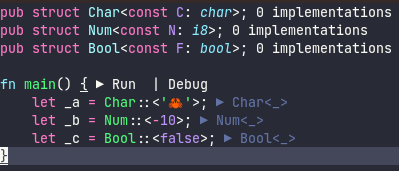
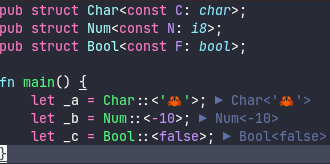
Handle trait alias definitions
Part of #2773
This PR adds a bunch of structs and enum variants for trait aliases. Trait aliases should be handled as an independent item because they are semantically distinct from traits.
I basically started by adding `TraitAlias{Id, Loc}` to `hir_def::item_tree` and iterated adding necessary stuffs until compiler stopped complaining what's missing. Let me know if there's still anything I need to add.
I'm opening up this PR for early review and stuff. I'm planning to add tests for IDE functionalities in this PR, but not type-related support, for which I put FIXME notes.
Beginning of MIR
This pull request introduces the initial implementation of MIR lowering and interpreting in Rust Analyzer.
The implementation of MIR has potential to bring several benefits:
- Executing a unit test without compiling it: This is my main goal. It can be useful for quickly testing code changes and print-debugging unit tests without the need for a full compilation (ideally in almost zero time, similar to languages like python and js). There is a probability that it goes nowhere, it might become slower than rustc, or it might need some unreasonable amount of memory, or we may fail to support a common pattern/function that make it unusable for most of the codes.
- Constant evaluation: MIR allows for easier and more correct constant evaluation, on par with rustc. If r-a wants to fully support the type system, it needs full const eval, which means arbitrary code execution, which needs MIR or something similar.
- Supporting more diagnostics: MIR can be used to detect errors, most famously borrow checker and lifetime errors, but also mutability errors and uninitialized variables, which can be difficult/impossible to detect in HIR.
- Lowering closures: With MIR we can find out closure capture modes, which is useful in detecting if a closure implements the `FnMut` or `Fn` traits, and calculating its size and data layout.
But the current PR implements no diagnostics and doesn't support closures. About const eval, I removed the old const eval code and it now uses the mir interpreter. Everything that is supported in stable rustc is either implemented or is super easy to implement. About interpreting unit tests, I added an experimental config, disabled by default, that shows a `pass` or `fail` on hover of unit tests (ideally it should be a button similar to `Run test` button, but I didn't figured out how to add them). Currently, no real world test works, due to missing features including closures, heap allocation, `dyn Trait` and ... so at this point it is only useful for me selecting what to implement next.
The implementation of MIR is based on the design of rustc, the data structures are almost copy paste (so it should be easy to migrate it to a possible future stable-mir), but the lowering and interpreting code is from me.
(This is a large commit. The changes to
`compiler/rustc_middle/src/ty/context.rs` are the most important ones.)
The current naming scheme is a mess, with a mix of `_intern_`, `intern_`
and `mk_` prefixes, with little consistency. In particular, in many
cases it's easy to use an iterator interner when a (preferable) slice
interner is available.
The guiding principles of the new naming system:
- No `_intern_` prefixes.
- The `intern_` prefix is for internal operations.
- The `mk_` prefix is for external operations.
- For cases where there is a slice interner and an iterator interner,
the former is `mk_foo` and the latter is `mk_foo_from_iter`.
Also, `slice_interners!` and `direct_interners!` can now be `pub` or
non-`pub`, which helps enforce the internal/external operations
division.
It's not perfect, but I think it's a clear improvement.
