4903: Add highlighting support for doc comments r=matklad a=Nashenas88
The language server protocol includes a semantic modifier for documentation. This change exports that modifier for doc comments so users can choose to highlight them differently compared to regular comments.
Example:
<img width="375" alt="Screen Shot 2020-06-16 at 10 34 14 AM" src="https://user-images.githubusercontent.com/1673130/84788271-f6599580-afbc-11ea-96e5-7a0215da620b.png">
CC @woody77
Co-authored-by: Paul Daniel Faria <Nashenas88@users.noreply.github.com>
We might as well handle them internally, via queries.
I am not sure, but it looks like the current LibraryData setup might
even predate salsa? It's not really needed and creates a bunch of
complexity.
4913: Remove debugging code for incremental sync r=matklad a=lnicola
4915: Inspect markdown code fences to determine whether to apply syntax highlighting r=matklad a=ltentrup
Fixes#4904
4916: Warnings as hint or info r=matklad a=GabbeV
Fixes#4229
This PR is my second attempt at providing a solution to the above issue. My last PR(#4721) had to be rolled back(#4862) due to it overriding behavior many users expected. This PR solves a broader problem while trying to minimize surprises for the users.
### Problem description
The underlying problem this PR tries to solve is the mismatch between [Rustc lint levels](https://doc.rust-lang.org/rustc/lints/levels.html) and [LSP diagnostic severity](https://microsoft.github.io/language-server-protocol/specification#diagnostic). Rustc currently doesn't have a lint level less severe than warning forcing the user to disable warnings if they think they get to noisy. LSP however provides two severitys below warning, information and hint. This allows editors like VSCode to provide more fine grained control over how prominently to show different diagnostics.
Info severity shows a blue squiggly underline in code and can be filtered separately from errors and warnings in the problems panel.


Hint severity doesn't show up in the problems panel at all and only show three dots under the affected code or just faded text if the diagnostic also has the unnecessary tag.
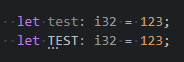
### Solution
The solution provided by this PR allows the user to configure lists of of warnings to report as info severity and hint severity respectively. I purposefully only convert warnings and not errors as i believe it's a good idea to have the editor show the same severity as the compiler as much as possible.

### Open questions
#### Discoverability
How do we teach this to new and existing users? Should a section be added to the user manual? If so where and what should it say?
#### Defaults
Other languages such as TypeScript report unused code as hint by default. Should rust-analyzer similarly report some problems as hint/info by default?
Co-authored-by: Laurențiu Nicola <lnicola@dend.ro>
Co-authored-by: Leander Tentrup <leander.tentrup@gmail.com>
Co-authored-by: Gabriel Valfridsson <gabriel.valfridsson@gmail.com>
Anchoring to the SourceRoot wont' work if the path is absolute:
#[path = "/tmp/foo.rs"]
mod foo;
Anchoring to a file will.
However, we *should* anchor, instead of just producing an abs path.
I can imagine a situation where, for example, rust-analyzer processes
crates from different machines (or, for example, from in-memory git
branch), where the same absolute path in different crates might refer
to different files in the end!
This commit adds a function that tries to determine the syntax highlighting class of NAME_REFs based on the usage.
It is used for highlighting injections (such as highlighting of doctests) as the semantic logic will most of the time result in unresolved references.
It also adds a color to unresolved references in HTML encoding.
4849: Make known paths use `core` instead of `std` r=matklad a=jonas-schievink
I'm not sure if this causes problems today, but it seems like it easily could, if rust-analyzer processes the libstd sources for the right `--target` and that target is a `#![no_std]`-only target.
Co-authored-by: Jonas Schievink <jonas.schievink@ferrous-systems.com>
4775: Add goto def for enum variant field r=matklad a=unexge
Closes#4764. I'm not familiar with ra codebase, there might be better ways to do that 😄
Co-authored-by: unexge <unexge@gmail.com>
4683: Implement syntax highlighting for doctests r=ltentrup a=ltentrup
The implementation is more complicated than the previous injection logic as the doctest comments consist of multiple ranges. The implementation extracts the doctests together with an offset-mapping, applies the syntax highlighting, and updates the text ranges.
<img width="478" alt="Bildschirmfoto 2020-06-01 um 15 45 25" src="https://user-images.githubusercontent.com/201808/83415249-1f0b5800-a41f-11ea-8fa6-c282434d6ff7.png">
Part of #4170.
