This pulls in https://github.com/rust-analyzer/rowan/pull/111, which
fixes a bug in green node hash, making it more efficient.
On analysis stats, total memory goes from 1271mb to 1244mb, instructions
from 358ginstr to 353ginstr (not 100% clear on this one -- for some
reasons instruction counts are not stable for me anymore).
The counts are (before, than after):
rowan::green::node::GreenNode 11_490_596 2_357_063 2_233_347
rowan::green::token::GreenToken 5_010_401 994_281 991_920
rowan::green::node::GreenNode 9_738_085 1_988_164 1_890_549
rowan::green::token::GreenToken 3_353_409 687_333 685_831
total max_live live
I don't think there's anything wrong with project_model depending on
proc_macro_api directly -- fundamentally, both are about gluing our pure
data model to the messy outside world.
However, it's easy enough to avoid the dependency, so why not.
As an additional consideration, `proc_macro_api` now pulls in `base_db`.
project_model should definitely not depend on that!
cargo llvm-lines shows that path_to_error bloats the code. I don't think
I've needed this functionality recently, seems that we've fixed most of
the serialization problems. So let's just remove it. Should be easy to
add back if we ever need it, and it does make sense to keep the
`from_json` function around.
Today, rust-analyzer (and rustc, and bat, and IntelliJ) fail badly on
some kinds of maliciously constructed code, like a deep sequence of
nested parenthesis.
"Who writes 100k nested parenthesis" you'd ask?
Well, in a language with macros, a run-away macro expansion might do
that (see the added tests)! Such expansion can be broad, rather than
deep, so it bypasses recursion check at the macro-expansion layer, but
triggers deep recursion in parser.
In the ideal world, the parser would just handle deeply nested structs
gracefully. We'll get there some day, but at the moment, let's try to be
simple, and just avoid expanding macros with unbalanced parenthesis in
the first place.
closes#9358
9453: Add first-class limits. r=matklad,lnicola a=rbartlensky
Partially fixes#9286.
This introduces a new `Limits` structure which is passed as an input
to `SourceDatabase`. This makes limits accessible almost everywhere in
the code, since most places have a database in scope.
One downside of this approach is that whenever you query limits, you
essentially do an `Arc::clone` which is less than ideal.
Let me know if I missed anything, or would like me to take a different approach!
Co-authored-by: Robert Bartlensky <bartlensky.robert@gmail.com>
Our project model code is rather complicated -- the logic for lowering
from `cargo metadata` to `CrateGraph` is fiddly and special-case. So
far, we survived without testing this at all, but this increasingly
seems like a poor option.
So this PR introduces a simple tests just to detect the most obvious
failures. The idea here is that, although we rely on external processes
(cargo & rustc), we are actually using their stable interfaces, so we
might just mock out the outputs.
Long term, I would like to try to virtualize IO here, so as to do such
mocking in a more principled way, but lets start simple.
Should we forgo the mocking and just call `cargo metadata` directly
perhaps? Touch question -- I personally feel that fast, in-process tests
are more important in this case than any extra assurance we get from
running the real thing.
Super-long term, we would probably want to extend our heavy tests to
cover more use-cases, but we should figure a way to do that without
slowing the tests down for everyone.
Perhaps we need two-tiered bors system, where we pull from `master` into
`release` branch only when an additional set of tests passes?
Moving tests to `rust-analyzer` crate allows removing walkdir dependency
from `xtask`. It does seem more reasonable to keep tidy tests outside of
the "build system" and closer to other integration tests.
* Keep codegen adjacent to the relevant crates.
* Remove codgen deps from xtask, speeding-up from-source installation.
This regresses the release process a bit, as it now needs to run the
tests (and, by extension, compile the code).
9204: feat: more accurate memory usage info on glibc Linux r=jonas-schievink a=jonas-schievink
This adds support for the new `mallinfo2` API added in glibc 2.33. It addresses a shortcoming in the `mallinfo` API where it was unable to handle memory usage of more than 2 GB, which we sometimes exceed.
