like `ucd`, `encoding_rs`, etc come to mind as having bigger than usual allocations as well, because of big tables of code points (in the hundreds of KB, so still an order of magnitude or 2 less than the stress test).
In a check build, for a single static array shown above, from 100 to 10^9 u64s (for lengths in powers of ten), the constant factors are lowered:
(log scales for easier comparisons)
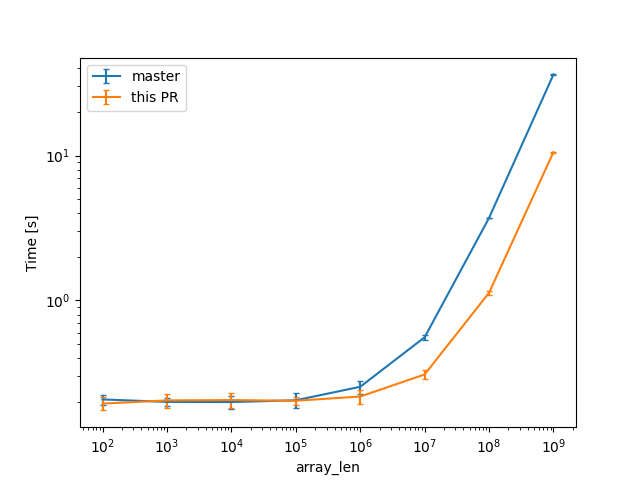
(linear scale for absolute diff at higher Ns)
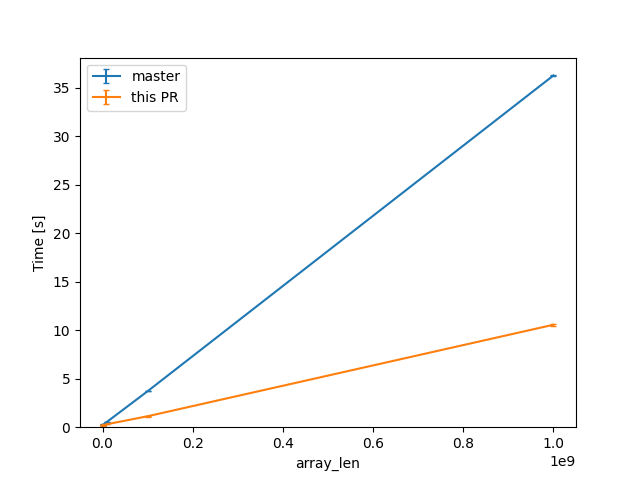
For one of the alternatives of that issue
```rust
const ROWS: usize = 100_000;
const COLS: usize = 10_000;
static TWODARRAY: [[u128; COLS]; ROWS] = [[0; COLS]; ROWS];
```
we can see a similar reduction of around 3x (from 38s to 12s or so).
For the same size, the slowest case IIRC is when there are uninitialized bytes e.g. via padding
```rust
const ROWS: usize = 100_000;
const COLS: usize = 10_000;
static TWODARRAY: [[(u64, u8); COLS]; ROWS] = [[(0, 0); COLS]; ROWS];
```
then interning/walking does not dominate anymore (but means there is likely still some interesting work left to do here).
Compile times in this case rise up quite a bit, and avoiding interning walks has less impact: around 23%, from 730s on master to 568s with this PR.
Fix FFI-unwind unsoundness with mixed panic mode
UB maybe introduced when an FFI exception happens in a `C-unwind` foreign function and it propagates through a crate compiled with `-C panic=unwind` into a crate compiled with `-C panic=abort` (#96926).
To prevent this unsoundness from happening, we will disallow a crate compiled with `-C panic=unwind` to be linked into `panic-abort` *if* it contains a call to `C-unwind` foreign function or function pointer. If no such call exists, then we continue to allow such mixed panic mode linking because it's sound (and stable). In fact we still need the ability to do mixed panic mode linking for std, because we only compile std once with `-C panic=unwind` and link it regardless panic strategy.
For libraries that wish to remain compile-once-and-linkable-to-both-panic-runtimes, a `ffi_unwind_calls` lint is added (gated under `c_unwind` feature gate) to flag any FFI unwind calls that will cause the linkable panic runtime be restricted.
