Update to new browser-ui-test version
This new version brings a lot of new internal improvements (mostly around validating the commands input).
It also improved some command names and arguments.
r? `@notriddle`
rustdoc-search: shard the search result descriptions
## Preview
This makes no visual changes to rustdoc search. It's a pure perf improvement.
<details><summary>old</summary>
Preview: <http://notriddle.com/rustdoc-html-demo-10/doc/std/index.html?search=vec>
WebPageTest Comparison with before branch on a sort of worst case (searching `vec`, winds up downloading most of the shards anyway): <https://www.webpagetest.org/video/compare.php?tests=240317_AiDc61_2EM,240317_AiDcM0_2EN>
Waterfall diagram:
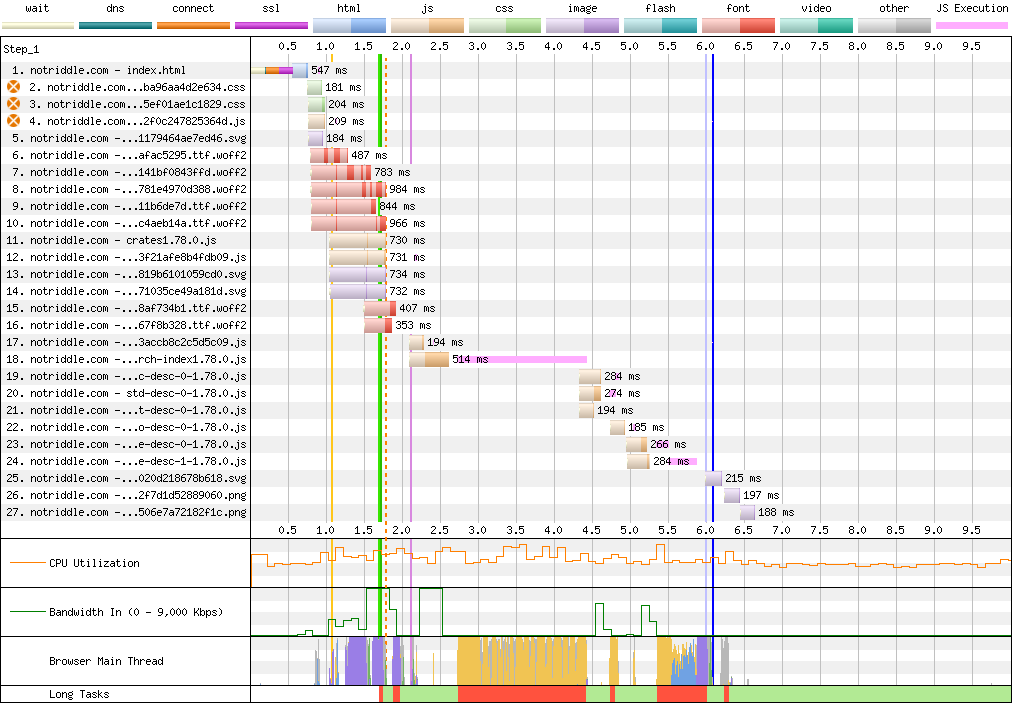
</details>
Preview: <http://notriddle.com/rustdoc-html-demo-10/doc2/std/index.html?search=vec>
WebPageTest Comparison with before branch on a sort of worst case (searching `vec`, winds up downloading most of the shards anyway): <https://www.webpagetest.org/video/compare.php?tests=240322_BiDcCH_13R,240322_AiDcJY_104>
