This only works if arrays are passed directly instead of array iterators
because we need to be sure that they have not been advanced before
Flatten does its size calculation.
Add Integer::log variants
_This is another attempt at landing https://github.com/rust-lang/rust/pull/70835, which was approved by the libs team but failed on Android tests through Bors. The text copied here is from the original issue. The only change made so far is the addition of non-`checked_` variants of the log methods._
_Tracking issue: #70887_
---
This implements `{log,log2,log10}` methods for all integer types. The implementation was provided by `@substack` for use in the stdlib.
_Note: I'm not big on math, so this PR is a best effort written with limited knowledge. It's likely I'll be getting things wrong, but happy to learn and correct. Please bare with me._
## Motivation
Calculating the logarithm of a number is a generally useful operation. Currently the stdlib only provides implementations for floats, which means that if we want to calculate the logarithm for an integer we have to cast it to a float and then back to an int.
> would be nice if there was an integer log2 instead of having to either use the f32 version or leading_zeros() which i have to verify the results of every time to be sure
_— [`@substack,` 2020-03-08](https://twitter.com/substack/status/1236445105197727744)_
At higher numbers converting from an integer to a float we also risk overflows. This means that Rust currently only provides log operations for a limited set of integers.
The process of doing log operations by converting between floats and integers is also prone to rounding errors. In the following example we're trying to calculate `base10` for an integer. We might try and calculate the `base2` for the values, and attempt [a base swap](https://www.rapidtables.com/math/algebra/Logarithm.html#log-rules) to arrive at `base10`. However because we're performing intermediate rounding we arrive at the wrong result:
```rust
// log10(900) = ~2.95 = 2
dbg!(900f32.log10() as u64);
// log base change rule: logb(x) = logc(x) / logc(b)
// log2(900) / log2(10) = 9/3 = 3
dbg!((900f32.log2() as u64) / (10f32.log2() as u64));
```
_[playground](https://play.rust-lang.org/?version=stable&mode=debug&edition=2018&gist=6bd6c68b3539e400f9ca4fdc6fc2eed0)_
This is somewhat nuanced as a lot of the time it'll work well, but in real world code this could lead to some hard to track bugs. By providing correct log implementations directly on integers we can help prevent errors around this.
## Implementation notes
I checked whether LLVM intrinsics existed before implementing this, and none exist yet. ~~Also I couldn't really find a better way to write the `ilog` function. One option would be to make it a private method on the number, but I didn't see any precedent for that. I also didn't know where to best place the tests, so I added them to the bottom of the file. Even though they might seem like quite a lot they take no time to execute.~~
## References
- [Log rules](https://www.rapidtables.com/math/algebra/Logarithm.html#log-rules)
- [Rounding error playground](https://play.rust-lang.org/?version=stable&mode=debug&edition=2018&gist=6bd6c68b3539e400f9ca4fdc6fc2eed0)
- [substack's tweet asking about integer log2 in the stdlib](https://twitter.com/substack/status/1236445105197727744)
- [Integer Logarithm, A. Jaffer 2008](https://people.csail.mit.edu/jaffer/III/ilog.pdf)
core: add unstable no_fp_fmt_parse to disable float formatting code
In some projects (e.g. kernel), floating point is forbidden. They can disable
hardware floating point support and use `+soft-float` to avoid fp instructions
from being generated, but as libcore contains the formatting code for `f32`
and `f64`, some fp intrinsics are depended. One could define stubs for these
intrinsics that just panic [1], but it means that if any formatting functions
are accidentally used, mistake can only be caught during the runtime rather
than during compile-time or link-time, and they consume a lot of space without
LTO.
This patch provides an unstable cfg `no_fp_fmt_parse` to disable these.
A panicking stub is still provided for the `Debug` implementation (unfortunately)
because there are some SIMD types that use `#[derive(Debug)]`.
[1]: https://lkml.org/lkml/2021/4/14/1028
* {:.PREC?} already had legitimately useful behavior (recursive formatting of structs using
fixed precision for floats) and I suspect that changes to the output there would be unwelcome.
(besides, precision introduces sinister edge cases where a number can be rounded up to one
of the thresholds)
Thus, the new behavior of Debug is, "dynamically switch to exponential, but only if there's
no precision."
* This could not be implemented in terms of float_to_decimal_common without repeating the branch
on precision, so 'float_to_general_debug' is a new function. The name is '_debug' instead of
'_common' because the considerations in the previous bullet make this logic pretty specific
to Debug.
* 'float_to_decimal_common' is now only used by Display, so I inlined the min_precision argument
and renamed the function accordingly.
This was unsound since a panic in a.next_back() would result in the
length not being updated which would then lead to the same element
being revisited in the side-effect preserving code.
to_digit simplification (less jumps)
I just realised we might be able to make use of the fact that changing case in ascii is easy to help simplify to_digit some more.
It looks a bit cleaner and it looks like it's less jumps and there's less instructions in the generated assembly:
https://godbolt.org/z/84Erh5dhz
The benchmarks don't really tell me much. Maybe a slight improvement on the var radix.