In summary:
```rust
#![warn(ffi_unwind_calls)]
mod foo {
#[no_mangle]
pub extern "C-unwind" fn foo() {}
}
extern "C-unwind" {
fn foo();
}
fn main() {
// Call to Rust function is fine regardless ABI.
foo::foo();
// Call to foreign function, will cause the crate to be unlinkable to panic-abort if compiled with `-Cpanic=unwind`.
unsafe { foo(); }
//~^ WARNING call to foreign function with FFI-unwind ABI
let ptr: extern "C-unwind" fn() = foo::foo;
// Call to function pointer, will cause the crate to be unlinkable to panic-abort if compiled with `-Cpanic=unwind`.
ptr();
//~^ WARNING call to function pointer with FFI-unwind ABI
}
```
Fix#96926
`@rustbot` label: T-compiler F-c_unwind
Enable MIR inlining
Continuation of https://github.com/rust-lang/rust/pull/82280 by `@wesleywiser.`
#82280 has shown nice compile time wins could be obtained by enabling MIR inlining.
Most of the issues in https://github.com/rust-lang/rust/issues/81567 are now fixed,
except the interaction with polymorphization which is worked around specifically.
I believe we can proceed with enabling MIR inlining in the near future
(preferably just after beta branching, in case we discover new issues).
Steps before merging:
- [x] figure out the interaction with polymorphization;
- [x] figure out how miri should deal with extern types;
- [x] silence the extra arithmetic overflow warnings;
- [x] remove the codegen fulfilment ICE;
- [x] remove the type normalization ICEs while compiling nalgebra;
- [ ] tweak the inlining threshold.
cleanup mir visitor for `rustc::pass_by_value`
by changing `& $($mutability)?` to `$(& $mutability)?`
I also did some formatting changes because I started doing them for the visit methods I changed and then couldn't get myself to stop xx, I hope that's still fairly easy to review.
Accept `DiagnosticMessage` in `LintDiagnosticBuilder::build` so that
lints can be built with translatable diagnostic messages.
Signed-off-by: David Wood <david.wood@huawei.com>
move MIR syntax into a dedicated file and ping some people whenever it changes
Adding or changing MIR operations/statements/whatever should be under significant scrutiny wrt their wider impact, specified semantics, and so on. So let's start by putting all that into a dedicated file and pinging some people whenever that file changes.
This PR only moves definitions around, and then fiddles with imports until it all works again.
Only keep a single query for well-formed checking
There are currently 3 queries to perform wf checks on different item-likes. This complexity is not required.
This PR replaces the query by:
- one query per item;
- one query to invoke it for a whole module.
This allows to remove HIR `ParItemLikeVisitor`.
Check ADT field is well-formed before checking it is sized
Fixes#96810.
There is one diagnostics regression, in [`src/test/ui/generic-associated-types/bugs/issue-80626.stderr`](https://github.com/rust-lang/rust/pull/97780/files#diff-53795946378e78a0af23a10277c628ff79091c18090fdc385801ee70c1ba6963). I am not super concerned about it, since it's GAT related.
We _could_ fix it, possibly by using the `FieldSized` obligation cause code instead of `BuiltinDerivedObligation`. But that would require changing `Sized` trait confirmation and the `adt_sized_constraint` query.
Reverse folder hierarchy
#91318 introduced a trait for infallible folders distinct from the fallible version. For some reason (completely unfathomable to me now that I look at it with fresh eyes), the infallible trait was a supertrait of the fallible one: that is, all fallible folders were required to also be infallible. Moreover the `Error` associated type was defined on the infallible trait! It's so absurd that it has me questioning whether I was entirely sane.
This trait reverses the hierarchy, so that the fallible trait is a supertrait of the infallible one: all infallible folders are required to also be fallible (which is a trivial blanket implementation). This of course makes much more sense! It also enables the `Error` associated type to sit on the fallible trait, where it sensibly belongs.
There is one downside however: folders expose a `tcx` accessor method. Since the blanket fallible implementation for infallible folders only has access to a generic `F: TypeFolder`, we need that trait to expose such an accessor to which we can delegate. Alternatively it's possible to extract that accessor into a separate `HasTcx` trait (or similar) that would then be a supertrait of both the fallible and infallible folder traits: this would ensure that there's only one unambiguous `tcx` method, at the cost of a little additional boilerplate. If desired, I can submit that as a separate PR.
r? ````@jackh726````
Improve suggestion for calling fn-like expr on type mismatch
1.) Suggest calling values of with RPIT types (and probably TAIT) when we expect `Ty` and have `impl Fn() -> Ty`
2.) Suggest calling closures even when they're not assigned to a local variable first
3.) Drive-by fix of a pretty-printing bug (`impl Fn()-> Ty` => `impl Fn() -> Ty`)
r? ```@estebank```
Remove (transitive) reliance on sorting by DefId in pretty-printer
This moves us a step closer to removing the `PartialOrd/`Ord` impls
for `DefId`. See #90317
implement `iter_projections` function on `PlaceRef`
this makes the api more flexible. the original function now calls the PlaceRef
version to avoid duplicating the code.
