The `&[ast::Variant]` field isn't used.
The `Vec<Ident>` field is only used for its length, but that's always
the same as the length of the `&[Ident]` and so isn't necessary.
[RFC 2011] Optimize non-consuming operators
Tracking issue: https://github.com/rust-lang/rust/issues/44838
Fifth step of https://github.com/rust-lang/rust/pull/96496
The most non-invasive approach that will probably have very little to no performance impact.
## Current behaviour
Captures are handled "on-the-fly", i.e., they are performed in the same place expressions are located.
```rust
// `let a = 1; let b = 2; assert!(a > 1 && b < 100);`
if !(
{ ***try capture `a` and then return `a`*** } > 1 && { ***try capture `b` and then return `b`*** } < 100
) {
panic!( ... );
}
```
As such, some overhead is likely to occur (Specially with very large chains of conditions).
## New behaviour for non-consuming operators
When an operator is known to not take `self`, then it is possible to capture variables **AFTER** the condition.
```rust
// `let a = 1; let b = 2; assert!(a > 1 && b < 100);`
if !( a > 1 && b < 100 ) {
{ ***try capture `a`*** }
{ ***try capture `b`*** }
panic!( ... );
}
```
So the possible impact on the runtime execution time will be diminished.
r? ````@oli-obk````
Currently the generated code for methods like `eq`, `ne`, and `partial_cmp`
includes stuff like this:
```
let __self_vi = ::core::intrinsics::discriminant_value(&*self);
let __arg_1_vi = ::core::intrinsics::discriminant_value(&*other);
if true && __self_vi == __arg_1_vi {
...
}
```
This commit removes the unnecessary `true &&`, and makes the generating
code a little easier to read in the process. It also fixes some errors
in comments.
macros: use typed identifiers in diag and subdiag derive
Using typed identifiers instead of strings with the Fluent identifiers in the diagnostic and subdiagnostic derives - this enables the diagnostic derive to benefit from the compile-time validation that comes with typed identifiers, namely that use of a non-existent Fluent identifier will not compile.
r? `````@oli-obk`````
Using typed identifiers instead of strings with the Fluent identifier
enables the diagnostic derive to benefit from the compile-time
validation that comes with typed identifiers - use of a non-existent
Fluent identifier will not compile.
Signed-off-by: David Wood <david.wood@huawei.com>
Fixup missing renames from `#[main]` to `#[rustc_main]`
In #84217 `#[main]` was removed and replaced with `#[rustc_main]`. In some places the rename was forgotten, which makes the current code confusing, because at first glance it seems that `#[main]` is still around. Perform the renames also in these places.
I noticed this (after first being confused by it) when working on #97802.
r? `@petrochenkov`
(since you reviewed the other PR)
This commit adds new methods that combine sequences of existing
formatting methods.
- `Formatter::debug_{tuple,struct}_field[12345]_finish`, equivalent to a
`Formatter::debug_{tuple,struct}` + N x `Debug{Tuple,Struct}::field` +
`Debug{Tuple,Struct}::finish` call sequence.
- `Formatter::debug_{tuple,struct}_fields_finish` is similar, but can
handle any number of fields by using arrays.
These new methods are all marked as `doc(hidden)` and unstable. They are
intended for the compiler's own use.
Special-casing up to 5 fields gives significantly better performance
results than always using arrays (as was tried in #95637).
The commit also changes the `Debug` deriving code to use these new methods. For
example, where the old `Debug` code for a struct with two fields would be like
this:
```
fn fmt(&self, f: &mut ::core::fmt::Formatter) -> ::core::fmt::Result {
match *self {
Self {
f1: ref __self_0_0,
f2: ref __self_0_1,
} => {
let debug_trait_builder = &mut ::core::fmt::Formatter::debug_struct(f, "S2");
let _ = ::core::fmt::DebugStruct::field(debug_trait_builder, "f1", &&(*__self_0_0));
let _ = ::core::fmt::DebugStruct::field(debug_trait_builder, "f2", &&(*__self_0_1));
::core::fmt::DebugStruct::finish(debug_trait_builder)
}
}
}
```
the new code is like this:
```
fn fmt(&self, f: &mut ::core::fmt::Formatter) -> ::core::fmt::Result {
match *self {
Self {
f1: ref __self_0_0,
f2: ref __self_0_1,
} => ::core::fmt::Formatter::debug_struct_field2_finish(
f,
"S2",
"f1",
&&(*__self_0_0),
"f2",
&&(*__self_0_1),
),
}
}
```
This shrinks the code produced for `Debug` instances
considerably, reducing compile times and binary sizes.
Co-authored-by: Scott McMurray <scottmcm@users.noreply.github.com>
In fc357039f9 `#[main]` was removed and replaced with `#[rustc_main]`.
In some place the rename was forgotten, which makes the current code
confusing, because at first glance it seems that `#[main]` is still
around. Perform the renames also in these places.
proc_macro: don't pass a client-side function pointer through the server.
Before this PR, `proc_macro::bridge::Client<F>` contained both:
* the C ABI entry-point `run`, that the server can call to start the client
* some "payload" `f: F` passed to that entry-point
* in practice, this was always a (client-side Rust ABI) `fn` pointer to the actual function the proc macro author wrote, i.e. `#[proc_macro] fn foo(input: TokenStream) -> TokenStream`
In other words, the client was passing one of its (Rust) `fn` pointers to the server, which was passing it back to the client, for the client to call (see later below for why that was ever needed).
I was inspired by `@nnethercote's` attempt to remove the `get_handle_counters` field from `Client` (see https://github.com/rust-lang/rust/pull/97004#issuecomment-1139273301), which combined with removing the `f` ("payload") field, could theoretically allow for a `#[repr(transparent)]` `Client` that mostly just newtypes the C ABI entry-point `fn` pointer <sub>(and in the context of e.g. wasm isolation, that's *all* you want, since you can reason about it from outside the wasm VM, as just a 32-bit "function table index", that you can pass to the wasm VM to call that function)</sub>.
