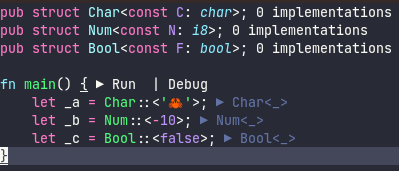
fix: Acknowledge `pub(crate)` imports in import suggestions
rust-analyzer has logic that discounts suggesting `use`s for private imports, but that logic is unnecessarily strict - for instance given this code:
```rust
mod foo {
pub struct Foo;
}
pub(crate) use self::foo::*;
mod bar {
fn main() {
Foo$0;
}
}
```
... RA will suggest to add `use crate::foo::Foo;`, which not only makes the code overly verbose (especially in larger code bases), but also is disjoint with what rustc itself suggests.
This commit adjusts the logic, so that `pub(crate)` imports are taken into account when generating the suggestions; considering rustc's behavior, I think this change doesn't warrant any extra configuration flag.
Note that this is my first commit to RA, so I guess the approach taken here might be suboptimal - certainly feels somewhat hacky, maybe there's some better way of finding out the optimal import path 😅
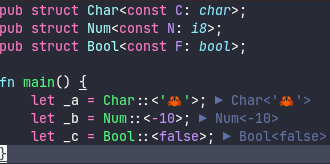
rust-analyzer has logic that discounts suggesting `use`s for private
imports, but that logic is unnecessarily strict - for instance given
this code:
```rust
mod foo {
pub struct Foo;
}
pub(crate) use self::foo::*;
mod bar {
fn main() {
Foo$0;
}
}
```
... RA will suggest to add `use crate::foo::Foo;`, which not only makes
the code overly verbose (especially in larger code bases), but also is
disjoint with what rustc itself suggests.
This commit adjusts the logic, so that `pub(crate)` imports are taken
into account when generating the suggestions; considering rustc's
behavior, I think this change doesn't warrant any extra configuration
flag.
Note that this is my first commit to RA, so I guess the approach taken
here might be suboptimal - certainly feels somewhat hacky, maybe there's
some better way of finding out the optimal import path 😅
fix: try obligation of `IndexMut` when infer
Closes#15842.
This issue arises because `K` is ambiguous if only inferred from `Index` trait, but is unique if inferred from `IndexMut`, but r-a doesn't use this info.
Fix panic with closure inside array len
I was working on #15947 and found out that we panic on this test:
```
fn main() {
let x = [(); &(&'static: loop { |x| {}; }) as *const _ as usize]
}
```
This PR fixes the panic. Closures in array len are still broken, but closure in const eval is not stable anyway.
TokenMap -> SpanMap rewrite
Opening early so I can have an overview over the full diff more easily, still very unfinished and lots of work to be done.
The gist of what this PR does is move away from assigning IDs to tokens in arguments and expansions and instead gives the subtrees the text ranges they are sourced from (made relative to some item for incrementality). This means we now only have a single map per expension, opposed to map for expansion and arguments.
A few of the things that are not done yet (in arbitrary order):
- [x] generally clean up the current mess
- [x] proc-macros, have been completely ignored so far
- [x] syntax fixups, has been commented out for the time being needs to be rewritten on top of some marker SyntaxContextId
- [x] macro invocation syntax contexts are not properly passed around yet, so $crate hygiene does not work in all cases (but most)
- [x] builtin macros do not set spans properly, $crate basically does not work with them rn (which we use)
~~- [ ] remove all uses of dummy spans (or if that does not work, change the dummy entries for dummy spans so that tests will not silently pass due to havin a file id for the dummy file)~~
- [x] de-queryfy `macro_expand`, the sole caller of it is `parse_macro_expansion`, and both of these are lru-cached with the same limit so having it be a query is pointless
- [x] docs and more docs
- [x] fix eager macro spans and other stuff
- [x] simplify include! handling
- [x] Figure out how to undo the sudden `()` expression wrapping in expansions / alternatively prioritize getting invisible delimiters working again
- [x] Simplify InFile stuff and HirFIleId extensions
~~- [ ] span crate containing all the file ids, span stuff, ast ids. Then remove the dependency injection generics from tt and mbe~~
Fixes https://github.com/rust-lang/rust-analyzer/issues/10300
Fixes https://github.com/rust-lang/rust-analyzer/issues/15685
fix: Diagnose everything in nested items, not just def diagnostics
Turns out we only calculated def diagnostics for these before (was wondering why I wasn't getting any type mismatches)
feat: implement tuple return type to tuple struct assist
This PR implements the `convert_tuple_return_type_to_struct` assist, for converting the return type of a function or method from a tuple to a tuple struct. Additionally, it moves the `to_camel_case` and `char_has_case` functions from `case_conv` to `stdx` so that they can be used similar to `to_lower_snake_case`.
[tuple_return_type_to_tuple_struct.webm](https://github.com/rust-lang/rust-analyzer/assets/52933714/2803ff58-fde3-4144-9495-7c7c7e139075)
Currently, the assist puts the struct definition above the function, or above the nearest `impl` or `trait` if applicable and only rewrites literal tuples that are returned in the body of the function. Additionally, it only attempts to rewrite simple tuple pattern usages with the corresponding tuple struct pattern but does so across files and modules.
I think that this is sufficient for the majority of use cases but I could be wrong. One thing I'm still not sure how to approach is handling `Self` and generics/lifetimes in the tuple type to be extracted. I was thinking of either manually figuring out what lifetimes and generics are in scope and using them (sort of similar to the `generate_function` assist) or maybe using `ctx.sema.resolve_type` and `generic_params` on `hir::Type` but this seems to not deal with lifetimes.