Co-authored-by: Leander Tentrup <leander.tentrup@gmail.com>
4781: Remove redundancy in syntax highlighting tests r=matklad a=ltentrup
Follow up from #4683. Improves syntax highlighting testing by introducing a function that contains the boilerplate comparison code. Keeps the `ra_fixture` argument in the first position, thus, the editor syntax highlighting injection still works.
Co-authored-by: Leander Tentrup <leander.tentrup@gmail.com>
4729: Hover actions r=matklad a=vsrs
This PR adds a `hoverActions` LSP extension and a `Go to Implementations` action as an example:
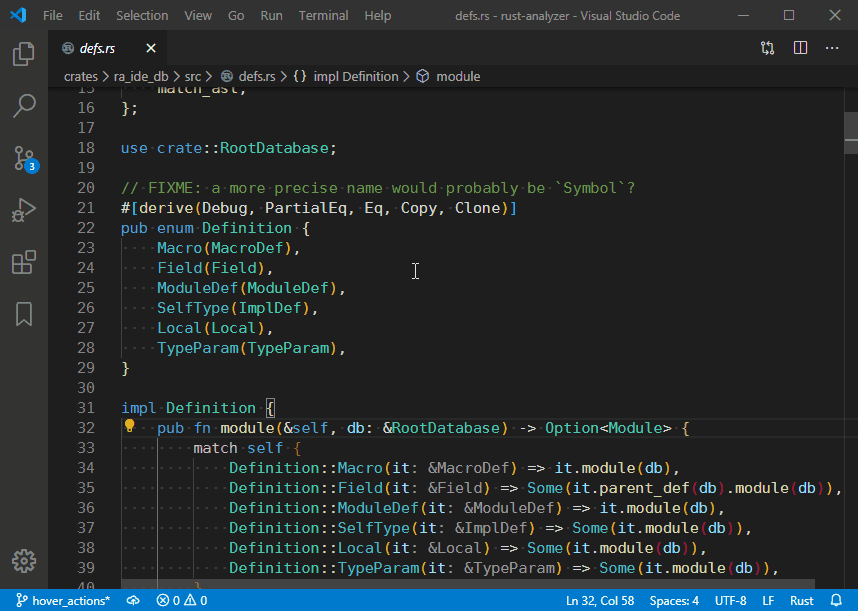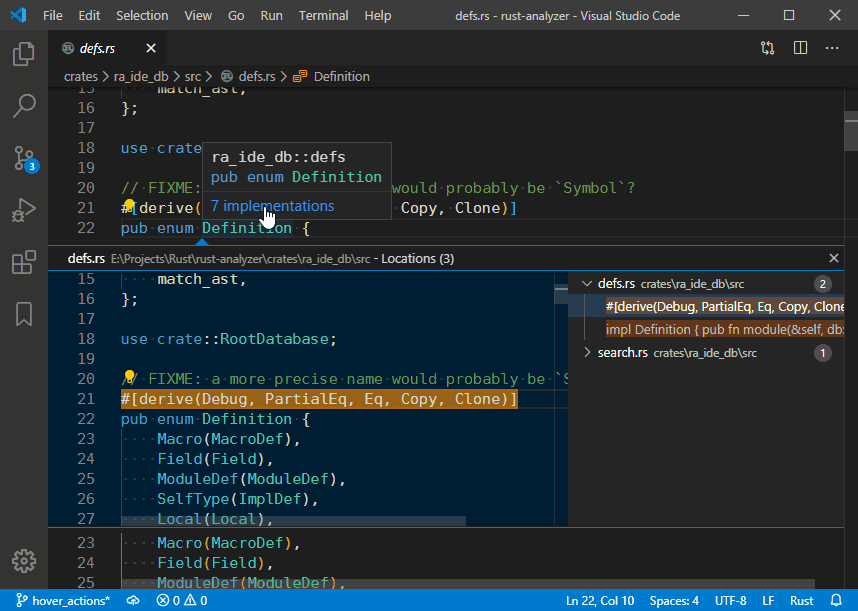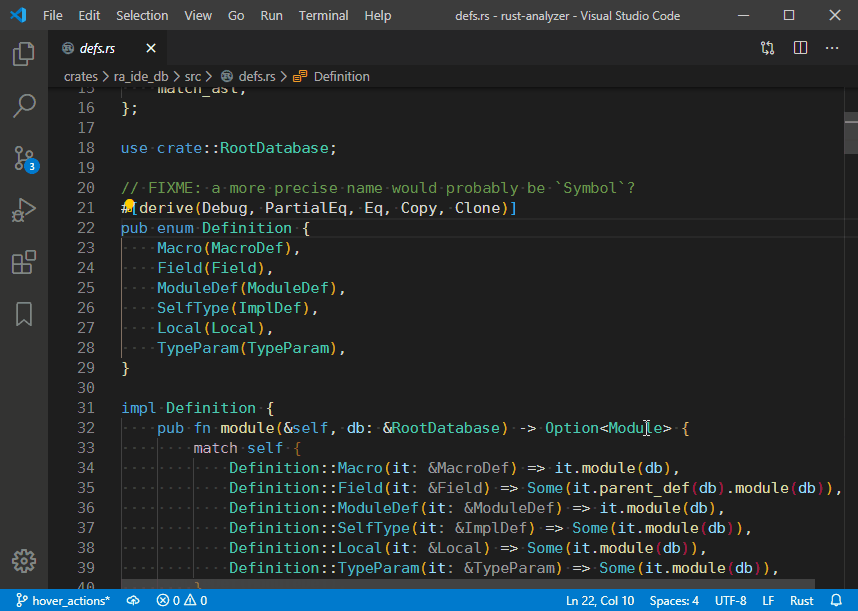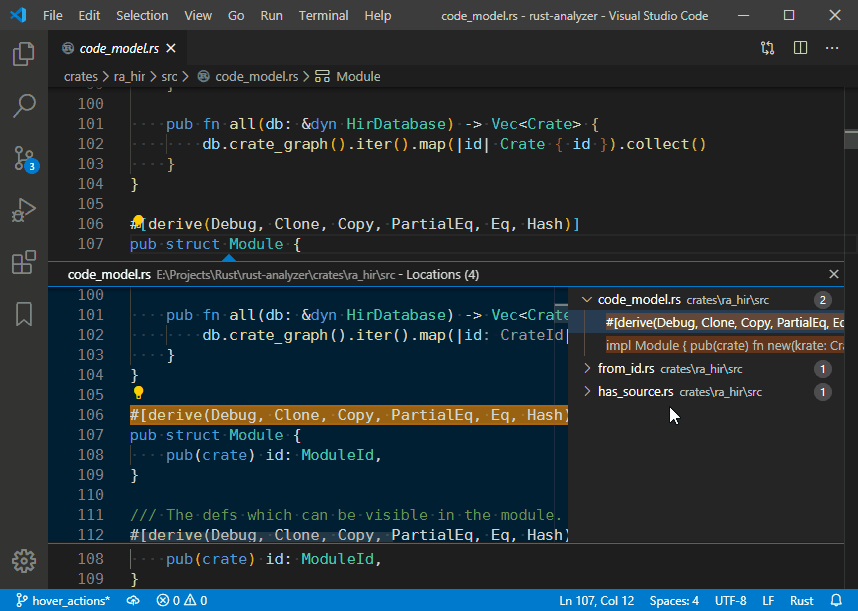
4748: Add an `ImportMap` and use it to resolve item paths in `find_path` r=matklad a=jonas-schievink
Removes the "go faster" queries I added in https://github.com/rust-analyzer/rust-analyzer/pull/4501 and https://github.com/rust-analyzer/rust-analyzer/pull/4506. I've checked this PR on the rustc code base and the assists are still fast.
This should fix https://github.com/rust-analyzer/rust-analyzer/issues/4515.