<hr/>
So this PR removes that "payload". But it's not a simple refactor: the reason the field existed in the first place is because monomorphizing over a function type doesn't let you call the function without having a value of that type, because function types don't implement anything like `Default`, i.e.:
```rust
extern "C" fn ffi_wrapper<A, R, F: Fn(A) -> R>(arg: A) -> R {
let f: F = ???; // no way to get a value of `F`
f(arg)
}
```
That could be solved with something like this, if it was allowed:
```rust
extern "C" fn ffi_wrapper<
A, R,
F: Fn(A) -> R,
const f: F // not allowed because the type is a generic param
>(arg: A) -> R {
f(arg)
}
```
Instead, this PR contains a workaround in `proc_macro::bridge::selfless_reify` (see its module-level comment for more details) that can provide something similar to the `ffi_wrapper` example above, but limited to `F` being `Copy` and ZST (and requiring an `F` value to prove the caller actually can create values of `F` and it's not uninhabited or some other unsound situation).
<hr/>
Hopefully this time we don't have a performance regression, and this has a chance to land.
cc `@mystor` `@bjorn3`
Begin fixing all the broken doctests in `compiler/`
Begins to fix#95994.
All of them pass now but 24 of them I've marked with `ignore HELP (<explanation>)` (asking for help) as I'm unsure how to get them to work / if we should leave them as they are.
There are also a few that I marked `ignore` that could maybe be made to work but seem less important.
Each `ignore` has a rough "reason" for ignoring after it parentheses, with
- `(pseudo-rust)` meaning "mostly rust-like but contains foreign syntax"
- `(illustrative)` a somewhat catchall for either a fragment of rust that doesn't stand on its own (like a lone type), or abbreviated rust with ellipses and undeclared types that would get too cluttered if made compile-worthy.
- `(not-rust)` stuff that isn't rust but benefits from the syntax highlighting, like MIR.
- `(internal)` uses `rustc_*` code which would be difficult to make work with the testing setup.
Those reason notes are a bit inconsistently applied and messy though. If that's important I can go through them again and try a more principled approach. When I run `rg '```ignore \(' .` on the repo, there look to be lots of different conventions other people have used for this sort of thing. I could try unifying them all if that would be helpful.
I'm not sure if there was a better existing way to do this but I wrote my own script to help me run all the doctests and wade through the output. If that would be useful to anyone else, I put it here: https://github.com/Elliot-Roberts/rust_doctest_fixing_tool
Add a new Rust attribute to support embedding debugger visualizers
Implemented [this RFC](https://github.com/rust-lang/rfcs/pull/3191) to add support for embedding debugger visualizers into a PDB.
Added a new attribute `#[debugger_visualizer]` and updated the `CrateMetadata` to store debugger visualizers for crate dependencies.
RFC: https://github.com/rust-lang/rfcs/pull/3191
Cleanup `DebuggerVisualizerFile` type and other minor cleanup of queries.
Merge the queries for debugger visualizers into a single query.
Revert move of `resolve_path` to `rustc_builtin_macros`. Update dependencies in Cargo.toml for `rustc_passes`.
Respond to PR comments. Load visualizer files into opaque bytes `Vec<u8>`. Debugger visualizers for dynamically linked crates should not be embedded in the current crate.
Update the unstable book with the new feature. Add the tracking issue for the debugger_visualizer feature.
Respond to PR comments and minor cleanups.
Change `span_suggestion` (and variants) to take `impl ToString` rather
than `String` for the suggested code, as this simplifies the
requirements on the diagnostic derive.
Signed-off-by: David Wood <david.wood@huawei.com>
Implement sym operands for global_asm!
Tracking issue: #93333
This PR is pretty much a complete rewrite of `sym` operand support for inline assembly so that the same implementation can be shared by `asm!` and `global_asm!`. The main changes are:
- At the AST level, `sym` is represented as a special `InlineAsmSym` AST node containing a path instead of an `Expr`.
- At the HIR level, `sym` is split into `SymStatic` and `SymFn` depending on whether the path resolves to a static during AST lowering (defaults to `SynFn` if `get_early_res` fails).
- `SymFn` is just an `AnonConst`. It runs through typeck and we just collect the resulting type at the end. An error is emitted if the type is not a `FnDef`.
- `SymStatic` directly holds a path and the `DefId` of the `static` that it is pointing to.
- The representation at the MIR level is mostly unchanged. There is a minor change to THIR where `SymFn` is a constant instead of an expression.
- At the codegen level we need to apply the target's symbol mangling to the result of `tcx.symbol_name()` depending on the target. This is done by calling the LLVM name mangler, which handles all of the details.
- On Mach-O, all symbols have a leading underscore.
- On x86 Windows, different mangling is used for cdecl, stdcall, fastcall and vectorcall.
- No mangling is needed on other platforms.
r? `@nagisa`
cc `@eddyb`
Create (unstable) 2024 edition
[On Zulip](https://rust-lang.zulipchat.com/#narrow/stream/213817-t-lang/topic/Deprecating.20macro.20scoping.20shenanigans/near/272860652), there was a small aside regarding creating the 2024 edition now as opposed to later. There was a reasonable amount of support and no stated opposition.
This change creates the 2024 edition in the compiler and creates a prelude for the 2024 edition. There is no current difference between the 2021 and 2024 editions. Cargo and other tools will need to be updated separately, as it's not in the same repository. This change permits the vast majority of work towards the next edition to proceed _now_ instead of waiting until 2024.
For sanity purposes, I've merged the "hello" UI tests into a single file with multiple revisions. Otherwise we'd end up with a file per edition, despite them being essentially identical.
````@rustbot```` label +T-lang +S-waiting-on-review
Not sure on the relevant team, to be honest.
Stabilize `derive_default_enum`
This stabilizes `#![feature(derive_default_enum)]`, as proposed in [RFC 3107](https://github.com/rust-lang/rfcs/pull/3107) and tracked in #87517. In short, it permits you to `#[derive(Default)]` on `enum`s, indicating what the default should be by placing a `#[default]` attribute on the desired variant (which must be a unit variant in the interest of forward compatibility).
