Validate lint docs separately.
This addresses some concerns raised in https://github.com/rust-lang/rust/pull/76549#issuecomment-727638552 about errors with the lint docs being confusing and cumbersome. Errors from validating the lint documentation were being generated during `x.py doc` (and `x.py dist`), since extraction and validation are being done in a single step. This changes it so that extraction and validation are separated, so that `x.py doc` will not error if there is a validation problem, and tests are moved to `x.py test src/tools/lint-docs`.
This includes the following changes:
* Separate validation to `x.py test`.
* Added some more documentation on how to more easily modify and test the docs.
* Added more help to the error messages to hopefully provide more information on how to fix things.
The first commit just moves the code around, so you may consider looking at the other commits for a smaller diff.
Remove const_fn_feature_flags test
## Overview
Helps with #76268
I found `const_fn_feature_flags` is targeting feature-gate and remove it.
r? ``@matklad``
Stop adding '*' at the end of slice and str typenames for MSVC case
When computing debug info for MSVC debuggers, Rust compiler emits C++ style type names for compatibility with .natvis visualizers. All Ref types are treated as equivalences of C++ pointers in this process, and, as a result, their type names end with a '\*'. Since Slice and Str are treated as Ref by the compiler, their type names also end with a '\*'. This causes the .natvis engine for WinDbg fails to display data of Slice and Str objects. We addressed this problem simply by removing the '*' at the end of type names for Slice and Str types.
Debug info in WinDbg before the fix:

Debug info in WinDbg after the fix:
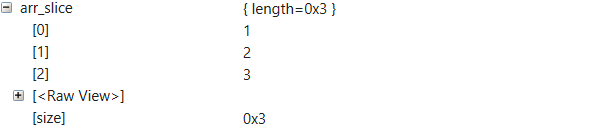
This change has also been tested with debuggers for Visual Studio, VS Code C++ and VS Code LLDB to make sure that it does not affect the behavior of other kinds of debugger.
Make keyboard interactions in the settings menu more pleasant
#78868 improved the keyboard interactions with the settings page. This PR goes a bit further by allowing more than just "space" to toggle the checkboxes.
r? `@jyn514`
Add built-in support for the armv5te-unknown-linux-uclibcgnueabi target
Hi!
I'd like to add built-in support for the `armv5te-unknown-linux-uclibcgnueabi` target. It's a pretty common target used by many devices like routers and IP cameras. It's mostly a copy-paste of `armv5te-unknown-linux-gnueabi`. I've tested it on a quite complex application that uses tokio, openssl and a lot of other stuff and everything seems to be working fine.
I'm not sure about the `post_link_args` but the point is that my linker fails when `-ldl` isn't specified. Maybe there is a better place where to put this option...
It's my first contribution to Rust itself, so feel free to wash my head 😄
_Note: The app mentioned above was built with this in my `.cargo/config`:_
```
[unstable]
build-std = ["core", "std", "alloc", "proc_macro", "panic_abort"]
build-std-features = ["panic_immediate_abort"]
```
More intra doc links
Helps with #75080.
I did a commit by group of file, I can squash if wanted.
`@rustbot` modify labels: T-doc, A-intra-doc-links
r? `@jyn514`
The NetBSD ports of rust to aarch64, armv7*, i686, and powerpc**
all both build and run.
*) Natively requires repeated successive build attempts (rustc is
such a resource pig VM-consumption-wise), or run in a chroot
on an aarch64 host where the available VM space is 4GB instead
of the native 2GB.
**) Powerpc either requires -latomic in a directory searched by
default by 'ld' or to be built within pkgsrc which has a patch
to tackle this.
This checks the error code returned by `dsymutil` and warns if it failed. It
also provides the stdout and stderr logs from `dsymutil`, similar to the native
linker step.
Fixes https://github.com/rust-lang/rust/issues/78770
Fix intra-doc links for `Self` on cross-crate items and primitives
- Remove the difference between `parent_item` and `current_item`; these
should never have been different.
- Remove `current_item` from `resolve` and `variant_field` so that
`Self` is only substituted in one place at the very start.