Before:
```
test char::methods::bench_to_digit_radix_10 ... bench: 53,819 ns/iter (+/- 8,314)
test char::methods::bench_to_digit_radix_16 ... bench: 57,265 ns/iter (+/- 10,730)
test char::methods::bench_to_digit_radix_2 ... bench: 55,077 ns/iter (+/- 5,431)
test char::methods::bench_to_digit_radix_36 ... bench: 56,549 ns/iter (+/- 3,248)
test char::methods::bench_to_digit_radix_var ... bench: 43,848 ns/iter (+/- 3,189)
test char::methods::bench_to_digit_radix_10 ... bench: 51,707 ns/iter (+/- 10,946)
test char::methods::bench_to_digit_radix_16 ... bench: 52,835 ns/iter (+/- 2,689)
test char::methods::bench_to_digit_radix_2 ... bench: 51,012 ns/iter (+/- 2,746)
test char::methods::bench_to_digit_radix_36 ... bench: 53,210 ns/iter (+/- 8,645)
test char::methods::bench_to_digit_radix_var ... bench: 40,386 ns/iter (+/- 4,711)
test char::methods::bench_to_digit_radix_10 ... bench: 54,088 ns/iter (+/- 5,677)
test char::methods::bench_to_digit_radix_16 ... bench: 55,972 ns/iter (+/- 17,229)
test char::methods::bench_to_digit_radix_2 ... bench: 52,083 ns/iter (+/- 2,425)
test char::methods::bench_to_digit_radix_36 ... bench: 54,132 ns/iter (+/- 1,548)
test char::methods::bench_to_digit_radix_var ... bench: 41,250 ns/iter (+/- 5,299)
```
After:
```
test char::methods::bench_to_digit_radix_10 ... bench: 48,907 ns/iter (+/- 19,449)
test char::methods::bench_to_digit_radix_16 ... bench: 52,673 ns/iter (+/- 8,122)
test char::methods::bench_to_digit_radix_2 ... bench: 48,509 ns/iter (+/- 2,885)
test char::methods::bench_to_digit_radix_36 ... bench: 50,526 ns/iter (+/- 4,610)
test char::methods::bench_to_digit_radix_var ... bench: 38,618 ns/iter (+/- 3,180)
test char::methods::bench_to_digit_radix_10 ... bench: 54,202 ns/iter (+/- 6,994)
test char::methods::bench_to_digit_radix_16 ... bench: 56,585 ns/iter (+/- 8,448)
test char::methods::bench_to_digit_radix_2 ... bench: 50,548 ns/iter (+/- 1,674)
test char::methods::bench_to_digit_radix_36 ... bench: 52,749 ns/iter (+/- 2,576)
test char::methods::bench_to_digit_radix_var ... bench: 40,215 ns/iter (+/- 3,327)
test char::methods::bench_to_digit_radix_10 ... bench: 50,233 ns/iter (+/- 22,272)
test char::methods::bench_to_digit_radix_16 ... bench: 50,841 ns/iter (+/- 19,981)
test char::methods::bench_to_digit_radix_2 ... bench: 50,386 ns/iter (+/- 4,555)
test char::methods::bench_to_digit_radix_36 ... bench: 52,369 ns/iter (+/- 2,737)
test char::methods::bench_to_digit_radix_var ... bench: 40,417 ns/iter (+/- 2,766)
```
I removed the likely as it resulted in a few less instructions. (It's not been in there long - I added it in the last to_digit iteration).
Make copy/copy_nonoverlapping fn's again
Make copy/copy_nonoverlapping fn's again, rather than intrinsics.
This a short-term change to address issue #84297.
It effectively reverts PRs #81167#81238 (and part of #82967), #83091, and parts of #79684.
Update standard library for IntoIterator implementation of arrays
This PR partially resolves issue #84513 of updating the standard library part.
I haven't found any remaining doctest examples which are using iterators over e.g. &i32 instead of just i32 in the standard library. Can anyone point me to them if there's remaining any?
Thanks!
r? ```@m-ou-se```
While stdlib implementations of the unchecked methods require unchecked
math, there is no reason to gate it behind this for external users. The
reasoning for a separate `step_trait_ext` feature is unclear, and as
such has been merged as well.
Implement indexing slices with pairs of core::ops::Bound<usize>
Closes#49976.
I am not sure about code duplication between `check_range` and `into_maybe_range`. Should be former implemented in terms of the latter? Also this PR doesn't address code duplication between `impl SliceIndex for Range*`.
Format `Struct { .. }` on one line even with `{:#?}`.
The result of `debug_struct("A").finish_non_exhaustive()` before this change:
```
A {
..
}
```
And after this change:
```
A { .. }
```
If there's any fields, the result stays unchanged:
```
A {
field: value,
..
}
Stabilize `peekable_peek_mut`
Resolves#78302. Also adds some documentation on `std::iter::Iterator::peekable()` regarding the new method.
The feature was added in #77491 in Nov' 20, which is recently, but the feature seems reasonably small. Never did a stabilization-pr, excuse my ignorance if there is a protocol I'm not aware of.
Stabilize cmp_min_max_by
I would like to propose cmp::{min_by, min_by_key, max_by, max_by_key}
for stabilization.
These are relatively simple and seemingly uncontroversial functions and
have been unchanged in unstable for a while now.
Closes: #64460
I would like to propose cmp::{min_by, min_by_key, max_by, max_by_key}
for stabilization.
These are relatively simple and seemingly uncontroversial functions and
have been unchanged in unstable for a while now.
Add IEEE 754 compliant fmt/parse of -0, infinity, NaN
This pull request improves the Rust float formatting/parsing libraries to comply with IEEE 754's formatting expectations around certain special values, namely signed zero, the infinities, and NaN. It also adds IEEE 754 compliance tests that, while less stringent in certain places than many of the existing flt2dec/dec2flt capability tests, are intended to serve as the beginning of a roadmap to future compliance with the standard. Some relevant documentation is also adjusted with clarifying remarks.
This PR follows from discussion in https://github.com/rust-lang/rfcs/issues/1074, and closes#24623.
The most controversial change here is likely to be that -0 is now printed as -0. Allow me to explain: While there appears to be community support for an opt-in toggle of printing floats as if they exist in the naively expected domain of numbers, i.e. not the extended reals (where floats live), IEEE 754-2019 is clear that a float converted to a string should be capable of being transformed into the original floating point bit-pattern when it satisfies certain conditions (namely, when it is an actual numeric value i.e. not a NaN and the original and destination float width are the same). -0 is given special attention here as a value that should have its sign preserved. In addition, the vast majority of other programming languages not only output `-0` but output `-0.0` here.
While IEEE 754 offers a broad leeway in how to handle producing what it calls a "decimal character sequence", it is clear that the operations a language provides should be capable of round tripping, and it is confusing to advertise the f32 and f64 types as binary32 and binary64 yet have the most basic way of producing a string and then reading it back into a floating point number be non-conformant with the standard. Further, existing documentation suggested that e.g. -0 would be printed with -0 regardless of the presence of the `+` fmt character, but it prints "+0" instead if given such (which was what led to the opening of #24623).
There are other parsing and formatting issues for floating point numbers which prevent Rust from complying with the standard, as well as other well-documented challenges on the arithmetic level, but I hope that this can be the beginning of motion towards solving those challenges.
Add Result::into_err where the Ok variant is the never type
Equivalent of #66045 but for the inverse situation where `T: Into<!>` rather than `E: Into<!>`.
I'm using the same feature gate name. I can't see why one of these methods would be OK to stabilize but not the other.
Tracking issue: #61695
Remove Option::{unwrap_none, expect_none}.
This removes `Option::unwrap_none` and `Option::expect_none` since we're not going to stabilize them, see https://github.com/rust-lang/rust/issues/62633.
Closes#62633
This commit removes the previous mechanism of differentiating
between "Debug" and "Display" formattings for the sign of -0 so as
to comply with the IEEE 754 standard's requirements on external
character sequences preserving various attributes of a floating
point representation.
In addition, numerous tests are fixed.