```````@rustbot``````` label +S-waiting-on-review +T-lang
refactor: simplify few string related interactions
Few small optimizations:
check_doc_keyword: don't alloc string for emptiness check
check_doc_alias_value: get argument as Symbol to prevent needless string convertions
check_doc_attrs: don't alloc vec, iterate over slice.
replace as_str() check with symbol check
get_single_str_from_tts: don't prealloc string
trivial string to str replace
LifetimeScopeForPath::NonElided use Vec<Symbol> instead of Vec<String>
AssertModuleSource use FxHashSet<Symbol> instead of BTreeSet<String>
CrateInfo.crate_name replace FxHashMap<CrateNum, String> with FxHashMap<CrateNum, Symbol>
check_doc_alias_value: get argument as Symbol to prevent needless string convertions
check_doc_attrs: don't alloc vec, iterate over slice. Vec introduced in #83149, but no perf run posted on merge
replace as_str() check with symbol check
get_single_str_from_tts: don't prealloc string
trivial string to str replace
LifetimeScopeForPath::NonElided use Vec<Symbol> instead of Vec<String>
AssertModuleSource use BTreeSet<Symbol> instead of BTreeSet<String>
CrateInfo.crate_name replace FxHashMap<CrateNum, String> with FxHashMap<CrateNum, Symbol>
`MultiSpan` contains labels, which are more complicated with the
introduction of diagnostic translation and will use types from
`rustc_errors` - however, `rustc_errors` depends on `rustc_span` so
`rustc_span` cannot use types like `DiagnosticMessage` without
dependency cycles. Introduce a new `rustc_error_messages` crate that can
contain `DiagnosticMessage` and `MultiSpan`.
Signed-off-by: David Wood <david.wood@huawei.com>
More robust fallback for `use` suggestion
Our old way to suggest where to add `use`s would first look for pre-existing `use`s in the relevant crate/module, and if there are *no* uses, it would fallback on trying to use another item as the basis for the suggestion.
But this was fragile, as illustrated in issue #87613
This PR instead identifies span of the first token after any inner attributes, and uses *that* as the fallback for the `use` suggestion.
Fix#87613
then we just suggest the first legal position where you could inject a use.
To do this, I added `inject_use_span` field to `ModSpans`, and populate it in
parser (it is the span of the first token found after inner attributes, if any).
Then I rewrote the use-suggestion code to utilize it, and threw out some stuff
that is now unnecessary with this in place. (I think the result is easier to
understand.)
Then I added a test of issue 87613.
Improve allowness of the unexpected_cfgs lint
This pull-request improve the allowness (`#[allow(...)]`) of the `unexpected_cfgs` lint.
Before this PR only crate level `#![allow(unexpected_cfgs)]` worked, now with this PR it also work when put around `cfg!` or if it is in a upper level. Making it work ~for the attributes `cfg`, `cfg_attr`, ...~ for the same level is awkward as the current code is design to give "Some parent node that is close to this macro call" (cf. https://doc.rust-lang.org/nightly/nightly-rustc/rustc_expand/base/struct.ExpansionData.html) meaning that allow on the same line as an attribute won't work. I'm note even sure if this would be possible.
Found while working on https://github.com/rust-lang/rust/pull/94298.
r? ````````@petrochenkov````````
As an example:
#[test]
#[ignore = "not yet implemented"]
fn test_ignored() {
...
}
Will now render as:
running 2 tests
test tests::test_ignored ... ignored, not yet implemented
test result: ok. 1 passed; 0 failed; 1 ignored; 0 measured; 0 filtered out; finished in 0.00s
Adopt let else in more places
Continuation of #89933, #91018, #91481, #93046, #93590, #94011.
I have extended my clippy lint to also recognize tuple passing and match statements. The diff caused by fixing it is way above 1 thousand lines. Thus, I split it up into multiple pull requests to make reviewing easier. This is the biggest of these PRs and handles the changes outside of rustdoc, rustc_typeck, rustc_const_eval, rustc_trait_selection, which were handled in PRs #94139, #94142, #94143, #94144.
Add more info and suggestions to use of #[test] on invalid items
This pr changes the diagnostics for using `#[test]` on an item that can't be used as a test to explain that the attribute has no meaningful effect on non-functions and suggests the use of `#[cfg(test)]` for conditional compilation instead.
Example change:
```rs
#[test]
mod test {}
```
previously output
```
error: only functions may be used as tests
--> src/lib.rs:2:1
|
2 | mod test {}
| ^^^^^^^^^^^
```
now outputs
```
error: the `#[test]` attribute may only be used on a non-associated function
--> $DIR/test-on-not-fn.rs:3:1
|
LL | #[test]
| ^^^^^^^
LL | mod test {}
| ----------- expected a non-associated function, found a module
|
= note: the `#[test]` macro causes a a function to be run on a test and has no effect on non-functions
help: replace with conditional compilation to make the item only exist when tests are being run
|
LL | #[cfg(test)]
| ~~~~~~~~~~~~
```
Deny mixing bin crate type with lib crate types
The produced library would get a main shim too which conflicts with the
main shim of the executable linking the library.
```
$ cat > main1.rs <<EOF
fn main() {}
pub fn bar() {}
EOF
$ cat > main2.rs <<EOF
extern crate main1;
fn main() {
main1::bar();
}
EOF
$ rustc --crate-type bin --crate-type lib main1.rs
$ rustc -L. main2.rs
error: linking with `cc` failed: exit status: 1
[...]
= note: /usr/bin/ld: /tmp/crate_bin_lib/libmain1.rlib(main1.main1.707747aa-cgu.0.rcgu.o): in function `main':
main1.707747aa-cgu.0:(.text.main+0x0): multiple definition of `main'; main2.main2.02a148fe-cgu.0.rcgu.o:main2.02a148fe-cgu.0:(.text.main+0x0): first defined here
collect2: error: ld returned 1 exit status
```
Correctly mark the span of captured arguments in `format_args!()`
It should not include the braces, or misspelling suggestions will be wrong.
Fixes#94010.
Resolve concern of `derive_default_enum`
This resolves the concern in favor of prohibiting multiple instances of
the attribute. This is similar to non-helper attributes as introduced in
#88681.
``@rustbot`` label +S-waiting-on-review +T-libs-api
This option introduced in #15820 allows a custom crate to be imported in
the place of std, but with the name std. I don't think there is any
value to this. At most it is confusing users of a driver that uses this option. There are no users of
this option on github. If anyone still needs it, they can emulate it
injecting #![no_core] in addition to their own prelude.
update comment wrt const param defaults
after #93669 i looked through all other uses of `GenericParamKind::Const` again to detect if we missed the `default` there as well, but afaict we really only missed lifetime resolution '^^ at least i found an outdated comment :3
Fix invalid special casing of the unreachable! macro
This pull-request fix an invalid special casing of the `unreachable!` macro in the same way the `panic!` macro was solved, by adding two new internal only macros `unreachable_2015` and `unreachable_2021` edition dependent and turn `unreachable!` into a built-in macro that do dispatching. This logic is stolen from the `panic!` macro.
