19 KiB
Architecture
This document describes the high-level architecture of rust-analyzer. If you want to familiarize yourself with the code base, you are just in the right place!
See also the guide, which walks through a particular snapshot of rust-analyzer code base.
Yet another resource is this playlist with videos about various parts of the analyzer:
https://www.youtube.com/playlist?list=PL85XCvVPmGQho7MZkdW-wtPtuJcFpzycE
Note that the guide and videos are pretty dated, this document should be in generally fresher.
See also this implementation-oriented blog posts:
- https://rust-analyzer.github.io/blog/2019/11/13/find-usages.html
- https://rust-analyzer.github.io/blog/2020/07/20/three-architectures-for-responsive-ide.html
- https://rust-analyzer.github.io/blog/2020/09/16/challeging-LR-parsing.html
- https://rust-analyzer.github.io/blog/2020/09/28/how-to-make-a-light-bulb.html
- https://rust-analyzer.github.io/blog/2020/10/24/introducing-ungrammar.html
Bird's Eye View
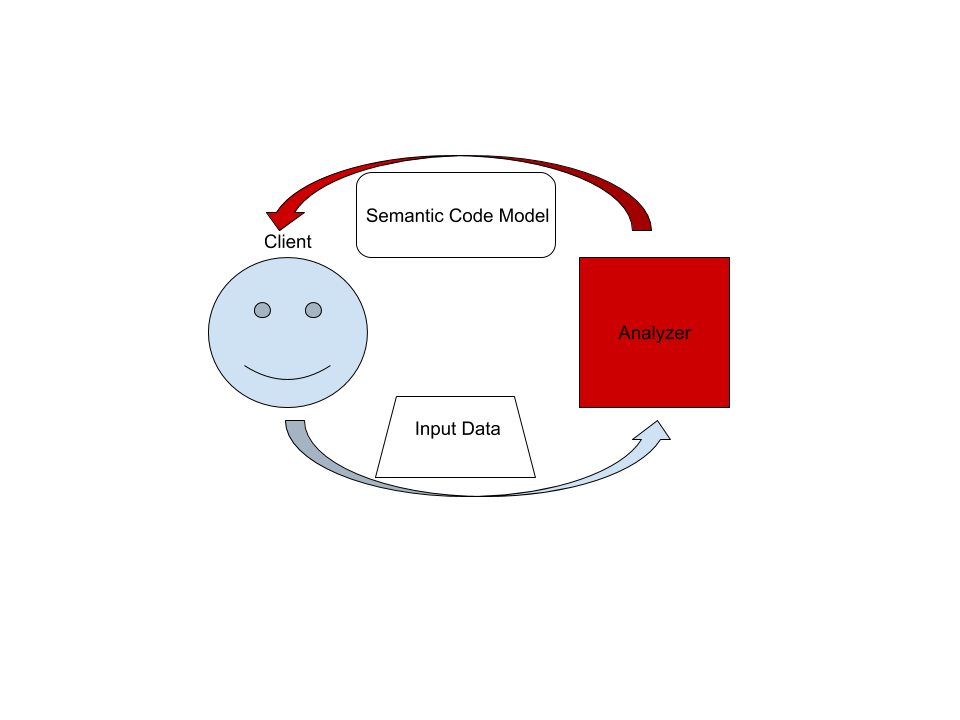
On the highest level, rust-analyzer is a thing which accepts input source code from the client and produces a structured semantic model of the code.
More specifically, input data consists of a set of test files ((PathBuf, String) pairs) and information about project structure, captured in the so called CrateGraph.
The crate graph specifies which files are crate roots, which cfg flags are specified for each crate and what dependencies exist between the crates.
This the input (ground) state.
The analyzer keeps all this input data in memory and never does any IO.
Because the input data are source code, which typically measures in tens of megabytes at most, keeping everything in memory is OK.
A "structured semantic model" is basically an object-oriented representation of modules, functions and types which appear in the source code. This representation is fully "resolved": all expressions have types, all references are bound to declarations, etc. This is derived state.
The client can submit a small delta of input data (typically, a change to a single file) and get a fresh code model which accounts for changes.
The underlying engine makes sure that model is computed lazily (on-demand) and can be quickly updated for small modifications.
Code Map
This section talks briefly about various important directories an data structures. Pay attention to the Architecture Invariant sections. They often talk about things which are deliberately absent in the source code.