Note that this does introduce a change in behavior: We now always refer to items defined in external crates using paths through the external crate. Previously we could also use a local path (if for example the extern crate was reexported locally), as seen in the changed test. If that is undesired I can fix that, but the test didn't say why the previous behavior would be preferable.
Co-authored-by: vsrs <vit@conrlab.com>
Co-authored-by: Jonas Schievink <jonasschievink@gmail.com>
Co-authored-by: Jonas Schievink <jonas.schievink@ferrous-systems.com>
Removes the duplicated `expand_doc_attrs` and `merge_doc_comments_and_attrs`
functions from `ra_ide` and exposes the same functionality via
`ra_hir::Documentation::from_ast`.
4658: Fix problem with format string tokenization r=matklad a=ruabmbua
Fixed by just not handling closing curlybrace escaping.
Closes https://github.com/rust-analyzer/rust-analyzer/issues/4637
Co-authored-by: Roland Ruckerbauer <roland.rucky@gmail.com>
4592: fix textedit range returned for completion when left token is a keyword r=bnjjj a=bnjjj
close#4545
Co-authored-by: Benjamin Coenen <5719034+bnjjj@users.noreply.github.com>
4596: Strip leading underscores of argument names in function/method r=matklad a=kuy
Closes#4510
### Goal
When I select a function/method from completions, I get a snippet that doesn't contain leading underscores of argument names.