~~This pull-request also adds an internal feature `format_args_capture_non_literal` that allows capturing arguments from formatted string that expanded from macros. The original RFC #2795 mentioned this as a future possibility. This feature is [required](https://github.com/rust-lang/rust/issues/92137#issuecomment-1018630522) because of concatenation that needs to be done inside the macro:~~
```rust
$crate::concat!("internal error: entered unreachable code: ", $fmt)
```
**In summary** the new behavior for the `unreachable!` macro with this pr is:
Edition 2021:
```rust
let x = 5;
unreachable!("x is {x}");
```
```
internal error: entered unreachable code: x is 5
```
Edition <= 2018:
```rust
let x = 5;
unreachable!("x is {x}");
```
```
internal error: entered unreachable code: x is {x}
```
Also note that the change in this PR are **insta-stable** and **breaking changes** but this a considered as being a [bug](https://github.com/rust-lang/rust/issues/92137#issuecomment-998441613).
If someone could start a perf run and then a crater run this would be appreciated.
Fixes https://github.com/rust-lang/rust/issues/92137
Create `core::fmt::ArgumentV1` with generics instead of fn pointer
Split from (and prerequisite of) #90488, as this seems to have perf implication.
`@rustbot` label: +T-libs
Remove deprecated LLVM-style inline assembly
The `llvm_asm!` was deprecated back in #87590 1.56.0, with intention to remove
it once `asm!` was stabilized, which already happened in #91728 1.59.0. Now it
is time to remove `llvm_asm!` to avoid continued maintenance cost.
Closes#70173.
Closes#92794.
Closes#87612.
Closes#82065.
cc `@rust-lang/wg-inline-asm`
r? `@Amanieu`
The produced library would get a main shim too which conflicts with the
main shim of the executable linking the library.
```
$ cat > main1.rs <<EOF
fn main() {}
pub fn bar() {}
EOF
$ cat > main2.rs <<EOF
extern crate main1;
fn main() {
main1::bar();
}
EOF
$ rustc --crate-type bin --crate-type lib main1.rs
$ rustc -L. main2.rs
error: linking with `cc` failed: exit status: 1
[...]
= note: /usr/bin/ld: /tmp/crate_bin_lib/libmain1.rlib(main1.main1.707747aa-cgu.0.rcgu.o): in function `main':
main1.707747aa-cgu.0:(.text.main+0x0): multiple definition of `main'; main2.main2.02a148fe-cgu.0.rcgu.o:main2.02a148fe-cgu.0:(.text.main+0x0): first defined here
collect2: error: ld returned 1 exit status
```
Support [x; n] expressions in concat_bytes!
Currently trying to use `concat_bytes!` with a repeating array value like `[42; 5]` results in an error:
```
error: expected a byte literal
--> src/main.rs:3:27
|
3 | let x = concat_bytes!([3; 4]);
| ^^^^^^
|
= note: only byte literals (like `b"foo"`, `b's'`, and `[3, 4, 5]`) can be passed to `concat_bytes!()`
```
This makes it so repeating array syntax can be used the same way normal arrays can be. The RFC doesn't explicitly mention repeat expressions, but it seems reasonable to allow them as well, since normal arrays are allowed.
It is possible to make the compiler get stuck compiling forever with `concat_bytes!([3; 999999999])`, but I don't think that's much of an issue since you can do that already with `const X: [u8; 999999999] = [3; 999999999];`.
Contributes to #87555.
This resolves the concern in favor of prohibiting multiple instances of
the attribute. This is similar to non-helper attributes as introduced in
#88681.
Remove `SymbolStr`
This was originally proposed in https://github.com/rust-lang/rust/pull/74554#discussion_r466203544. As well as removing the icky `SymbolStr` type, it allows the removal of a lot of `&` and `*` occurrences.
Best reviewed one commit at a time.
r? `@oli-obk`
Stabilize `iter::zip`
Hello all!
As the tracking issue (#83574) for `iter::zip` completed the final commenting period without any concerns being raised, I hereby submit this stabilization PR on the issue.
As the pull request that introduced the feature (#82917) states, the `iter::zip` function is a shorter way to zip two iterators. As it's generally a quality-of-life/ergonomic improvement, it has been integrated into the codebase without any trouble, and has been
used in many places across the rust compiler and standard library since March without any issues.
For more details, I would refer to `@cuviper's` original PR, or the [function's documentation](https://doc.rust-lang.org/std/iter/fn.zip.html).
Fix ICE on format string of macro with secondary-label
This generalizes the fix#86104 to also correctly skip `Span::from_inner` for the `secondary_label` of a format macro parsing error as well.
We can alternatively skip the `span_label` diagnostic call for the secondary label as well, since that label probably only makes sense when the _proper_ span is computed.
Fixes#91556
Keep spans for generics in `#[derive(_)]` desugaring
Keep the spans for generics coming from a `derive`d Item, so that errors
and suggestions have better detail.
Fix#84003.
* Annotate `derive`d spans from the user's code with the appropciate context
* Add `Span::can_be_used_for_suggestion` to query if the underlying span
at the users' code
expand: Turn `ast::Crate` into a first class expansion target
And stop creating a fake `mod` item for the crate root when expanding a crate, thus addressing FIXMEs left in https://github.com/rust-lang/rust/pull/82238, and making a step towards a proper support for crate-level macro attributes (cc #54726).
I haven't added token collection support for the whole crate in this PR, maybe later.
r? `@Aaron1011`
Don't destructure args tuple in format_args!
This allows Clippy to parse the HIR more simply since `arg0` is changed to `_args.0`. (cc rust-lang/rust-clippy#7843). From rustc's perspective, I think this is something between a lateral move and a tiny improvement since there are fewer bindings.
r? `@m-ou-se`
TraitKind -> Trait
TyAliasKind -> TyAlias
ImplKind -> Impl
FnKind -> Fn
All `*Kind`s in AST are supposed to be enums.
Tuple structs are converted to braced structs for the types above, and fields are reordered in syntactic order.
Also, mutable AST visitor now correctly visit spans in defaultness, unsafety, impl polarity and constness.
Deriving: Include bound generic params in type parameters for where clause
Fixes#89188.
The `derive` macro ignored the `for<'s>` needed with the `Fn` trait in that code example.
edit: I'm unsure if this might cause regressions. I'm not an experienced compiler developer so I'm not used to thinking about unwanted side effects code changes like this might have.
