Stop inserting semicolon when extracting match arm
# Overview
Extracting a match arm value that has type unit into a function, when a
comma already follows the match arm value, results in an invalid (syntax
error) semicolon added between the newly generated function's generated
call and the comma.
# Example
Running this extraction
```rust
fn main() {
match () {
_ => $0()$0,
};
}
```
would lead to
```rust
fn main() {
match () {
_ => fun_name();,
};
}
fn fun_name() {
}
```
# Issue / Fix details
This happens because when there is no comma, rust-analyzer would simply
add the comma and wouldn't even try to evaluate whether it needs to add
a semicolon. But when the comma is there, it proceeds to evaluate
whether it needs to add a semicolon and it looks like the evaluation
logic erroneously ignores the possibility that we're in a match arm.
IIUC it never makes sense to add a semicolon when we're extracting from
a match arm value, so I've adjusted the logic to always decide against
adding a semicolon when we're in a match arm
Remind user to check $PATH after installation.
fixes#14882 . I don't think that this is the correct wording to express this but I at least wanted to take the initiative :)
# Overview
Extracting a match arm value that has type unit into a function, when a
comma already follows the match arm value, results in an invalid (syntax
error) semicolon added between the newly generated function's generated
call and the comma.
# Example
Running this extraction
```rust
fn main() {
match () {
_ => $0()$0,
};
}
```
would lead to
```rust
fn main() {
match () {
_ => fun_name();,
};
}
fn fun_name() {
}
```
# Issue / Fix details
This happens because when there is no comma, rust-analyzer would simply
add the comma and wouldn't even try to evaluate whether it needs to add
a semicolon. But when the comma is there, it proceeds to evaluate
whether it needs to add a semicolon and it looks like the evaluation
logic erroneously ignores the possibility that we're in a match arm.
IIUC it never makes sense to add a semicolon when we're extracting from
a match arm value, so I've adjusted the logic to always decide against
adding a semicolon when we're in a match arm
Implement recursion in mir interpreter without recursion
This enables interpreting functions with deep stack + profiling. I also applied some changes to make it faster based on the profiling result.
Replace `x` with `it`
I kept some usages of `x`:
* `x`s that are used together with `y`, `z`, ...
* `x` that shadow `it`. I use `it` for iterators out of r-a, so there were some cases that I used `it` and `x` together.
* `x` in test fixtures. Many of those `x` usages was not me so I thought it's better to keep them as is.
I tried to remove the rest, but since there was too many `x` I might missed some of them or changed some of them that I didn't want to change.
Unify getter and setter assists
This PR combines what previously have been two different files into a single file. I want to talk about the reasons why I did this. The issue that prompted this PR ( and before I forget : this pr fixes#15080 ) mentions an interesting behavior. We combine these two assists into an assist group and the order in which the assists are listed in this group changes depending on the text range of the selected area. The reason for that is that VSCode prioritizes actions that have a bigger impact in a smaller area and until now generate setter assist was only possible to be invoked for a single field whereas you could generate multiple getters for the getter assist. So I used the latter's infra to make former applicable to multiple fields, hence the unification. So this PR solves in essence
1. Make `generate setter` applicable to multiple fields
2. Provide a consistent order of the said assists in listing.
Don't show `unresolved-field` diagnostic for missing names
I don't think reporting ``"no field `[missing name]` on type `SomeType`"`` makes much sense because it's a syntax error rather than a semantic error. We already report a syntax error for it and I find it sufficient.
editor/code: Enable `--noUncheckedIndexedAccess` & `--noPropertyAccessFromIndexSignature` ts option
This enables typescript's these option:
- [`--noUncheckedIndexedAccess`](https://www.typescriptlang.org/tsconfig#noUncheckedIndexedAccess)
- This checks whether indexed access is not `null` (or `undefined`) strictly just as like checking by `std::option::Option::unwrap()`.
- [`--noPropertyAccessFromIndexSignature`](https://www.typescriptlang.org/tsconfig#noPropertyAccessFromIndexSignature)
- This disallows `bar.foo` access if the `bar` type is `{ [key: string]: someType; }`.
----
Additionally, to enable `--noUncheckedIndexedAccess` easily, this pull request introduces [option-t](https://www.npmjs.com/package/option-t) as a dependency instead of defining a function in this repository like `unwrapUndefinable()` .
I'll remove it and define them byself if our dependency management policy is that to avoid to add a new package as possible.