Blocked on https://github.com/rust-lang/libc/pull/2228
Co-authored-by: Jonas Schievink <jonasschievink@gmail.com>
9192: internal: Build test-macros in a build script r=jonas-schievink a=jonas-schievink
This build the test-proc-macros in `proc_macro_test` in a build script, and copies the artifact to `OUT_DIR`. This should make it available throughout all of rust-analyzer at no cost other than depending on `proc_macro_test`, fixing https://github.com/rust-analyzer/rust-analyzer/issues/9067.
This hopefully will let us later write inline tests that utilize proc macros, which makes my life fixing proc macro bugs easier.
Opening this as a sort of RFC, because I'm not totally sure this approach is the best.
Co-authored-by: Jonas Schievink <jonasschievink@gmail.com>
8866: Update salsa r=matklad a=jonas-schievink
This updates salsa to include https://github.com/salsa-rs/salsa/pull/265, and removes all cancellation-related code from rust-analyzer
Co-authored-by: Jonas Schievink <jonasschievink@gmail.com>
According to the spec we should return ServerNotInitialized if the server is waiting for an initialize request and something else comes in.
Upgrading to lsp-server 0.5.1 will do this and retry until the initialize request comes in.
Fixes#8581
8570: Flycheck tries to parse both Cargo and Rustc messages. r=rickvanprim a=rickvanprim
This change allows non-Cargo build systems to be used for Flycheck provided they call `rustc` with `--error-format=json` and emit those JSON messages to `stdout`.
Co-authored-by: James Leitch <rickvanprim@gmail.com>
reading both stdout & stderr is a common gotcha, you need to drain them
concurrently to avoid deadlocks. Not sure why I didn't do the right
thing from the start. Seems like I assumed the stderr is short? That's
not the case when cargo spams `compiling xyz` messages
Bitflags is generally a good dependency -- it's lightweight, well
maintained and embraced by the ecosystem.
I wonder, however, do we really need it? Doesn't feel like it adds much
to be honest.
6822: Read version of rustc that compiled proc macro r=edwin0cheng a=jsomedon
Signed-off-by: Jay Somedon <jay.somedon@outlook.com>
This PR is to fix#6174.
I basically
* added two methods, `read_version` and `read_section`(used by `read_version`)
* two new crates `snap` and `object` to be used by those two methods
I just noticed that some part of code were auto-reformatted by rust-analyzer on file save. Does it matter?
Co-authored-by: Jay Somedon <jay.somedon@outlook.com>
Co-authored-by: Edwin Cheng <edwin0cheng@gmail.com>
7566: Add benchmark tests for mbe r=matklad a=edwin0cheng
This PR add more real world tests dumped from `rust-analyzer analysis-stats .` to benchmark its performance.
cc #7513
r? @matklad
Co-authored-by: Edwin Cheng <edwin0cheng@gmail.com>
7291: Wrap remaining self/super/crate in Name{Ref} r=matklad a=Veykril
That should be the remaining special casing for `self` 🎉
Co-authored-by: Lukas Wirth <lukastw97@gmail.com>
Configuration is editor-independent. For this reason, we pick
JSON-schema as the repr of the source of truth. We do specify it using
rust-macros and some quick&dirty hackery though.
The idea for syncing truth with package.json is to just do that
manually, but there's a test to check that they are actually synced.
There's CLI to print config's json schema:
$ rust-analyzer --print-config-schema
We go with a CLI rather than LSP request/response to make it easier to
incorporate the thing into extension's static config. This is roughtly
how we put the thing in package.json.