This allows the format_args! macro to keep the pre-expansion code out of
the unsafe block without doing gymnastics with nested `match`
expressions. This reduces codegen.
Introduce a fast path that avoids the `debug_tuple` abstraction when deriving Debug for unit-like enum variants.
The intent here is to allow LLVM to remove the switch entirely in favor of an
indexed load from a table of constant strings, which is likely what the
programmer would write in C. Unfortunately, LLVM currently doesn't perform this
optimization due to a bug, but there is [a
patch](https://reviews.llvm.org/D109565) that fixes this issue. I've verified
that, with that patch applied on top of this commit, Debug for unit-like tuple
variants becomes a load, reducing the O(n) code bloat to O(1).
Note that inlining `DebugTuple::finish()` wasn't enough to allow LLVM to
optimize the code properly; I had to avoid the abstraction entirely. Not using
the abstraction is likely better for compile time anyway.
Part of #88793.
r? `@oli-obk`
Debug for unit-like enum variants.
The intent here is to allow LLVM to remove the switch entirely in favor of an
indexed load from a table of constant strings, which is likely what the
programmer would write in C. Unfortunately, LLVM currently doesn't perform this
optimization due to a bug, but there is [a
patch](https://reviews.llvm.org/D109565) that fixes this issue. I've verified
that, with that patch applied on top of this commit, Debug for unit-like tuple
variants becomes a load, reducing the O(n) code bloat to O(1).
Note that inlining `DebugTuple::finish()` wasn't enough to allow LLVM to
optimize the code properly; I had to avoid the abstraction entirely. Not using
the abstraction is likely better for compile time anyway.
Part of #88793.
Detect bare blocks with type ascription that were meant to be a `struct` literal
Address part of #34255.
Potential improvement: silence the other knock down errors in `issue-34255-1.rs`.
Remove `Session.used_attrs` and move logic to `CheckAttrVisitor`
Instead of updating global state to mark attributes as used,
we now explicitly emit a warning when an attribute is used in
an unsupported position. As a side effect, we are to emit more
detailed warning messages (instead of just a generic "unused" message).
`Session.check_name` is removed, since its only purpose was to mark
the attribute as used. All of the callers are modified to use
`Attribute.has_name`
Additionally, `AttributeType::AssumedUsed` is removed - an 'assumed
used' attribute is implemented by simply not performing any checks
in `CheckAttrVisitor` for a particular attribute.
We no longer emit unused attribute warnings for the `#[rustc_dummy]`
attribute - it's an internal attribute used for tests, so it doesn't
mark sense to treat it as 'unused'.
With this commit, a large source of global untracked state is removed.
Get piece unchecked in `write`
We already use specialized `zip`, but it seems like we can do a little better by not checking `pieces` length at all.
`Arguments` constructors are now unsafe. So the `format_args!` expansion now includes an `unsafe` block.
<details>
<summary>Local Bench Diff</summary>
```text
name before ns/iter after ns/iter diff ns/iter diff % speedup
fmt::write_str_macro1 22,967 19,718 -3,249 -14.15% x 1.16
fmt::write_str_macro2 35,527 32,654 -2,873 -8.09% x 1.09
fmt::write_str_macro_debug 571,953 575,973 4,020 0.70% x 0.99
fmt::write_str_ref 9,579 9,459 -120 -1.25% x 1.01
fmt::write_str_value 9,573 9,572 -1 -0.01% x 1.00
fmt::write_u128_max 176 173 -3 -1.70% x 1.02
fmt::write_u128_min 138 134 -4 -2.90% x 1.03
fmt::write_u64_max 139 136 -3 -2.16% x 1.02
fmt::write_u64_min 129 135 6 4.65% x 0.96
fmt::write_vec_macro1 24,401 22,273 -2,128 -8.72% x 1.10
fmt::write_vec_macro2 37,096 35,602 -1,494 -4.03% x 1.04
fmt::write_vec_macro_debug 588,291 589,575 1,284 0.22% x 1.00
fmt::write_vec_ref 9,568 9,732 164 1.71% x 0.98
fmt::write_vec_value 9,516 9,625 109 1.15% x 0.99
```
</details>
Instead of updating global state to mark attributes as used,
we now explicitly emit a warning when an attribute is used in
an unsupported position. As a side effect, we are to emit more
detailed warning messages (instead of just a generic "unused" message).
`Session.check_name` is removed, since its only purpose was to mark
the attribute as used. All of the callers are modified to use
`Attribute.has_name`
Additionally, `AttributeType::AssumedUsed` is removed - an 'assumed
used' attribute is implemented by simply not performing any checks
in `CheckAttrVisitor` for a particular attribute.
We no longer emit unused attribute warnings for the `#[rustc_dummy]`
attribute - it's an internal attribute used for tests, so it doesn't
mark sense to treat it as 'unused'.
With this commit, a large source of global untracked state is removed.
Add support for clobber_abi to asm!
This PR adds the `clobber_abi` feature that was proposed in #81092.
Fixes#81092
cc `@rust-lang/wg-inline-asm`
r? `@nagisa`
Since RFC 3052 soft deprecated the authors field anyway, hiding it from
crates.io, docs.rs, and making Cargo not add it by default, and it is
not generally up to date/useful information, we should remove it from
crates in this repo.
avoid temporary vectors/reuse iterators
Avoid collecting an interator just to re-iterate immediately.
Rather reuse the previous iterator. (clippy::needless_collect)
Various diagnostics clean ups/tweaks
* Always point at macros, including derive macros
* Point at non-local items that introduce a trait requirement
* On private associated item, point at definition
* Always point at macros, including derive macros
* Point at non-local items that introduce a trait requirement
* On private associated item, point at definition
When we need to emit a lint at a macro invocation, we currently use the
`NodeId` of its parent definition (e.g. the enclosing function). This
means that any `#[allow]` / `#[deny]` attributes placed 'closer' to the
macro (e.g. on an enclosing block or statement) will have no effect.
This commit computes a better `lint_node_id` in `InvocationCollector`.
When we visit/flat_map an AST node, we assign it a `NodeId` (earlier
than we normally would), and store than `NodeId` in current
`ExpansionData`. When we collect a macro invocation, the current
`lint_node_id` gets cloned along with our `ExpansionData`, allowing it
to be used if we need to emit a lint later on.