- Resolve the current item as a `DefId`, not a `HirId`. This is what
actually fixed the bug.
Hacks:
- `clean` uses `TypedefItem` when it _really_ should be
`AssociatedTypeItem`. I tried fixing this without success and hacked
around it instead (see comments)
- This second-guesses the `to_string()` impl since it wants
fully-qualified paths. Possibly there's a better way to do this.
Update error to reflect that integer literals can have float suffixes
For example, `1` is parsed as an integer literal, but it can be turned
into a float with the suffix `f32`. Now the error calls them "numeric
literals" and notes that you can add a float suffix since they can be
either integers or floats.
Avoid panic_bounds_check in fmt::write.
Writing any fmt::Arguments would trigger the inclusion of usize formatting and padding code in the resulting binary, because indexing used in fmt::write would generate code using panic_bounds_check, which prints the index and length.
These bounds checks are not necessary, as fmt::Arguments never contains any out-of-bounds indexes.
This change replaces them with unsafe get_unchecked, to reduce the amount of generated code, which is especially important for embedded targets.
---
Demonstration of the size of and the symbols in a 'hello world' no_std binary:
<details>
<summary>Source code</summary>
```rust
#![feature(lang_items)]
#![feature(start)]
#![no_std]
use core::fmt;
use core::fmt::Write;
#[link(name = "c")]
extern "C" {
#[allow(improper_ctypes)]
fn write(fd: i32, s: &str) -> isize;
fn exit(code: i32) -> !;
}
struct Stdout;
impl fmt::Write for Stdout {
fn write_str(&mut self, s: &str) -> fmt::Result {
unsafe { write(1, s) };
Ok(())
}
}
#[start]
fn main(_argc: isize, _argv: *const *const u8) -> isize {
let _ = writeln!(Stdout, "Hello World");
0
}
#[lang = "eh_personality"]
fn eh_personality() {}
#[panic_handler]
fn panic(_: &core::panic::PanicInfo) -> ! {
unsafe { exit(1) };
}
```
</details>
Before:
```
text data bss dec hex filename
6059 736 8 6803 1a93 before
```
```
0000000000001e00 T <T as core::any::Any>::type_id
0000000000003dd0 D core::fmt::num::DEC_DIGITS_LUT
0000000000001ce0 T core::fmt::num:👿:<impl core::fmt::Display for u64>::fmt
0000000000001ce0 T core::fmt::num:👿:<impl core::fmt::Display for usize>::fmt
0000000000001370 T core::fmt::write
0000000000001b30 t core::fmt::Formatter::pad_integral::write_prefix
0000000000001660 T core::fmt::Formatter::pad_integral
0000000000001350 T core::ops::function::FnOnce::call_once
0000000000001b80 t core::ptr::drop_in_place
0000000000001120 t core::ptr::drop_in_place
0000000000001c50 t core::iter::adapters::zip::Zip<A,B>::new
0000000000001c90 t core::iter::adapters::zip::Zip<A,B>::new
0000000000001b90 T core::panicking::panic_bounds_check
0000000000001c10 T core::panicking::panic_fmt
0000000000001130 t <&mut W as core::fmt::Write>::write_char
0000000000001200 t <&mut W as core::fmt::Write>::write_fmt
0000000000001250 t <&mut W as core::fmt::Write>::write_str
```
After:
```
text data bss dec hex filename
3068 600 8 3676 e5c after
```
```
0000000000001360 T core::fmt::write
0000000000001340 T core::ops::function::FnOnce::call_once
0000000000001120 t core::ptr::drop_in_place
0000000000001620 t core::iter::adapters::zip::Zip<A,B>::new
0000000000001660 t core::iter::adapters::zip::Zip<A,B>::new
0000000000001130 t <&mut W as core::fmt::Write>::write_char
0000000000001200 t <&mut W as core::fmt::Write>::write_fmt
0000000000001250 t <&mut W as core::fmt::Write>::write_str
```
Fix overlap detection of `usize`/`isize` range patterns
`usize` and `isize` are a bit of a special case in the match usefulness algorithm, because the range of values they contain depends on the platform. Specifically, we don't want `0..usize::MAX` to count as an exhaustive match (see also [`precise_pointer_size_matching`](https://github.com/rust-lang/rust/issues/56354)). The way this was initially implemented is by treating those ranges like float ranges, i.e. with limited cleverness. This means we didn't catch the following as unreachable:
```rust
match 0usize {
0..10 => {},
10..20 => {},
5..15 => {}, // oops, should be detected as unreachable
_ => {},
}
```
This PRs fixes this oversight. Now the only difference between `usize` and `u64` range patterns is in what ranges count as exhaustive.