Stabilize `unsafe_op_in_unsafe_fn` lint
This makes it possible to override the level of the `unsafe_op_in_unsafe_fn`, as proposed in https://github.com/rust-lang/rust/issues/71668#issuecomment-729770896.
Tracking issue: #71668
r? ```@nikomatsakis``` cc ```@SimonSapin``` ```@RalfJung```
# Stabilization report
This is a stabilization report for `#![feature(unsafe_block_in_unsafe_fn)]`.
## Summary
Currently, the body of unsafe functions is an unsafe block, i.e. you can perform unsafe operations inside.
The `unsafe_op_in_unsafe_fn` lint, stabilized here, can be used to change this behavior, so performing unsafe operations in unsafe functions requires an unsafe block.
For now, the lint is allow-by-default, which means that this PR does not change anything without overriding the lint level.
For more information, see [RFC 2585](https://github.com/rust-lang/rfcs/blob/master/text/2585-unsafe-block-in-unsafe-fn.md)
### Example
```rust
// An `unsafe fn` for demonstration purposes.
// Calling this is an unsafe operation.
unsafe fn unsf() {}
// #[allow(unsafe_op_in_unsafe_fn)] by default,
// the behavior of `unsafe fn` is unchanged
unsafe fn allowed() {
// Here, no `unsafe` block is needed to
// perform unsafe operations...
unsf();
// ...and any `unsafe` block is considered
// unused and is warned on by the compiler.
unsafe {
unsf();
}
}
#[warn(unsafe_op_in_unsafe_fn)]
unsafe fn warned() {
// Removing this `unsafe` block will
// cause the compiler to emit a warning.
// (Also, no "unused unsafe" warning will be emitted here.)
unsafe {
unsf();
}
}
#[deny(unsafe_op_in_unsafe_fn)]
unsafe fn denied() {
// Removing this `unsafe` block will
// cause a compilation error.
// (Also, no "unused unsafe" warning will be emitted here.)
unsafe {
unsf();
}
}
```
Prevent specialized ZipImpl from calling `__iterator_get_unchecked` twice with the same index
Fixes#82291
It's open for review, but conflicts with #82289, wait before merging. The conflict involves only the new test, so it should be rather trivial to fix.
Improve slice.binary_search_by()'s best-case performance to O(1)
This PR aimed to improve the [slice.binary_search_by()](https://doc.rust-lang.org/std/primitive.slice.html#method.binary_search_by)'s best-case performance to O(1).
# Noticed
I don't know why the docs of `binary_search_by` said `"If there are multiple matches, then any one of the matches could be returned."`, but the implementation isn't the same thing. Actually, it returns the **last one** if multiple matches found.
Then we got two options:
## If returns the last one is the correct or desired result
Then I can rectify the docs and revert my changes.
## If the docs are correct or desired result
Then my changes can be merged after fully reviewed.
However, if my PR gets merged, another issue raised: this could be a **breaking change** since if multiple matches found, the returning order no longer the last one instead of it could be any one.
For example:
```rust
let mut s = vec![0, 1, 1, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55];
let num = 1;
let idx = s.binary_search(&num);
s.insert(idx, 2);
// Old implementations
assert_eq!(s, [0, 1, 1, 1, 1, 2, 2, 3, 5, 8, 13, 21, 34, 42, 55]);
// New implementations
assert_eq!(s, [0, 1, 1, 1, 2, 1, 2, 3, 5, 8, 13, 21, 34, 42, 55]);
```
# Benchmarking
**Old implementations**
```sh
$ ./x.py bench --stage 1 library/libcore
test slice::binary_search_l1 ... bench: 59 ns/iter (+/- 4)
test slice::binary_search_l1_with_dups ... bench: 59 ns/iter (+/- 3)
test slice::binary_search_l2 ... bench: 76 ns/iter (+/- 5)
test slice::binary_search_l2_with_dups ... bench: 77 ns/iter (+/- 17)
test slice::binary_search_l3 ... bench: 183 ns/iter (+/- 23)
test slice::binary_search_l3_with_dups ... bench: 185 ns/iter (+/- 19)
```
**New implementations (1)**
Implemented by this PR.
```rust
if cmp == Equal {
return Ok(mid);
} else if cmp == Less {
base = mid
}
```
```sh
$ ./x.py bench --stage 1 library/libcore
test slice::binary_search_l1 ... bench: 58 ns/iter (+/- 2)
test slice::binary_search_l1_with_dups ... bench: 37 ns/iter (+/- 4)
test slice::binary_search_l2 ... bench: 76 ns/iter (+/- 3)
test slice::binary_search_l2_with_dups ... bench: 57 ns/iter (+/- 6)
test slice::binary_search_l3 ... bench: 200 ns/iter (+/- 30)
test slice::binary_search_l3_with_dups ... bench: 157 ns/iter (+/- 6)
$ ./x.py bench --stage 1 library/libcore
test slice::binary_search_l1 ... bench: 59 ns/iter (+/- 8)
test slice::binary_search_l1_with_dups ... bench: 37 ns/iter (+/- 2)
test slice::binary_search_l2 ... bench: 77 ns/iter (+/- 2)
test slice::binary_search_l2_with_dups ... bench: 57 ns/iter (+/- 2)
test slice::binary_search_l3 ... bench: 198 ns/iter (+/- 21)
test slice::binary_search_l3_with_dups ... bench: 158 ns/iter (+/- 11)
```
**New implementations (2)**
Suggested by `@nbdd0121` in [comment](https://github.com/rust-lang/rust/pull/74024#issuecomment-665430239).
```rust
base = if cmp == Greater { base } else { mid };
if cmp == Equal { break }
```
```sh
$ ./x.py bench --stage 1 library/libcore
test slice::binary_search_l1 ... bench: 59 ns/iter (+/- 7)
test slice::binary_search_l1_with_dups ... bench: 37 ns/iter (+/- 5)
test slice::binary_search_l2 ... bench: 75 ns/iter (+/- 3)
test slice::binary_search_l2_with_dups ... bench: 56 ns/iter (+/- 3)
test slice::binary_search_l3 ... bench: 195 ns/iter (+/- 15)
test slice::binary_search_l3_with_dups ... bench: 151 ns/iter (+/- 7)
$ ./x.py bench --stage 1 library/libcore
test slice::binary_search_l1 ... bench: 57 ns/iter (+/- 2)
test slice::binary_search_l1_with_dups ... bench: 38 ns/iter (+/- 2)
test slice::binary_search_l2 ... bench: 77 ns/iter (+/- 11)
test slice::binary_search_l2_with_dups ... bench: 57 ns/iter (+/- 4)
test slice::binary_search_l3 ... bench: 194 ns/iter (+/- 15)
test slice::binary_search_l3_with_dups ... bench: 151 ns/iter (+/- 18)
```
I run some benchmarking testings against on two implementations. The new implementation has a lot of improvement in duplicates cases, while in `binary_search_l3` case, it's a little bit slower than the old one.