This improves the handling of `#[allow]` / `#[deny]` for
`SEMICOLON_IN_EXPRESSIONS_FROM_MACROS` and some `asm!`-related lints.
The 'legacy derive helpers' lint retains its current behavior
(I've inlined the now-removed `lint_node_id` function), since
there isn't an `ExpansionData` readily available.
Make `s` pre-interned
Now we should be able to pre-intern `s` as the test `ui/lint/rfc-2457-non-ascii-idents/lint-confusable-idents.rs` no longer fails.
Show test type during prints
Test output can sometimes be confusing. For example doctest with the no_run argument are displayed the same way than test that are run.
During #83857 I got the feedback that test output can be confusing.
For the moment test output is
```
test $DIR/test-type.rs - f (line 12) ... ignored
test $DIR/test-type.rs - f (line 15) ... ok
test $DIR/test-type.rs - f (line 21) ... ok
test $DIR/test-type.rs - f (line 6) ... ok
```
I propose to change output by indicating the test type as
```
test $DIR/test-type.rs - f (line 12) ... ignored
test $DIR/test-type.rs - f (line 15) - compile ... ok
test $DIR/test-type.rs - f (line 21) - compile fail ... ok
test $DIR/test-type.rs - f (line 6) ... ok
```
by indicating the test type after the test name (and in the case of doctest after the function name and line) and before the "...".
------------
Note: this is a proof of concept, the implementation is probably not optimal as the properties added in `TestDesc` are only use in the display and does not represent actual change of behavior, maybe `TestType::DocTest` could have fields
Fix `--remap-path-prefix` not correctly remapping `rust-src` component paths and unify handling of path mapping with virtualized paths
This PR fixes#73167 ("Binaries end up containing path to the rust-src component despite `--remap-path-prefix`") by preventing real local filesystem paths from reaching compilation output if the path is supposed to be remapped.
`RealFileName::Named` introduced in #72767 is now renamed as `LocalPath`, because this variant wraps a (most likely) valid local filesystem path.
`RealFileName::Devirtualized` is renamed as `Remapped` to be used for remapped path from a real path via `--remap-path-prefix` argument, as well as real path inferred from a virtualized (during compiler bootstrapping) `/rustc/...` path. The `local_path` field is now an `Option<PathBuf>`, as it will be set to `None` before serialisation, so it never reaches any build output. Attempting to serialise a non-`None` `local_path` will cause an assertion faliure.
When a path is remapped, a `RealFileName::Remapped` variant is created. The original path is preserved in `local_path` field and the remapped path is saved in `virtual_name` field. Previously, the `local_path` is directly modified which goes against its purpose of "suitable for reading from the file system on the local host".
`rustc_span::SourceFile`'s fields `unmapped_path` (introduced by #44940) and `name_was_remapped` (introduced by #41508 when `--remap-path-prefix` feature originally added) are removed, as these two pieces of information can be inferred from the `name` field: if it's anything other than a `FileName::Real(_)`, or if it is a `FileName::Real(RealFileName::LocalPath(_))`, then clearly `name_was_remapped` would've been false and `unmapped_path` would've been `None`. If it is a `FileName::Real(RealFileName::Remapped{local_path, virtual_name})`, then `name_was_remapped` would've been true and `unmapped_path` would've been `Some(local_path)`.
cc `@eddyb` who implemented `/rustc/...` path devirtualisation
This PR implements span quoting, allowing proc-macros to produce spans
pointing *into their own crate*. This is used by the unstable
`proc_macro::quote!` macro, allowing us to get error messages like this:
```
error[E0412]: cannot find type `MissingType` in this scope
--> $DIR/auxiliary/span-from-proc-macro.rs:37:20
|
LL | pub fn error_from_attribute(_args: TokenStream, _input: TokenStream) -> TokenStream {
| ----------------------------------------------------------------------------------- in this expansion of procedural macro `#[error_from_attribute]`
...
LL | field: MissingType
| ^^^^^^^^^^^ not found in this scope
|
::: $DIR/span-from-proc-macro.rs:8:1
|
LL | #[error_from_attribute]
| ----------------------- in this macro invocation
```
Here, `MissingType` occurs inside the implementation of the proc-macro
`#[error_from_attribute]`. Previosuly, this would always result in a
span pointing at `#[error_from_attribute]`
This will make many proc-macro-related error message much more useful -
when a proc-macro generates code containing an error, users will get an
error message pointing directly at that code (within the macro
definition), instead of always getting a span pointing at the macro
invocation site.
This is implemented as follows:
* When a proc-macro crate is being *compiled*, it causes the `quote!`
macro to get run. This saves all of the sapns in the input to `quote!`
into the metadata of *the proc-macro-crate* (which we are currently
compiling). The `quote!` macro then expands to a call to
`proc_macro::Span::recover_proc_macro_span(id)`, where `id` is an
opaque identifier for the span in the crate metadata.
* When the same proc-macro crate is *run* (e.g. it is loaded from disk
and invoked by some consumer crate), the call to
`proc_macro::Span::recover_proc_macro_span` causes us to load the span
from the proc-macro crate's metadata. The proc-macro then produces a
`TokenStream` containing a `Span` pointing into the proc-macro crate
itself.
The recursive nature of 'quote!' can be difficult to understand at
first. The file `src/test/ui/proc-macro/quote-debug.stdout` shows
the output of the `quote!` macro, which should make this eaier to
understand.
This PR also supports custom quoting spans in custom quote macros (e.g.
the `quote` crate). All span quoting goes through the
`proc_macro::quote_span` method, which can be called by a custom quote
macro to perform span quoting. An example of this usage is provided in
`src/test/ui/proc-macro/auxiliary/custom-quote.rs`
Custom quoting currently has a few limitations:
In order to quote a span, we need to generate a call to
`proc_macro::Span::recover_proc_macro_span`. However, proc-macros
support renaming the `proc_macro` crate, so we can't simply hardcode
this path. Previously, the `quote_span` method used the path
`crate::Span` - however, this only works when it is called by the
builtin `quote!` macro in the same crate. To support being called from
arbitrary crates, we need access to the name of the `proc_macro` crate
to generate a path. This PR adds an additional argument to `quote_span`
to specify the name of the `proc_macro` crate. Howver, this feels kind
of hacky, and we may want to change this before stabilizing anything
quote-related.