Note also which crates are API Boundaries. Remember, rules at the boundary are different.
xtask
This is rust-analyzer's "build system". We use cargo to compile rust code, but there are also various other tasks, like release management or local installation. They are handled by Rust code in the xtask directory.
editors/code
VS Code plugin.
libs/
rust-analyzer independent libraries which we publish to crates.io. It not heavily utilized at the moment.
crates/parser
It is a hand-written recursive descent parser, which produces a sequence of events like "start node X", "finish node Y".
It works similarly to
kotlin's parser,
which is a good source of inspiration for dealing with syntax errors and incomplete input.
Original libsyntax parser is what we use for the definition of the Rust language.
TreeSink and TokenSource traits bridge the tree-agnostic parser from grammar with rowan trees.
Architecture Invariant: the parser is independent of the particular tree structure and particular representation of the tokens.
It transforms one flat stream of events into another flat stream of events.
Token independence allows us to pares out both text-based source code and tt-based macro input.
Tree independence allows us to more easily vary the syntax tree implementation.
It should also unlock efficient light-parsing approaches.
For example, you can extract the set of names defined in a file (for typo correction) without building a syntax tree.
Architecture Invariant: parsing never fails, the parser produces (T, Vec<Error>) rather than Result<T, Error>.
crates/syntax
Rust syntax tree structure and parser. See RFC and ./syntax.md for some design notes.
- rowan library is used for constructing syntax trees.
astprovides a type safe API on top of the rawrowantree.ungrammardescription of the grammar, which is used to generatesyntax_kindsandastmodules, usingcargo xtask codegencommand.
Tests for ra_syntax are mostly data-driven.
test_data/parser contains subdirectories with a bunch of .rs (test vectors) and .txt files with corresponding syntax trees.
During testing, we check .rs against .txt.
If the .txt file is missing, it is created (this is how you update tests).
Additionally, running cargo xtask codegen will walk the grammar module and collect all // test test_name comments into files inside test_data/parser/inline directory.
To update test data, run with UPDATE_EXPECT variable:
env UPDATE_EXPECT=1 cargo qt
After adding a new inline test you need to run cargo xtest codegen and also update the test data as described above.
Note api_walkthrough
in particular: it shows off various methods of working with syntax tree.
See #93 for an example PR which fixes a bug in the grammar.
Architecture Invariant: syntax crate is completely independent from the rest of rust-analyzer, it knows nothing about salsa or LSP.
This is important because it is possible to useful tooling using only syntax tree.
Without semantic information, you don't need to be able to build code, which makes the tooling more robust.
See also https://web.stanford.edu/~mlfbrown/paper.pdf.
You can view the syntax crate as an entry point to rust-analyzer.
sytax crate is an API Boundary.
Architecture Invariant: syntax tree is a value type. The tree is fully determined by the contents of its syntax nodes, it doesn't need global context (like an interner) and doesn't store semantic info. Using the tree as a store for semantic info is convenient in traditional compilers, but doesn't work nicely in the IDE. Specifically, assists and refactors require transforming syntax trees, and that becomes awkward if you need to do something with the semantic info.
Architecture Invariant: syntax tree is build for a single file. This is to enable parallel parsing of all files.
Architecture Invariant: Syntax trees are by design incomplete and do not enforce well-formedness.
If an AST method returns an Option, it can be None at runtime, even if this is forbidden by the grammar.
crates/base_db
We use the salsa crate for incremental and on-demand computation.
Roughly, you can think of salsa as a key-value store, but it also can compute derived values using specified functions. The base_db crate provides basic infrastructure for interacting with salsa.
Crucially, it defines most of the "input" queries: facts supplied by the client of the analyzer.
Reading the docs of the base_db::input module should be useful: everything else is strictly derived from those inputs.
Architecture Invariant: particularities of the build system are not the part of the ground state.
In particular, base_db knows nothing about cargo.
The CrateGraph structure is used to represent the dependencies between the crates abstractly.
Architecture Invariant: base_db doesn't know about file system and file paths.
Files are represented with opaque FileId, there's no operation to get an std::path::Path out of the FileId.
crates/hir_expand, crates/hir_def, crates/hir_ty
These crates are the brain of rust-analyzer. This is the compiler part of the IDE.
hir_xxx crates have a strong ECS flavor, in that they work with raw ids and directly query the database.
