Group related stuff together, use only on path for parsing extern blocks
(they actually have modifiers).
Perhaps we should get rid of items_without_modifiers altogether? Better
to handle these kinds on diagnostics in validation layer...
10081: Fix error message r=lnicola a=digama0
I'm not entirely sure if the message is still correct, it seems to have survived a number of refactors, but it is mangled english anyway.
Co-authored-by: Mario Carneiro <di.gama@gmail.com>
10005: Extend `CargoConfig.unset_test_crates` r=matklad a=regexident
This is to allow for efficiently disabling `#[cfg(test)]` on all crates (by passing `unset_test_crates: UnsetTestCrates::All`) without having to first load the crate graph, when using rust-analyzer as a library.
(FYI: The change doesn't seem to be covered by any existing tests.)
Co-authored-by: Vincent Esche <regexident@gmail.com>
10080: internal: don't shut up the compiler when it says the code's buggy r=matklad a=matklad
bors r+
🤖
Co-authored-by: Aleksey Kladov <aleksey.kladov@gmail.com>
9906: switch `log` crate to `tracing` r=lnicola a=dzvon
Fixes#9274
1. Replace `log` crate with `tracing` of every crate that depend on `log`.
2. Change all `log` record macro with `tracing`.
3. Add `LoggerFormatter` make output format be the same as original.
Co-authored-by: Dezhi Wu <wu543065657@163.com>
10078: internal: Use Ubuntu 18.04 on CI r=lnicola a=lnicola
Ubuntu 16.04 is EOL since April, let's upgrade to 18.04.
bors r+
Co-authored-by: Laurențiu Nicola <lnicola@dend.ro>
10067: Downmap tokens to all token descendants instead of just the first r=Veykril a=Veykril
With this we can now resolve usages of identifiers inside (proc-)macros even if they are used for different purposes multiple times inside the expansion.
Example here being with the cursor being on the `no_send_sync_value` function causing us to still highlight the identifier in the attribute invocation correctly as we now resolve its usages in there. Prior we only saw the first usage of the identifier which is for a definition only, as such we bailed and didn't highlight it.
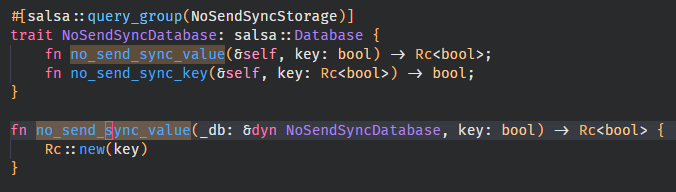
Note that this has to be explicitly switched over for most IDE features now as pretty much everything expects a single node/token as a result from descending.
Co-authored-by: Lukas Wirth <lukastw97@gmail.com>
10069: internal: Use `ManuallyDrop` in `RootDatabase` to improve build times r=matklad a=jonas-schievink
Co-authored-by: Jonas Schievink <jonasschievink@gmail.com>
10066: internal: improve compile times a bit r=matklad a=matklad
I wanted to *quickly* remove `smol_str = {features = "serde"}`, and figured out that the simplest way to do that is to replace our straightforward proc macro serialization with something significantly more obscure.
Co-authored-by: Aleksey Kladov <aleksey.kladov@gmail.com>
9970: feat: Implement attribute input token mapping, fix attribute item token mapping r=Veykril a=Veykril
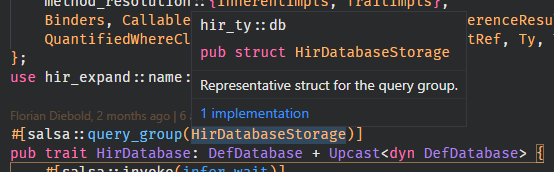
The token mapping for items with attributes got overwritten partially by the attributes non-item input, since attributes have two different inputs, the item and the direct input both.
This PR gives attributes a second TokenMap for its direct input. We now shift all normal input IDs by the item input maximum(we maybe wanna swap this see below) similar to what we do for macro-rules/def. For mapping down we then have to figure out whether we are inside the direct attribute input or its item input to pick the appropriate mapping which can be done with some token range comparisons.
Fixes https://github.com/rust-analyzer/rust-analyzer/issues/9867
Co-authored-by: Lukas Wirth <lukastw97@gmail.com>
{kind=link}
{kind=link}