### Solution
- Option 1: All signatures don't contain underscores
- Option 2: Keep same signature, but inserted snippet doesn't contain underscores
I choose Option 2 because I think that leading underscores is a part of "signature". Users should get correct signatures. On the other hand, trimming underscores is an assist by IDE.
### Other impls.
rls: Complete argument names with underscores (same as actual ra)
IntelliJ Rust: Doesn't complete argument names
VSCode (TypeScript): Doesn't complete argument names
### Working example
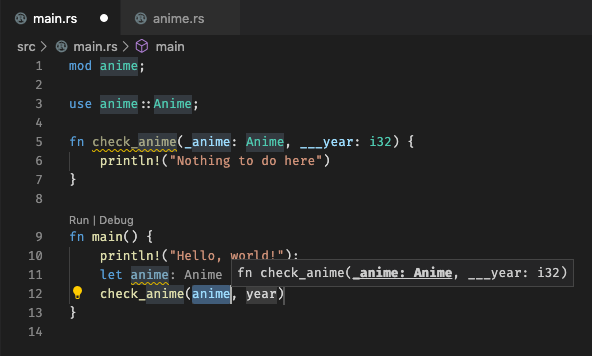
Co-authored-by: Yuki Kodama <endflow.net@gmail.com>
4625: Partially fix displaying inlay hints in Github PR diff views r=matklad a=Veetaha
See the comment in https://github.com/rust-analyzer/rust-analyzer/issues/4608#issuecomment-63424257
It partially fixes the left side of diff view (the one where old code is displayed), but the diff editor with new code changes still has `file` scheme and will proceed displaying inlay hints...
4629: Fix the `should_panic` snippet r=matklad a=eminence
Closes#4628
Co-authored-by: veetaha <veetaha2@gmail.com>
Co-authored-by: Andrew Chin <achin@eminence32.net>
4534: Add call postfix completion r=matklad a=vain0x
To make it easier to wrap an expression with Ok/Some/Rc::new etc.
Note I agree with conclusion of the discussion in #1431 that adding many completions is not the way to go. However, this PR still could be justified due to versatility of use.
Co-authored-by: vain0x <vainzerox@gmail.com>
The line separator is moved below the function signature to split
regions between the docs. This is very similar to how IntelliJ
displays tooltips. Adding an additional separator between the module
name and function signature currently has rendering issues.
Fixes#4594
Alternative to #4615
4602: Add boolean literal semantic token type to package.json r=matklad a=lnicola
Closes#4583.
CC @GrayJack
4603: Add self keyword semantic token type r=matklad a=lnicola
Not sure if this is warranted a new token type or just a modifier.
---
CC #4583, @GrayJack
Co-authored-by: Laurențiu Nicola <lnicola@dend.ro>
The idea behind requiring the label is a noble one, but we are not
really using it consistently anyway, and it should be easy to retrofit
later, should we need it.
This also changes our handiling of snippet edits on the client side.
`editor.insertSnippet` unfortunately forces indentation, which we
really don't want to have to deal with. So, let's just implement our
manual hacky way of dealing with a simple subset of snippets we
actually use in rust-analyzer
4472: Fix path resolution for module and function with same name r=hasali19 a=hasali19
This fixes#3970 and also fixes completion for the same issue.
Co-authored-by: Hasan Ali <git@hasali.co.uk>
4423: add tests module snippet r=bnjjj a=bnjjj
Request from a friend coming from intellij Rust
Co-authored-by: Benjamin Coenen <5719034+bnjjj@users.noreply.github.com>
4397: Textmate cooperation r=matklad a=georgewfraser
This PR tweaks the fallback TextMate scopes to make them more consistent with the existing grammar and other languages, and edits the builtin TextMate grammar to align with semantic coloring. Before is on the left, after is on the right:
<img width="855" alt="Screen Shot 2020-05-10 at 1 45 51 PM" src="https://user-images.githubusercontent.com/1369240/81512320-a8be7e80-92d4-11ea-8940-2c03f6769015.png">
**Use keyword.other for regular keywords instead of keyword**. This is a really peculiar quirk of TextMate conventions, but virtually *all* TextMate grammars use `keyword.other` (colored blue in VSCode Dark+) for regular keywords and `keyword.control` (colored purple in VSCode Dark+) for control keywords. The TextMate scope `keyword` is colored like control keywords, not regular keywords. It may seem strange that the `keyword` scope is not the right fallback for the `keyword` semantic token, but TextMate has a long and weird history. Note how keywords change from purple back to blue (what they were before semantic coloring was added):
**(1) Use punctuation.section.embedded for format specifiers**. This aligns with how Typescript colors formatting directives:
<img width="238" alt="Screen Shot 2020-05-09 at 10 54 01 AM" src="https://user-images.githubusercontent.com/1369240/81481258-93b5f280-91e3-11ea-99c2-c6d258c5bcad.png">
**(2) Consistently use `entity.name.type.*` scopes for type names**. Avoid using `entity.name.*` which gets colored like a keyword.
