Historically, we intentinally violated JSON-RPC spec here by hard
crashing. The idea was to poke both the clients and servers to fix
stuff.
However, this is confusing for server implementors, and falls down in
one important place -- protocol extension are not always backwards
compatible, which causes crashes simply due to version mismatch. We
had once such case with our own extension, and one for semantic
tokens.
So let's be less adventerous and just err on the err side!
Percentage is a UI concern, the physical fact here is fraction. It's
sad that percentage bleeds into the protocol level, we even duplicated
this bad API ourselves!
5693: Fix no inlay hints / unresolved tokens until manual edit to refresh r=jonas-schievink a=Veetaha
Fixes https://github.com/rust-analyzer/rust-analyzer/issues/5349
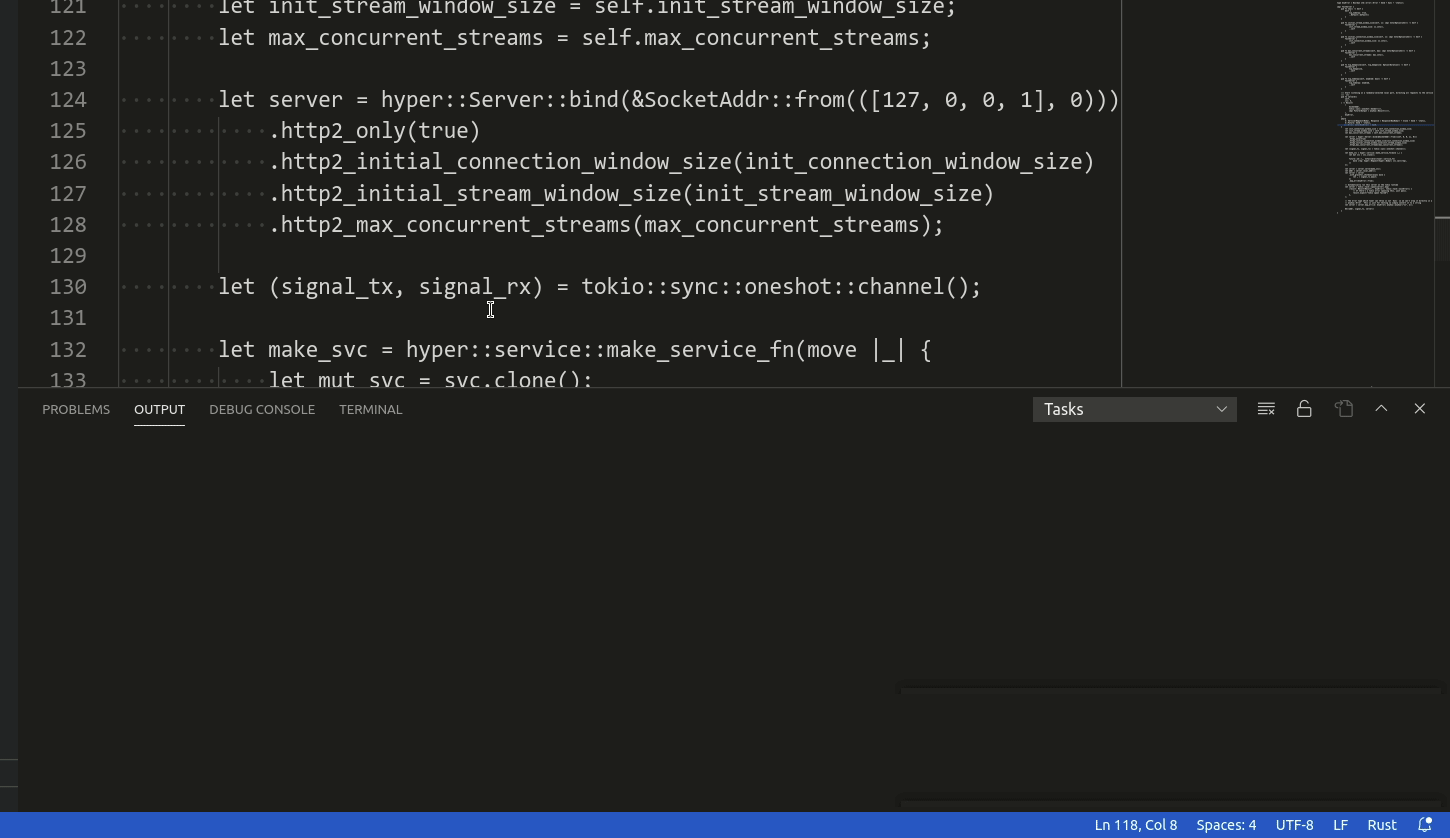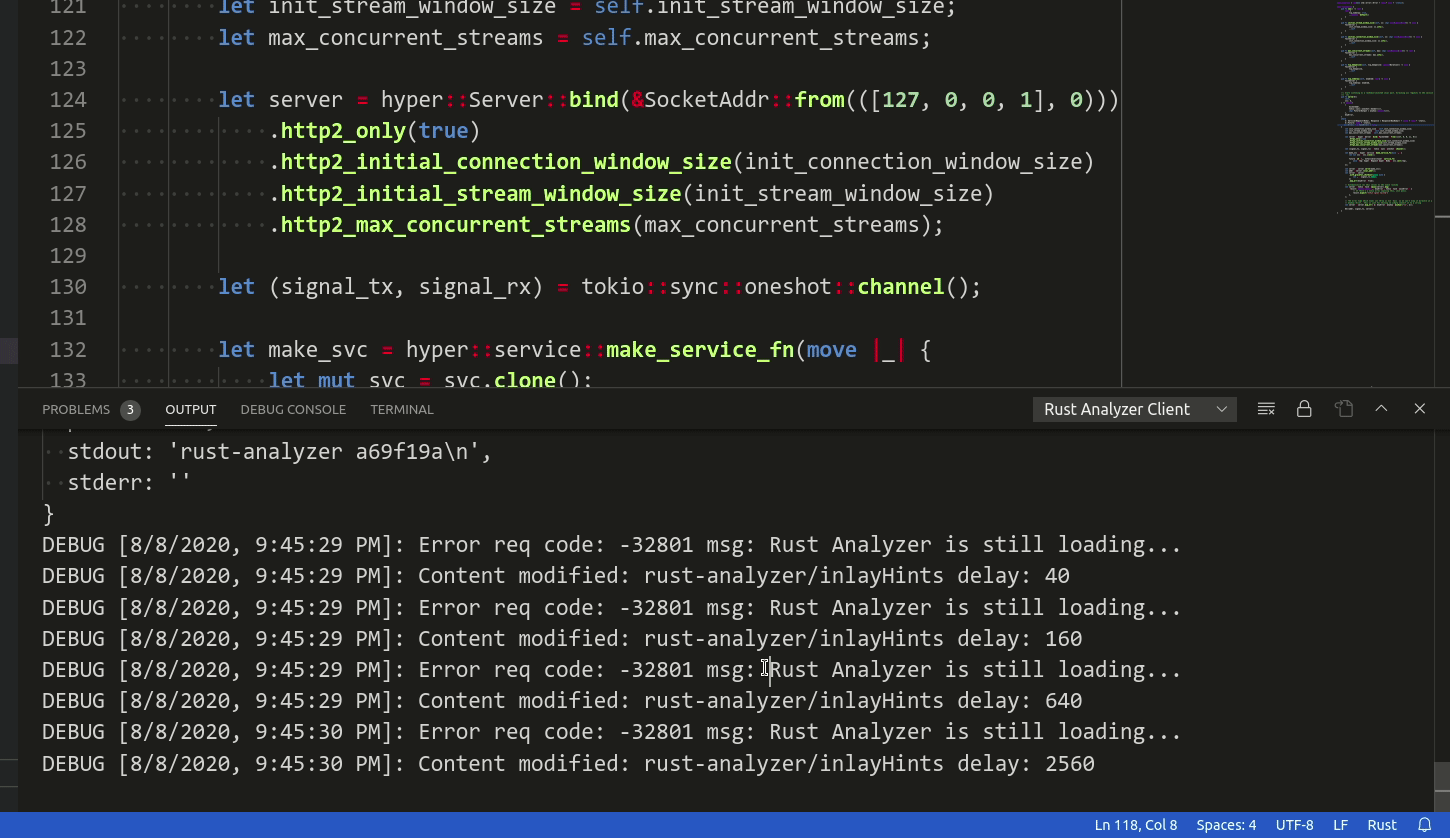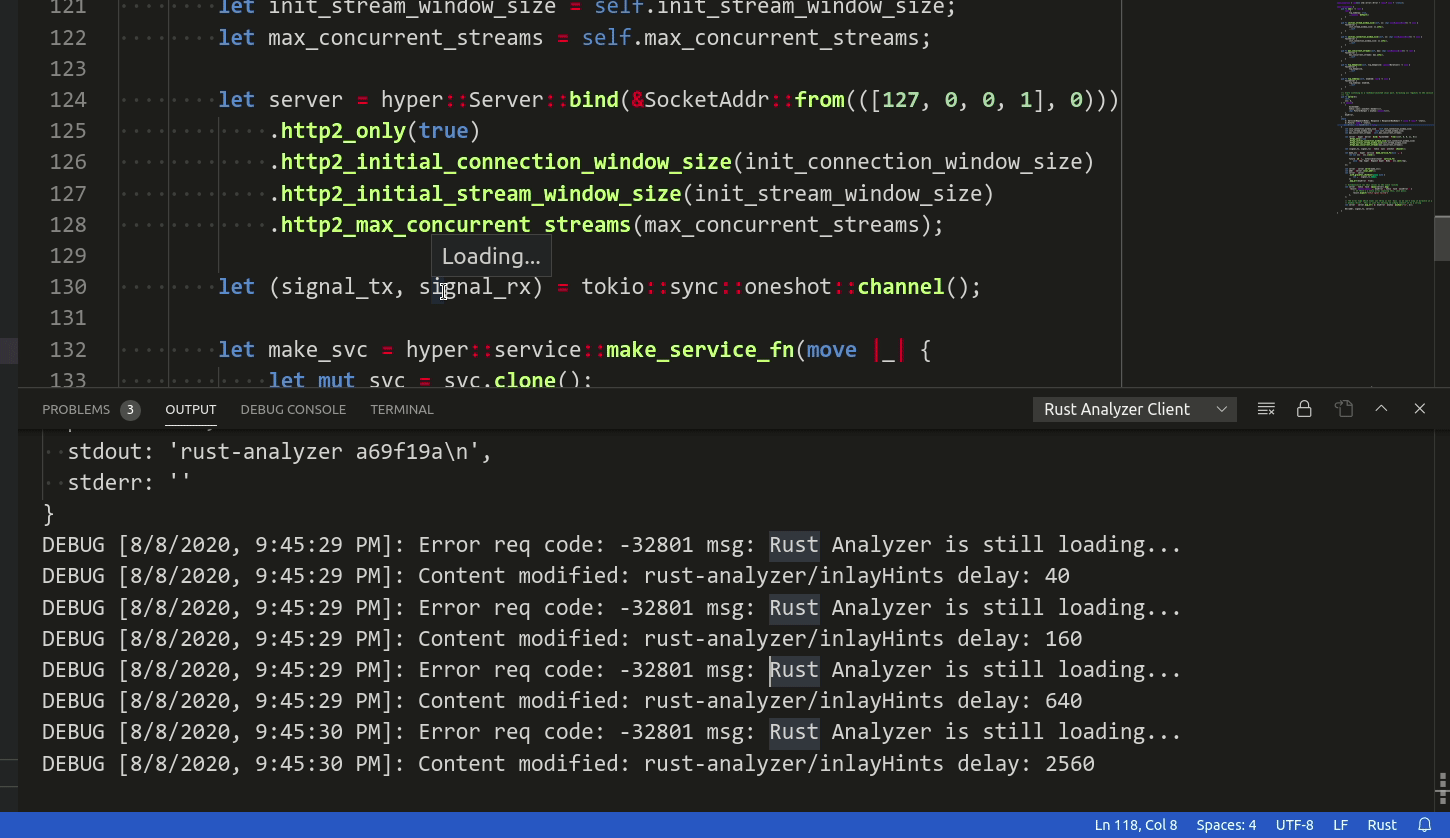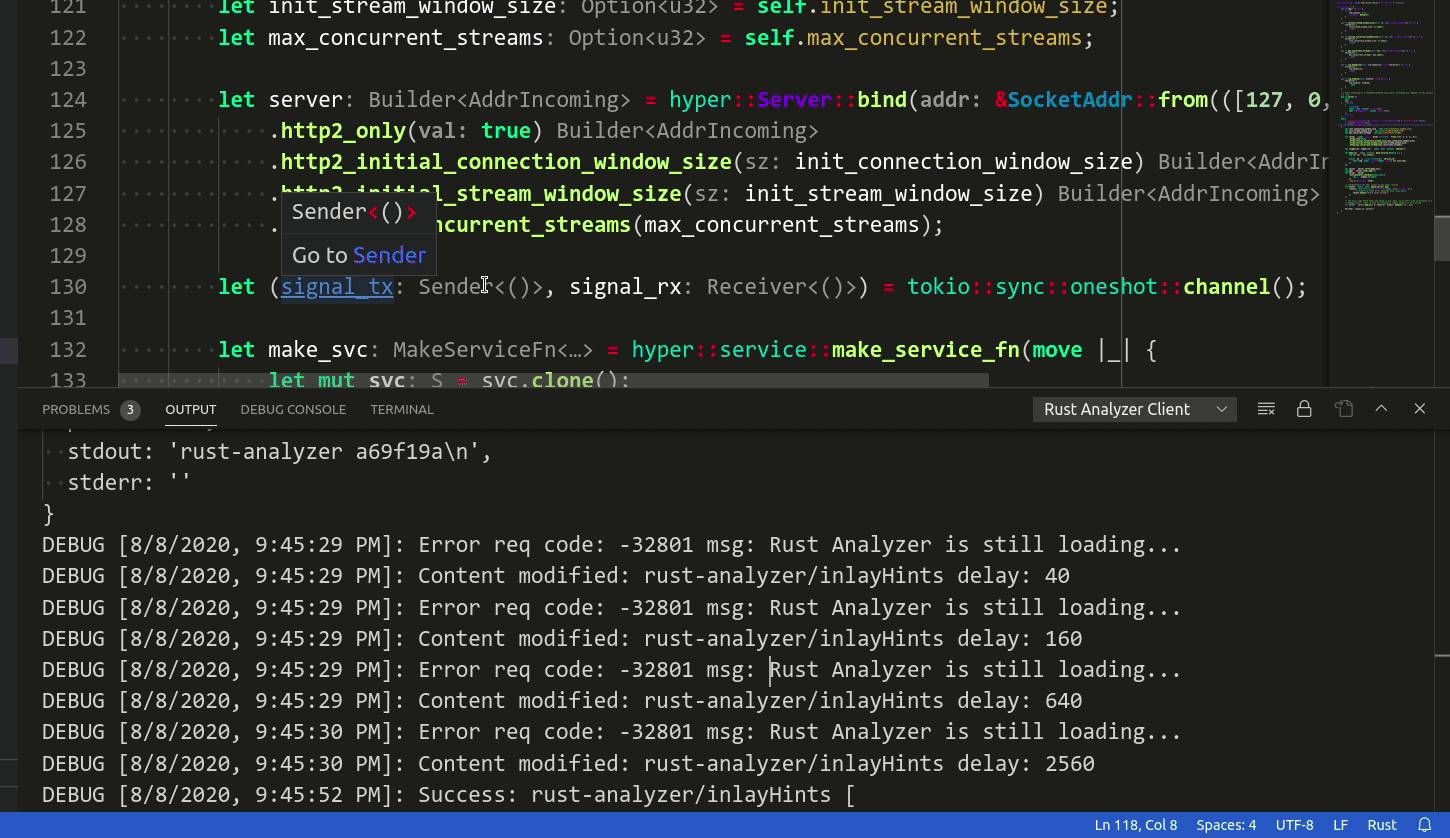
Now we return ContentModified during the workspace loading. This signifies the language
client to retry the operation (i.e. the client will
continue polling the server while it returns ContentModified).
I believe that there might be cases of overly big projects where the backoff
logic we have setup in `sendRequestWithRetry` (which we use for inlay hints)
might bail too early (currently the largest retry standby time is 10 seconds).
However, I've tried on one of my project with 500+ dependencies and it is still enough.
Here are the examples before/after the change (the gifs are quite lengthy because they show testing rather large cargo workspace).