Point at return expression for RPIT-related error
Certainly this needs some diagnostic refining, but I wanted to show that it was possible first and foremost. Not sure if this is the right approach. Open to feedback.
Fixes#80583
#91318 introduced a trait for infallible folders distinct from the fallible version. For some reason (completely unfathomable to me now that I look at it with fresh eyes), the infallible trait was a supertrait of the fallible one: that is, all fallible folders were required to also be infallible. Moreover the `Error` associated type was defined on the infallible trait! It's so absurd that it has me questioning whether I was entirely sane.
This trait reverses the hierarchy, so that the fallible trait is a supertrait of the infallible one: all infallible folders are required to also be fallible (which is a trivial blanket implementation). This of course makes much more sense! It also enables the `Error` associated type to sit on the fallible trait, where it sensibly belongs.
There is one downside however: folders expose a `tcx` accessor method. Since the blanket fallible implementation for infallible folders only has access to a generic `F: TypeFolder`, we need that trait to expose such an accessor to which we can delegate. Alternatively it's possible to extract that accessor into a separate `HasTcx` trait (or similar) that would then be a supertrait of both the fallible and infallible folder traits: this would ensure that there's only one unambiguous `tcx` method, at the cost of a little additional boilerplate. If desired, I can submit that as a separate PR.
r? @jackh726
`try_fold_unevaluated` for infallible folders
#97447 added folding of unevaluated constants, but did not include an override of the default (fallible) operation in the blanket impl of `FallibleTypeFolder` for infallible folders. Here we provide that missing override.
r? ```@nnethercote```
Remove dereferencing of Box from codegen
Through #94043, #94414, #94873, and #95328, I've been fixing issues caused by Box being treated like a pointer when it is not a pointer. However, these PRs just introduced special cases for Box. This PR removes those special cases and instead transforms a deref of Box into a deref of the pointer it contains.
Hopefully, this is the end of the Box<T, A> ICEs.
Don't omit comma when suggesting wildcard arm after macro expr
* Also adds `Span::eq_ctxt` to consolidate the various usages of `span.ctxt() == other.ctxt()`
* Also fixes an unhygenic usage of spans which caused the suggestion to render weirdly when we had one arm match in a macro
* Also always suggests a comma (i.e. even after a block) if we're rendering a wildcard arm in a single-line match (looks prettier 🌹)
Fixes#94866
#97447 added folding of unevaluated constants, but did not include an override of the default (fallible) operation in the blanket impl of `FallibleTypeFolder` for infallible folders. Here we provide that missing override.
r? @nnethercote
Rollup of 5 pull requests
Successful merges:
- #98105 (rustdoc: remove tuple link on round braces)
- #98136 (Rename `impl_constness` to `constness`)
- #98146 (Remove --memory-init-file flag when linking with Emscripten)
- #98219 (Skip late bound regions in GATSubstCollector)
- #98233 (Remove accidental uses of `&A: Allocator`)
Failed merges:
r? `@ghost`
`@rustbot` modify labels: rollup
Rename `impl_constness` to `constness`
The current code is a basis for `is_const_fn_raw`, and `impl_constness`
is no longer a valid name, which is previously used for determining the
constness of impls, and not items in general.
r? `@oli-obk`
ctfe: limit hashing of big const allocations when interning
Const allocations are only hashed for interning. However, they can be large, making the hashing expensive especially since it uses `FxHash`: it's better suited to short keys, not potentially big buffers like the actual bytes of allocation and the associated 1/8th sized `InitMask`.
We can partially hash these fields when they're large, hashing the length, and head and tail of these buffers, to
limit possible collisions while avoiding most of the hashing work.
r? `@ghost`
Big const allocations hash a large amount of data for interning:
the whole bytes buffer, and the 1/8th sized initmask, with FxHash.
This hash function is made for shorter keys.
This only hashes the length, and head and tail of these buffers, to
limit possible collisions while avoiding most of the hashing work.
Support lint expectations for `--force-warn` lints (RFC 2383)
Rustc has a `--force-warn` flag, which overrides lint level attributes and forces the diagnostics to always be warn. This means, that for lint expectations, the diagnostic can't be suppressed as usual. This also means that the expectation would not be fulfilled, even if a lint had been triggered in the expected scope.
This PR now also tracks the expectation ID in the `ForceWarn` level. I've also made some minor adjustments, to possibly catch more bugs and make the whole implementation more robust.
This will probably conflict with https://github.com/rust-lang/rust/pull/97718. That PR should ideally be reviewed and merged first. The conflict itself will be trivial to fix.
---
r? `@wesleywiser`
cc: `@flip1995` since you've helped with the initial review and also discussed this topic with me. 🙃
Follow-up of: https://github.com/rust-lang/rust/pull/87835
Issue: https://github.com/rust-lang/rust/issues/85549
Yeah, and that's it.
