The fix is admittedly quit literally just papering over.
Long-term, I see two more principled approaches:
* we switch to a fully tree-based impl, without parse . to_string
step; with this approach, there shouldn't be any panics. The results
might be nonsensical, but so was the original input.
* we preserve the invariant that re-parsing constructed node is an
identity, and make all the `make_xxx` method return an `Option`.
closes#4044
Detailed changes:
1) Implement a lexer for string literals that divides the string in format specifier `{}` including the format specifier modifier.
2) Adapt syntax highlighting to add ranges for the detected sequences.
3) Add a test case for the format string syntax highlighting.
4035: Convert bool to ident instead of literal in mbe r=matklad a=edwin0cheng
Fixed#1249
Currently we treat boolean literal as `tt::Literal` , which makes parsing $lit:lit matcher easily.
However, proc-macro2 treat boolean literal as `ident` :
4173a21dc4/src/lib.rs (L939)
OT: I am quite happy we finally need to fix this bug :)
Co-authored-by: Edwin Cheng <edwin0cheng@gmail.com>
4034: Add semantic tag for unresolved references r=matklad a=matklad
This is a quick way to implement unresolved reference diagnostics.
For example, adding to VS Code config
"editor.tokenColorCustomizationsExperimental": {
"unresolvedReference": "#FF0000"
},
will highlight all unresolved refs in red.
Co-authored-by: Aleksey Kladov <aleksey.kladov@gmail.com>
This is a quick way to implement unresolved reference diagnostics.
For example, adding to VS Code config
"editor.tokenColorCustomizationsExperimental": {
"unresolvedReference": "#FF0000"
},
will highlight all unresolved refs in red.
3894: Match check enum record r=flodiebold a=JoshMcguigan
This PR implements match statement exhaustiveness checking for record type enums.
It also make a minor addition to the test infrastructure to allow testing against a single diagnostic, so you can be sure your test is triggering (or not) whichever diagnostic you expect.
Co-authored-by: Josh Mcguigan <joshmcg88@gmail.com>
4029: Fix various proc-macro bugs r=matklad a=edwin0cheng
This PRs does the following things:
1. Fixed#4001 by splitting `LIFETIME` lexer token to two mbe tokens. It is because rustc token stream expects `LIFETIME` as a combination of punct and ident, but RA `tt:TokenTree` treats it as a single `Ident` previously.
2. Fixed#4003, by skipping `proc-macro` for completion. It is because currently we don't have `AstNode` for `proc-macro`. We would need to redesign how to implement `HasSource` for `proc-macro`.
3. Fixed a bug how empty `TokenStream` merging in `proc-macro-srv` such that no L_DOLLAR and R_DOLLAR will be emitted accidentally.
Co-authored-by: Edwin Cheng <edwin0cheng@gmail.com>
4023: Fix another crash from wrong binders r=matklad a=flodiebold
Basically, if we had something like `dyn Trait<T>` (where `T` is a type parameter) in an impl we lowered that to `dyn Trait<^0.0>`, when it should be `dyn Trait<^1.0>` because the `dyn` introduces a new binder. With one type parameter, that's just wrong, with two, it'll lead to crashes.
Co-authored-by: Florian Diebold <flodiebold@gmail.com>
Basically, if we had something like `dyn Trait<T>` (where `T` is a type
parameter) in an impl we lowered that to `dyn Trait<^0.0>`, when it should be
`dyn Trait<^1.0>` because the `dyn` introduces a new binder. With one type
parameter, that's just wrong, with two, it'll lead to crashes.
Fixes a lot of false type mismatches.
(And as always when touching the unification code, I have to say I'm looking
forward to replacing it by Chalk's...)
It's not entirely clear what subnode ranges should mean in the
presence of macros, so let's leave them out for now. We are not using
them heavily anyway.
3996: Fix path for proc-macro in nightly / stable release r=matklad a=edwin0cheng
I messed up that I forget we use different executable names for nightly / stable release, I changed to use the current executable name instead.
Co-authored-by: Edwin Cheng <edwin0cheng@gmail.com>
3958: Add proc-macro related config and tests r=matklad a=edwin0cheng
This PR do the following things:
1. Add cli argument `proc-macro` for running proc-macro server.
2. Added support for proc-macro in bench and analysis-stats
3. Added typescript config for proc-macros
4. Added an heavy test for proc-macros.
To test it out:
1. run `cargo xtask install --proc-macro`
2. add `"rust-analyzer.cargo.loadOutDirsFromCheck": true"` and `"rust-analyzer.procMacro.enabled": true"` in vs code config.
[Edit] Change to use `rust-analyzer proc-macro` for running proc-macro standalone process.
Co-authored-by: Edwin Cheng <edwin0cheng@gmail.com>
3979: fix missing match arm false positive for enum with no variants r=flodiebold a=JoshMcguigan
fixes#3974
Co-authored-by: Josh Mcguigan <joshmcg88@gmail.com>
3966: Add support for bounds on associated types in trait definitions r=matklad a=flodiebold
E.g.
```rust
trait Trait {
type Item: SomeOtherTrait;
}
```
Note that these don't simply desugar to where clauses; as I understand it, where clauses have to be proved by the *user* of the trait, but these bounds are proved by the *implementor*. (Also, where clauses on associated types are unstable.)