r? `@varkor`
`@rustbot` label +A-exhaustiveness-checking
- Remove the difference between `parent_item` and `current_item`; these
should never have been different.
- Remove `current_item` from `resolve` and `variant_field` so that
`Self` is only substituted in one place at the very start.
- Resolve the current item as a `DefId`, not a `HirId`. This is what
actually fixed the bug.
Hacks:
- `clean` uses `TypedefItem` when it _really_ should be
`AssociatedTypeItem`. I tried fixing this without success and hacked
around it instead (see comments)
- This stringifies DefIds, then resolves them a second time. This is
really silly and rustdoc should just use DefIds throughout. Fixing
this is a larger task than I want to take on right now.
Bump dependencies invalidly assuming memory layout of SocketAddr
Bumps net2, socket2 and miow.
Helps unblock #78802
Done as separate PR since frequent lockfile collisions is a thing... And since the main PR can't be merged until large parts of the ecosystem uses the newer crates only, so we have to start somewhere.
Update tests to remove old numeric constants
Part of #68490.
Care has been taken to leave the old consts where appropriate, for testing backcompat regressions, module shadowing, etc. The intrinsics docs were accidentally referring to some methods on f64 as std::f64, which I changed due to being contrary with how we normally disambiguate the shadow module from the primitive. In one other place I changed std::u8 to std::ops since it was just testing path handling in macros.
For places which have legitimate uses of the old consts, deprecated attributes have been optimistically inserted. Although currently unnecessary, they exist to emphasize to any future deprecation effort the necessity of these specific symbols and prevent them from being accidentally removed.
Don't run `resolve_vars_if_possible` in `normalize_erasing_regions`
Neither `@eddyb` nor I could figure out what this was for. I changed it to `assert_eq!(normalized_value, infcx.resolve_vars_if_possible(&normalized_value));` and it passed the UI test suite.
<details><summary>
Outdated, I figured out the issue - `needs_infer()` needs to come _after_ erasing the lifetimes
</summary>
Strangely, if I change it to `assert!(!normalized_value.needs_infer())` it panics almost immediately:
```
query stack during panic:
#0 [normalize_generic_arg_after_erasing_regions] normalizing `<str::IsWhitespace as str::pattern::Pattern>::Searcher`
#1 [needs_drop_raw] computing whether `str::iter::Split<str::IsWhitespace>` needs drop
#2 [mir_built] building MIR for `str::<impl str>::split_whitespace`
#3 [unsafety_check_result] unsafety-checking `str::<impl str>::split_whitespace`
#4 [mir_const] processing MIR for `str::<impl str>::split_whitespace`
#5 [mir_promoted] processing `str::<impl str>::split_whitespace`
#6 [mir_borrowck] borrow-checking `str::<impl str>::split_whitespace`
#7 [analysis] running analysis passes on this crate
end of query stack
```
I'm not entirely sure what's going on - maybe the two disagree?
</details>
For context, this came up while reviewing https://github.com/rust-lang/rust/pull/77467/ (cc `@lcnr).`
Possibly this needs a crater run?
r? `@nikomatsakis`
cc `@matthewjasper`
{kind=link}
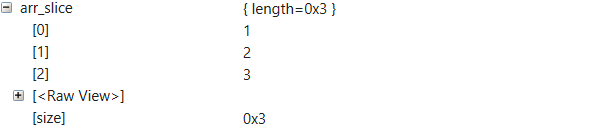{kind=link}