The current code is a basis for `is_const_fn_raw`, and `impl_constness`
is no longer a valid name, which is previously used for determining the
constness of impls, and not items in general.
Make `ExprKind::Closure` a struct variant.
Simple refactor since we both need it to introduce additional fields in `ExprKind::Closure`.
r? ``@Aaron1011``
Rename rustc_serialize::opaque::Encoder as MemEncoder.
This avoids the name clash with `rustc_serialize::Encoder` (a trait),
and allows lots qualifiers to be removed and imports to be simplified
(e.g. fewer `as` imports).
(This was previously merged as commit 5 in #94732 and then was reverted
in #97905 because of a perf regression caused by commit 4 in #94732.)
r? ```@bjorn3```
This avoids the name clash with `rustc_serialize::Encoder` (a trait),
and allows lots qualifiers to be removed and imports to be simplified
(e.g. fewer `as` imports).
(This was previously merged as commit 5 in #94732 and then was reverted
in #97905 because of a perf regression caused by commit 4 in #94732.)
And likewise for the `Const::val` method.
Because its type is called `ConstKind`. Also `val` is a confusing name
because `ConstKind` is an enum with seven variants, one of which is
called `Value`. Also, this gives consistency with `TyS` and `PredicateS`
which have `kind` fields.
The commit also renames a few `Const` variables from `val` to `c`, to
avoid confusion with the `ConstKind::Value` variant.
Remove unnecessary `to_string` and `String::new`
73fa217bc1 changed the type of the `suggestion` argument to `impl ToString`. This patch removes unnecessary `to_string` and `String::new`.
cc: `````@davidtwco`````
Handle `def_ident_span` like `def_span`.
`def_ident_span` had an ad-hoc status in the compiler.
This PR refactors it to be a first-class citizen like `def_span`:
- it gets encoded in the main metadata loop, instead of the visitor;
- its implementation is updated to mirror the one of `def_span`.
We do not remove the `Option` in the return type, since some items do not have an ident, AnonConsts for instance.
Wrap `HirId`s of locals into `LocalVarId`s for THIR nodes
This is the first effort to decouple `HirId`s from THIR. `HirId` is not very relevant in building THIR and MIR.
Based on the changeset, I think there are a few other pending refactoring that we could perform after this, in case we want to eliminate use of `HirId` in THIR.
- `TypeckResults::closure_min_captures` could be remapped from the variable `HirId`s to `LocalVarId` while the THIR is getting built.
- Use of `ScopeTree::var_scope` could be eliminated as well, since we will consider deprecating `ScopeTree` in the future.
Revert part of #94372 to improve performance
#94732 was supposed to give small but widespread performance improvements, as judged from three per-merge performance runs. But the performance run that occurred after merging included a roughly equal number of improvements and regressions, for unclear reasons.
This PR is for a test run reverting those changes, to see what happens.
r? `@ghost`
use precise spans for recursive const evaluation
This fixes https://github.com/rust-lang/rust/issues/73283 by using a `TyCtxtAt` with a more precise span when the interpreter recursively calls itself. Hopefully such calls are sufficiently rare that this does not cost us too much performance.
(In theory, cycles can also arise through layout computation, as layout can depend on consts -- but layout computation happens all the time so we'd have to do something to not make this terrible for performance.)
it feels arbitrary to have `Ty` and `Const` directly
in that module and to not have `GenericArg` and
`GenericArgKind` there. Writing `ty::GenericArg`
can also feel clearer than importing it. Using
`ty::subst::GenericArg` however is ugly.
This avoids the name clash with `rustc_serialize::Encoder` (a trait),
and allows lots qualifiers to be removed and imports to be simplified
(e.g. fewer `as` imports).
This commit makes type folding more like the way chalk does it.
Currently, `TypeFoldable` has `fold_with` and `super_fold_with` methods.
- `fold_with` is the standard entry point, and defaults to calling
`super_fold_with`.
- `super_fold_with` does the actual work of traversing a type.
- For a few types of interest (`Ty`, `Region`, etc.) `fold_with` instead
calls into a `TypeFolder`, which can then call back into
`super_fold_with`.
With the new approach, `TypeFoldable` has `fold_with` and
`TypeSuperFoldable` has `super_fold_with`.
- `fold_with` is still the standard entry point, *and* it does the
actual work of traversing a type, for all types except types of
interest.
- `super_fold_with` is only implemented for the types of interest.
Benefits of the new model.
- I find it easier to understand. The distinction between types of
interest and other types is clearer, and `super_fold_with` doesn't
exist for most types.