Additionally, using `quote_span` currently requires enabling the
`proc_macro_internals` feature. The builtin `quote!` macro
has an `#[allow_internal_unstable]` attribute, but this won't work for
custom quote implementations. This will likely require some additional
tricks to apply `allow_internal_unstable` to the span of
`proc_macro::Span::recover_proc_macro_span`.
using allow_internal_unstable (as recommended)
Fixes: #84836
```shell
$ ./build/x86_64-unknown-linux-gnu/stage1/bin/rustc src/test/run-make-fulldeps/coverage/no_cov_crate.rs
error[E0554]: `#![feature]` may not be used on the dev release channel
--> src/test/run-make-fulldeps/coverage/no_cov_crate.rs:2:1
|
2 | #![feature(no_coverage)]
| ^^^^^^^^^^^^^^^^^^^^^^^^
error: aborting due to previous error
For more information about this error, try `rustc --explain E0554`.
```
The Eq trait has a special hidden function. MIR `InstrumentCoverage`
would add this function to the coverage map, but it is never called, so
the `Eq` trait would always appear uncovered.
Fixes: #83601
The fix required creating a new function attribute `no_coverage` to mark
functions that should be ignored by `InstrumentCoverage` and the
coverage `mapgen` (during codegen).
While testing, I also noticed two other issues:
* spanview debug file output ICEd on a function with no body. The
workaround for this is included in this PR.
* `assert_*!()` macro coverage can appear covered if followed by another
`assert_*!()` macro. Normally they appear uncovered. I submitted a new
Issue #84561, and added a coverage test to demonstrate this issue.
This PR modifies the macro expansion infrastructure to handle attributes
in a fully token-based manner. As a result:
* Derives macros no longer lose spans when their input is modified
by eager cfg-expansion. This is accomplished by performing eager
cfg-expansion on the token stream that we pass to the derive
proc-macro
* Inner attributes now preserve spans in all cases, including when we
have multiple inner attributes in a row.
This is accomplished through the following changes:
* New structs `AttrAnnotatedTokenStream` and `AttrAnnotatedTokenTree` are introduced.
These are very similar to a normal `TokenTree`, but they also track
the position of attributes and attribute targets within the stream.
They are built when we collect tokens during parsing.
An `AttrAnnotatedTokenStream` is converted to a regular `TokenStream` when
we invoke a macro.
* Token capturing and `LazyTokenStream` are modified to work with
`AttrAnnotatedTokenStream`. A new `ReplaceRange` type is introduced, which
is created during the parsing of a nested AST node to make the 'outer'
AST node aware of the attributes and attribute target stored deeper in the token stream.
* When we need to perform eager cfg-expansion (either due to `#[derive]` or `#[cfg_eval]`),
we tokenize and reparse our target, capturing additional information about the locations of
`#[cfg]` and `#[cfg_attr]` attributes at any depth within the target.
This is a performance optimization, allowing us to perform less work
in the typical case where captured tokens never have eager cfg-expansion run.
Use AnonConst for asm! constants
This replaces the old system which used explicit promotion. See #83169 for more background.
The syntax for `const` operands is still the same as before: `const <expr>`.
Fixes#83169
Because the implementation is heavily based on inline consts, we suffer from the same issues:
- We lose the ability to use expressions derived from generics. See the deleted tests in `src/test/ui/asm/const.rs`.
- We are hitting the same ICEs as inline consts, for example #78174. It is unlikely that we will be able to stabilize this before inline consts are stabilized.
Don't ICE when using `#[global_alloc]` on a non-item statement
Fixes#83469
We need to return an `Annotatable::Stmt` if we were passed an
`Annotatable::Stmt`
Emit error when trying to use assembler syntax directives in `asm!`
The `.intel_syntax` and `.att_syntax` assembler directives should not be used, in favor of not specifying a syntax for intel, and in favor of the explicit `att_syntax` option using the inline assembly options.
Closes#79869
StructField -> FieldDef ("field definition")
Field -> ExprField ("expression field", not "field expression")
FieldPat -> PatField ("pattern field", not "field pattern")
Also rename visiting and other methods working on them.
Edition-specific preludes
This changes `{std,core}::prelude` to export edition-specific preludes under `rust_2015`, `rust_2018` and `rust_2021`. (As suggested in https://github.com/rust-lang/rust/issues/51418#issuecomment-395630382.) For now they all just re-export `v1::*`, but this allows us to add things to the 2021edition prelude soon.
This also changes the compiler to make the automatically injected prelude import dependent on the selected edition.
cc `@rust-lang/libs` `@djc`
Implement built-in attribute macro `#[cfg_eval]` + some refactoring
This PR implements a built-in attribute macro `#[cfg_eval]` as it was suggested in https://github.com/rust-lang/rust/pull/79078 to avoid `#[derive()]` without arguments being abused as a way to configure input for other attributes.
The macro is used for eagerly expanding all `#[cfg]` and `#[cfg_attr]` attributes in its input ("fully configuring" the input).
The effect is identical to effect of `#[derive(Foo, Bar)]` which also fully configures its input before passing it to macros `Foo` and `Bar`, but unlike `#[derive]` `#[cfg_eval]` can be applied to any syntax nodes supporting macro attributes, not only certain items.
`cfg_eval` was the first name suggested in https://github.com/rust-lang/rust/pull/79078, but other alternatives are also possible, e.g. `cfg_expand`.
```rust
#[cfg_eval]
#[my_attr] // Receives `struct S {}` as input, the field is configured away by `#[cfg_eval]`
struct S {
#[cfg(FALSE)]
field: u8,
}
```
Tracking issue: https://github.com/rust-lang/rust/issues/82679
Crate root is sufficiently different from `mod` items, at least at syntactic level.
Also remove customization point for "`mod` item or crate root" from AST visitors.
The derived implementation of `partial_cmp` compares matching fields one
by one, stopping the computation when the result of a comparison is not
equal to `Some(Equal)`.
On the other hand the derived implementation for `lt`, `le`, `gt` and
`ge` continues the computation when the result of a field comparison is
`None`, consequently those operators are not transitive and inconsistent
with `partial_cmp`.
Fix the inconsistency by using the default implementation that fall-backs
to the `partial_cmp`. This also avoids creating very deeply nested
closures that were quite costly to compile.
Fix bug with assert!() calling the wrong edition of panic!().
The span of `panic!` produced by the `assert` macro did not carry the right edition. This changes `assert` to call the right version.