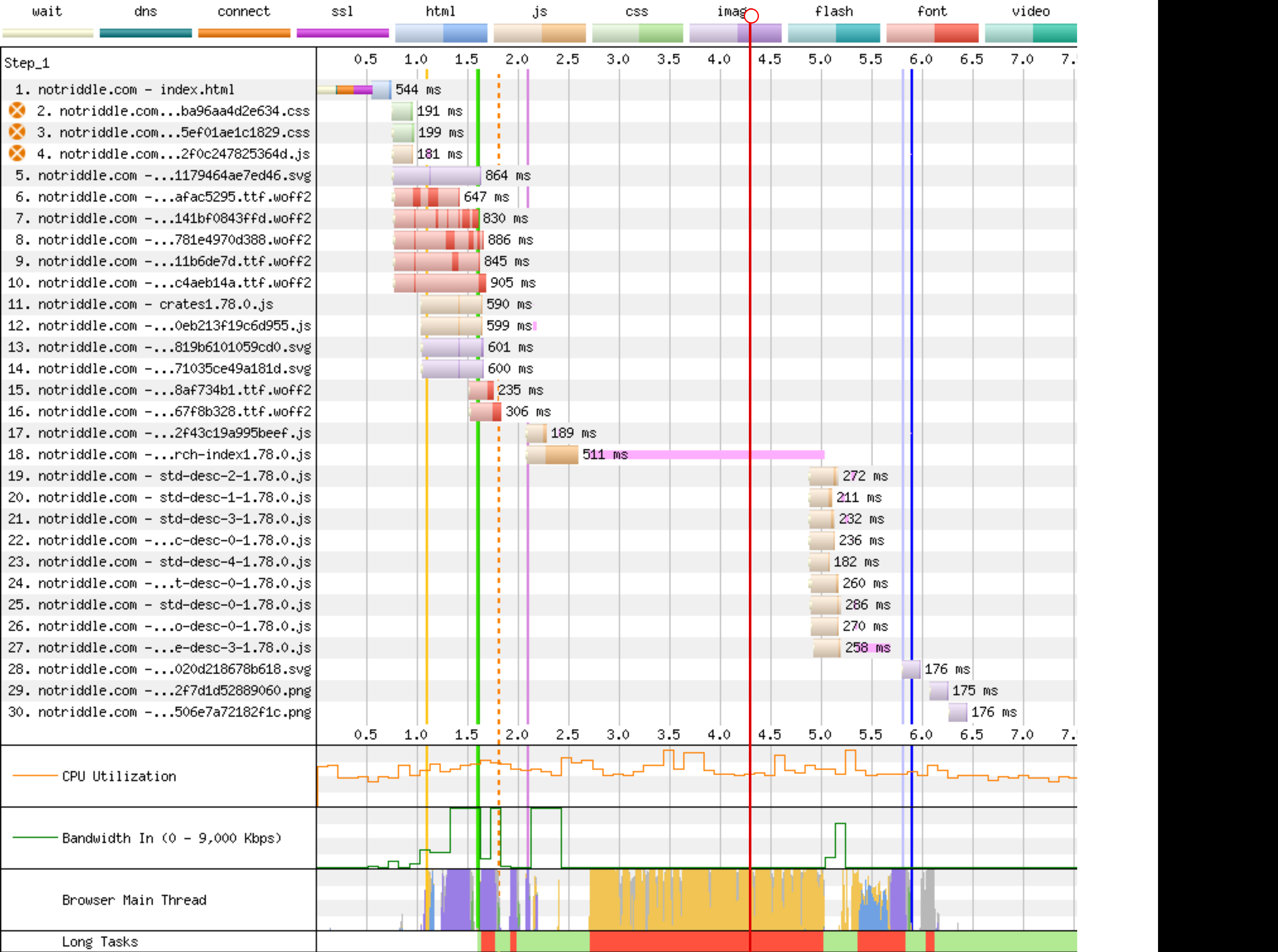
## Description
r? `@GuillaumeGomez`
The descriptions are, on almost all crates[^1], the majority of the size of the search index, even though they aren't really used for searching. This makes it relatively easy to separate them into their own files.
Additionally, this PR pulls out information about whether there's a description into a bitmap. This allows us to sort, truncate, *then* download.
This PR also bumps us to ES8. Out of the browsers we support, all of them support async functions according to caniuse.
https://caniuse.com/async-functions
[^1]:
<https://microsoft.github.io/windows-docs-rs/>, a crate with
44MiB of pure names and no descriptions for them, is an outlier
and should not be counted. But this PR should improve it, by replacing a long line of empty strings with a compressed bitmap with a single Run section. Just not very much.