**(3) Use Property instead of Member for fields**. Property and Member are very similar, but if you look at the TextMate fallback scopes, it's clear that Member is intended for function-like-things (methods?) and Property is intended for variable-like-things.
**(4) Color `for` as a regular keyword when it's part of `impl Trait for Struct`**.
**(5) Use `variable.other.constant` for constants instead of `entity.name.constant`**. In the latest VSCode insiders, variable.other.constant has a subtly different color that differentiates constants from ordinary variables. It looks close to the green of types but it's not the same---it's a new color recently added to take advantage of semantic coloring.
I also made some minor changes that make the TextMate scopes better match the semantic scopes. The effect of this for the user is you observe less of a change when semantic coloring "activates". You can see the changes I made relative to the built-in TextMate grammar here:
a91d15c80c..97428b6d52 (diff-6966c729b862f79f79bf7258eb3e0885)
Co-authored-by: George Fraser <george@fivetran.com>
4421: Find references to a function outside module r=flodiebold a=montekki
Fixes#4188
Yet again, it looks like although the code in
da1f316b02/crates/ra_ide_db/src/search.rs (L128-L132)
may be wrong, it is not hit since the `vis` is `None` at this point. The fix is similar to the #4237 case: just add another special case to `Definition::visibility()`.
Co-authored-by: Fedor Sakharov <fedor.sakharov@gmail.com>
4394: Simplify r=matklad a=Veetaha
4414: Highlighting improvements r=matklad a=matthewjasper