There's little abstraction here.
These crates integrate deeply with salsa and chalk.
Name resolution, macro expansion and type inference all happen here. These crates also define various intermediate representations of the core.
ItemTree condenses a single SyntaxTree into a "summary" data structure, which is stable over modifications to function bodies.
DefMap contains the module tree of a crate and stores module scopes.
Body stores information about expressions.
Architecture Invariant: this crates are not, and will never be, an api boundary.
Architecture Invariant: these creates explicitly care about being incremental.
The core invariant we maintain is "typing inside a function's body never invalidates global derived data".
Ie, if you change body of foo, all facts about bar should remain intact.
Architecture Invariant: hir exists only in context of particular crate instance with specific CFG flags. The same syntax may produce several instances of HIR if the crate participates in the crate graph more than once.
crates/hir
The top-level hir crate is an API Boundary.
If you think about "using rust-analyzer as a library", hir crate is most likely the façade you'll be talking to.
It wraps ECS-style internal API into a more OO-flavored API (with an extra db argument for each call).
Architecture Invariant: hir provides a static, fully resolved view of the code.
While internal hir_* crates compute things, hir, from the outside, looks like an inert data structure.
hir also handles the delicate task of going from syntax to the corresponding hir.
Remember that the mapping here is one-to-many.
See Semantics type and source_to_def module.
Note in particular a curious recursive structure in source_to_def.
We first resolve the parent syntax node to the parent hir element.
Then we ask the hir parent what syntax children does it have.
Then we look for our node in the set of children.
This is the heart of many IDE features, like goto definition, which start with figuring out a hir node at the cursor. This is some kind of (yet unnamed) uber-IDE pattern, as it is present in Roslyn and Kotlin as well.
crates/ide
The ide crate build's on top of hir semantic model to provide high-level IDE features like completion or goto definition.
It is an API Boundary.
If you want to use IDE parts of rust-analyzer via LSP, custom flatbuffers-based protocol or just as a library in your text editor, this is the right API.
Architecture Invariant: ide crate's API is build out of POD types with public fields.
The API uses editor's terminology, it talks about offsets and string labels rathe than in terms of definitions or types.
It is effectively the view in MVC and viewmodel in MVVM.
All arguments and return types are conceptually serializable.
In particular, syntax tress and and hir types are generally absent from the API (but are used heavily in the implementation).
Shout outs to LSP developers for popularizing the idea that "UI" is a good place to draw a boundary at.
ide is also the first crate which has the notion of change over time.
AnalysisHost is a state to which you can transactonally apply_change.
Analysis is an immutable snapshot of the state.
Internally, ide is split across several crates. ide_assists, ide_completion and ide_ssr implement large isolated features.
ide_db implements common IDE functionality (notably, reference search is implemented here).
The ide contains a public API/façade, as well as implementation for a plethora of smaller features.
Architecture Invariant: ide crate strives to provide a perfect API.
Although at the moment it has only one consumer, the LSP server, LSP does not influence it's API design.
Instead, we keep in mind a hypothetical ideal client -- an IDE tailored specifically for rust, every nook and cranny of which is packed with Rust-specific goodies.
crates/rust-analyzer
This crate defines the rust-analyzer binary, so it is the entry point.
It implements the language server.
Architecture Invariant: rust-analyzer is the only crate that knows about LSP and JSON serialization.
If you want to expose a datastructure X from ide to LSP, don't make it serializable.
Instead, create a serializable counterpart in rust-analyzer crate and manually convert between the two.
GlobalState is the state of the server.
The main_loop defines the server event loop which accepts requests and sends responses.
Requests that modify the state or might block user's typing are handled on the main thread.
All other requests are processed in background.
Architecture Invariant: the server is stateless, a-la HTTP.
Sometimes state needs to be preserved between requests.
For example, "what is the edit for the fifth's completion item of the last completion edit?".
For this, the second request should include enough info to re-create the context from scratch.
This generally means including all the parameters of the original request.
reload module contains the code that handles configuration and Cargo.toml changes.
This is a tricky business.
Architecture Invariant: rust-analyzer should be partially available even when the build is broken.
Reloading process should not prevent IDE features from working.
crates/toolchain, crates/project_model, crates/flycheck
These crates deal with invoking cargo to learn about project structure and get compiler errors for the "check on save" feature.