The following lists show everything that was renamed.
slice_interners
- const_list
- mk_const_list -> mk_const_list_from_iter
- intern_const_list -> mk_const_list
- substs
- mk_substs -> mk_substs_from_iter
- intern_substs -> mk_substs
- check_substs -> check_and_mk_substs (this is a weird one)
- canonical_var_infos
- intern_canonical_var_infos -> mk_canonical_var_infos
- poly_existential_predicates
- mk_poly_existential_predicates -> mk_poly_existential_predicates_from_iter
- intern_poly_existential_predicates -> mk_poly_existential_predicates
- _intern_poly_existential_predicates -> intern_poly_existential_predicates
- predicates
- mk_predicates -> mk_predicates_from_iter
- intern_predicates -> mk_predicates
- _intern_predicates -> intern_predicates
- projs
- intern_projs -> mk_projs
- place_elems
- mk_place_elems -> mk_place_elems_from_iter
- intern_place_elems -> mk_place_elems
- bound_variable_kinds
- mk_bound_variable_kinds -> mk_bound_variable_kinds_from_iter
- intern_bound_variable_kinds -> mk_bound_variable_kinds
direct_interners
- region
- intern_region (unchanged)
- const
- mk_const_internal -> intern_const
- const_allocation
- intern_const_alloc -> mk_const_alloc
- layout
- intern_layout -> mk_layout
- adt_def
- intern_adt_def -> mk_adt_def_from_data (unusual case, hard to avoid)
- alloc_adt_def(!) -> mk_adt_def
- external_constraints
- intern_external_constraints -> mk_external_constraints
Other
- type_list
- mk_type_list -> mk_type_list_from_iter
- intern_type_list -> mk_type_list
- tup
- mk_tup -> mk_tup_from_iter
- intern_tup -> mk_tup
Support generic function in `generate_function` assist
Part of #3639
This PR adds support for generic function generation in `generate_function` assist. Now the assist looks for generic parameters and trait bounds in scope, filters out irrelevant ones, and generates new function with them.
See `fn_generic_params()` for the outline of the procedure, and see comments on `filter_unnecessary_bounds()` for criteria for filtering. I think it's good criteria for most cases, but I'm open to opinions and suggestions.
The diff is pretty big, but it should run in linear time w.r.t. the number of nodes we operate on and should be fast enough.
Some notes:
- When we generate function in an existing impl, generic parameters may cause name conflict. While we can detect the conflict and rename conflicting params, I didn't find it worthwhile mainly because it's really easy to resolve on IDE: use Rename functionality.
- I've implemented graph structure myself, because we don't have graph library as a dependency and we only need the simplest one.
- Although `petgraph` is in our dependency graph and I was initially looking to use it, we don't actually depend on it AFAICT since it's only used in chalk's specialization graph handling, which we don't use. I'd be happy to replace my implementation with `petgraph` if it's okay to use it though.
- There are some caveats that I consider out of scope of this PR. See FIXME notes on added tests.
fix a bunch of clippy lints
fixes a bunch of clippy lints for fun and profit
i'm aware of this repo's position on clippy. The changes are split into separate commits so they can be reviewed separately
Use `rustc_safe_intrinsic` attribute to check for intrinsic safety
Instead of maintaining a list that is poorly kept in sync we can just use the attribute.
This will make new RA versions unusable with old toolchains that don't have the attribute yet. Should we keep maintaining the list as a fallback or just don't care?
fix: handle lifetime variables in `CallableSig` query
Fixes#13838
The problem is similar to #13223: we've been skipping non-empty binders, letting lifetime bound variables escape.
I ended up refactoring `hir_ty::callable_sig_from_fnonce()`. Like #13223, I chose to make use of `InferenceTable` which is capable of handling variables (I feel we should always use it when we solve trait-related stuff instead of manually building obligations/queries).
I couldn't make up a test that crashes without this patch (since the function I'm fixing is only used *outside* `hir-ty`, simple `hir-ty` test wouldn't cause crash), but at least I tested with my local build and made sure it doesn't crash with the code in the original issue. I'd appreciate any help to find a regression test.
This makes code more readale and concise,
moving all format arguments like `format!("{}", foo)`
into the more compact `format!("{foo}")` form.
The change was automatically created with, so there are far less change
of an accidental typo.
```
cargo clippy --fix -- -A clippy::all -W clippy::uninlined_format_args
```
I am not certain if this will improve performance,
but it seems having a .clone() without any need should be removed.