(Another one from my recursive solver branch...)
3968: Remove format from syntax_bridge hot path r=matklad a=edwin0cheng
Although only around 1% speed up by running:
```
Measure-Command {start-process .\target\release\rust-analyzer "analysis-stats -q ." -NoNewWindow -wait}
```
Co-authored-by: Florian Diebold <flodiebold@gmail.com>
Co-authored-by: Edwin Cheng <edwin0cheng@gmail.com>
3964: Nicer Chalk debug logs r=matklad a=flodiebold
I'm looking at a lot of Chalk debug logs at the moment, so here's a few changes to make them slightly nicer...
3965: Implement inline associated type bounds r=matklad a=flodiebold
Like `Iterator<Item: SomeTrait>`.
This is an unstable feature, but it's used in the standard library e.g. in the definition of Flatten, so we can't get away with not implementing it :)
(This is cherry-picked from my recursive solver branch, where it works better, but I did manage to write a test that works with the current Chalk solver as well...)
3967: Handle `Self::Type` in trait definitions when referring to own associated type r=matklad a=flodiebold
It was implemented for other generic parameters for the trait, but not for `Self`.
(Last one off my recursive solver branch 😄 )
Co-authored-by: Florian Diebold <flodiebold@gmail.com>
3969: Change add_function assist to use todo!() instead of unimplemented!() r=matklad a=TimoFreiberg
In the spirit of #3935
Co-authored-by: Timo Freiberg <timo.freiberg@gmail.com>
3971: add diagnostics subcommand to rust-analyzer CLI r=JoshMcguigan a=JoshMcguigan
This PR adds a `diagnostics` subcommand to the rust-analyzer CLI. The intent is to detect all diagnostics on a workspace. It returns a non-zero status code if any error diagnostics are detected. Ideally I'd like to run this in CI against the rust analyzer project as a guard against false positives.
```
$ cargo run --release --bin rust-analyzer -- diagnostics .
```
Questions for reviewers:
1. Is this the proper way to get all diagnostics for a workspace? It seems there are at least a few ways this can be done, and I'm not sure if this is the most appropriate mechanism to do this.
2. It currently prints out the relative file path as it is collecting diagnostics, but it doesn't print the crate name. Since the file name is relative to the crate there can be repeated names, so it would be nice to print some identifier for the crate as well, but it wasn't clear to me how best to accomplish this.
Co-authored-by: Josh Mcguigan <joshmcg88@gmail.com>
3961: Fix double comma when merge imports on second line r=edwin0cheng a=IceSentry
This fixes the bug when merging imports from the second line when it already has a comma it would previously insert a comma.
There's probably a better way to check for a COMMA.
This also ends up with a weird indentation, but rust-fmt can easily deal with it so I'm not sure how to resolve that.
Closes#3832
Co-authored-by: IceSentry <c.giguere42@gmail.com>
3960: ellipsis in tuple patterns r=JoshMcguigan a=JoshMcguigan
This PR lowers ellipsis in tuple patterns. It fixes a bug in the way ellipsis were previously lowered (by replacing the ellipsis with a single `Pat::Wild` no matter how many items the `..` was taking the place of).
It also uses this new information to properly handle `..` in tuple struct patterns when perform match statement exhaustiveness checks.
While this PR provides the building blocks for match statement exhaustiveness checks for tuples, there are some additional challenges there, so that is still unimplemented (unlike tuple structs).
Co-authored-by: Josh Mcguigan <joshmcg88@gmail.com>
E.g.
```
trait Trait {
type Item: SomeOtherTrait;
}
```
Note that these don't simply desugar to where clauses; as I understand it, where
clauses have to be proved by the *user* of the trait, but these bounds are proved
by the *implementor*. (Also, where clauses on associated types are unstable.)
Like `Iterator<Item: SomeTrait>`.
This is an unstable feature, but it's used in the standard library e.g. in the
definition of Flatten, so we can't get away with not implementing it :)
This fixes the a bug when merging imports from the second line when it already has a comma it would previously insert a comma.
There's probably a better way to check for a COMMA.
This also ends up with a weird indentation, but rust-fmt can easily deal with it so I'm not sure how to resolve that.
Closes#3832
3938: fix missing match arm false positive r=flodiebold a=JoshMcguigan
This fixes#3932 by skipping the missing match arm diagnostic in the case any of the match arms don't type check properly against the match expression.
I think this is the appropriate behavior for this diagnostic, since `is_useful` relies on all match arms being well formed, and the case of a malformed match arm should probably be handled by a different diagnostic.
Co-authored-by: Josh Mcguigan <joshmcg88@gmail.com>
3955: Align grammar for record patterns and literals r=matklad a=matklad
The grammar now looks like this
[name_ref :] pat
bors r+
🤖
Co-authored-by: Aleksey Kladov <aleksey.kladov@gmail.com>
3925: Implement assist "Reorder field names" r=matklad a=geoffreycopin
This PR implements the "Reorder record fields" assist as discussed in issue #3821 .
Adding a `RecordFieldPat` variant to the `Pat` enum seemed like the easiest way to handle the `RecordPat` children as a single sequence of elements, maybe there is a better way ?