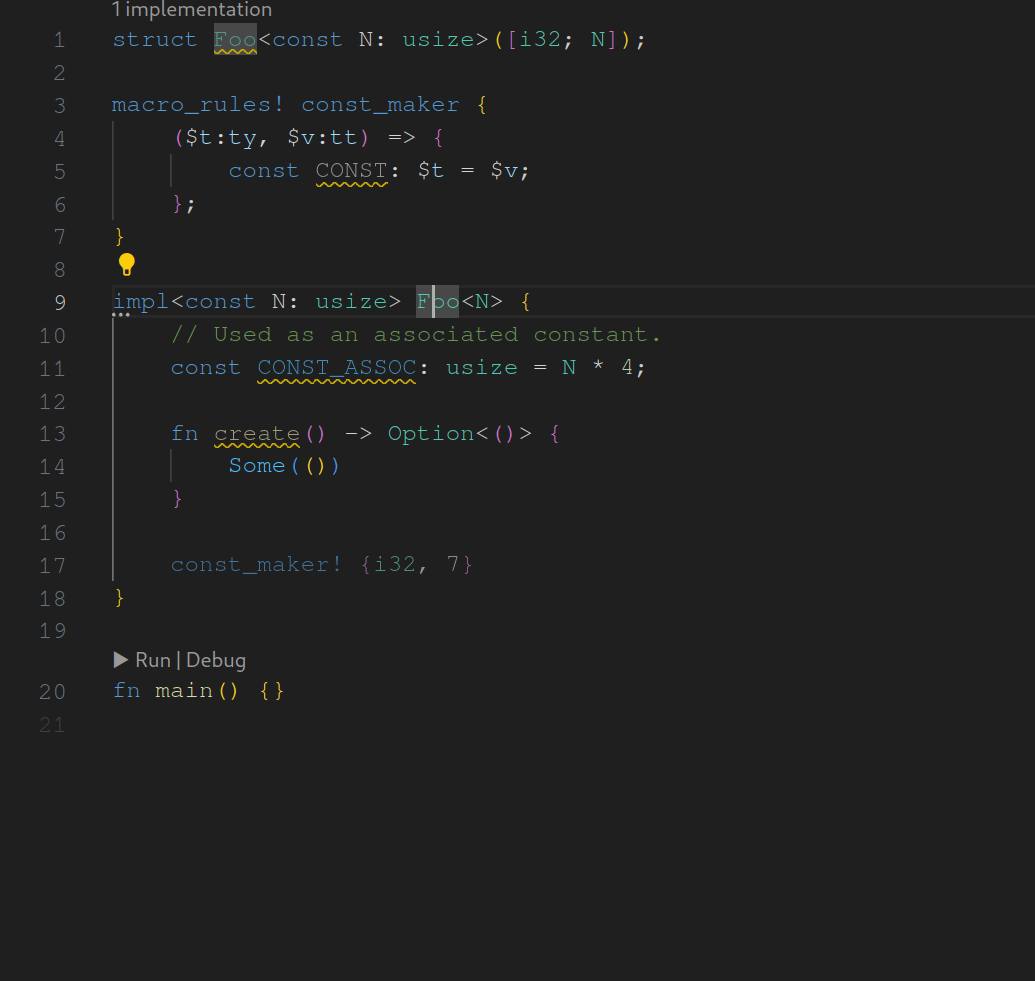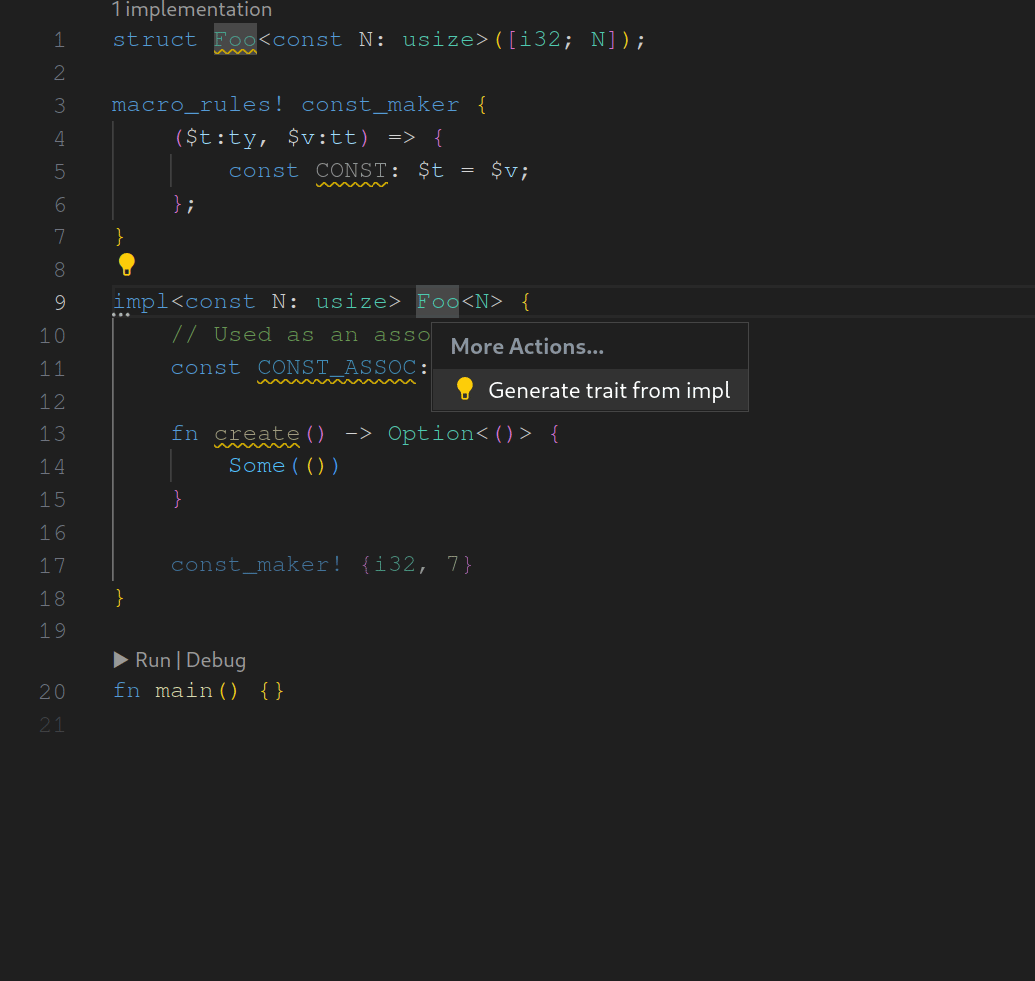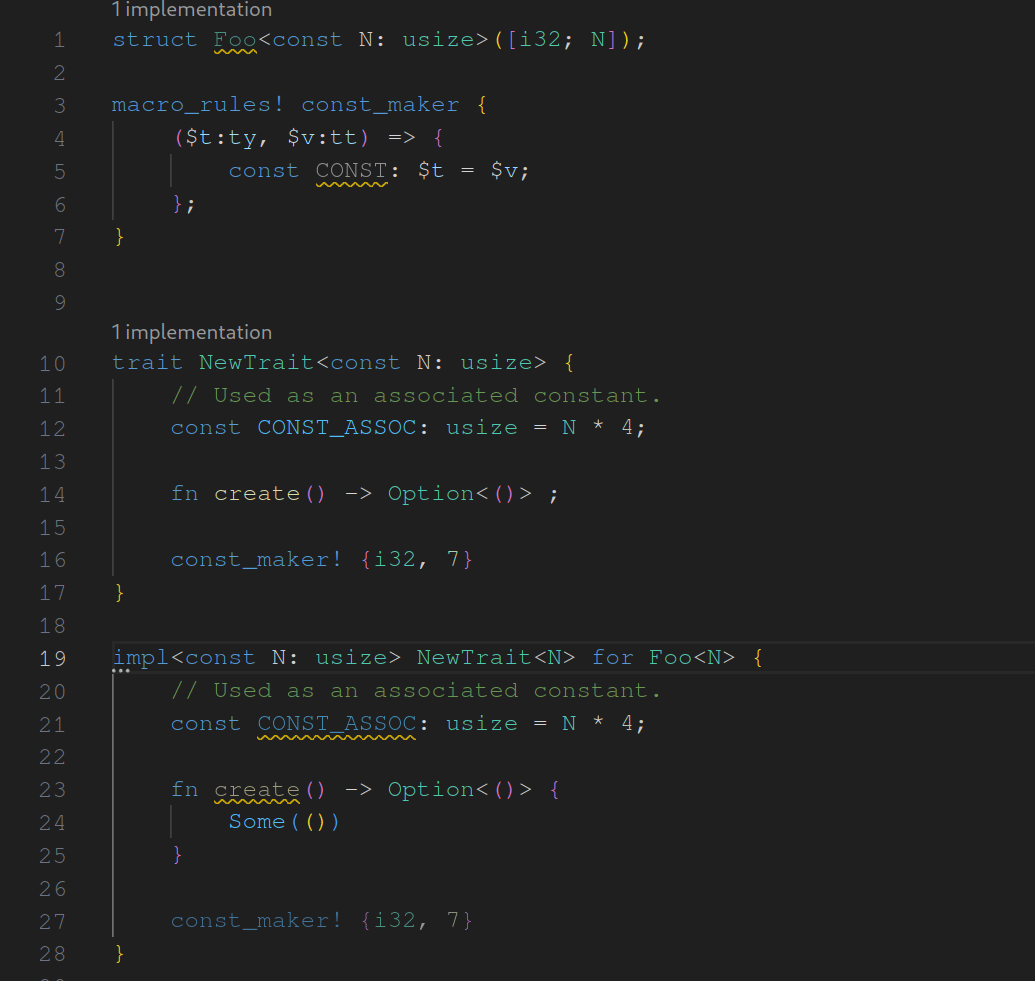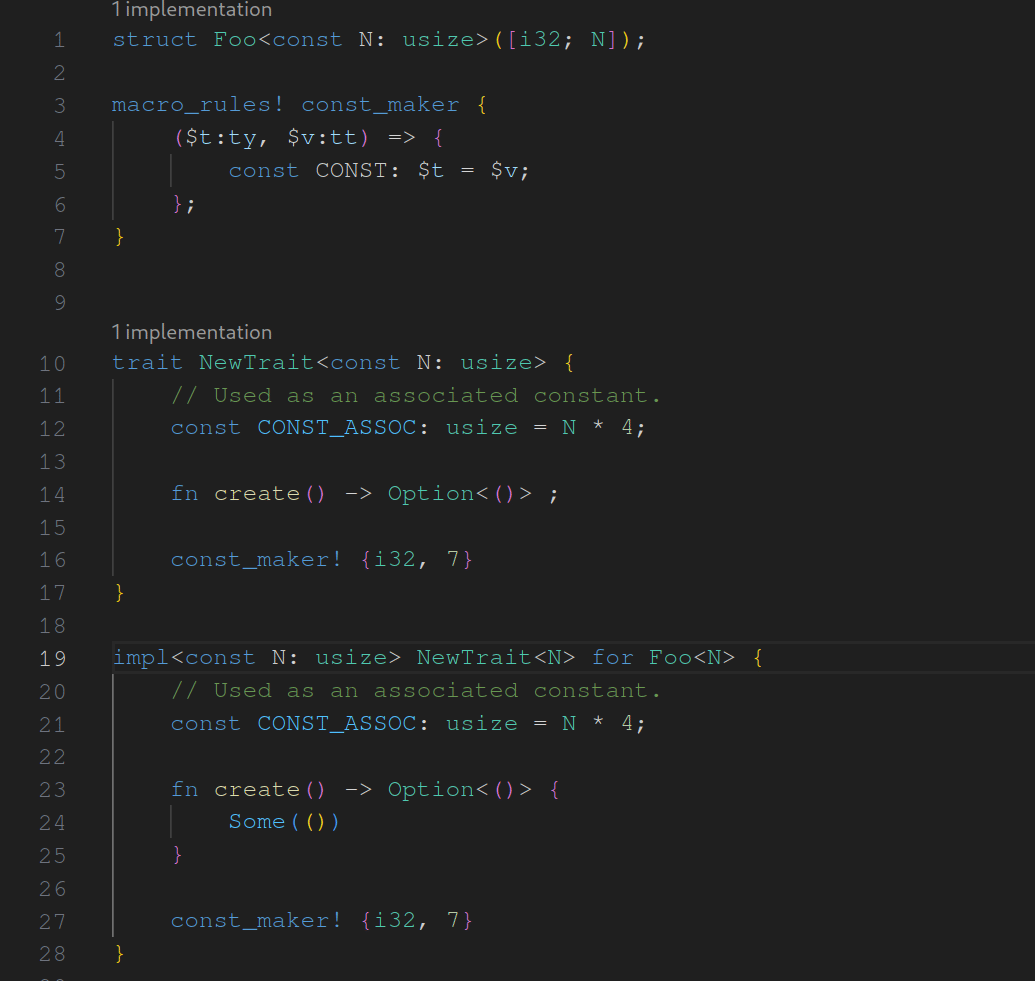
assist : generate trait from impl
fixes#14987 . As the name suggests this assist is used to generate traits from inherent impls while adapting the original impl to fit to the newly generated trait. I made some decisions regarding when the assist should be applicable. These are surely open to discussion. I looking forward to any feedback.
Disable remove unnecessary braces diagnotics for self imports
Disable `remove unnecessary braces` diagnostic if the there is a `self` inside the bracketed `use`
Fix#15191
Support GATs in bounds for associated types
Chalk has a dedicated IR for bounds on trait associated type: `rust_ir::InlineBound`. We have been failing to convert GATs inside those bounds from our IR to chalk IR. This PR provides an easy fix for it: properly take GATs into account during the conversion.