<details>
<summary>Before</summary>
Here you can see that the client receives empty array of inlay hints and does nothing more.
Same applies to semantic tokens. The client receives unresolved tokens and does nothing more.
The user needs to do a manual edit to refresh the editor.

</details>
<details>
<summary>After</summary>
Here the server returns ContentModified, so the client periodically retries the requests and eventually receives the wellformed response.
</details>
Co-authored-by: Veetaha <veetaha2@gmail.com>
No we return ContentModified during the workspace loading. This signifies the language
client to retry the operation (i.e. the client will
continue polling the server while it returns ContentModified).
I believe that there might be cases of overly big projects where the backoff
logic we have setup in `sendRequestWithRetry` (which we use for inlay hints)
might bail too early (currently the largest retry standby time is 10 seconds).
However, I've tried on one of my project with 500+ dependencies and it is still enough.
5526: Handle semantic token deltas r=kjeremy a=kjeremy
This basically takes the naive approach where we always compute the tokens but save space sending over the wire which apparently solves some GC problems with vscode.
This is waiting for https://github.com/gluon-lang/lsp-types/pull/174 to be merged. I am also unsure of the best way to stash the tokens into `DocumentData` in a safe manner.
Co-authored-by: kjeremy <kjeremy@gmail.com>
Co-authored-by: Jeremy Kolb <kjeremy@gmail.com>
{kind=link}
{kind=link}