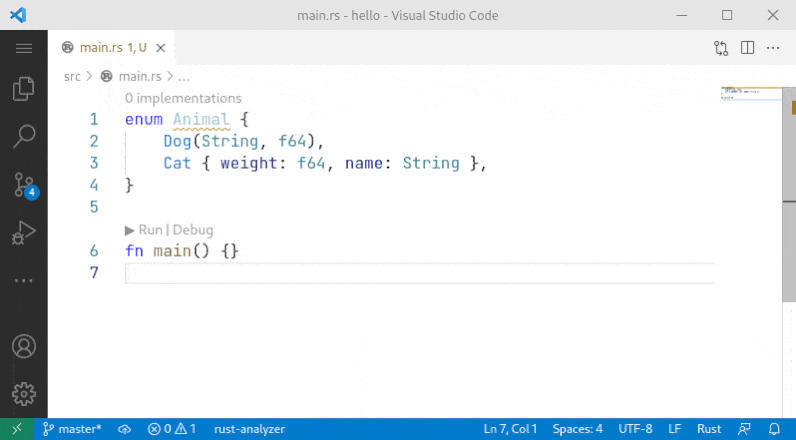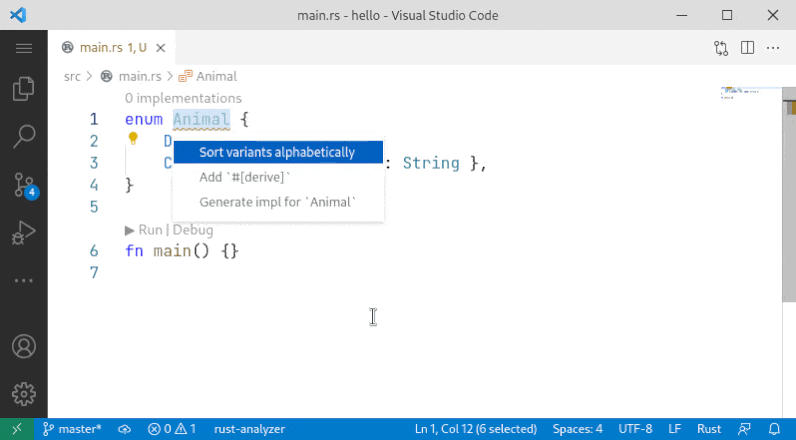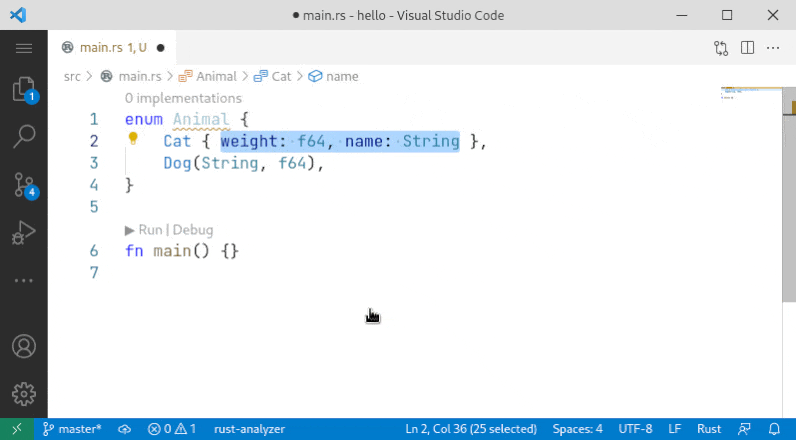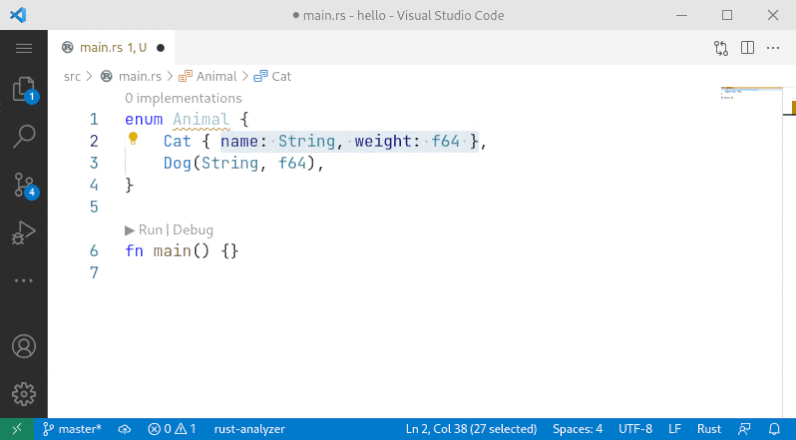
10001: Sort enum variant r=Veykril a=vsrs
A small fix to the problem noted by `@lnicola` :
> 
>
> (note the slight inconsistency here: to sort the variants of `Animal` I have to select the enum name, but to sort the fields of `Cat` I have to select the fields themselves)
Co-authored-by: vsrs <vit@conrlab.com>
This pulls in https://github.com/rust-analyzer/rowan/pull/111, which
fixes a bug in green node hash, making it more efficient.