Also adds tests for the 2021 edition of panic and assert, that would've caught this.
Box the biggest ast::ItemKind variants
This PR is a different approach on https://github.com/rust-lang/rust/pull/81400, aiming to save memory in humongous ASTs.
The three affected item kind enums are:
- `ast::ItemKind` (208 -> 112 bytes)
- `ast::AssocItemKind` (176 -> 72 bytes)
- `ast::ForeignItemKind` (176 -> 72 bytes)
Implement Rust 2021 panic
This implements the Rust 2021 versions of `panic!()`. See https://github.com/rust-lang/rust/issues/80162 and https://github.com/rust-lang/rfcs/pull/3007.
It does so by replacing `{std, core}::panic!()` by a bulitin macro that expands to either `$crate::panic::panic_2015!(..)` or `$crate::panic::panic_2021!(..)` depending on the edition of the caller.
This does not yet make std's panic an alias for core's panic on Rust 2021 as the RFC proposes. That will be a separate change: c5273bdfb2 That change is blocked on figuring out what to do with https://github.com/rust-lang/rust/issues/80846 first.
Expand assert!(expr, args..) to include $crate for hygiene on 2021.
This makes `assert!(expr, args..)` properly hygienic in Rust 2021.
This is part of rust-lang/rfcs#3007, see #80162.
Before edition 2021, this was a breaking change, as `std::panic` and `core::panic` are different. In edition 2021 they will be identical, making it possible to apply proper hygiene here.
Fixes#81007
Previously, we would fail to collect tokens in the proper place when
only builtin attributes were present. As a result, we would end up with
attribute tokens in the collected `TokenStream`, leading to duplication
when we attempted to prepend the attributes from the AST node.
We now explicitly track when token collection must be performed due to
nomterminal parsing.
Before 2021, this was a breaking change, as std::panic and core::panic
are different. In edition 2021 they will be identical, making it
possible again to apply proper hygiene here.
This makes it possible to have both std::panic and core::panic as a
builtin macro, by using different builtin macro names for each.
Also removes SyntaxExtension::is_derive_copy, as the macro name (e.g.
sym::Copy) is now tracked and provides that information directly.
- Adds optional default values to const generic parameters in the AST
and HIR
- Parses these optional default values
- Adds a `const_generics_defaults` feature gate
We now collect tokens for the underlying node wrapped by `StmtKind`
instead of storing tokens directly in `Stmt`.
`LazyTokenStream` now supports capturing a trailing semicolon after it
is initially constructed. This allows us to avoid refactoring statement
parsing to wrap the parsing of the semicolon in `parse_tokens`.
Attributes on item statements
(e.g. `fn foo() { #[bar] struct MyStruct; }`) are now treated as
item attributes, not statement attributes, which is consistent with how
we handle attributes on other kinds of statements. The feature-gating
code is adjusted so that proc-macro attributes are still allowed on item
statements on stable.
Two built-in macros (`#[global_allocator]` and `#[test]`) needed to be
adjusted to support being passed `Annotatable::Stmt`.
Add lint for panic!("{}")
This adds a lint that warns about `panic!("{}")`.
`panic!(msg)` invocations with a single argument use their argument as panic payload literally, without using it as a format string. The same holds for `assert!(expr, msg)`.
This lints checks if `msg` is a string literal (after expansion), and warns in case it contained braces. It suggests to insert `"{}", ` to use the message literally, or to add arguments to use it as a format string.
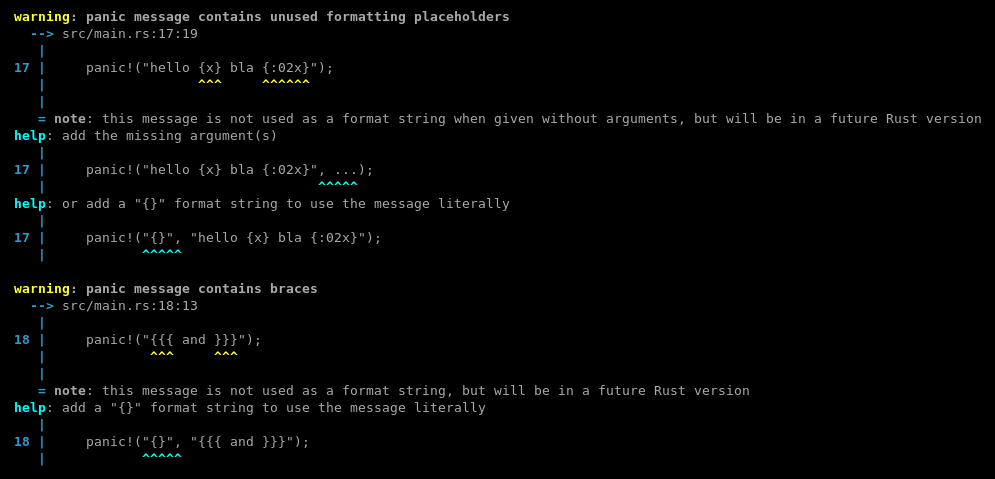
This lint is also a good starting point for adding warnings about `panic!(not_a_string)` later, once [`panic_any()`](https://github.com/rust-lang/rust/pull/74622) becomes a stable alternative.
cleanup: Remove `ParseSess::injected_crate_name`
Its only remaining use is in pretty-printing where the necessary information can be easily re-computed.
The discussion seems to have resolved that this lint is a bit "noisy" in
that applying it in all places would result in a reduction in
readability.
A few of the trivial functions (like `Path::new`) are fine to leave
outside of closures.
The general rule seems to be that anything that is obviously an
allocation (`Box`, `Vec`, `vec![]`) should be in a closure, even if it
is a 0-sized allocation.
rustc_target: Further cleanup use of target options
Follow up to https://github.com/rust-lang/rust/pull/77729.
Implements items 2 and 4 from the list in https://github.com/rust-lang/rust/pull/77729#issue-500228243.
The first commit collapses uses of `target.options.foo` into `target.foo`.
The second commit renames some target options to avoid tautology:
`target.target_endian` -> `target.endian`
`target.target_c_int_width` -> `target.c_int_width`
`target.target_os` -> `target.os`
`target.target_env` -> `target.env`
`target.target_vendor` -> `target.vendor`
`target.target_family` -> `target.os_family`
`target.target_mcount` -> `target.mcount`
r? `@Mark-Simulacrum`
{kind=link}