Co-authored-by: Geoffrey Copin <copin.geoffrey@gmail.com>
3944: Look up trait impls by self type r=matklad a=flodiebold
This speeds up inference in analysis-stats by ~30% (even more with the recursive solver).
There's a slight difference in inferred types, which I think comes from pre-existing wrong handling of error types in impls, so I think it's fine.
Co-authored-by: Florian Diebold <flodiebold@gmail.com>
3920: Implement expand_task and list_macros in proc_macro_srv r=matklad a=edwin0cheng
This PR finish up the remain `proc_macro_srv` implementation :
1. Added dylib loading code for proc-macro crate dylib. Note that we have to add some special flags for unix loading because of a bug in old version of glibc, see https://github.com/fedochet/rust-proc-macro-panic-inside-panic-expample/issues/1 and https://github.com/rust-lang/rust/issues/60593 for details.
2. Added tests for proc-macro expansion: We use a trick here by adding `serde_derive` to dev-dependencies and calling `cargo-metadata` for searching its dylib path, and expand it in our tests.
[EDIT]
Note that this PR **DO NOT** implement the final glue code with rust-analzyer and proc-macro-srv yet.
Co-authored-by: Edwin Cheng <edwin0cheng@gmail.com>
todo!() "Indicates unfinished code" (https://doc.rust-lang.org/std/macro.todo.html)
Rust documentation provides further clarification:
> The difference between unimplemented! and todo! is that while todo!
> conveys an intent of implementing the functionality later and the
> message is "not yet implemented", unimplemented! makes no such claims.
todo!() seems more appropriate for assists that insert missing impls.
3905: add ellipsis field to hir pat record r=matklad a=JoshMcguigan
This PR corrects a `fixme`, adding an `ellipsis` field to the hir `Pat::Record` type. It will also be unlock some useful follow on work for #3894.
Additionally it adds a diagnostic for missing fields in record patterns.
~~Marking as a draft because I don't have any tests, and a small amount of manual testing on my branch from #3894 suggests it might *not* be working. Any thoughts on how I can best test this, or else pointers on where I might be going wrong?~~
Co-authored-by: Josh Mcguigan <joshmcg88@gmail.com>
Chalk now panics if we don't implement these methods and run with CHALK_DEBUG,
so I thought I'd try to implement them 'properly'. Sadly, it seems impossible to
do without transmuting lifetimes somewhere. The problem is that we need a `&dyn
HirDatabase` to get names etc., which we can't just put into TLS. I thought I
could just use `scoped-tls`, but that doesn't support references to unsized
types. So I put the `&dyn` into another struct and put the reference to *that*
into the TLS, but I have to transmute the lifetime to 'static for that to work.
3918: Add support for feature attributes in struct literal r=matklad a=bnjjj
As promised here is the next PR to solve 2 different scenarios with feature flag on struct literal.
close#3870
Co-authored-by: Benjamin Coenen <5719034+bnjjj@users.noreply.github.com>
3901: Add more heuristics for hiding obvious param hints r=matklad a=IceSentry
This will now hide `value`, `pat`, `rhs` and `other`. These words were selected from the std because they are used in commonly used functions with only a single param and are obvious by their use.
It will also hide the hint if the passed param **starts** or end with the param_name. Maybe we could also split on '_' and check if one of the string is the param_name.
I think it would be good to also hide `bytes` if the type is `[u8; n]` but I'm not sure how to get the param type signature.
Closes#3900
Co-authored-by: IceSentry <c.giguere42@gmail.com>
3880: Add support for attributes for struct fields r=matklad a=bnjjj
Hello I try to solve this example:
```rust
struct MyStruct {
my_val: usize,
#[cfg(feature = "foo")]
bar: bool,
}
impl MyStruct {
#[cfg(feature = "foo")]
pub(crate) fn new(my_val: usize, bar: bool) -> Self {
Self { my_val, bar }
}
#[cfg(not(feature = "foo"))]
pub(crate) fn new(my_val: usize, _bar: bool) -> Self {
Self { my_val }
}
}
```
Here is a draft PR to try to solve this issue. In fact for now when i have this kind of example, rust-analyzer tells me that my second Self {} miss the bar field. Which is a bug.
I have some difficulties to add this features. Here in my draft I share my work about adding attributes support on struct field data. But I'm stuck when I have to fetch attributes from parent expressions. I don't really know how to do that. For the first iteration I just want to solve my issue without solving on all different expressions. And then after I will try to implement that on different kind of expression. I think I have to fetch my FunctionId and then I will be able to find attributes with myFunction.attrs() But I don't know if it's the right way.
@matklad (or anyone else) if you can help me it would be great :D
Co-authored-by: Benjamin Coenen <5719034+bnjjj@users.noreply.github.com>
This will now hide "value", "pat", "rhs" and "other"
These words were selected from the std because they are used in common functions with only a single param and are obvious by their use.
I think it would be good to also hide "bytes" if the type is `[u8; n]` but I'm not sure how to get the param type signature
It will also hide the hint if the passed param starts or end with the param_name
- Adds a new AstElement trait that is implemented by all generated
node, token and enum structs
- Overhauls the code generators to code-generate all tokens, and
also enhances enums to support including tokens, node, and nested
enums
3826: Flatten nested highlight ranges during DFS traversal r=matklad a=ltentrup
Implements the flattening of nested highlights from #3447.