## Detailed sizes
```console
$ cat test.sh
set -ex
cp ../search-index*.js search-index.js
awk 'FNR==NR {a++;next} FNR<a-3' search-index.js{,} | awk 'NR>1 {gsub(/\],\\$/,""); gsub(/^\["[^"]+",/,""); print} {next}' | sed -E "s:\\\\':':g" > search-index.json
jq -c '.t' search-index.json > t.json
jq -c '.n' search-index.json > n.json
jq -c '.q' search-index.json > q.json
jq -c '.D' search-index.json > D.json
jq -c '.e' search-index.json > e.json
jq -c '.i' search-index.json > i.json
jq -c '.f' search-index.json > f.json
jq -c '.c' search-index.json > c.json
jq -c '.p' search-index.json > p.json
jq -c '.a' search-index.json > a.json
du -hs t.json n.json q.json D.json e.json i.json f.json c.json p.json a.json
$ bash test.sh
+ cp ../search-index1.78.0.js search-index.js
+ awk 'FNR==NR {a++;next} FNR<a-3' search-index.js search-index.js
+ awk 'NR>1 {gsub(/\],\\$/,""); gsub(/^\["[^"]+",/,""); print} {next}'
+ sed -E 's:\\'\'':'\'':g'
+ jq -c .t search-index.json
+ jq -c .n search-index.json
+ jq -c .q search-index.json
+ jq -c .D search-index.json
+ jq -c .e search-index.json
+ jq -c .i search-index.json
+ jq -c .f search-index.json
+ jq -c .c search-index.json
+ jq -c .p search-index.json
+ jq -c .a search-index.json
+ du -hs t.json n.json q.json D.json e.json i.json f.json c.json p.json a.json
64K t.json
800K n.json
8.0K q.json
4.0K D.json
16K e.json
192K i.json
544K f.json
4.0K c.json
36K p.json
20K a.json
```
These are, roughly, the size of each section in the standard library (this tool actually excludes libtest, for parsing-json-with-awk reasons, but libtest is tiny so it's probably not important).
t = item type, like "struct", "free fn", or "type alias". Since one byte is used for every item, this implies that there are approximately 64 thousand items in the standard library.
n = name, and that's now the largest section of the search index with the descriptions removed from it
q = parent *module* path, stored parallel to the items within
D = the size of each description shard, stored as vlq hex numbers
e = empty description bit flags, stored as a roaring bitmap
i = parent *type* index as a link into `p`, stored as decimal json numbers; used only for associated types; might want to switch to vlq hex, since that's shorter, but that would be a separate pr
f = function signature, stored as lists of lists that index into `p`
c = deprecation flag, stored as a roaring bitmap
p = parent *type*, stored separately and linked into from `i` and `f`
a = alias, as [[key, value]] pairs
## Search performance
http://notriddle.com/rustdoc-html-demo-11/perf-shard/index.html
For example, in stm32f4:
<table><thead><tr><th>before<th>after</tr></thead>
<tbody><tr><td>
```
Testing T -> U ... in_args = 0, returned = 0, others = 200
wall time = 617
Testing T, U ... in_args = 0, returned = 0, others = 200
wall time = 198
Testing T -> T ... in_args = 0, returned = 0, others = 200
wall time = 282
Testing crc32 ... in_args = 0, returned = 0, others = 0
wall time = 426
Testing spi::pac ... in_args = 0, returned = 0, others = 0
wall time = 673
```
</td><td>
```
Testing T -> U ... in_args = 0, returned = 0, others = 200
wall time = 716
Testing T, U ... in_args = 0, returned = 0, others = 200
wall time = 207
Testing T -> T ... in_args = 0, returned = 0, others = 200
wall time = 289
Testing crc32 ... in_args = 0, returned = 0, others = 0
wall time = 418
Testing spi::pac ... in_args = 0, returned = 0, others = 0
wall time = 687
```
</td></tr><tr><td>
```
user: 005.345 s
sys: 002.955 s
wall: 006.899 s
child_RSS_high: 583664 KiB
group_mem_high: 557876 KiB
```
</td><td>
```
user: 004.652 s
sys: 000.565 s
wall: 003.865 s
child_RSS_high: 538696 KiB
group_mem_high: 511724 KiB
```
</td></tr>
</table>
This perf tester is janky and unscientific enough that the apparent differences might just be noise. If it's not an order of magnitude, it's probably not real.