Implement NOOP_METHOD_CALL lint
Implements the beginnings of https://github.com/rust-lang/lang-team/issues/67 - a lint for detecting noop method calls (e.g, calling `<&T as Clone>::clone()` when `T: !Clone`).
This PR does not fully realize the vision and has a few limitations that need to be addressed either before merging or in subsequent PRs:
* [ ] No UFCS support
* [ ] The warning message is pretty plain
* [ ] Doesn't work for `ToOwned`
The implementation uses [`Instance::resolve`](https://doc.rust-lang.org/nightly/nightly-rustc/rustc_middle/ty/instance/struct.Instance.html#method.resolve) which is normally later in the compiler. It seems that there are some invariants that this function relies on that we try our best to respect. For instance, it expects substitutions to have happened, which haven't yet performed, but we check first for `needs_subst` to ensure we're dealing with a monomorphic type.
Thank you to ```@davidtwco,``` ```@Aaron1011,``` and ```@wesleywiser``` for helping me at various points through out this PR ❤️.
Make ptr::write const
~~The code in this PR as of right now is not much more than an experiment.~~
~~This should, if I am not mistaken, in theory compile and pass the tests once the bootstraping compiler is updated. Thus the PR is blocked on that which should happen some time after the February the 9th. Also we might want to wait for #79989 to avoid regressing performance due to using `mem::forget` over `intrinsics::forget`~~.
Add tests for Atomic*::fetch_{min,max}
This ensures that all atomic operations except for fences are tested. This has been useful to test my work on using atomic instructions for atomic operations in cg_clif instead of a global lock.
Implement RFC 2580: Pointer metadata & VTable
RFC: https://github.com/rust-lang/rfcs/pull/2580
~~Before merging this PR:~~
* [x] Wait for the end of the RFC’s [FCP to merge](https://github.com/rust-lang/rfcs/pull/2580#issuecomment-759145278).
* [x] Open a tracking issue: https://github.com/rust-lang/rust/issues/81513
* [x] Update `#[unstable]` attributes in the PR with the tracking issue number
----
This PR extends the language with a new lang item for the `Pointee` trait which is special-cased in trait resolution to implement it for all types. Even in generic contexts, parameters can be assumed to implement it without a corresponding bound.
For this I mostly imitated what the compiler was already doing for the `DiscriminantKind` trait. I’m very unfamiliar with compiler internals, so careful review is appreciated.
This PR also extends the standard library with new unstable APIs in `core::ptr` and `std::ptr`:
```rust
pub trait Pointee {
/// One of `()`, `usize`, or `DynMetadata<dyn SomeTrait>`
type Metadata: Copy + Send + Sync + Ord + Hash + Unpin;
}
pub trait Thin = Pointee<Metadata = ()>;
pub const fn metadata<T: ?Sized>(ptr: *const T) -> <T as Pointee>::Metadata {}
pub const fn from_raw_parts<T: ?Sized>(*const (), <T as Pointee>::Metadata) -> *const T {}
pub const fn from_raw_parts_mut<T: ?Sized>(*mut (),<T as Pointee>::Metadata) -> *mut T {}
impl<T: ?Sized> NonNull<T> {
pub const fn from_raw_parts(NonNull<()>, <T as Pointee>::Metadata) -> NonNull<T> {}
/// Convenience for `(ptr.cast(), metadata(ptr))`
pub const fn to_raw_parts(self) -> (NonNull<()>, <T as Pointee>::Metadata) {}
}
impl<T: ?Sized> *const T {
pub const fn to_raw_parts(self) -> (*const (), <T as Pointee>::Metadata) {}
}
impl<T: ?Sized> *mut T {
pub const fn to_raw_parts(self) -> (*mut (), <T as Pointee>::Metadata) {}
}
/// `<dyn SomeTrait as Pointee>::Metadata == DynMetadata<dyn SomeTrait>`
pub struct DynMetadata<Dyn: ?Sized> {
// Private pointer to vtable
}
impl<Dyn: ?Sized> DynMetadata<Dyn> {
pub fn size_of(self) -> usize {}
pub fn align_of(self) -> usize {}
pub fn layout(self) -> crate::alloc::Layout {}
}
unsafe impl<Dyn: ?Sized> Send for DynMetadata<Dyn> {}
unsafe impl<Dyn: ?Sized> Sync for DynMetadata<Dyn> {}
impl<Dyn: ?Sized> Debug for DynMetadata<Dyn> {}
impl<Dyn: ?Sized> Unpin for DynMetadata<Dyn> {}
impl<Dyn: ?Sized> Copy for DynMetadata<Dyn> {}
impl<Dyn: ?Sized> Clone for DynMetadata<Dyn> {}
impl<Dyn: ?Sized> Eq for DynMetadata<Dyn> {}
impl<Dyn: ?Sized> PartialEq for DynMetadata<Dyn> {}
impl<Dyn: ?Sized> Ord for DynMetadata<Dyn> {}
impl<Dyn: ?Sized> PartialOrd for DynMetadata<Dyn> {}
impl<Dyn: ?Sized> Hash for DynMetadata<Dyn> {}
```
API differences from the RFC, in areas noted as unresolved questions in the RFC:
* Module-level functions instead of associated `from_raw_parts` functions on `*const T` and `*mut T`, following the precedent of `null`, `slice_from_raw_parts`, etc.
* Added `to_raw_parts`
The use of module-level functions instead of associated functions
on `<*const T>` or `<*mut T>` follows the precedent of
`ptr::slice_from_raw_parts` and `ptr::slice_from_raw_parts_mut`.
Stabilize by-value `[T; N]` iterator `core::array::IntoIter`
Tracking issue: https://github.com/rust-lang/rust/issues/65798
This is unblocked now that `min_const_generics` has been stabilized in https://github.com/rust-lang/rust/pull/79135.
This PR does *not* include the corresponding `IntoIterator` impl, which is https://github.com/rust-lang/rust/pull/65819. Instead, an iterator can be constructed through the `new` method.
`new` would become unnecessary when `IntoIterator` is implemented and might be deprecated then, although it will stay stable.
Add `unwrap_unchecked()` methods for `Option` and `Result`
In particular:
- `unwrap_unchecked()` for `Option`.
- `unwrap_unchecked()` and `unwrap_err_unchecked()` for `Result`.
These complement other `*_unchecked()` methods in `core` etc.