- With the current model is easy to get confused and implement a
`super_fold_with` method that should be left defaulted. (Some of the
precursor commits fixed such cases.)
- With the current model it's easy to call `super_fold_with` within
`TypeFolder` impls where `fold_with` should be called. The new
approach makes this mistake impossible, and this commit fixes a number
of such cases.
- It's potentially faster, because it avoids the `fold_with` ->
`super_fold_with` call in all cases except types of interest. A lot of
the time the compile would inline those away, but not necessarily
always.
We already have `visit_unevaluated`, so this improves consistency.
Also, define `TypeFoldable for Unevaluated<'tcx, ()>` in terms of
`TypeFoldable for Unevaluated<'tcx>`, which is neater.
Because `TypeFoldable::try_fold_mir_const` exists, and even though
`visit_mir_const` isn't needed right now, the consistency makes the code
easier to understand.
There are two impls of the `Encoder` trait: `opaque::Encoder` and
`opaque::FileEncoder`. The former encodes into memory and is infallible, the
latter writes to file and is fallible.
Currently, standard `Result`/`?`/`unwrap` error handling is used, but this is a
bit verbose and has non-trivial cost, which is annoying given how rare failures
are (especially in the infallible `opaque::Encoder` case).
This commit changes how `Encoder` fallibility is handled. All the `emit_*`
methods are now infallible. `opaque::Encoder` requires no great changes for
this. `opaque::FileEncoder` now implements a delayed error handling strategy.
If a failure occurs, it records this via the `res` field, and all subsequent
encoding operations are skipped if `res` indicates an error has occurred. Once
encoding is complete, the new `finish` method is called, which returns a
`Result`. In other words, there is now a single `Result`-producing method
instead of many of them.
This has very little effect on how any file errors are reported if
`opaque::FileEncoder` has any failures.
Much of this commit is boring mechanical changes, removing `Result` return
values and `?` or `unwrap` from expressions. The more interesting parts are as
follows.
- serialize.rs: The `Encoder` trait gains an `Ok` associated type. The
`into_inner` method is changed into `finish`, which returns
`Result<Vec<u8>, !>`.
- opaque.rs: The `FileEncoder` adopts the delayed error handling
strategy. Its `Ok` type is a `usize`, returning the number of bytes
written, replacing previous uses of `FileEncoder::position`.
- Various methods that take an encoder now consume it, rather than being
passed a mutable reference, e.g. `serialize_query_result_cache`.
Fix precise field capture of univariant enums
When constructing a MIR from a THIR field expression, introduce an
additional downcast projection before accessing a field of an enum.
When rebasing a place builder on top of a captured place, account for
the fact that a single HIR enum field projection corresponds to two MIR
projection elements: a downcast element and a field element.
Fixes#95271.
Fixes#96299.
Fixes#96512.
Fixes#97378.
r? ``@nikomatsakis`` ``@arora-aman``
Rollup of 5 pull requests
Successful merges:
- #97058 (Various refactors to the incr comp workproduct handling)
- #97301 (Allow unstable items to be re-exported unstably without requiring the feature be enabled)
- #97738 (Fix ICEs from zsts within unsized types with non-zero offsets)
- #97771 (Remove SIGIO reference on Haiku)
- #97808 (Add some unstable target features for the wasm target codegen)
Failed merges:
r? `@ghost`
`@rustbot` modify labels: rollup
Allow unstable items to be re-exported unstably without requiring the feature be enabled
Closes#94972
The diagnostic may need some work still, and I haven't added a test yet
Various refactors to the incr comp workproduct handling
This is the result of me looking into adding support for having multiple object files for a single codegen unit to incr comp. This is necessary to support inline assembly in cg_clif without requiring partial linking which is not supported on Windows and seems to fail on macOS for some reason. Cg_clif uses an external assembler to handle inline asm and thus produces one object file with regular functions and one object file containing compiled inline asm for each codegen unit which uses inline asm. Current incr comp can't handle this. This PR doesn't yet add support for this, but it makes it easier to do so.
Add support for emitting functions with `coldcc` to LLVM
The eventual goal is to try using this for things like the internal panicking stuff, to see whether it helps.
Remove migrate borrowck mode
Closes#58781Closes#43234
# Stabilization proposal
This PR proposes the stabilization of `#![feature(nll)]` and the removal of `-Z borrowck`. Current borrow checking behavior of item bodies is currently done by first infering regions *lexically* and reporting any errors during HIR type checking. If there *are* any errors, then MIR borrowck (NLL) never occurs. If there *aren't* any errors, then MIR borrowck happens and any errors there would be reported. This PR removes the lexical region check of item bodies entirely and only uses MIR borrowck. Because MIR borrowck could never *not* be run for a compiled program, this should not break any programs. It does, however, change diagnostics significantly and allows a slightly larger set of programs to compile.