There is a caveat: I needed to add `Clone` to `HighlightedRange` to split highlight ranges ~and the nesting does not appear in the syntax highlighting test (it does appear in the accidental-quadratic test but there it is not checked against a ground-truth)~.
I have added a test case for the example mentioned in #3447.
Co-authored-by: Leander Tentrup <leander.tentrup@gmail.com>
3892: Add L_DOLLAR for TYPE_RECOVERY_SET r=matklad a=edwin0cheng
This PR is a hot fix for issue #3861 that just prevent it make the parser being stuck.
The actual problem described in https://github.com/rust-analyzer/rust-analyzer/pull/3873#issuecomment-610208693 is a very deep rabbit hole I don't want to dig right now :(
Co-authored-by: Edwin Cheng <edwin0cheng@gmail.com>
The sytax tree output files now use .rast extension
(rust-analyzer syntax tree or rust abstract syntax tree
(whatever)).
This format has a editors/code/ra_syntax_tree.tmGrammar.json declaration
that supplies nice syntax highlighting for .rast files.
3843: Remove rustc_lexer dependency in favour of rustc-ap-rustc_lexer r=est31 a=est31
The latter is auto-published on a regular schedule (Right now weekly).
See also https://github.com/alexcrichton/rustc-auto-publish
Co-authored-by: est31 <MTest31@outlook.com>
3829: Adds to SSR match for semantically equivalent call and method call r=matklad a=mikhail-m1
#3186
maybe I've missed some corner cases, but it works in general
Co-authored-by: Mikhail Modin <mikhailm1@gmail.com>
In textmate, keyword.control is used for all kinds of things; in fact,
the default scope mapping for keyword is keyword.control!
So let's add a less ambiguous controlFlow modifier
See Microsoft/vscode#94367
The big change here is counting binders, not
variables (https://github.com/rust-lang/chalk/pull/360). We have to adapt to the
same scheme for our `Ty::Bound`. It's mostly fine though, even makes some things
more clear.
We treat macro calls as expressions (there's appropriate Into impl),
which causes problem if there's expresison and non-expression macro in
the same node (like in the match arm).
We fix this problem by nesting macor patterns into another node (the
same way we nest path into PathExpr or PathPat). Ideally, we probably
should add a similar nesting for macro expressions, but that needs
some careful thinking about macros in blocks: `{ am_i_expression!() }`.
3746: Add create_function assist r=flodiebold a=TimoFreiberg
The function part of #3639, creating methods will come later
- [X] Function arguments
- [X] Function call arguments
- [x] Method call arguments
- [x] Literal arguments
- [x] Variable reference arguments
- [X] Migrate to `ast::make` API
Done, but there are some ugly spots.
Issues to handle in another PR:
- function reference arguments: Their type isn't printed properly right now.
The "insert explicit type" assist has the same issue and this is probably a relatively rare usecase.
- generating proper names for all kinds of argument expressions (if, loop, ...?)
Without this, it's totally possible for the assist to generate invalid argument names.
I think the assist it's already helpful enough to be shipped as it is, at least for me the main usecase involves passing in named references.
Besides, the Rust tooling ecosystem is immature enough that some janky behaviour in a new assist probably won't scare anyone off.
- select the generated placeholder body so it's a bit easier to overwrite it
- create method (`self.foo<|>(..)` or `some_foo.foo<|>(..)`) instead of create_function.
The main difference would be finding (or creating) the impl block and inserting the `self` argument correctly
- more specific default arg names for literals.
So far, every generated argument whose name can't be taken from the call site is called `arg` (with a number suffix if necessary).
- creating functions in another module of the same crate.
E.g. when typing `some_mod::foo<|>(...)` when in `lib.rs`, I'd want to have `foo` generated in `some_mod.rs` and jump there.
Issues: the mod could exist in `some_mod.rs`, in `lib.rs` as `mod some_mod`, or inside another mod but be imported via `use other_mod::some_mod`.
- refer to arguments of the generated function with a qualified path if the types aren't imported yet
(alternative: run autoimport. i think starting with a qualified path is cleaner and there's already an assist to replace a qualified path with an import and an unqualified path)
- add type arguments of the arguments to the generated function
- Autocomplete functions with information from unresolved calls (see https://github.com/rust-analyzer/rust-analyzer/pull/3746#issuecomment-605281323)
Issues: see https://github.com/rust-analyzer/rust-analyzer/pull/3746#issuecomment-605282542. The unresolved call could be anywhere. But just offering this autocompletion for unresolved calls in the same module would already be cool.
Co-authored-by: Timo Freiberg <timo.freiberg@gmail.com>
3814: Add impl From for enum variant assist r=flodiebold a=mattyhall
Basically adds a From impl for tuple enum variants with one field. It was recommended to me on the zulip to maybe try using the trait solver, but I had trouble with that as, although it could resolve the trait impl, it couldn't resolve the variable unambiguously in real use. I'm also unsure of how it would work if there were already multiple From impls to resolve - I can't see a way we could get more than one solution to my query.
Fixes#3766
Co-authored-by: Matthew Hall <matthew@quickbeam.me.uk>
This commit is a fixup of a bug I introduced by using a PackageId to refer to a crate when its name conflicts with a dependency.