Currently there are a couple of places it may be used inside rustc (`LinkedList`, `BTree`). It is also easy to find other repositories with similar functionality.
Fixes#48278.
TrustedRandomAaccess specialization composes incorrectly for nested iter::Zips
I found this while working on improvements for TRA.
After partially consuming a Zip adapter and then wrapping it into another Zip where the adapters use their `TrustedRandomAccess` specializations leads to the outer adapter returning elements which should have already been consumed.
If the optimizer gets tripped up by the addition this might affect performance for chained `zip()` iterators even when the inner one is not partially advanced but it would require more extensive fixes to `TrustedRandomAccess` to communicate those offsets earlier.
Included test fails on nightly, [playground link](https://play.rust-lang.org/?version=nightly&mode=debug&edition=2018&gist=24fa1edf8a104ff31f5a24830593b01f)
Add Iterator::intersperse_with
This is a follow-up to #79479, tracking in #79524, as discussed https://github.com/rust-lang/rust/pull/79479#issuecomment-752671731.
~~Note that I had to manually implement `Clone` and `Debug` because `derive` insists on placing a `Clone`-bound on the struct-definition, which is too narrow. There is a long-standing issue # for this somewhere around here :-)~~
Also, note that I refactored the guts of `Intersperse` into private functions and re-used them in `IntersperseWith`, so I also went light on duplicating all the tests.
If this is suitable to be merged, the tracking issue should be updated, since it only mentions `intersperse`.
Happy New Year!
r? ``@m-ou-se``
These tests invoke the various op traits using all accepted types they
are implemented for as well as for references to those types.
This fixes#49660 and ensures the following implementations exist:
* `Add`, `Sub`, `Mul`, `Div`, `Rem`
* `T op T`, `T op &T`, `&T op T` and `&T op &T`
* for all integer and floating point types
* `AddAssign`, `SubAssign`, `MulAssign`, `DivAssign`, `RemAssign`
* `&mut T op T` and `&mut T op &T`
* for all integer and floating point types
* `Neg`
* `op T` and `op &T`
* for all signed integer and floating point types
* `Not`
* `op T` and `op &T`
* for `bool`
* `BitAnd`, `BitOr`, `BitXor`
* `T op T`, `T op &T`, `&T op T` and `&T op &T`
* for all integer types and bool
* `BitAndAssign`, `BitOrAssign`, `BitXorAssign`
* `&mut T op T` and `&mut T op &T`
* for all integer types and bool
* `Shl`, `Shr`
* `L op R`, `L op &R`, `&L op R` and `&L op &R`
* for all pairs of integer types
* `ShlAssign`, `ShrAssign`
* `&mut L op R`, `&mut L op &R`
* for all pairs of integer types
In particular:
- `unwrap_unchecked()` for `Option`.
- `unwrap_unchecked()` and `unwrap_err_unchecked()` for `Result`.
These complement other `*_unchecked()` methods in `core` etc.
Currently there are a couple of places it may be used inside rustc
(`LinkedList`, `BTree`). It is also easy to find other repositories
with similar functionality.
Fixes#48278.
Signed-off-by: Miguel Ojeda <ojeda@kernel.org>
After partially consuming a Zip adapter and then wrapping it into
another Zip where the adapters use their TrustedRandomAccess specializations
leads to the outer adapter returning elements which should have already been
consumed.
The return of the GroupBy and GroupByMut iterators on slice
According to https://github.com/rust-lang/rfcs/pull/2477#issuecomment-742034372, I am opening this PR again, this time I implemented it in safe Rust only, it is therefore much easier to read and is completely safe.
This PR proposes to add two new methods to the slice, the `group_by` and `group_by_mut`. These two methods provide a way to iterate over non-overlapping sub-slices of a base slice that are separated by the predicate given by the user (e.g. `Partial::eq`, `|a, b| a.abs() < b.abs()`).
```rust
let slice = &[1, 1, 1, 3, 3, 2, 2, 2];
let mut iter = slice.group_by(|a, b| a == b);
assert_eq!(iter.next(), Some(&[1, 1, 1][..]));
assert_eq!(iter.next(), Some(&[3, 3][..]));
assert_eq!(iter.next(), Some(&[2, 2, 2][..]));
assert_eq!(iter.next(), None);
```
[An RFC](https://github.com/rust-lang/rfcs/pull/2477) was open 2 years ago but wasn't necessary.
Rollup of 9 pull requests
Successful merges:
- #78934 (refactor: removing library/alloc/src/vec/mod.rs ignore-tidy-filelength)
- #79479 (Add `Iterator::intersperse`)
- #80128 (Edit rustc_ast::ast::FieldPat docs)
- #80424 (Don't give an error when creating a file for the first time)
- #80458 (Some Promotion Refactoring)
- #80488 (Do not create dangling &T in Weak<T>::drop)
- #80491 (Miri: make size/align_of_val work for dangling raw ptrs)
- #80495 (Rename kw::Invalid -> kw::Empty)
- #80513 (Add regression test for #80062)
Failed merges:
r? `@ghost`
`@rustbot` modify labels: rollup
Add `impl Div<NonZeroU{0}> for u{0}` which cannot panic
Dividing an unsigned int by a `NonZeroUxx` requires a user to write (for example, in [this SO question](https://stackoverflow.com/questions/64855738/how-to-inform-the-optimizer-that-nonzerou32get-will-never-return-zero)):
```
pub fn safe_div(x: u32, y: std::num::NonZeroU32) -> u32 {
x / y.get()
}
```
which generates a panicking-checked-div [assembly](https://godbolt.org/#g:!((g:!((g:!((h:codeEditor,i:(fontScale:14,j:1,lang:rust,selection:(endColumn:2,endLineNumber:6,positionColumn:2,positionLineNumber:6,selectionStartColumn:2,selectionStartLineNumber:6,startColumn:2,startLineNumber:6),source:%27pub+fn+div(x:+u32,+y:+u32)+-%3E+u32+%7B%0A++++x+/+y%0A%7D%0Apub+fn+safe_div(x:+u32,+y:+std::num::NonZeroU32)+-%3E+u32+%7B%0A++++x+/+y.get()+//+an+unchecked+division+expected%0A%7D%27),l:%275%27,n:%270%27,o:%27Rust+source+%231%27,t:%270%27)),k:50,l:%274%27,n:%270%27,o:%27%27,s:0,t:%270%27),(g:!((h:compiler,i:(compiler:r1470,filters:(b:%270%27,binary:%271%27,commentOnly:%270%27,demangle:%270%27,directives:%270%27,execute:%271%27,intel:%270%27,libraryCode:%271%27,trim:%271%27),fontScale:14,j:1,lang:rust,libs:!(),options:%27-O%27,selection:(endColumn:1,endLineNumber:1,positionColumn:1,positionLineNumber:1,selectionStartColumn:1,selectionStartLineNumber:1,startColumn:1,startLineNumber:1),source:1),l:%275%27,n:%270%27,o:%27rustc+1.47.0+(Editor+%231,+Compiler+%231)+Rust%27,t:%270%27)),k:50,l:%274%27,n:%270%27,o:%27%27,s:0,t:%270%27)),l:%272%27,n:%270%27,o:%27%27,t:%270%27)),version:4).