## Future possibilities
* Currently, results are not shown until the descriptions are downloaded. Theoretically, the description-less results could be shown. But actually doing that, and making sure it works properly, would require extra work (we have to be careful to avoid layout jumps).
* More than just descriptions can be sharded this way. But we have to be careful to make sure the size wins are worth the round trips. Ideally, data that’s needed only for display should be sharded while data needed for search isn’t.
* [Full text search](https://internals.rust-lang.org/t/full-text-search-for-rustdoc-and-doc-rs/20427) also needs this kind of infrastructure. A good implementation might store a compressed bloom filter in the search index, then download the full keyword in shards. But, we have to be careful not just of the amount readers have to download, but also of the amount that [publishers](https://gist.github.com/notriddle/c289e77f3ed469d1c0238d1d135d49e1) have to store.
rustdoc: heavily simplify the synthesis of auto trait impls
`gd --numstat HEAD~2 HEAD src/librustdoc/clean/auto_trait.rs`
**+315 -705** 🟩🟥🟥🟥⬛
---
As outlined in issue #113015, there are currently 3[^1] large separate routines that “clean” `rustc_middle::ty` data types related to generics & predicates to rustdoc data types. Every single one has their own kinds of bugs. While I've patched a lot of bugs in each of the routines in the past, it's about time to unify them. This PR is only the first in a series. It completely **yanks** the custom “bounds cleaning” of mod `auto_trait` and reuses the routines found in mod `simplify`. As alluded to, `simplify` is also flawed but it's still more complete than `auto_trait`'s routines. [See also my review comment over at `tests/rustdoc/synthetic_auto/bounds.rs`](https://github.com/rust-lang/rust/pull/123340#discussion_r1546900539).
This is preparatory work for rewriting “bounds cleaning” from scratch in follow-up PRs in order to finally [fix] #113015.
Apart from that, I've eliminated all potential sources of *instability* in the rendered output.
See also #119597. I'm pretty sure this fixes#119597.
This PR does not attempt to fix [any other issues related to synthetic auto trait impls](https://github.com/rust-lang/rust/issues?q=is%3Aissue+is%3Aopen+label%3AA-synthetic-impls%20label%3AA-auto-traits).
However, it's definitely meant to be a *stepping stone* by making `auto_trait` more contributor-friendly.
---
* Replace `FxHash{Map,Set}` with `FxIndex{Map,Set}` to guarantee a stable iteration order
* Or as a perf opt, `UnordSet` (a thin wrapper around `FxHashSet`) in cases where we never iterate over the set.
* Yes, we do make use of `swap_remove` but that shouldn't matter since all the callers are deterministic. It does make the output less “predictable” but it's still better than before. Ofc, I rely on `rustc_infer` being deterministic. I hope that holds.
* Utilizing `clean::simplify` over the custom “bounds cleaning” routines wipes out the last reference to `collect_referenced_late_bound_regions` in rustdoc (`simplify` uses `bound_vars`) which was a source of instability / unpredictability (cc #116388)
* Remove the types `RegionTarget` and `RegionDeps` from `librustdoc`. They were duplicates of the identical types found in `rustc`. Just import them from `rustc`. For some reason, they were duplicated when splitting `auto_trait` in two in #49711.
* Get rid of the useless “type namespace” `AutoTraitFinder` in `librustdoc`
* The struct only held a `DocContext`, it was over-engineered
* Turn the associated functions into free ones
* Eliminates rightward drift; increases legibility
* `rustc` also contains a useless `AutoTraitFinder` struct but I plan on removing that in a follow-up PR
* Rename a bunch of methods to be way more descriptive
* Eliminate `use super::*;`
* Lead to `clean/mod.rs` accumulating a lot of unnecessary imports
* Made `auto_traits` less modular
* Eliminate a custom `TypeFolder`: We can just use the rustc helper `fold_regions` which does that for us
I plan on adding extensive documentation to `librustdoc`'s `auto_trait` in follow-up PRs.
I don't want to do that in this PR because further refactoring & bug fix PRs may alter the overall structure of `librustdoc`'s & `rustc`'s `auto_trait` modules to a great degree. I'm slowly digging into the dark details of `rustc`'s `auto_trait` module again and once I have the full picture I will be able to provide proper docs.