Tracking issue: #43234
RFC: https://github.com/rust-lang/rfcs/blob/master/text/2094-nll.md
Version: 1.63 (2022-06-30 => beta, 2022-08-11 => stable).
## Motivation
Over time, the Rust borrow checker has become "smarter" and thus allowed more programs to compile. There have been three different implementations: AST borrowck, MIR borrowck, and polonius (well, in progress). Additionally, there is the "lexical region resolver", which (roughly) solves the constraints generated through HIR typeck. It is not a full borrow checker, but does emit some errors.
The AST borrowck was the original implementation of the borrow checker and was part of the initially stabilized Rust 1.0. In mid 2017, work began to implement the current MIR borrow checker and that effort ompleted by the end of 2017, for the most part. During 2018, efforts were made to migrate away from the AST borrow checker to the MIR borrow checker - eventually culminating into "migrate" mode - where HIR typeck with lexical region resolving following by MIR borrow checking - being active by default in the 2018 edition.
In early 2019, migrate mode was turned on by default in the 2015 edition as well, but with MIR borrowck errors emitted as warnings. By late 2019, these warnings were upgraded to full errors. This was followed by the complete removal of the AST borrow checker.
In the period since, various errors emitted by the MIR borrow checker have been improved to the point that they are mostly the same or better than those emitted by the lexical region resolver.
While there do remain some degradations in errors (tracked under the [NLL-diagnostics tag](https://github.com/rust-lang/rust/issues?q=is%3Aopen+is%3Aissue+label%3ANLL-diagnostics), those are sufficiently small and rare enough that increased flexibility of MIR borrow check-only is now a worthwhile tradeoff.
## What is stabilized
As said previously, this does not fundamentally change the landscape of accepted programs. However, there are a [few](https://github.com/rust-lang/rust/issues?q=is%3Aopen+is%3Aissue+label%3ANLL-fixed-by-NLL) cases where programs can compile under `feature(nll)`, but not otherwise.
There are two notable patterns that are "fixed" by this stabilization. First, the `scoped_threads` feature, which is a continutation of a pre-1.0 API, can sometimes emit a [weird lifetime error](https://github.com/rust-lang/rust/issues/95527) without NLL. Second, actually seen in the standard library. In the `Extend` impl for `HashMap`, there is an implied bound of `K: 'a` that is available with NLL on but not without - this is utilized in the impl.
As mentioned before, there are a large number of diagnostic differences. Most of them are better, but some are worse. None are serious or happen often enough to need to block this PR. The biggest change is the loss of error code for a number of lifetime errors in favor of more general "lifetime may not live long enough" error. While this may *seem* bad, the former error codes were just attempts to somewhat-arbitrarily bin together lifetime errors of the same type; however, on paper, they end up being roughly the same with roughly the same kinds of solutions.
## What isn't stabilized
This PR does not completely remove the lexical region resolver. In the future, it may be possible to remove that (while still keeping HIR typeck) or to remove it together with HIR typeck.
## Tests
Many test outputs get updated by this PR. However, there are number of tests specifically geared towards NLL under `src/test/ui/nll`
## History
* On 2017-07-14, [tracking issue opened](https://github.com/rust-lang/rust/issues/43234)
* On 2017-07-20, [initial empty MIR pass added](https://github.com/rust-lang/rust/pull/43271)
* On 2017-08-29, [RFC opened](https://github.com/rust-lang/rfcs/pull/2094)
* On 2017-11-16, [Integrate MIR type-checker with NLL](https://github.com/rust-lang/rust/pull/45825)
* On 2017-12-20, [NLL feature complete](https://github.com/rust-lang/rust/pull/46862)
* On 2018-07-07, [Don't run AST borrowck on mir mode](https://github.com/rust-lang/rust/pull/52083)
* On 2018-07-27, [Add migrate mode](https://github.com/rust-lang/rust/pull/52681)
* On 2019-04-22, [Enable migrate mode on 2015 edition](https://github.com/rust-lang/rust/pull/59114)
* On 2019-08-26, [Don't downgrade errors on 2015 edition](https://github.com/rust-lang/rust/pull/64221)
* On 2019-08-27, [Remove AST borrowck](https://github.com/rust-lang/rust/pull/64790)
Rollup of 5 pull requests
Successful merges:
- #97312 (Compute lifetimes in scope at diagnostic time)
- #97495 (Add E0788 for improper #[no_coverage] usage)
- #97579 (Avoid creating `SmallVec`s in `global_llvm_features`)
- #97767 (interpret: do not claim UB until we looked more into variadic functions)
- #97787 (E0432: rust 2018 -> rust 2018 or later in --explain message)
Failed merges:
r? `@ghost`
`@rustbot` modify labels: rollup
interpret: better control over whether we read data with provenance
The resolution in https://github.com/rust-lang/unsafe-code-guidelines/issues/286 seems to be that when we load data at integer type, we implicitly strip provenance. So let's implement that in Miri at least for scalar loads. This makes use of the fact that `Scalar` layouts distinguish pointer-sized integers and pointers -- so I was expecting some wild bugs where layouts set this incorrectly, but so far that does not seem to happen.