Avoiding the `panic` currently requires `unsafe` code.
This PR adds an `impl Div<NonZeroU{0}> for u{0}` (and `impl Rem<NonZeroU{0}> for u{0}`) which calls the `unchecked_div` (and `unchecked_rem`) intrinsic without any additional checks,
making the following code compile:
```
pub fn safe_div(x: u32, y: std::num::NonZeroU32) -> u32 {
x / y
}
pub fn safe_rem(x: u32, y: std::num::NonZeroU32) -> u32 {
x % y
}
```
The doc is set to match the regular div impl [docs](https://doc.rust-lang.org/beta/src/core/ops/arith.rs.html#460).
I've marked these as stable because (as I understand it) trait impls are automatically stable. I'm happy to change it to unstable if needed.
Following `@dtolnay` template from a similar issue:
this adds the following **stable** impls, which rely on dividing unsigned integers by nonzero integers being well defined and previously would have involved unsafe code to encode that knowledge:
```
impl Div<NonZeroU8> for u8 {
type Output = u8;
}
impl Rem<NonZeroU8> for u8 {
type Output = u8;
}
```
and equivalent for u16, u32, u64, u128, usize, but **not** for i8, i16, i32, i64, i128, isize (since -1/MIN is undefined).
r? `@dtolnay`
Part of #68490.
Care has been taken to leave the old consts where appropriate, for testing backcompat regressions, module shadowing, etc. The intrinsics docs were accidentally referring to some methods on f64 as std::f64, which I changed due to being contrary with how we normally disambiguate the shadow module from the primitive. In one other place I changed std::u8 to std::ops since it was just testing path handling in macros.
For places which have legitimate uses of the old consts, deprecated attributes have been optimistically inserted. Although currently unnecessary, they exist to emphasize to any future deprecation effort the necessity of these specific symbols and prevent them from being accidentally removed.
Add lint for panic!("{}")
This adds a lint that warns about `panic!("{}")`.
`panic!(msg)` invocations with a single argument use their argument as panic payload literally, without using it as a format string. The same holds for `assert!(expr, msg)`.
This lints checks if `msg` is a string literal (after expansion), and warns in case it contained braces. It suggests to insert `"{}", ` to use the message literally, or to add arguments to use it as a format string.
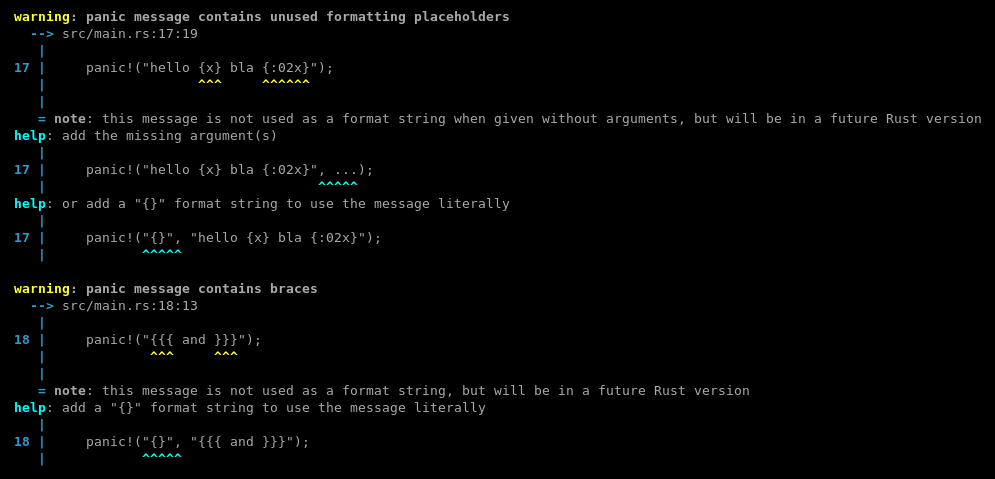
This lint is also a good starting point for adding warnings about `panic!(not_a_string)` later, once [`panic_any()`](https://github.com/rust-lang/rust/pull/74622) becomes a stable alternative.
add trailing_zeros and leading_zeros to non zero types
as a way towards being able to use the optimized intrinsics ctlz_nonzero and cttz_nonzero from stable.
have not crated any tracking issue if this is not a solution that is wanted
Test structural matching for all range types
As of #70166 all range types (`core::ops::Range` etc.) can be structurally matched upon, and by extension used in const generics. In reference to the fact that this is a publicly observable property of these types, and thus falls under the Rust stability guarantees of the standard library, a regression test was added in #70283.
This regression test was implemented by me by testing for the ability to use the range types within const generics, but that is not the actual property the std guarantees now (const generics is still unstable). This PR addresses that situation by adding extra tests for the range types that directly test whether they can be structurally matched upon.
Note: also adds the otherwise unrelated test `test_range_to_inclusive` for completeness with the other range unit tests
Duration::zero() -> Duration::ZERO
In review for #72790, whether or not a constant or a function should be favored for `#![feature(duration_zero)]` was seen as an open question. In https://github.com/rust-lang/rust/issues/73544#issuecomment-691701670 an invitation was opened to either stabilize the methods or propose a switch to the constant value, supplemented with reasoning. Followup comments suggested community preference leans towards the const ZERO, which would be reason enough.
ZERO also "makes sense" beside existing associated consts for Duration. It is ever so slightly awkward to have a series of constants specifying 1 of various units but leave 0 as a method, especially when they are side-by-side in code. It seems unintuitive for the one non-dynamic value (that isn't from Default) to be not-a-const, which could hurt discoverability of the associated constants overall. Elsewhere in `std`, methods for obtaining a constant value were even deprecated, as seen with [std::u32::min_value](https://doc.rust-lang.org/std/primitive.u32.html#method.min_value).