---
While this PR does indeed touch `rustc`'s `auto_trait` — mostly tiny refactorings — I argue this PR doesn't need any compiler reviewers next to rustdoc ones since that module falls under the purview of rustdoc — it used to be part of `librustdoc` after all (#49711).
Sorry for not having split this into more commits. If you'd like me to I can try to split it into more atomic commits retroactively. However, I don't know if that would actually make reviewing easier. I think the best way to review this might just be to place the master version of `auto_trait` on the left of your screen and the patched one on the right, not joking.
r? `@GuillaumeGomez`
[^1]: Or even 4 depending on the way you're counting.
Only allow compiler_builtins to call LLVM intrinsics, not any link_name function
This is another case of accidental reliance on `inline(never)` like I rooted out in https://github.com/rust-lang/rust/pull/118770. Without this PR, attempting to build some large programs with `-Zcross-crate-inline-threshold=yes` with a sysroot also compiled with that flag will result in linker errors like this:
```
= note: /usr/bin/ld: /tmp/cargo-installNrfN4T/x86_64-unknown-linux-gnu/release/deps/libcompiler_builtins-d2a9b69f4e45b883.rlib(compiler_builtins-d2a9b69f4e45b883.compiler_builtins.dbbc6c2ca970faa4-cgu.0.rcgu.o): in function `core::panicking::panic_fmt':
/home/ben/.rustup/toolchains/nightly-x86_64-unknown-linux-gnu/lib/rustlib/src/rust/library/core/src/panicking.rs:72:(.text.unlikely._ZN4core9panicking9panic_fmt17ha407cc99e97c942fE+0x31): undefined reference to `rust_begin_unwind'
```
With `-Zcross-crate-inline-threshold=yes` we can inline `panic_fmt` into `compiler_builtins`. Then we end up with a call to an upstream monomorphization, but one that has a `link_name` set. But unlike LLVM's magic intrinsic names, this link name is going to make it to the linker, and then we have a problem.
This logic looks scuffed, but also we're doing this in 4 other places. Don't know if that means it's good or bad.
1684a753db/compiler/rustc_codegen_cranelift/src/abi/mod.rs (L386)1684a753db/compiler/rustc_ast_passes/src/feature_gate.rs (L306)1684a753db/compiler/rustc_codegen_ssa/src/codegen_attrs.rs (L609)1684a753db/compiler/rustc_codegen_gcc/src/declare.rs (L170)
Note impact of `-Cstrip` on backtraces
It is not always clear to people what the impact of `-Cstrip` options are. They are a common question on sites like StackOverflow, and sometimes people even report bugs with "no backtrace" after deliberately mangling the symbol table. We cannot exhaustively document every permutation, but we should warn people about common effects.
Eagerly instantiate closure/coroutine-like bounds with placeholders to deal with binders correctly
A follow-up to #119849, however it aims to fix a different set of issues. Currently, we have trouble confirming goals where built-in closure/fnptr/coroutine signatures are compared against higher-ranked goals.
Currently, we don't support goals like `for<'a> fn(&'a ()): Fn(&'a ())` because we don't expect the self type of goal to reference any bound regions from the goal, because we don't really know how to deal with the double binder of predicate + self type. However, this definitely can be reached (#121653) -- and in fact, it results in post-mono errors in the case of #112347 where the builtin type (e.g. a coroutine) is hidden behind a TAIT.
The proper fix here is to instantiate the goal before trying to extract the signature from the self type. See final two commits.
r? lcnr
Update `ParamEnv` docs
There is now a wealth of information in the dev guide about `ParamEnv` so we should explicitly link to it from the doc comments. I also added a caution against using `ParamEnv` and removed the comment about it being "suitable for type checking" as you should practically never use `ParamEnv::empty` for type checking
r? `@compiler-errors`
It is not always clear to people what the impact of `-Cstrip` options are.
They are a common question on sites like StackOverflow, and sometimes
people even report bugs with "no backtrace" after deliberately mangling
the symbol table. We cannot exhaustively document every permutation, but
we should warn people about common effects.
chore: fix footnotes/links in `platform-support.md`
A missing newline between two references is resulting in some links/footnotes not rendering properly. This PR fixes this.