- `static mut`s are highlighted as `mutable`.
- The name of the macro declared by `macro_rules!` is now highlighted.
Co-authored-by: veetaha <veetaha2@gmail.com>
Co-authored-by: Matthew Jasper <mjjasper1@gmail.com>
4346: Fix rename of enum variant visible from module r=matklad a=montekki
Probably fixes#4237
It looks like the ref is found correctly in this case but it's visibility is not correctly determined. I took a stab at fixing that by adding an implementation of `HasVisibility` for `EnumVariant` so it works more or less the same way it does for struct fields.
In other words, the `search_range` here does not contain the ref since it's not considered visible:
efd8e34c39/crates/ra_ide_db/src/search.rs (L209-L214)
Before that I tried to populate `ItemScope` with visible enum variants but that ended up with breaking tests all over the place and also it looked illogical in the end: `ItemScope` is not populated with, say, public struct fields and the same should be true for `enum` variants.
I've added two more or less identical tests: one for the case with a struct field rename and one for enum variant rename; the test for struct should probably be removed and the names should be changed.
Co-authored-by: Fedor Sakharov <fedor.sakharov@gmail.com>
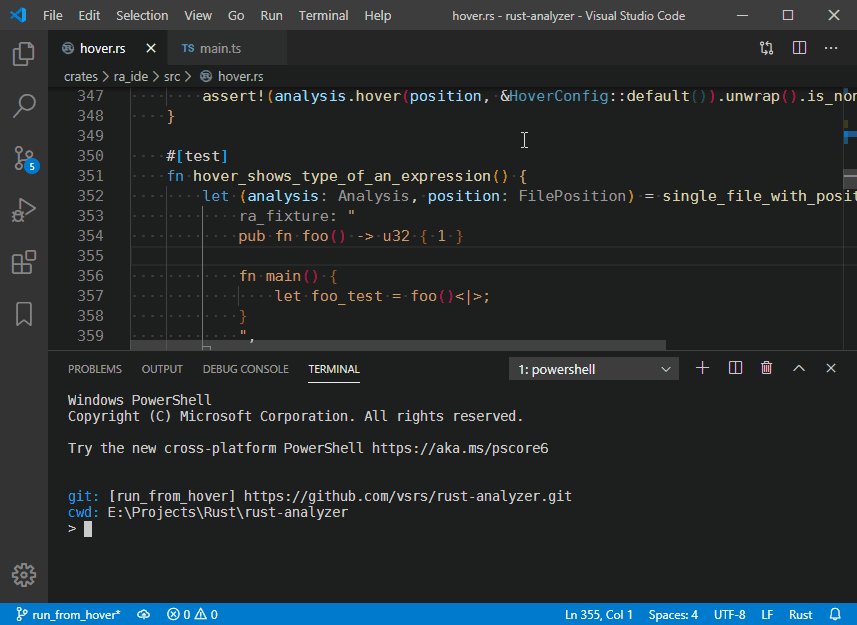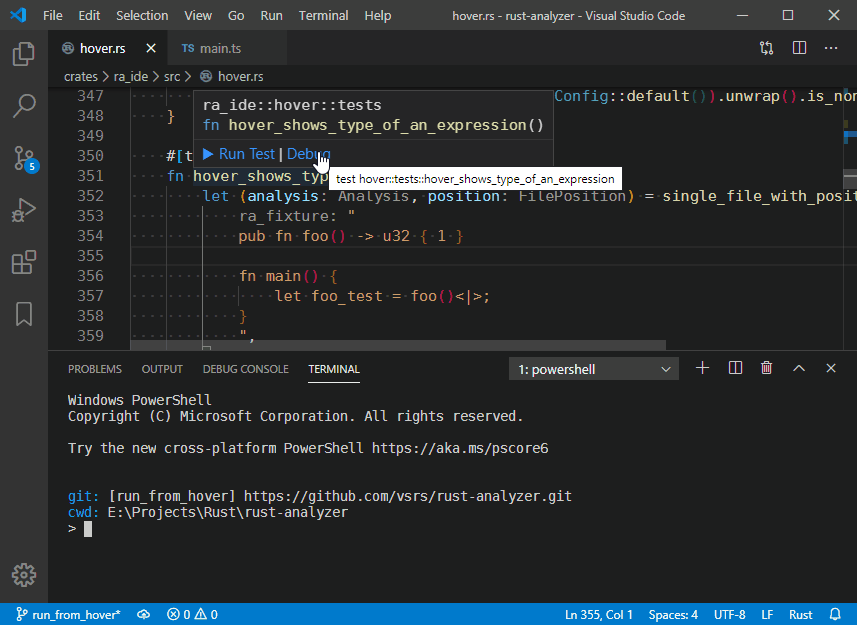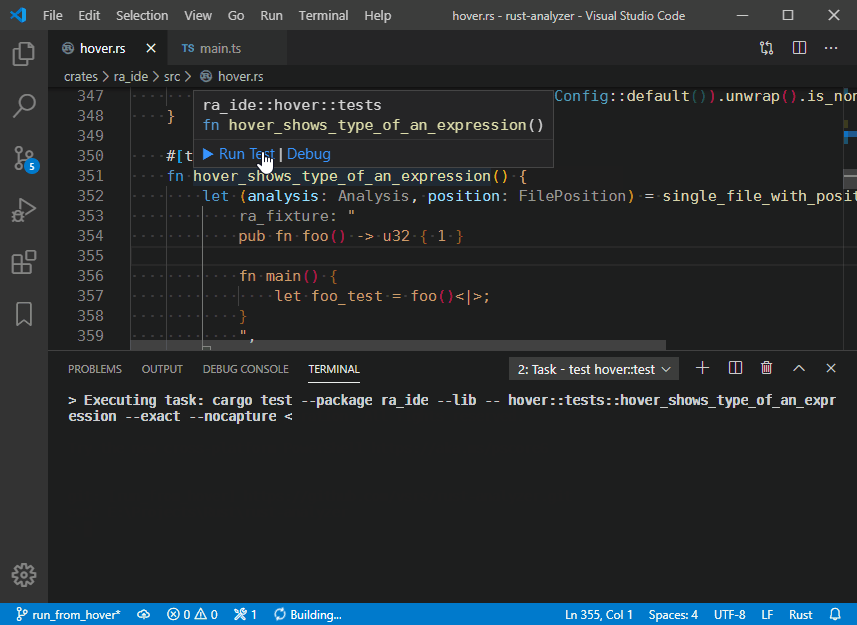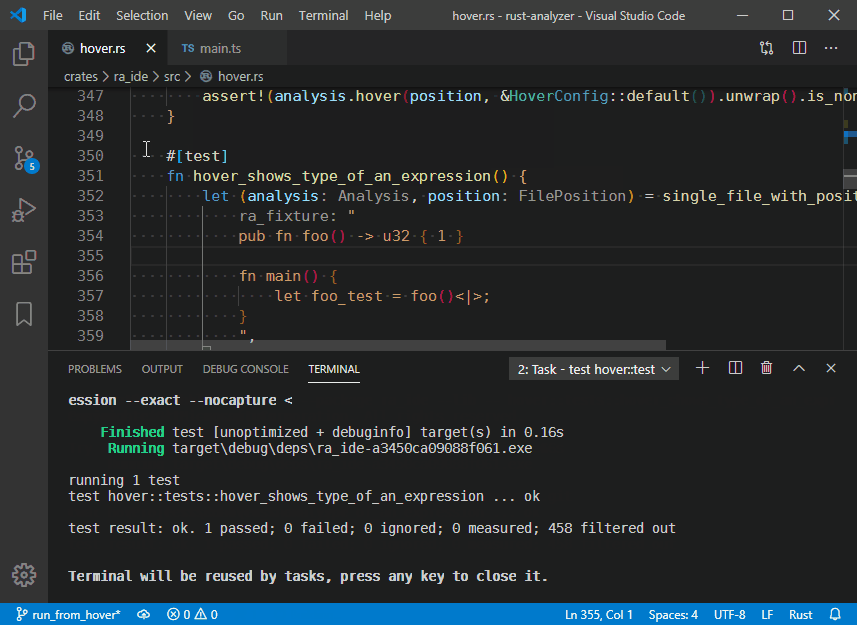
4316: do not truncate display for hover r=matklad a=bnjjj
close#4311
4351: Fix Windows server path r=matklad a=lnicola
CC @Coder-256.