Most importantly, ZERO costs less to use. A match supports a const pattern, but const fn can only be used if evaluated through a const context such as an inline `const { const_fn() }` or a `const NAME: T = const_fn()` declaration elsewhere. Likewise, while https://github.com/rust-lang/rust/issues/73544#issuecomment-691949373 notes `Duration::zero()` can optimize to a constant value, "can" is not "will". Only const contexts have a strong promise of such. Even without that in mind, the comment in question still leans in favor of the constant for simplicity. As it costs less for a developer to use, may cost less to optimize, and seems to have more of a community consensus for it, the associated const seems best.
r? ```@LukasKalbertodt```
Refactor IntErrorKind to avoid "underflow" terminology
This PR is a continuation of #76455
# Changes
- `Overflow` renamed to `PosOverflow` and `Underflow` renamed to `NegOverflow` after discussion in #76455
- Changed some of the parsing code to return `InvalidDigit` rather than `Empty` for strings "+" and "-". https://users.rust-lang.org/t/misleading-error-in-str-parse-for-int-types/49178
- Carry the problem `char` with the `InvalidDigit` variant.
- Necessary changes were made to the compiler as it depends on `int_error_matching`.
- Redid tests to match on specific errors.
r? ```@KodrAus```
Stabilize `Poll::is_ready` and `is_pending` as const
Insta-stabilize the methods `is_ready` and `is_pending` of `std::task::Poll` as const, in the same way as [PR#76198](https://github.com/rust-lang/rust/pull/76198).
Possible because of the recent stabilization of const control flow.
Part of #76225.
Duration::ZERO composes better with match and various other things,
at the cost of an occasional parens, and results in less work for the
optimizer, so let's use that instead.
This expands time's test suite to use more and in more places the
range of methods and constants added to Duration in recent
proposals for the sake of testing more API surface area and
improving legibility.
Replace absolute paths with relative ones
Modern compilers allow reaching external crates
like std or core via relative paths in modules
outside of lib.rs and main.rs.
This stabilizes the functionality in slice_partition_at_index,
but under the names `select_nth_unstable*`. The functions
`partition_at_index*` are left as deprecated, to be removed in
a later release.
Closes#55300
Implement advance_by, advance_back_by for iter::Chain
Part of #77404.
This PR does two things:
- implement `Chain::advance[_back]_by` in terms of `advance[_back]_by` on `self.a` and `advance[_back]_by` on `self.b`
- change `Chain::nth[_back]` to use `advance[_back]_by` on `self.a` and `nth[_back]` on `self.b`
This ensures that `Chain::nth` can take advantage of an efficient `nth` implementation on the second iterator, in case it doesn't implement `advance_by`.
cc `@scottmcm` in case you want to review this
Add Iterator::advance_by and DoubleEndedIterator::advance_back_by
This PR adds the iterator method
```rust
fn advance_by(&mut self, n: usize) -> Result<(), usize>
```
that advances the iterator by `n` elements, returning `Ok(())` if this succeeds or `Err(len)` if the length of the iterator was less than `n`.
Currently `Iterator::nth` is the method to override for efficiently advancing an iterator by multiple elements at once. `advance_by` is superior for this purpose because
- it's simpler to implement: instead of advancing the iterator and producing the next element you only need to advance the iterator
- it composes better: iterators like `Chain` and `FlatMap` can implement `advance_by` in terms of `advance_by` on their inner iterators, but they cannot implement `nth` in terms of `nth` on their inner iterators (see #60395)
- the default implementation of `nth` can trivially be implemented in terms of `advance_by` and `next`, which this PR also does
This PR also adds `DoubleEndedIterator::advance_back_by` for all the same reasons.
I'll make a tracking issue if it's decided this is worth merging. Also let me know if anything can be improved, this went through several iterations so there might very well still be room for improvement (especially in the doc comments). I've written overrides of these methods for most iterators that already override `nth`/`nth_back`, but those still need tests so I'll add them in a later PR.
cc @cuviper @scottmcm @Amanieu
UI to unit test for those using Cell/RefCell/UnsafeCell
Helps with #76268.
I'm working on all files using `Cell` and moving them to unit tests when possible.
r? @matklad
Make some methods of `Pin` unstable const
Make the following methods unstable const under the `const_pin` feature:
- `new`
- `new_unchecked`
- `into_inner`
- `into_inner_unchecked`
- `get_ref`
- `into_ref`
- `get_mut`
- `get_unchecked_mut`
Of these, `into_inner` and `into_inner_unchecked` require the unstable `const_precise_live_drops`.
Also adds tests for these methods in a const context.
Tracking issue: #76654
r? @ecstatic-morse
Stabilize some Result methods as const
Stabilize the following methods of Result as const:
- `is_ok`
- `is_err`
- `as_ref`
A test is also included, analogous to the test for `const_option`.
These methods are currently const under the unstable feature `const_result` (tracking issue: #67520).
I believe these methods to be eligible for stabilization because of the stabilization of #49146 (Allow if and match in constants) and the trivial implementations, see also: [PR#75463](https://github.com/rust-lang/rust/pull/75463) and [PR#76135](https://github.com/rust-lang/rust/pull/76135).
Note: these methods are the only methods currently under the `const_result` feature, thus this PR results in the removal of the feature.
Related: #76225
Add array_windows fn
This mimicks the functionality added by array_chunks, and implements a const-generic form of
`windows`. It makes egregious use of `unsafe`, but by necessity because the array must be
re-interpreted as a slice of arrays, and unlike array_chunks this cannot be done by casting the
original array once, since each time the index is advanced it needs to move one element, not
`N`.
I'm planning on adding more tests, but this should be good enough as a premise for the functionality.
Notably: should there be more functions overwritten for the iterator implementation/in general?
~~I've marked the issue as #74985 as there is no corresponding exact issue for `array_windows`, but it's based of off `array_chunks`.~~
Edit: See Issue #75027 created by @lcnr for tracking issue
~~Do not merge until I add more tests, please.~~
r? @lcnr
Updated issue to #75027
Update to rm oob access
And hopefully fix docs as well
Fixed naming conflict in test
Fix test which used 1-indexing
Nth starts from 0, woops
Fix a bunch of off by 1 errors
See https://play.rust-lang.org/?version=nightly&mode=debug&edition=2018&gist=757b311987e3fae1ca47122969acda5a
Add even more off by 1 errors
And also write `next` and `next_back` in terms of `nth` and `nth_back`.
Run fmt
Fix forgetting to change fn name in test
add nth_back test & document unsafe
Remove as_ref().unwrap()
Documented occurrences of unsafe, noting what invariants are maintained
Make all methods of `Duration` unstably const
Make the following methods of `Duration` unstable const under `duration_const_2`:
- `from_secs_f64`
- `from_secs_f32`
- `mul_f64`
- `mul_f32`
- `div_f64`
- `div_f32`
This results in all methods of `Duration` being (unstable) const.