It turns out the package id currently is `name version path` while cargo expects `name:version` as argument.
Basically adds a From impl for tuple enum variants with one field. Added
to cover the fairly common case of implementing your own Error that can
be created from another one, although other use cases exist.
3806: lower bool literal value r=flodiebold a=JoshMcguigan
Following up on #3805, this PR adds the literal value to `ast::LiteralKind` so when we lower we can use the actual value from the source code rather than the default value for the type. Ultimately I plan to use this for exhaustiveness checking in #3706.
I didn't include this in the previous PR because I wasn't sure if it made sense to add this information to `ast::LiteralKind` or provide some other mechanism to get this from `ast::Literal`.
For now I've only implemented this for boolean literals, but I think it could be easily extended to other types. A possible exception to this are string literals, since we may not want to clone around an owned string to hold onto in `ast::LiteralKind`, and it'd be nice to avoid adding a generic lifetime as well. Perhaps we won't ever care about the actual value of a string literal?
Co-authored-by: Josh Mcguigan <joshmcg88@gmail.com>
3797: Don't show chaining hints for record literals and unit structs r=matklad a=lnicola
Fixes#3796
r? @Veetaha
Co-authored-by: Laurențiu Nicola <lnicola@dend.ro>
3805: lower literal patterns r=JoshMcguigan a=JoshMcguigan