Co-authored-by: Benjamin Coenen <5719034+bnjjj@users.noreply.github.com>
Co-authored-by: Laurențiu Nicola <lnicola@users.noreply.github.com>
No tests fail, and quick manual testing shows that there are no
false-positives. In general, each completion contributor should be
independent from the others.
4269: add support of use alias semantic in definition r=matklad a=bnjjj
close#4202
4293: no doctests for flycheck r=matklad a=matklad
bors r+
🤖
Co-authored-by: Benjamin Coenen <5719034+bnjjj@users.noreply.github.com>
Co-authored-by: Aleksey Kladov <aleksey.kladov@gmail.com>
4133: main: eagerly prime goto-definition caches r=matklad a=BurntSushi
This commit eagerly primes the caches used by goto-definition by
submitting a "phantom" goto-definition request. This is perhaps a bit
circuitous, but it does actually get the job done. The result of this
change is that once RA is finished its initial loading of a project,
goto-definition requests are instant. There don't appear to be any more
surprise latency spikes.
This _partially_ addresses #1650 in that it front-loads the latency of the
first goto-definition request, which in turn makes it more predictable and
less surprising. In particular, this addresses the use case where one opens
the text editor, starts reading code for a while, and only later issues the
first goto-definition request. Before this PR, that first goto-definition request
is guaranteed to have high latency in any reasonably sized project. But
after this PR, there's a good chance that it will now be instant.
What this _doesn't_ address is that initial loading time. In fact, it makes it
longer by adding a phantom goto-definition request to the initial startup
sequence. However, I observed that while this did make initial loading
slower, it was overall a somewhat small (but not insignificant) fraction
of initial loading time.
-----
At least, the above is what I _want_ to do. The actual change in this PR is just a proof-of-concept. I came up with after an evening of printf-debugging. Once I found the spot where this cache priming should go, I was unsure of how to generate a phantom input. So I just took an input I knew worked from my printf-debugging and hacked it in. Obviously, what I'd like to do is make this more general such that it will always work.
I don't know whether this is the "right" approach or not. My guess is that there is perhaps a cleaner solution that more directly primes whatever cache is being lazily populated rather than fudging the issue with a phantom goto-definition request.
I created this as a draft PR because I'd really like help making this general. I think whether y'all want to accept this patch is perhaps a separate question. IMO, it seems like a good idea, but to be honest, I'm happy to maintain this patch on my own since it's so trivial. But I would like to generalize it so that it will work in any project.
My thinking is that all I really need to do is find a file and a token somewhere in the loaded project, and then use that as input. But I don't quite know how to connect all the data structures to do that. Any help would be appreciated!
cc @matklad since I've been a worm in your ear about this problem. :-)
Co-authored-by: Andrew Gallant <jamslam@gmail.com>
This commit makes RA more aggressive about eagerly priming the caches.
In particular, this fixes an issue where even after RA was done priming
its caches, an initial goto-definition request would have very high
latency. This fixes that issue by requesting syntax highlighting for
everything. It is presumed that this is a tad wasteful, but not overly
so.
This commit also tweaks the logic that determines when the cache is
primed. Namely, instead of just priming it when the state is loaded
initially, we attempt to prime it whenever some state changes. This
fixes an issue where if a modification notification is seen before cache
priming is done, it would stop the cache priming early.
