7904: Improved completion sorting r=JoshMcguigan a=JoshMcguigan
I was working on extending #3954 to apply completion scores in more places (I'll have another PR open for that soon) when I discovered that actually completion sorting was not working for me at all in `coc.nvim`. This led me down a bit of a rabbit hole of how coc and vs code each sort completion items.
Before this PR, rust-analyzer was setting the `sortText` field on completion items to `None` if we hadn't applied any completion score for that item, or to the label of the item with a leading whitespace character if we had applied any completion score. Completion score is defined in rust-analyzer as an enum with two variants, `TypeMatch` and `TypeAndNameMatch`.
In vs code the above strategy works, because if `sortText` isn't set [they default it to the label](b4ead4ed66). However, coc [does not do this](e211e36147/src/completion/complete.ts (L245)).
I was going to file a bug report against coc, but I read the [LSP spec for the `sortText` field](https://microsoft.github.io/language-server-protocol/specifications/specification-current/#textDocument_completion) and I feel like it is ambiguous and coc could claim what they do is a valid interpretation of the spec.
Further, the existing rust-analyzer behavior of prepending a leading whitespace character for completion items with any completion score does not handle sorting `TypeAndNameMatch` completions above `TypeMatch` completions. They were both being treated the same.
The first change this PR makes is to set the `sortText` field to either "1" for `TypeAndNameMatch` completions, "2" for `TypeMatch` completions, or "3" for completions which are neither of those. This change works around the potential ambiguity in the LSP spec and fixes completion sorting for users of coc. It also allows `TypeAndNameMatch` items to be sorted above just `TypeMatch` items (of course both of these will be sorted above completion items without a score).
The second change this PR makes is to use the actual completion scores for ref matches. The existing code ignored the actual score and always assumed these would be a high priority completion item.
#### Before
Here coc just sorts based on how close the items are in the file.

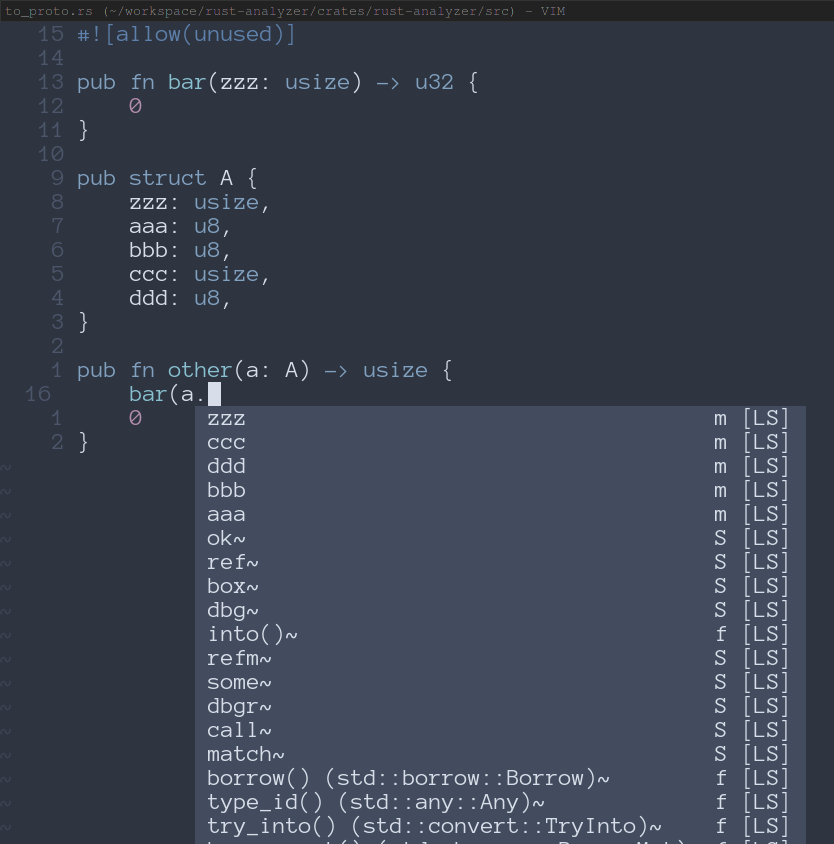
#### After
Here we correctly get `zzz` first, since that is both a type and name match. Then we get `ccc` which is just a type match.
Co-authored-by: Josh Mcguigan <joshmcg88@gmail.com>
7969: Return original text range in PrepareRename responses when inside macro r=Veykril a=Veykril
bors r+
Issue found in #7968
Co-authored-by: Lukas Wirth <lukastw97@gmail.com>
7967: Use expect-test for builtin macro/derive tests r=jonas-schievink a=jonas-schievink
bors r+
Co-authored-by: Jonas Schievink <jonasschievink@gmail.com>
7961: add user docs for ssr assist r=JoshMcguigan a=JoshMcguigan
@matklad
This is a small follow up on #7874, adding user docs for the SSR assist functionality. Since most other assists aren't handled this way I wasn't sure exactly how we wanted to document this, so feel free to suggest alternatives.
Co-authored-by: Josh Mcguigan <joshmcg88@gmail.com>
7959: Prefer names from outer DefMap over extern prelude r=jonas-schievink a=jonas-schievink
Fixes https://github.com/rust-analyzer/rust-analyzer/issues/7919
Just one more special case, how bad could it be.
bors r+
Co-authored-by: Jonas Schievink <jonasschievink@gmail.com>
7874: add apply ssr assist r=JoshMcguigan a=JoshMcguigan
This PR adds an `Apply SSR` assist which was briefly mentioned in #3186. It allows writing an ssr rule as a comment, and then applying that SSR via an assist. This workflow is much nicer than the default available via `coc-rust-analyzer` when iterating to find the proper replacement.
As currently implemented, this requires the ssr rule is written as a single line in the comment, and it doesn't require any kind of prefix. Anything which properly parses as a ssr rule will enable the assist. The benefit of requiring the ssr rule be on a single line is it allows for a workflow where the user has several rules written one after the other, possibly to be triggered in order, without having to try to parse multiple lines of text and determine where one rule ends and the next begins. The benefit of not requiring a prefix is less typing 😆 - plus, I think the chance of something accidentally parsing as an ssr rule is minimal.
I think a reasonable extension of this would be to allow either any ssr rule that fits on a single line, or any comment block which in its entirety makes up a single ssr rule (parsing a comment block containing multiple ssr rules and running them all would break the use case that currently works where a user writes multiple ssr rules then runs them each one by one in arbitrary order).
I've marked this as a draft because for some reason I am strugging to make the unit tests pass. It does work when I compile rust-analyzer and test it in my editor though, so I'm not sure what is going on.
Co-authored-by: Josh Mcguigan <joshmcg88@gmail.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}