On analysis stats, total memory goes from 1271mb to 1244mb, instructions
from 358ginstr to 353ginstr (not 100% clear on this one -- for some
reasons instruction counts are not stable for me anymore).
The counts are (before, than after):
rowan::green::node::GreenNode 11_490_596 2_357_063 2_233_347
rowan::green::token::GreenToken 5_010_401 994_281 991_920
rowan::green::node::GreenNode 9_738_085 1_988_164 1_890_549
rowan::green::token::GreenToken 3_353_409 687_333 685_831
total max_live live
9989: Fix two more “a”/“an” typos (this time the other way) r=lnicola a=steffahn
Follow-up to #9987
you guys are still merging these fast 😅
_this time I thought – for sure – that I’d get this commit into #9987 before it’s merged…_
Co-authored-by: Frank Steffahn <frank.steffahn@stu.uni-kiel.de>
9988: fix: Refactor & improve handling of overloaded binary operators r=flodiebold a=flodiebold
Fixes#9971. Also records them as method resolutions, which we could use later.
Co-authored-by: Florian Diebold <flodiebold@gmail.com>
9987: Fix two more “a”/“an” typos r=lnicola a=steffahn
Follow-up to #9985
you guys are merging these fast 😅
Co-authored-by: Frank Steffahn <frank.steffahn@stu.uni-kiel.de>
It's good that rust-analyzer doesn't belly-up on a panic in some random
assist.
It is less good that rust-analyzer devs only know that the assists are
buggy when they are actively looking at the logs.
9972: refactor : function generation assists r=Veykril a=mahdi-frms
Separated code generation from finding position for generated code. This will be ground work for introducing static associated function generation.
Co-authored-by: mahdi-frms <mahdif1380@outlook.com>
9979: fix: Incorrect up-mapping for tokens in derive attributes r=Veykril a=Veykril
Merely detaching the attributes causes incorrect spans to appear when mapping tokens up as the token ids resolve to the ranges of the stripped item so all the text ranges of its tokens are actually lower than the non-stripped ones.
Same fix as with attributes can be applied here, just replace the derive attribute with an equal amount of whitespace.
Fixes#9387
Co-authored-by: Lukas Wirth <lukastw97@gmail.com>
I don't think there's anything wrong with project_model depending on
proc_macro_api directly -- fundamentally, both are about gluing our pure
data model to the messy outside world.
However, it's easy enough to avoid the dependency, so why not.
As an additional consideration, `proc_macro_api` now pulls in `base_db`.
project_model should definitely not depend on that!
9976: fix: Do not show functional update completion when already qualified r=Veykril a=Veykril
Fixes#9964
bors r+
Co-authored-by: Lukas Wirth <lukastw97@gmail.com>
9975: minor: Fix panic caused by #9966 r=flodiebold a=flodiebold
Chalk can introduce new type variables when doing lazy normalization, so we have to do the proper 'fudging' after all.
Co-authored-by: Florian Diebold <flodiebold@gmail.com>
9965: minor: Don't ask for the builtin attribute input twice r=Veykril a=Veykril
`tt` and `item` here were the same, I misunderstood what the main input for attributes was in #9943
bors r+
Co-authored-by: Lukas Wirth <lukastw97@gmail.com>
{kind=link}