Refactor stack overflow handling
Currently, every platform must implement a `Guard` that protects a thread from stack overflow. However, UNIX is the only platform that actually does so. Windows has a different mechanism for detecting stack overflow, while the other platforms don't detect it at all. Also, the UNIX stack overflow handling is split between `sys::pal::unix::stack_overflow`, which implements the signal handler, and `sys::pal::unix::thread`, which detects/installs guard pages.
This PR cleans this by getting rid of `Guard` and unifying UNIX stack overflow handling inside `stack_overflow` (commit 1). Therefore we can get rid of `sys_common::thread_info`, which stores `Guard` and the current `Thread` handle and move the `thread::current` TLS variable into `thread` (commit 2).
The second commit is not strictly speaking necessary. To keep the implementation clean, I've included it here, but if it causes too much noise, I can split it out without any trouble.
match lowering: handle or-patterns one layer at a time
`create_or_subcandidates` and `merge_trivial_subcandidates` both call themselves recursively to handle nested or-patterns, which is hard to follow. In this PR I avoid the need for that; we now process a single "layer" of or-patterns at a time.
By calling back into `match_candidates`, we only need to expand one layer at a time. Conversely, since we always try to simplify a layer that we just expanded (thanks to https://github.com/rust-lang/rust/pull/123067), we only have to merge one layer at a time.
r? `@matthewjasper`
Don't inherit codegen attrs from parent static
Putting this up partly for discussion and partly for review. Specifically, in #121644, `@oli-obk` designed a system that creates new static items for representing nested allocations in statics. However, in that PR, oli made it so that these statics inherited the codegen attrs from the parent.
This causes problems such as colliding symbols with `#[export_name]` and ICEs with `#[no_mangle]` since these synthetic statics have no `tcx.item_name(..)`.
So the question is, is there any case where we *do* want to inherit codegen attrs from the parent? The only one that seems a bit suspicious is the thread-local attribute. And there may be some interesting interactions with the coverage attributes as well...
Fixes (after backport) #123274. Fixes#123243. cc #121644.
r? `@oli-obk` cc `@nnethercote` `@RalfJung` (reviewers on that pr)
Refactor the way bootstrap invokes `cargo miri`
Instead of basically doing `cargo run --manifest-path=<cargo-miri's manifest> -- miri`, let's invoke the `cargo-miri` binary directly. That means less indirections, and also makes it easier to e.g. run the libcore test suite in Miri. (But there are still other issues with that.)
Also also adjusted Miri's stage numbering so that it is consistent with rustc/rustdoc.
This also makes `./x.py test miri` honor `--no-doc`.
And this fixes https://github.com/rust-lang/rust/issues/123177 by moving where we handle parallel_compiler.
Fix error message for `env!` when env var is not valid Unicode
Currently (without this PR) the `env!` macro emits an ```environment variable `name` not defined at compile time``` error when the environment variable is defined, but not a valid Unicode string. This PR introduces a separate more accurate error message, and a test to verify this behaviour.
For reference, before this PR, the new test would have outputted:
```
error: environment variable `NON_UNICODE_VAR` not defined at compile time
--> non_unicode_env.rs:2:13
|
2 | let _ = env!("NON_UNICODE_VAR");
| ^^^^^^^^^^^^^^^^^^^^^^^
|
= help: use `std::env::var("NON_UNICODE_VAR")` to read the variable at run time
= note: this error originates in the macro `env` (in Nightly builds, run with -Z macro-backtrace for more info)
error: aborting due to 1 previous error
```
whereas with this PR, the test ouputs:
```
error: environment variable `NON_UNICODE_VAR` is not a valid Unicode string
--> non_unicode_env.rs:2:13
|
2 | let _ = env!("NON_UNICODE_VAR");
| ^^^^^^^^^^^^^^^^^^^^^^^
|
= note: this error originates in the macro `env` (in Nightly builds, run with -Z macro-backtrace for more info)
error: aborting due to 1 previous error
```
Use the `Align` type when parsing alignment attributes
Use the `Align` type in `rustc_attr::parse_alignment`, removing the need to call `Align::from_bytes(...).unwrap()` later in the compilation process.