While working on #3706 I discovered literal patterns weren't being lowered. This PR implements that lowering.
Questions for reviewers:
1. This re-uses the existing conversion from `ast::LiteralKind` to `Literal`, but `ast::LiteralKind` doesn't include information about the actual value of the literal, which causes `Literal` to be created with the default value for the type (rather than the actual value in the source code). Am I correct in thinking that we'd eventually want to change things in such a way that we could initialize the `Literal` with the actual literal value? Is there an existing issue for this, or else perhaps I should create one to discuss how it should be implemented? My main question would be whether `ast::LiteralKind` should be extended to hold the actual value, or if we should provide some other way to get that information from `ast::Literal`?
2. I couldn't find tests which directly cover this, but it does seem to work in #3706. Do we have unit tests for this lowering code?
3. I'm not sure why `lit.literal()` returns an `Option`. Is returning a `Pat::Missing` in the `None` case the right thing to do?
4. I was basically practicing type-system driven development to figure out the transformation from `ast::Pat::LiteralPat` to `Pat::Lit`. I don't have an immediate question here, but I just wanted to ensure this section is looked at closely during review.
Co-authored-by: Josh Mcguigan <joshmcg88@gmail.com>
3780: Simplify r=matklad a=Veetaha
I absolutely love tha fact that removing `.clone()` simplifies the code comparing to other languages where it's actually the contrary (ahem ~~`std::move()`~~)
3787: vscode: add syntax tree inspection hovers and highlights r=matklad a=Veetaha
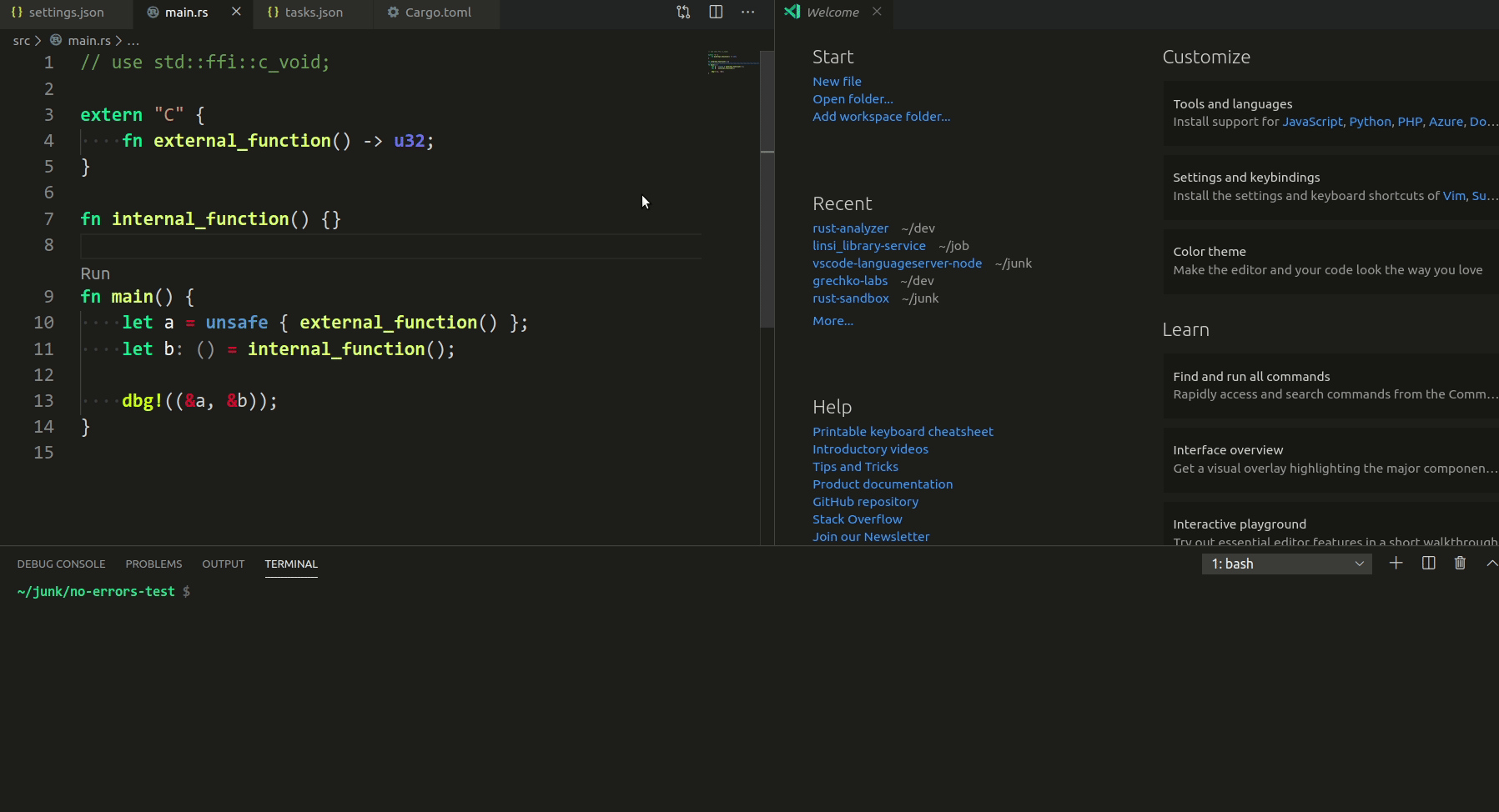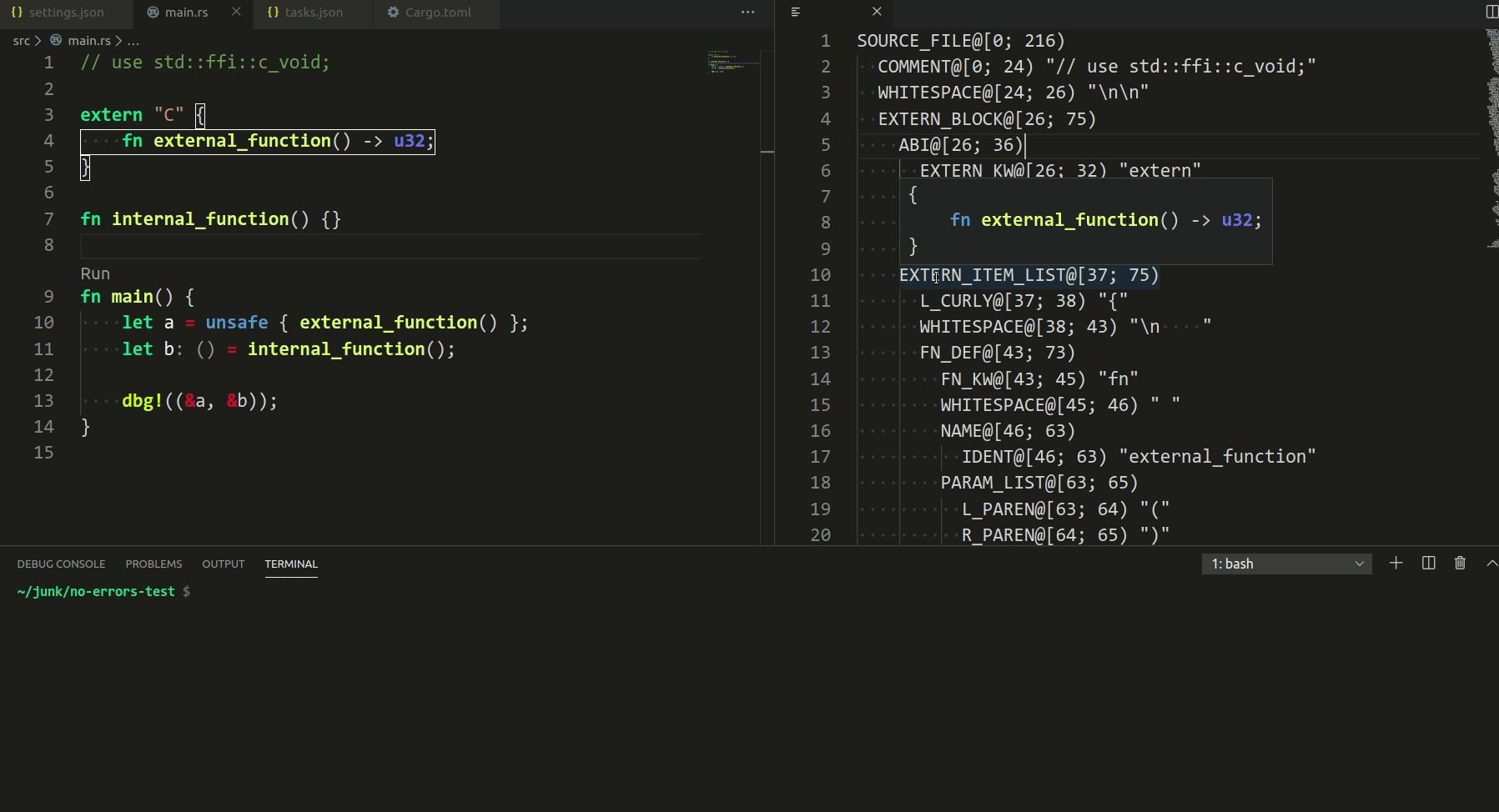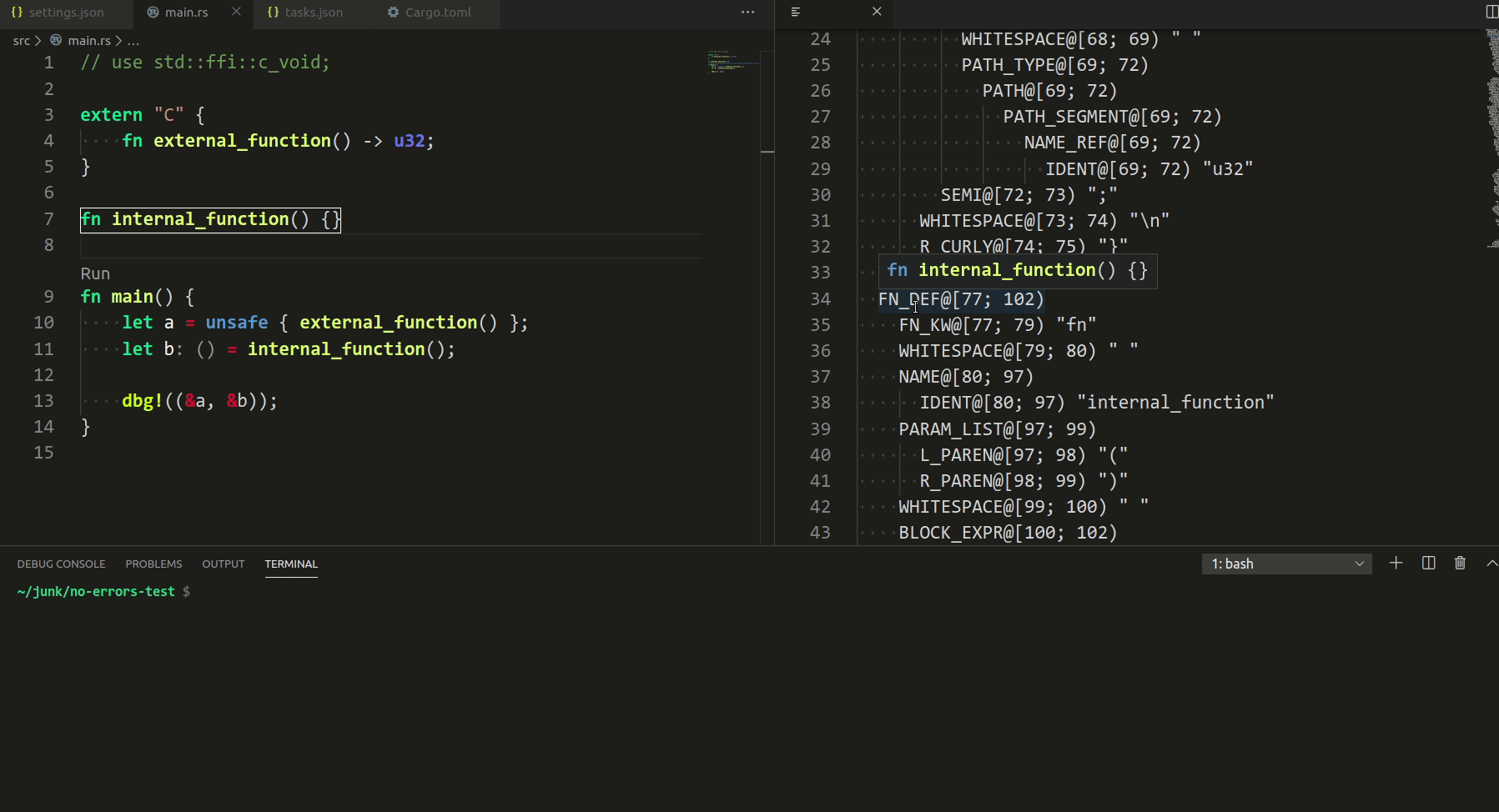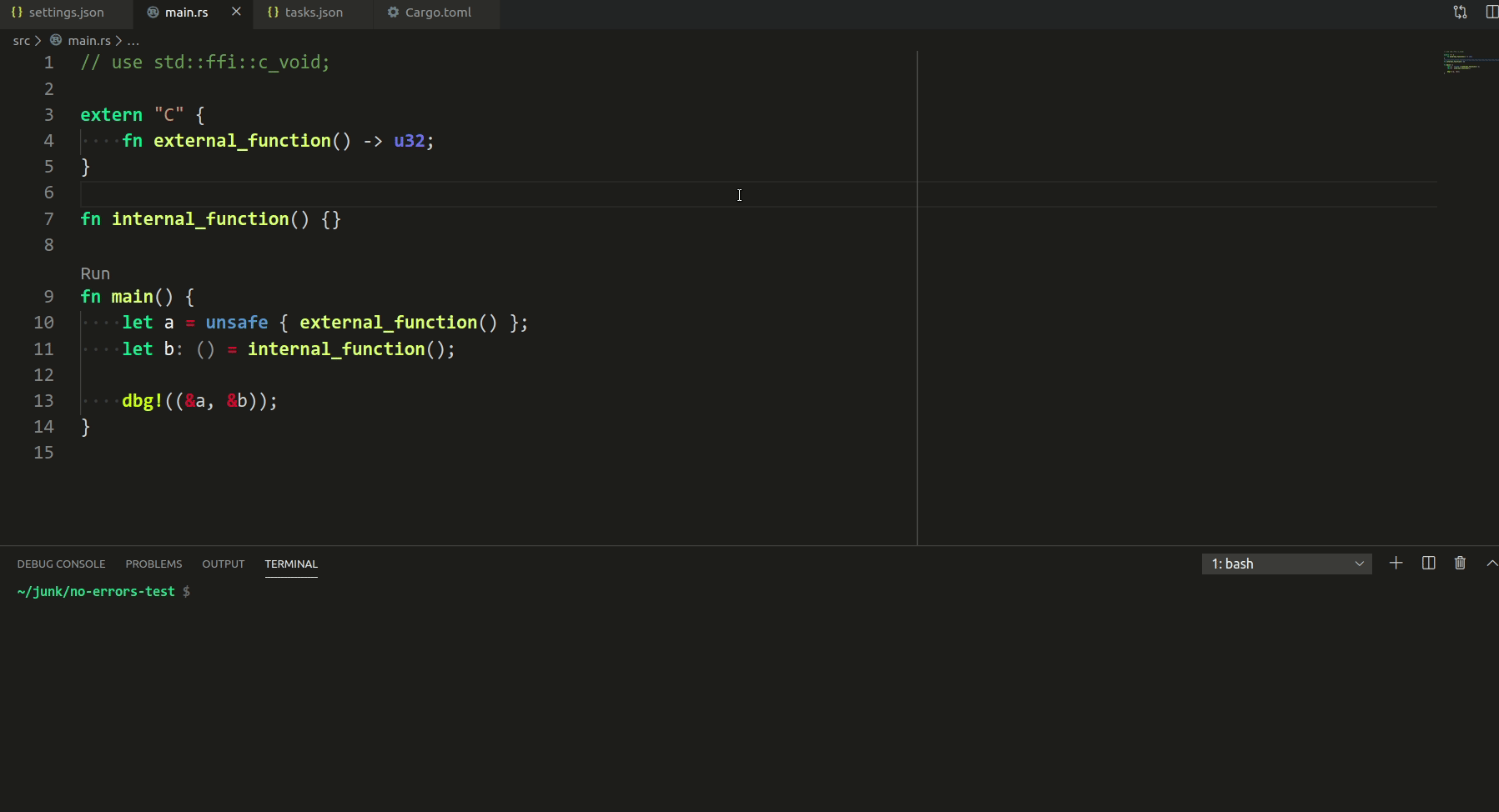
I implemented the reverse mapping (when you hover in the rust editor), but it seems overcomplicated, so I removed it
Related #3682
Co-authored-by: veetaha <veetaha2@gmail.com>
Co-authored-by: Veetaha <veetaha2@gmail.com>
3778: Use more functional programming in ArenaMap::insert r=matklad a=kjeremy
I find this more readable and it flattens out the body a little. Others may disagree.
Co-authored-by: kjeremy <kjeremy@gmail.com>
3781: Add crate versions when running cargo -p commands. r=matklad a=o0Ignition0o
If someone (unfortunately) creates a project that happens to have the same name as one of its (future) dependencies, there is [a way for them to change the dependency's alias in the Cargo.toml file](https://doc.rust-lang.org/cargo/reference/specifying-dependencies.html#renaming-dependencies-in-cargotoml), to mitigate the name conflict. Unfortunately cargo -p commands don't seem to pick it up, which seems to put rust-analyzer run commands in a tough situation:
```
> Executing task: cargo test --package config --example default -- tests --nocapture <