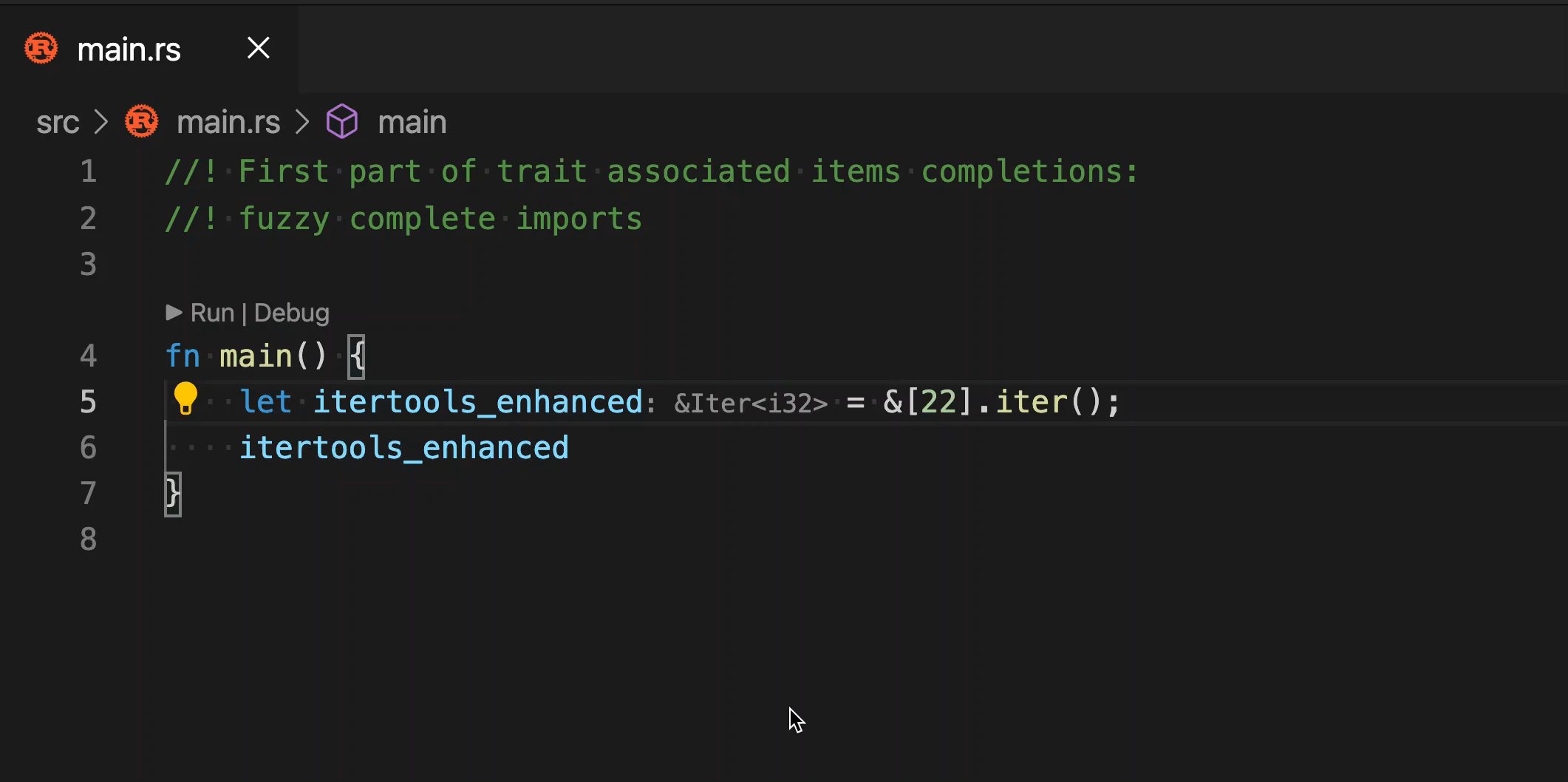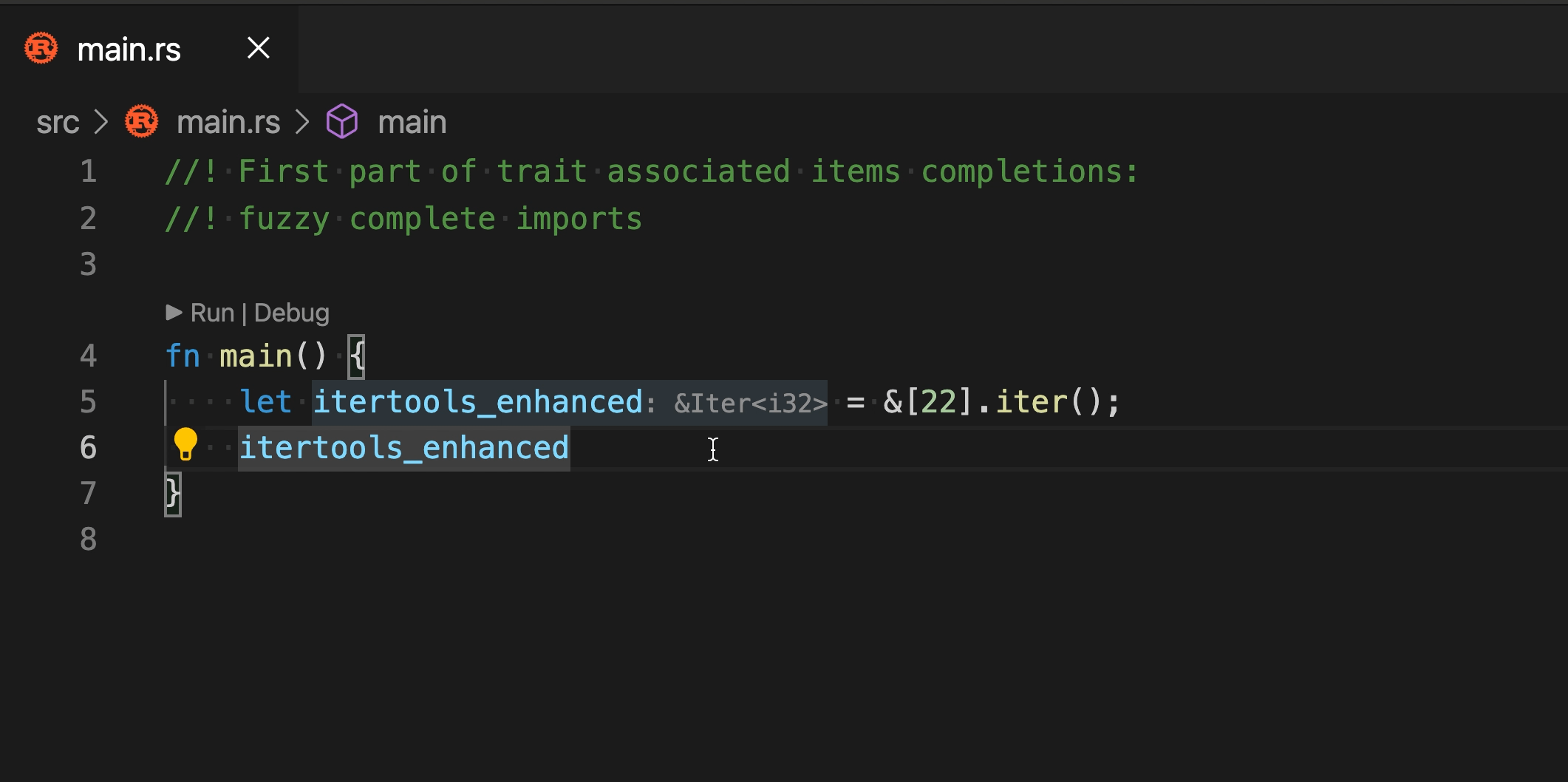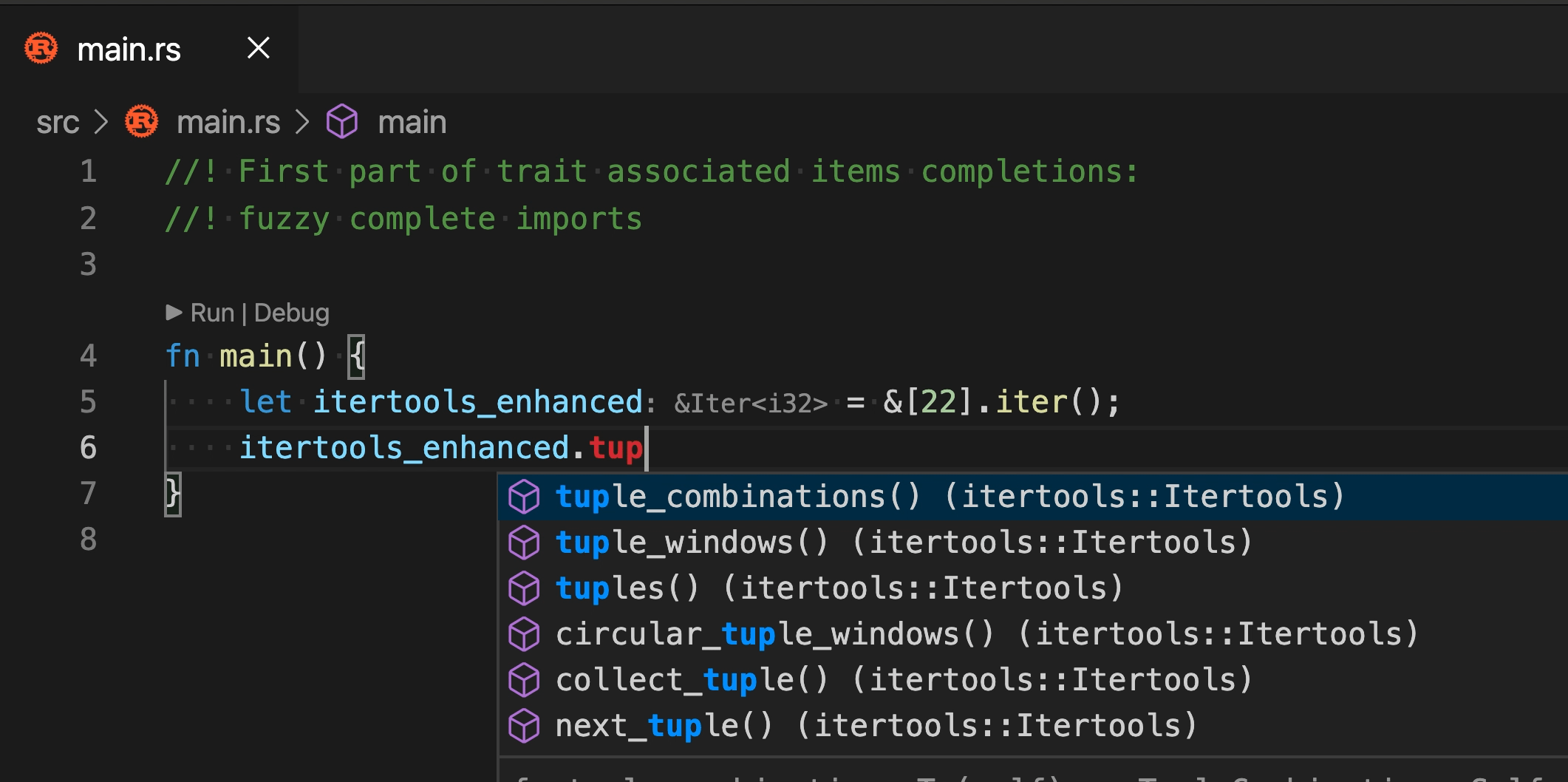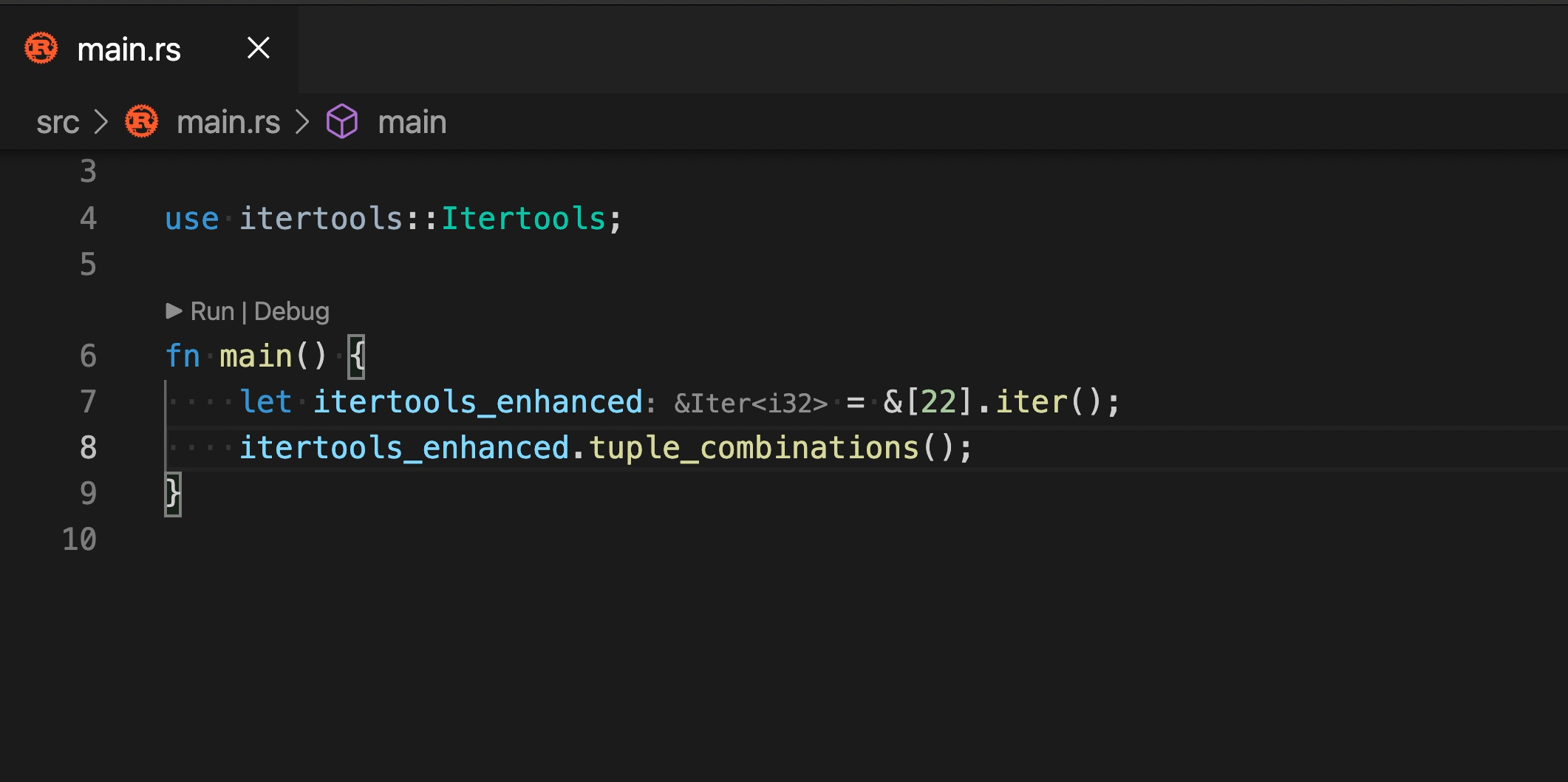
6553: Auto imports in completion r=matklad a=SomeoneToIgnore

Closes https://github.com/rust-analyzer/rust-analyzer/issues/1062 but does not handle the completion order, since it's a separate task for https://github.com/rust-analyzer/rust-analyzer/issues/4922 , https://github.com/rust-analyzer/rust-analyzer/issues/4922 and maybe something else.
2 quirks in the current implementation:
* traits are not auto imported during method completion