Closes#14293
Switch to in-tree rustc dependencies with a cfg flag
We can use this flag to detect and prevent breakages in rustc CI. (see #14846 and #15569)
~The `IN_RUSTC_REPOSITORY` is just a placeholder. Is there any existing cfg flag that rustc CI sets?~
(This is a large commit. The changes to
`compiler/rustc_middle/src/ty/context.rs` are the most important ones.)
The current naming scheme is a mess, with a mix of `_intern_`, `intern_`
and `mk_` prefixes, with little consistency. In particular, in many
cases it's easy to use an iterator interner when a (preferable) slice
interner is available.
The guiding principles of the new naming system:
- No `_intern_` prefixes.
- The `intern_` prefix is for internal operations.
- The `mk_` prefix is for external operations.
- For cases where there is a slice interner and an iterator interner,
the former is `mk_foo` and the latter is `mk_foo_from_iter`.
Also, `slice_interners!` and `direct_interners!` can now be `pub` or
non-`pub`, which helps enforce the internal/external operations
division.
It's not perfect, but I think it's a clear improvement.
The following lists show everything that was renamed.
slice_interners
- const_list
- mk_const_list -> mk_const_list_from_iter
- intern_const_list -> mk_const_list
- substs
- mk_substs -> mk_substs_from_iter
- intern_substs -> mk_substs
- check_substs -> check_and_mk_substs (this is a weird one)
- canonical_var_infos
- intern_canonical_var_infos -> mk_canonical_var_infos
- poly_existential_predicates
- mk_poly_existential_predicates -> mk_poly_existential_predicates_from_iter
- intern_poly_existential_predicates -> mk_poly_existential_predicates
- _intern_poly_existential_predicates -> intern_poly_existential_predicates
- predicates
- mk_predicates -> mk_predicates_from_iter
- intern_predicates -> mk_predicates
- _intern_predicates -> intern_predicates
- projs
- intern_projs -> mk_projs
- place_elems
- mk_place_elems -> mk_place_elems_from_iter
- intern_place_elems -> mk_place_elems
- bound_variable_kinds
- mk_bound_variable_kinds -> mk_bound_variable_kinds_from_iter
- intern_bound_variable_kinds -> mk_bound_variable_kinds
direct_interners
- region
- intern_region (unchanged)
- const
- mk_const_internal -> intern_const
- const_allocation
- intern_const_alloc -> mk_const_alloc
- layout
- intern_layout -> mk_layout
- adt_def
- intern_adt_def -> mk_adt_def_from_data (unusual case, hard to avoid)
- alloc_adt_def(!) -> mk_adt_def
- external_constraints
- intern_external_constraints -> mk_external_constraints
Other
- type_list
- mk_type_list -> mk_type_list_from_iter
- intern_type_list -> mk_type_list
- tup
- mk_tup -> mk_tup_from_iter
- intern_tup -> mk_tup
feat: Show witnesses of non-exhaustiveness in `missing-match-arm` diagnostic
Shamelessly copied from rustc. Thus reporting format is same.
This extends public api `hir::diagnostics::MissingMatchArms` with `uncovered_patterns: String` field. It does not expose data for implementing a quick fix yet.
-----
Worth to note: current implementation does not give a comprehensive list of missing patterns. Also mentioned in [paper](http://moscova.inria.fr/~maranget/papers/warn/warn.pdf):
> One may think that algorithm I should make an additional effort to provide more
> non-matching values, by systematically computing recursive calls on specialized
> matrices when possible, and by returning a list of all pattern vectors returned by
> recursive calls. We can first observe that it is not possible in general to supply the
> users with all non-matching values, since the signature of integers is (potentially)
> infinite.
feat: implement destructuring assignment
This is an attempt to implement destructuring assignments, or more specifically, type inference for [assignee expressions](https://doc.rust-lang.org/reference/expressions.html#place-expressions-and-value-expressions).
I'm not sure if this is the right approach, so I don't even expect this to be merged (hence the branch name 😉) but rather want to propose one direction we could choose. I don't mind getting merged if this is good enough though!
Some notes on the implementation choices:
- Assignee expressions are **not** desugared on HIR level unlike rustc, but are inferred directly along with other expressions. This matches the processing of other syntaxes that are desugared in rustc but not in r-a. I find this reasonable because r-a only needs to infer types and it's easier to relate AST nodes and HIR nodes, so I followed it.
- Assignee expressions obviously resemble patterns, so type inference for each kind of pattern and its corresponding assignee expressions share a significant amount of logic. I tried to reuse the type inference functions for patterns by introducing `PatLike` trait which generalizes assignee expressions and patterns.
- This is not the most elegant solution I suspect (and I really don't like the name of the trait!), but it's cleaner and the change is smaller than other ways I experimented, like making the functions generic without such trait, or making them take `Either<ExprId, PatId>` in place of `PatId`.
in case this is merged:
Closes#11532Closes#11839Closes#12322
- remove Valid, it serves no purpose and just obscures the diff
- rename some things
- don't use is_valid_candidate when searching for impl, it's not necessary
fix: #12441 False-positive type-mismatch error with generic future
I think the reason is same with #11815.
add ```Sized``` bound for ```AsyncBlockTypeImplTrait```.
Collect obligations from RPITs (Return Position `impl Trait`) of a function which is being inferred.
This allows inferring {unknown}s from RPIT bounds.
{kind=link}
{kind=link}
{kind=link}