error: There are multiple `config` packages in your project, and the specification `config` is ambiguous.
Please re-run this command with `-p <spec>` where `<spec>` is one of the following:
config:0.1.0
config:0.9.3
The terminal process terminated with exit code: 101
```
cargo suggests us to be more specific and refer to a package by its name and version, which this PR achieves.
I passed the version as a String because I don't really understand how the ra_db types work, but I would love to switch it to [a fully fledged Version type](https://steveklabnik.github.io/semver/semver/index.html) if you guide me towards that :)
Co-authored-by: o0Ignition0o <jeremy.lempereur@gmail.com>
Until now cargo commands with the -p flag would pass the package name only.
It doesn't play super well with the toml Renaming dependencies feature.
This commit specifies the package name and version when a cargo command is run with the -p flag,
to avoid ambiguities.
This commit changes the parser to attach doc-comments to the corresponding declaration in case there are newlines in between the doc-comment and the declaration.
3761: Append new match arms rather than replacing all of them r=matklad a=mattyhall
This means we now retain comments when filling in match arms. This fixes#3687. This is my first contribution so apologies if it needs a rethink! I think in particular the way I find the position to append to and remove_if_only_whitespace are a little hairy.
Co-authored-by: Matthew Hall <matthew@quickbeam.me.uk>
{kind=link}