This was done with clippy, and manually reviewed:
```
cargo clippy --fix -- -A clippy::all -D clippy::redundant_clone
```
fix: normalize projection after discarding free `BoundVar`s in RPIT
Fixes#13307
When we lower the return type of a function, it may contain free `BoundVar`s in `OpaqueType`'s substitution, which would cause panic during canonicalization as part of projection normalization. Those `BoundVar`s are irrelevant in this context and will be discarded, and we should defer projection normalization until then.
fix: only shift `BoundVar`s that come from outside lowering context
Fixes#13734
There are some free functions `TyLoweringContext` methods call, which do not know anything about current binders in scope. We need to shift in the `BoundVar`s in substitutions that we get from them (#4952), but not those we get from `TyLoweringContext` methods.
Compute data layout of types
cc #4091
Things that aren't working:
* Closures
* Generators (so no support for `Future` I think)
* Opaque types
* Type alias and associated types which may need normalization
Things that show wrong result:
* ~Enums with explicit discriminant~
* SIMD types
* ~`NonZero*` and similar standard library items which control layout with special attributes~
At the user level, I didn't put much work, since I wasn't confident about what is the best way to present this information. Currently it shows size and align for ADTs, and size, align, offset for struct fields, in the hover, similar to clangd. I used it some days and I feel I liked it, but we may consider it too noisy and move it to an assist or command.
The old value was for the old chalk-engine solver, nowadays the newer chalk-recursive solver is used.
The new solver currently uses fuel a bit more quickly, so a higher value is needed.
Running analysis-stats showed that a value of 100 increases the amount of unknown types,
while for a value of 1000 it's staying mostly the same.
feat: Show witnesses of non-exhaustiveness in `missing-match-arm` diagnostic
Shamelessly copied from rustc. Thus reporting format is same.
This extends public api `hir::diagnostics::MissingMatchArms` with `uncovered_patterns: String` field. It does not expose data for implementing a quick fix yet.
-----
Worth to note: current implementation does not give a comprehensive list of missing patterns. Also mentioned in [paper](http://moscova.inria.fr/~maranget/papers/warn/warn.pdf):
> One may think that algorithm I should make an additional effort to provide more
> non-matching values, by systematically computing recursive calls on specialized
> matrices when possible, and by returning a list of all pattern vectors returned by
> recursive calls. We can first observe that it is not possible in general to supply the
> users with all non-matching values, since the signature of integers is (potentially)
> infinite.
feat: implement destructuring assignment
This is an attempt to implement destructuring assignments, or more specifically, type inference for [assignee expressions](https://doc.rust-lang.org/reference/expressions.html#place-expressions-and-value-expressions).
I'm not sure if this is the right approach, so I don't even expect this to be merged (hence the branch name 😉) but rather want to propose one direction we could choose. I don't mind getting merged if this is good enough though!
Some notes on the implementation choices:
- Assignee expressions are **not** desugared on HIR level unlike rustc, but are inferred directly along with other expressions. This matches the processing of other syntaxes that are desugared in rustc but not in r-a. I find this reasonable because r-a only needs to infer types and it's easier to relate AST nodes and HIR nodes, so I followed it.
- Assignee expressions obviously resemble patterns, so type inference for each kind of pattern and its corresponding assignee expressions share a significant amount of logic. I tried to reuse the type inference functions for patterns by introducing `PatLike` trait which generalizes assignee expressions and patterns.
- This is not the most elegant solution I suspect (and I really don't like the name of the trait!), but it's cleaner and the change is smaller than other ways I experimented, like making the functions generic without such trait, or making them take `Either<ExprId, PatId>` in place of `PatId`.
in case this is merged:
Closes#11532Closes#11839Closes#12322
- remove Valid, it serves no purpose and just obscures the diff
- rename some things
- don't use is_valid_candidate when searching for impl, it's not necessary
fix: #12441 False-positive type-mismatch error with generic future
I think the reason is same with #11815.
add ```Sized``` bound for ```AsyncBlockTypeImplTrait```.
Collect obligations from RPITs (Return Position `impl Trait`) of a function which is being inferred.
This allows inferring {unknown}s from RPIT bounds.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}