This does not entirely implement the solution to https://github.com/rust-lang/unsafe-code-guidelines/issues/286; we still do the wrong thing for integers in larger types: we will `copy_op` them and then do validation, and validation will complain about the provenance. To fix that we need mutating validation; validation needs to strip the provenance rather than complaining about it. This is a larger undertaking (but will also help resolve https://github.com/rust-lang/miri/issues/845 since we can reset padding to `Uninit`).
The reason this is useful is that we can now implement `addr` as a `transmute` from a pointer to an integer, and actually get the desired behavior of stripping provenance without exposing it!
Compute lifetimes in scope at diagnostic time
The set of available lifetimes is currently computed during lifetime resolution on HIR. It is only used for one diagnostic.
In this PR, HIR lifetime resolution just reports whether elided lifetimes are well-defined at the place of use. The diagnostic code is responsible for building a list of lifetime names if elision is not allowed.
This will allow to remove lifetime resolution on HIR eventually.
Replace `&Vec<_>`s with `&[_]`s
It's generally preferable to use `&[_]` since it's one less indirection and it can be created from types other that `Vec`.
I've left `&Vec` in some locals where it doesn't really matter, in cases where `TypeFoldable` is expected (`TypeFoldable: Clone` so slice can't implement it) and in cases where it's `&TypeAliasThatIsActiallyVec`. Nothing important, really, I was just a little annoyed by `visit_generic_param_vec` :D
r? `@compiler-errors`
Iterate over `maybe_unused_trait_imports` when checking dead trait imports
Closes#96873
r? `@cjgillot`
Some questions, if you have time:
- Is there a way to shorten the `rustc_data_structures::fx::FxIndexSet` path in the query declaration? I wasn't sure where to put a `use`.
- Was returning by reference from the query the right choice here?
- How would I go about evaluating the importance of the `is_dummy()` call in `check_crate`? I don't see failing tests when I comment it out. Should I just try to determine whether dummy spans can ever be put into `maybe_unused_trait_imports`?
- Am I doing anything silly with the various ID types?
- Is that `let-else` with `unreachable!()` bad? (i.e is there a better idiom? Would `panic!("<explanation>")` be better?)
- If I want to evaluate the perf of using a `Vec` as mentioned in #96873, is the best way to use the CI or is it feasible locally?
Thanks :)
Remove all json handling from rustc_serialize
Json is now handled using serde_json. Where appropriate I have replaced json usage with binary serialization (rmeta files) or manual string formatting (emcc linker arg generation).
This allowed for removing and simplifying a lot of code, which hopefully results in faster serialization/deserialization and faster compiles of rustc itself.
Where sensible we now use serde. Metadata and incr cache serialization keeps using a heavily modified (compared to crates.io) rustc-serialize version that in the future could probably be extended with zero-copy deserialization or other perf tricks that serde can't support due to supporting more than one serialization format.
Note that I had to remove `-Zast-json` and `-Zast-json-noexpand` as the relevant AST types don't implement `serde::Serialize`.
Fixes#40177
See also https://github.com/rust-lang/compiler-team/issues/418
Compute `is_late_bound_map` query separately from lifetime resolution
This query is actually very simple, and is only useful for functions and method. It can be computed directly by fetching the HIR, with no need to embed it within the lifetime resolution visitor.
Based on https://github.com/rust-lang/rust/pull/96296
rewrite error handling for unresolved inference vars
Pretty much completely rewrites `fn emit_inference_failure_err`.
This new setup should hopefully be easier to extend and is already a lot better when looking for generic arguments.
