Add lint for panic!("{}")
This adds a lint that warns about `panic!("{}")`.
`panic!(msg)` invocations with a single argument use their argument as panic payload literally, without using it as a format string. The same holds for `assert!(expr, msg)`.
This lints checks if `msg` is a string literal (after expansion), and warns in case it contained braces. It suggests to insert `"{}", ` to use the message literally, or to add arguments to use it as a format string.
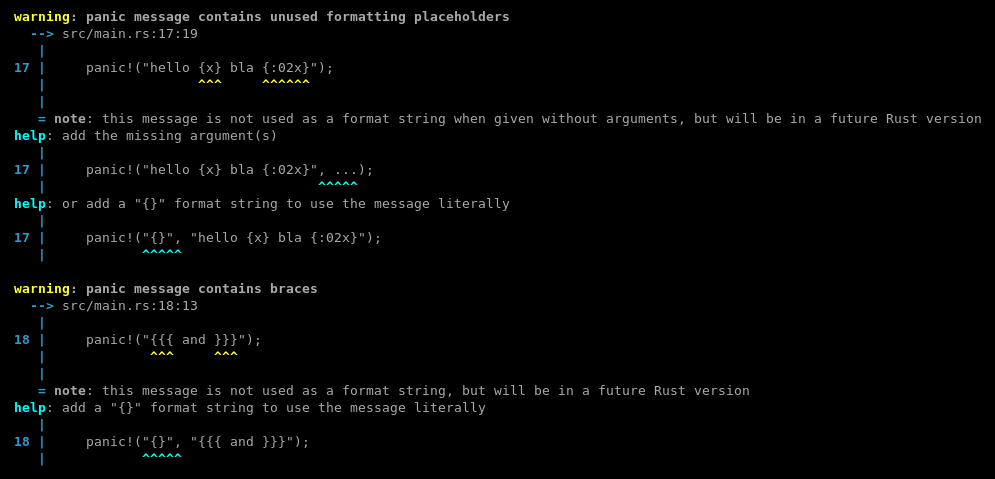
This lint is also a good starting point for adding warnings about `panic!(not_a_string)` later, once [`panic_any()`](https://github.com/rust-lang/rust/pull/74622) becomes a stable alternative.
cleanup: Remove `ParseSess::injected_crate_name`
Its only remaining use is in pretty-printing where the necessary information can be easily re-computed.
The discussion seems to have resolved that this lint is a bit "noisy" in
that applying it in all places would result in a reduction in
readability.
A few of the trivial functions (like `Path::new`) are fine to leave
outside of closures.
The general rule seems to be that anything that is obviously an
allocation (`Box`, `Vec`, `vec![]`) should be in a closure, even if it
is a 0-sized allocation.
rustc_target: Further cleanup use of target options
Follow up to https://github.com/rust-lang/rust/pull/77729.
Implements items 2 and 4 from the list in https://github.com/rust-lang/rust/pull/77729#issue-500228243.
The first commit collapses uses of `target.options.foo` into `target.foo`.
The second commit renames some target options to avoid tautology:
`target.target_endian` -> `target.endian`
`target.target_c_int_width` -> `target.c_int_width`
`target.target_os` -> `target.os`
`target.target_env` -> `target.env`
`target.target_vendor` -> `target.vendor`
`target.target_family` -> `target.os_family`
`target.target_mcount` -> `target.mcount`
r? `@Mark-Simulacrum`
with an eye on merging `TargetOptions` into `Target`.
`TargetOptions` as a separate structure is mostly an implementation detail of `Target` construction, all its fields logically belong to `Target` and available from `Target` through `Deref` impls.
This allows us to avoid synthesizing tokens in `prepend_attr`, since we
have the original tokens available.
We still need to synthesize tokens when expanding `cfg_attr`,
but this is an unavoidable consequence of the syntax of `cfg_attr` -
the user does not supply the `#` and `[]` tokens that a `cfg_attr`
expands to.
Preparation for a subsequent change that replaces
rustc_target::config::Config with its wrapped Target.
On its own, this commit breaks the build. I don't like making
build-breaking commits, but in this instance I believe that it
makes review easier, as the "real" changes of this PR can be
seen much more easily.
Result of running:
find compiler/ -type f -exec sed -i -e 's/target\.target\([)\.,; ]\)/target\1/g' {} \;
find compiler/ -type f -exec sed -i -e 's/target\.target$/target/g' {} \;
find compiler/ -type f -exec sed -i -e 's/target.ptr_width/target.pointer_width/g' {} \;
./x.py fmt
Since 63793 the discriminant_value intrinsic is safe to call. Remove
unnecessary unsafe block around calls to this intrinsic in built-in
derive macros.
We currently only attach tokens when parsing a `:stmt` matcher for a
`macro_rules!` macro. Proc-macro attributes on statements are still
unstable, and need additional work.
Previous implementation used the `Parser::parse_expr` function in order
to extract the format expression. If the first comma following the
format expression was mistakenly replaced with a dot, then the next
format expression was eaten by the function, because it looked as a
syntactically valid expression, which resulted in incorrectly spanned
error messages.
The way the format expression is exctracted is changed: we first look at
the first available token in the first argument supplied to the
`format!` macro call. If it is a string literal, then it is promoted as
a format expression immediatly, otherwise we fall back to the original
`parse_expr`-related method.
This allows us to ensure that the parser won't consume too much tokens
when a typo is made.
A test has been created so that it is ensured that the issue is properly
fixed.
{kind=link}