They use crates/path heavily instead of std::path.
A single rust-analyzer process can serve many projects, so it is important that server's current directory does not leak.
crates/mbe, crated/tt, crates/proc_macro_api, crates/proc_macro_srv
These crates implement macros as token tree -> token tree transforms. They are independent from the rest of the code.
crates/vfs, crates/vfs-notify
These crates implement a virtual fils system. They provide consistent snapshots of the underlying file system and insulate messy OS paths.
Architecture Invariant: vfs doesn't assume a single unified file system.
IE, a single rust-analyzer process can act as a remote server for two different machines, where the same /tmp/foo.rs path points to different files.
For this reason, all path APIs generally take some existing path as a "file system witness".
crates/stdx
This crate contains various non-rust-analyzer specific utils, which could have been in std.
crates/profile
This crate contains utilities for CPU and memory profiling.
Cross-Cutting Concerns
This sections talks about the things which are everywhere and nowhere in particular.
Code generation
Some of the components of this repository are generated through automatic processes.
cargo xtask codegen runs all generation tasks.
Generated code is generally committed to the git repository.
There are tests to check that the generated code is fresh.
In particular, we generate:
-
API for working with syntax trees (
syntax::ast, theungrammarcrate). -
Various sections of the manual:
- features
- assists
- config
-
Documentation tests for assists
Architecture Invariant: we avoid bootstrapping. For codegen we need to parse Rust code. Using rust-analyzer for that would work and would be fun, but it would also complicate the build process a lot. For that reason, we use syn and manual string parsing.
Cancellation
Let's say that the IDE is in the process of computing syntax highlighting, when the user types foo.
What should happen?
rust-analyzers answer is that the highlighting process should be cancelled -- its results are now stale, and it also blocks modification of the inputs.
The salsa database maintains a global revision counter.
When applying a change, salsa bumps this counter and waits until all other threads using salsa finish.
If a thread does salsa-based computation and notices that the counter is incremented, it panics with a special value (see Canceled::throw).
That is, rust-analyzer requires unwinding.
ide is the boundary where the panic is caught and transformed into a Result<T, Cancelled>.
Testing
Rust Analyzer has three interesting systems boundaries to concentrate tests on.
The outermost boundary is the rust-analyzer crate, which defines an LSP interface in terms of stdio.
We do integration testing of this component, by feeding it with a stream of LSP requests and checking responses.
These tests are known as "heavy", because they interact with Cargo and read real files from disk.
For this reason, we try to avoid writing too many tests on this boundary: in a statically typed language, it's hard to make an error in the protocol itself if messages are themselves typed.
Heavy tests are only run when RUN_SLOW_TESTS env var is set.
The middle, and most important, boundary is ide.
Unlike rust-analyzer, which exposes API, ide uses Rust API and is intended to use by various tools.
Typical test creates an AnalysisHost, calls some Analysis functions and compares the results against expectation.
The innermost and most elaborate boundary is hir.
It has a much richer vocabulary of types than ide, but the basic testing setup is the same: we create a database, run some queries, assert result.
For comparisons, we use the expect crate for snapshot testing.
To test various analysis corner cases and avoid forgetting about old tests, we use so-called marks.
See the marks module in the test_utils crate for more.
Architecture Invariant: rust-analyzer tests do not use libcore or libstd. All required library code must be a part of the tests. This ensures fast test execution.
Architecture Invariant: tests are data driven and do not test API. Tests which directly call various API functions are a liability, because they make refactoring the API significantly more complicated. So most of the tests look like this:
fn check(input: &str, expect: expect_test::Expect) {
// The single place that actually exercises a particular API
}
#[test]
fn foo() {
check("foo", expect![["bar"]]);
}
#[test]
fn spam() {
check("spam", expect![["eggs"]]);
}
// ...and a hundred more tests that don't care about the specific API at all.
To specify input data, we use a single string literal in a special format, which can describe a set of rust files.
See the Fixture type.
Architecture Invariant: all code invariants are tested by #[test] tests.
There's no additional checks in CI, formatting and tidy tests are run with cargo test.
Architecture Invariant: tests do not depend on any kind of external resources, they are perfectly reproducible.
Observability
I've run out of steam here :)
rust-analyzer is a long-running process, so its important to understand what's going on inside.
We have hierarchical profiler (RA_PROFILER=1) and object counting (RA_COUNT=1).