Because this is a rewrite there are still some parts which are lacking, these are tracked in #94483 and will be fixed in later PRs.
r? `@estebank` `@petrochenkov`
On E0204 suggest missing type param bounds
```
error[E0204]: the trait `Copy` may not be implemented for this type
--> f42.rs:9:17
|
9 | #[derive(Debug, Copy, Clone)]
| ^^^^
10 | pub struct AABB<K>{
11 | pub loc: Vector2<K>,
| ------------------- this field does not implement `Copy`
12 | pub size: Vector2<K>
| -------------------- this field does not implement `Copy`
|
note: the `Copy` impl for `Vector2<K>` requires that `K: Debug`
--> f42.rs:11:5
|
11 | pub loc: Vector2<K>,
| ^^^^^^^^^^^^^^^^^^^
note: the `Copy` impl for `Vector2<K>` requires that `K: Debug`
--> f42.rs:12:5
|
12 | pub size: Vector2<K>
| ^^^^^^^^^^^^^^^^^^^^
= note: this error originates in the derive macro `Copy` (in Nightly builds, run with -Z macro-backtrace for more info)
help: consider restricting type parameter `K`
|
10 | pub struct AABB<K: Debug>{
| +++++++
```
Fix#89137.
```
error[E0204]: the trait `Copy` may not be implemented for this type
--> f42.rs:9:17
|
9 | #[derive(Debug, Copy, Clone)]
| ^^^^
10 | pub struct AABB<K>{
11 | pub loc: Vector2<K>,
| ------------------- this field does not implement `Copy`
12 | pub size: Vector2<K>
| -------------------- this field does not implement `Copy`
|
note: the `Copy` impl for `Vector2<K>` requires that `K: Debug`
--> f42.rs:11:5
|
11 | pub loc: Vector2<K>,
| ^^^^^^^^^^^^^^^^^^^
note: the `Copy` impl for `Vector2<K>` requires that `K: Debug`
--> f42.rs:12:5
|
12 | pub size: Vector2<K>
| ^^^^^^^^^^^^^^^^^^^^
= note: this error originates in the derive macro `Copy` (in Nightly builds, run with -Z macro-backtrace for more info)
help: consider restricting type parameter `K`
|
10 | pub struct AABB<K: Debug>{
| +++++++
```
Fix#89137.
Diagnose anonymous lifetimes errors more uniformly between async and regular fns
Async fns and regular fns are desugared differently. For the former, we create a generic parameter at HIR level. For the latter, we just create an anonymous region for typeck.
I plan to migrate regular fns to the async fn desugaring.
Before that, this PR attempts to merge the diagnostics for both cases.
r? ```@estebank```
Add validation layer for Derefer
_Follow up work to #96549#96116#95857 #95649_
This adds validation for Derefer making sure it is always the first projection.
r? rust-lang/mir-opt
Replace `#[default_method_body_is_const]` with `#[const_trait]`
pulled out of #96077
related issues: #67792 and #92158
cc `@fee1-dead`
This is groundwork to only allowing `impl const Trait` for traits that are marked with `#[const_trait]`. This is necessary to prevent adding a new default method from becoming a breaking change (as it could be a non-const fn).
Finish bumping stage0
It looks like the last time had left some remaining cfg's -- which made me think
that the stage0 bump was actually successful. This brings us to a released 1.62
beta though.
This now brings us to cfg-clean, with the exception of check-cfg-features in bootstrap;
I'd prefer to leave that for a separate PR at this time since it's likely to be more tricky.
cc https://github.com/rust-lang/rust/pull/97147#issuecomment-1132845061
r? `@pietroalbini`
Update to rebased rustc-rayon 0.4
In rayon-rs/rayon#938, miri uncovered a race in `rustc-rayon-core` that had already been fixed in the regular `rayon-core`. I have now rebased that fork onto the latest rayon branch, and published as 0.4. I also updated `indexmap` to bump the dependency.
`Cargo.lock` changes:
Updating indexmap v1.8.0 -> v1.8.2
Updating rayon v1.5.1 -> v1.5.3
Updating rayon-core v1.9.1 -> v1.9.3
Updating rustc-rayon v0.3.2 -> v0.4.0
Updating rustc-rayon-core v0.3.2 -> v0.4.1
Try to cache region_scope_tree as a query
This PR will attempt to restore `region_scope_tree` as a query so that caching works again. It seems that `region_scope_tree` could be re-computed for nested items after all, which could explain the performance regression introduced by #95563.
cc `@Mark-Simulacrum` `@pnkfelix` I will try to trigger a perf run here.
Split dead store elimination off dest prop
This splits off a part of #96451 . I've added this in as its own pass for now, so that it actually runs, can be tested, etc. In the dest prop PR, I'll stop invoking this as its own pass, so that it doesn't get invoked twice.
r? `@tmiasko`
Add suggestion for relaxing static lifetime bounds on dyn trait impls in NLL
This PR introduces suggestions for relaxing static lifetime bounds on impls of dyn trait items for NLL similar to what is already available in lexical region diagnostics.
Fixes https://github.com/rust-lang/rust/issues/95701
r? `@estebank`
{kind=link}
{kind=link}
{kind=link}