If I understand the current situation right, we cannot search for traits by a **part** of a method name, we need a full name with correct case to get a trait for it.
* VSCode (?) autocompletion is not as rigid as in Intellij Rust as you can notice on the animation.
Intellij is able to refresh the completions on every new symbol added, yet VS Code does not query the completions on every symbol for me.
With a few debug prints placed in RA, I've observed the following behaviour: after the first set of completion suggestions is received, next symbol input does not trigger a server request, if the completions contain this symbol.
When more symbols added, the existing completion suggestions are filtered out until none are left and only then, on the next symbol it queries for completions.
It seems like the only alternative to get an updated set of results is to manually retrigger it with Esc and Ctrl + Space.
Despite the eerie latter bullet, the completion seems to work pretty fine and fast nontheless, but if you have any ideas on how to make it more smooth, I'll gladly try it out.
Co-authored-by: Kirill Bulatov <mail4score@gmail.com>
6331: correct hover text for items with doc attribute with raw strings r=matklad a=JoshMcguigan
Fixes#6300 by improving the handling of raw string literals in attribute style doc comments.
This still has a bug where it could consume too many `"` at the start or end of the comment text, just as the original code had. Not sure if we want to fix that as part of this PR or not? If so, I think I'd prefer to add a unit test for either the `as_simple_key_value` function (I'm not exactly sure where this would belong / how to set this up) or create a `fn(&SmolStr) -> &SmolStr` to unit test by factoring out the `trim` operations from `as_simple_key_value`. Thoughts on this?