4128: Include correct item path for variant completions r=matklad a=jonas-schievink
The test would previously suggest `E::V`, which is not enough to name the variant as the enum is in a module. Now it correctly suggests the full path `m::E::V`.
Co-authored-by: Jonas Schievink <jonasschievink@gmail.com>
3998: Make add_function generate functions in other modules via qualified path r=matklad a=TimoFreiberg
Additional feature for #3639
- [x] Add tests for paths with more segments
- [x] Make generating the function in another file work
- [x] Add `pub` or `pub(crate)` to the generated function if it's generated in a different module
- [x] Make the assist jump to the edited file
- [x] Enable file support in the `check_assist` helper
4006: Syntax highlighting for format strings r=matklad a=ltentrup
I have an implementation for syntax highlighting for format string modifiers `{}`.
The first commit refactors the changes in #3826 into a separate struct.
The second commit implements the highlighting: first we check in a macro call whether the macro is a format macro from `std`. In this case, we remember the format string node. If we encounter this node during syntax highlighting, we check for the format modifiers `{}` using regular expressions.
There are a few places which I am not quite sure:
- Is the way I extract the macro names correct?
- Is the `HighlightTag::Attribute` suitable for highlighting the `{}`?
Let me know what you think, any feedback is welcome!
Co-authored-by: Timo Freiberg <timo.freiberg@gmail.com>
Co-authored-by: Leander Tentrup <leander.tentrup@gmail.com>
Co-authored-by: Leander Tentrup <ltentrup@users.noreply.github.com>
3954: Improve autocompletion by looking on the type and name r=matklad a=bnjjj
This tweet (https://twitter.com/tjholowaychuk/status/1248918374731714560) gaves me the idea to implement that in rust-analyzer.
Basically for this first example I made some examples when we are in a function call definition. I look on the parameter list to prioritize autocompletions for the same types and if it's the same type + the same name then it's displayed first in the completion list.
So here is a draft, first step to open a discussion and know what you think about the implementation. It works (cf tests) but maybe I can make a better implementation at some places. Be careful the code needs some refactoring to be better and concise.
PS: It was lot of fun writing this haha
Co-authored-by: Benjamin Coenen <5719034+bnjjj@users.noreply.github.com>
4065: Complete unqualified enum names in patterns and expressions r=matklad a=nathanwhit
This PR implements the completion described in #4014.
The result looks like so for patterns:
<img width="542" alt="Screen Shot 2020-04-20 at 3 53 55 PM" src="https://user-images.githubusercontent.com/17734409/79794010-8f529400-831f-11ea-9673-f838aa9bc962.png">
and for `expr`s:
<img width="620" alt="Screen Shot 2020-04-21 at 3 51 24 PM" src="https://user-images.githubusercontent.com/17734409/79908784-d73ded80-83e9-11ea-991d-921f0cb27e6f.png">
I'm not confident that the completion text itself is very robust, as it will unconditionally add completions for enum variants with the form `Enum::Variant`. This means (I believe) it would still suggest `Enum::Variant` even if the local name is changed i.e. `use Enum as Foo` or the variants are brought into scope such as through `use Enum::*`.
Co-authored-by: nathanwhit <nathan.whitaker01@gmail.com>
Detailed changes:
1) Implement a lexer for string literals that divides the string in format specifier `{}` including the format specifier modifier.
2) Adapt syntax highlighting to add ranges for the detected sequences.
3) Add a test case for the format string syntax highlighting.
This is a quick way to implement unresolved reference diagnostics.
For example, adding to VS Code config
"editor.tokenColorCustomizationsExperimental": {
"unresolvedReference": "#FF0000"
},
will highlight all unresolved refs in red.
4029: Fix various proc-macro bugs r=matklad a=edwin0cheng
This PRs does the following things:
1. Fixed#4001 by splitting `LIFETIME` lexer token to two mbe tokens. It is because rustc token stream expects `LIFETIME` as a combination of punct and ident, but RA `tt:TokenTree` treats it as a single `Ident` previously.
2. Fixed#4003, by skipping `proc-macro` for completion. It is because currently we don't have `AstNode` for `proc-macro`. We would need to redesign how to implement `HasSource` for `proc-macro`.
3. Fixed a bug how empty `TokenStream` merging in `proc-macro-srv` such that no L_DOLLAR and R_DOLLAR will be emitted accidentally.
Co-authored-by: Edwin Cheng <edwin0cheng@gmail.com>
3955: Align grammar for record patterns and literals r=matklad a=matklad
The grammar now looks like this
[name_ref :] pat
bors r+
🤖
Co-authored-by: Aleksey Kladov <aleksey.kladov@gmail.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}