Moved the tests to `library` as part of #76268.
Possible because of #72449, which made the relevant `f32` and `f64` methods const.
Tracking issue: #72440
r? @ecstatic-morse
Make some Ordering methods const
Resubmission of [PR#75463](https://github.com/rust-lang/rust/pull/75463) as per [PR#76172](https://github.com/rust-lang/rust/pull/76172).
Constify the following methods of `core::cmp::Ordering`:
- `reverse`
- `then`
Insta-stabilizes these methods as const under the `const_ordering` feature, as their implementation is a trivial match and the recent stabilization of #49146 (Allow `if` and `match` in constants).
Note: the `const_ordering` feature has never actually been used as these methods have not been `#[rustc_const_unstable]`.
Tracking issue: #76113
Make the following methods unstable const under the `const_pin` feature:
- `new`
- `new_unchecked`
- `into_inner`
- `into_inner_unchecked`
- `get_ref`
- `into_ref`
Also adds tests for these methods in a const context.
Tracking issue: #76654
Make the following methods of `Duration` unstable const under `duration_const_2`:
- `from_secs_f64`
- `from_secs_f32`
- `mul_f64`
- `mul_f32`
- `div_f64`
- `div_f32`
This results in all methods of `Duration` being (unstable) const.
Also adds tests for these methods in a const context, moved the test to `library` as part of #76268.
Possible because of #72449, which made the relevant `f32` and `f64` methods const.
Tracking issue: #72440
Add saturating methods for `Duration`
In some project, I needed a `saturating_add` method for `Duration`. I implemented it myself but i thought it would be a nice addition to the standard library as it matches closely with the integers types.
3 new methods have been introduced and are gated by the new `duration_saturating_ops` unstable feature:
* `Duration::saturating_add`
* `Duration::saturating_sub`
* `Duration::saturating_mul`
If have left the tracking issue to `none` for now as I want first to understand if those methods would be acceptable at all. If agreed, I'll update the PR with the tracking issue.
Further more, to match the behavior of integers types, I introduced 2 associated constants:
* `Duration::MIN`: this one is somehow a duplicate from `Duration::zero()` method, but at the time this method was added, `MIN` was rejected as it was considered a different semantic (see https://github.com/rust-lang/rust/pull/72790#issuecomment-636511743).
* `Duration::MAX`
Both have been gated by the already existing unstable feature `duration_constants`, I can introduce a new unstable feature if needed or just re-use the `duration_saturating_ops`.
We might have to decide whether:
* `MIN` should be replaced by `ZERO`?
* associated constants over methods?
Add `slice::array_chunks_mut`
This follows `array_chunks` from #74373 with a mutable version, `array_chunks_mut`. The implementation is identical apart from mutability. The new tests are adaptations of the `chunks_exact_mut` tests, plus an inference test like the one for `array_chunks`.
I reused the unstable feature `array_chunks` and tracking issue #74985, but I can separate that if desired.
r? `@withoutboats`
cc `@lcnr`
Move various ui const tests to `library`
Move:
- `src\test\ui\consts\const-nonzero.rs` to `library\core`
- `src\test\ui\consts\ascii.rs` to `library\core`
- `src\test\ui\consts\cow-is-borrowed` to `library\alloc`
Part of #76268
r? @matklad
Move:
- `src\test\ui\consts\const-nonzero.rs` to `library\core`
- `src\test\ui\consts\ascii.rs` to `library\core`
- `src\test\ui\consts\cow-is-borrowed` to `library\alloc`
Part of #76268
Add `[T; N]::as_[mut_]slice`
Part of me trying to populate arrays with a couple of basic useful methods, like slices already have. The ability to add methods to arrays were added in #75212. Tracking issue: #76118
This adds:
```rust
impl<T, const N: usize> [T; N] {
pub fn as_slice(&self) -> &[T];
pub fn as_mut_slice(&mut self) -> &mut [T];
}
```
These methods are like the ones on `std::array::FixedSizeArray` and in the crate `arraytools`.
I would like to propose these two simple methods for stabilization:
- Knowing that a range is exhaused isn't otherwise trivial
- Clippy would like to suggest them, but had to do extra work to disable that path <https://github.com/rust-lang/rust-clippy/issues/3807> because they're unstable
- These work on `PartialOrd`, consistently with now-stable `contains`, and are thus more general than iterator-based approaches that need `Step`
- They've been unchanged for some time, and have picked up uses in the compiler
- Stabilizing them doesn't block any future iterator-based is_empty plans, as the inherent ones are preferred in name resolution
enable align_to tests in Miri
With https://github.com/rust-lang/miri/issues/1074 resolved, we can enable these tests in Miri.
I also tweaked the test sized to get reasonable execution times with decent test coverage.
Use min_specialization in libcore
Getting `TrustedRandomAccess` to work is the main interesting thing here.
- `get_unchecked` is now an unstable, hidden method on `Iterator`
- The contract for `TrustedRandomAccess` is made clearer in documentation
- Fixed a bug where `Debug` would create aliasing references when using the specialized zip impl
- Added tests for the side effects of `next_back` and `nth`.
closes#68536
Switch from indexing to zip, and also use `write` on `MaybeUninit`.
Add array_map feature to core/src/lib
Attempt to fix issue of no such feature
Update w/ pickfire's review
This changes a couple of names around, adds another small test of variable size,
and hides the rustdoc #![feature(..)].
Fmt doctest
Add suggestions from lcnr
Add basic test
And also run fmt which is where the other changes are from
Fix mut issues
These only appear when running tests, so resolved by adding mut
Swap order of forget
Add pub and rm guard impl
Add explicit type to guard
Add safety note
Change guard type from T to S
It should never have been T, as it guards over [MaybeUninit<S>; N]
Also add feature to test
Stabilize `Result::as_deref` and `as_deref_mut`
FCP completed in https://github.com/rust-lang/rust/issues/50264#issuecomment-645681400.
This PR stabilizes two new APIs for `std::result::Result`:
```rust
fn as_deref(&self) -> Result<&T::Target, &E> where T: Deref;
fn as_deref_mut(&mut self) -> Result<&mut T::Target, &mut E> where T: DerefMut;
```
This PR also removes two rarely used unstable APIs from `Result`:
```rust
fn as_deref_err(&self) -> Result<&T, &E::Target> where E: Deref;
fn as_deref_mut_err(&mut self) -> Result<&mut T, &mut E::Target> where E: DerefMut;
```
Closes#50264
{kind=link}