6342: Shorter dependency chain r=matklad a=popzxc
Continuing implementing suggestions from the `Completion refactoring` zulip thread.
This PR does the following:
- Removes dependency of `completions` on `assists` by moving required functionality into `ide_db`.
- Moves completely `call_info` crate into `ide_db` as it looks like it fits perfect there.
- Adds a bunch of new tests and docs.
- Adds the re-export of `base_db` to the `ide_db` and removes direct dependency on `base_db` from other crates.
The last point is controversial, I guess, but I noticed that in places where `ide_db` is used, `base_db` is also *always* used. Thus I think the dependency on the `base_db` is implied by the fact of `ide_db` interfaces, and thus it makes sense to just provide `base_db` out of the box.
Co-authored-by: Josh Mcguigan <joshmcg88@gmail.com>
Co-authored-by: Igor Aleksanov <popzxc@yandex.ru>
6251: Semantic Highlight: Add Callable modifier for variables r=matklad a=GrayJack
This PR added the `HighlightModifier::Callable` variant and assigned it to variables and parameters that are fn pointers, closures and implements FnOnce trait.
This allows to colorize these variables/parameters when used in call expression.
6310: Rewrite algo::diff to support insertion and deletion r=matklad a=Veykril
This in turn also makes `algo::diff` generate finer diffs(maybe even minimal diffs?) as insertions and deletions aren't always represented as as replacements of parent nodes now.
Required for #6287 to go on.
Co-authored-by: GrayJack <gr41.j4ck@gmail.com>
Co-authored-by: Lukas Wirth <lukastw97@gmail.com>
6324: Improve #[cfg] diagnostics r=jonas-schievink a=jonas-schievink
Unfortunately I ran into https://github.com/rust-analyzer/rust-analyzer/issues/4058 while testing this on https://github.com/nrf-rs/nrf-hal/, so I didn't see much of it in action yet, but it does seem to work.
Co-authored-by: Jonas Schievink <jonas.schievink@ferrous-systems.com>
Co-authored-by: Jonas Schievink <jonasschievink@gmail.com>
6207: Extract ImportAssets out of auto_import r=matklad a=Veykril
See https://github.com/rust-analyzer/rust-analyzer/pull/6172#issuecomment-707182140
I couldn't fully pull out `AssistContext` as `find_node_at_offset_with_descend`: 81fa00c5b5/crates/assists/src/assist_context.rs (L90-L92) requires the `SourceFile` which is private in it and I don't think making it public just for this is the right call?
6224: ⬆️ salsa r=matklad a=matklad
bors r+
🤖
6226: Add reminder to update lsp-extensions.md r=matklad a=matklad
bors r+
🤖
6227: Reduce bors timeout r=matklad a=matklad
bors r+
🤖
Co-authored-by: Lukas Wirth <lukastw97@gmail.com>
Co-authored-by: Aleksey Kladov <aleksey.kladov@gmail.com>
* Chalk very recently (like an hour ago) merged a fix that prevents rust analyzer from panicking. This allows it to be usable again for code that hits those situations. See #6134, #6145, Probably #6120
5930: Migrate to the latest Semantic Tokens Proposal for LSP 3.16 r=matklad a=kjeremy
This stabilizes call hierarchy and semantic tokens features on the client side and changes the server-side semantic tokens protocol to match the latest proposal for 3.16.
The server-side change will break clients depending on the earlier semantic tokens draft.
Fixes#4942
Co-authored-by: kjeremy <kjeremy@gmail.com>
`hir` should know nothing about URLs, markdown and html. It should
only be able to:
* resolve stringy path from documentation
* generate canonical stringy path for a def
In contrast, link rewriting should not care about semantics of paths
and names resolution, and should be concern only with text mangling
bits.
5758: SSR: Explicitly autoderef and ref placeholders as needed r=matklad a=davidlattimore
Structural search replace now inserts *, & and &mut in the replacement to match any auto[de]ref in the matched code.
e.g. `$a.foo() ==>> bar($a)` might convert `x.foo()` to `bar(&mut x)`
Co-authored-by: David Lattimore <dml@google.com>
{kind=link}
{kind=link}