The primary motivation is to get the changes from
https://github.com/tokio-rs/tracing/pull/990. Example output:
```
$ RUSTDOC_LOG=debug rustdoc +rustc2
warning: some trace filter directives would enable traces that are disabled statically
| `debug` would enable the DEBUG level for all targets
= note: the static max level is `info`
= help: to enable DEBUG logging, remove the `max_level_info` feature
```
- Remove useless test
This was testing for an ICE when passing `RUST_LOG=rustc_middle`. I
noticed it because it started giving the tracing warning (because tests
are not run with debug-logging enabled). Since this bug seems unlikely
to re-occur, I just removed it altogether.
Rollup of 11 pull requests
Successful merges:
- #76784 (Add some docs to rustdoc::clean::inline and def_id functions)
- #76911 (fix VecDeque::iter_mut aliasing issues)
- #77400 (Fix suggestions for x.py setup)
- #77515 (Update to chalk 0.31)
- #77568 (inliner: use caller param_env)
- #77571 (Use matches! for core::char methods)
- #77582 (Move `EarlyOtherwiseBranch` to mir-opt-level 2)
- #77590 (Update RLS and Rustfmt)
- #77605 (Fix rustc_def_path to show the full path and not the trimmed one)
- #77614 (Let backends access span information)
- #77624 (Add c as a shorthand check alternative for new options #77603)
Failed merges:
r? `@ghost`
Support static linking with glibc and target-feature=+crt-static
With this change, it's possible to build on a linux-gnu target and pass
RUSTFLAGS='-C target-feature=+crt-static' or the equivalent via a
`.cargo/config.toml` file, and get a statically linked executable.
Update to libc 0.2.78, which adds support for static linking with glibc.
Add `crt_static_respected` to the `linux_base` target spec.
Update `android_base` and `linux_musl_base` accordingly. Avoid enabling
crt_static_respected on Android platforms, since that hasn't been
tested.
Closes https://github.com/rust-lang/rust/issues/65447.
This is a combination of 18 commits.
Commit #2:
Additional examples and some small improvements.
Commit #3:
fixed mir-opt non-mir extensions and spanview title elements
Corrected a fairly recent assumption in runtest.rs that all MIR dump
files end in .mir. (It was appending .mir to the graphviz .dot and
spanview .html file names when generating blessed output files. That
also left outdated files in the baseline alongside the files with the
incorrect names, which I've now removed.)
Updated spanview HTML title elements to match their content, replacing a
hardcoded and incorrect name that was left in accidentally when
originally submitted.
Commit #4:
added more test examples
also improved Makefiles with support for non-zero exit status and to
force validation of tests unless a specific test overrides it with a
specific comment.
Commit #5:
Fixed rare issues after testing on real-world crate
Commit #6:
Addressed PR feedback, and removed temporary -Zexperimental-coverage
-Zinstrument-coverage once again supports the latest capabilities of
LLVM instrprof coverage instrumentation.
Also fixed a bug in spanview.
Commit #7:
Fix closure handling, add tests for closures and inner items
And cleaned up other tests for consistency, and to make it more clear
where spans start/end by breaking up lines.
Commit #8:
renamed "typical" test results "expected"
Now that the `llvm-cov show` tests are improved to normally expect
matching actuals, and to allow individual tests to override that
expectation.
Commit #9:
test coverage of inline generic struct function
Commit #10:
Addressed review feedback
* Removed unnecessary Unreachable filter.
* Replaced a match wildcard with remining variants.
* Added more comments to help clarify the role of successors() in the
CFG traversal
Commit #11:
refactoring based on feedback
* refactored `fn coverage_spans()`.
* changed the way I expand an empty coverage span to improve performance
* fixed a typo that I had accidently left in, in visit.rs
Commit #12:
Optimized use of SourceMap and SourceFile
Commit #13:
Fixed a regression, and synched with upstream
Some generated test file names changed due to some new change upstream.
Commit #14:
Stripping out crate disambiguators from demangled names
These can vary depending on the test platform.
Commit #15:
Ignore llvm-cov show diff on test with generics, expand IO error message
Tests with generics produce llvm-cov show results with demangled names
that can include an unstable "crate disambiguator" (hex value). The
value changes when run in the Rust CI Windows environment. I added a sed
filter to strip them out (in a prior commit), but sed also appears to
fail in the same environment. Until I can figure out a workaround, I'm
just going to ignore this specific test result. I added a FIXME to
follow up later, but it's not that critical.
I also saw an error with Windows GNU, but the IO error did not
specify a path for the directory or file that triggered the error. I
updated the error messages to provide more info for next, time but also
noticed some other tests with similar steps did not fail. Looks
spurious.
Commit #16:
Modify rust-demangler to strip disambiguators by default
Commit #17:
Remove std::process::exit from coverage tests
Due to Issue #77553, programs that call std::process::exit() do not
generate coverage results on Windows MSVC.
Commit #18:
fix: test file paths exceeding Windows max path len
Improve build-manifest to work with the improved promote-release
This PR makes some changes to build-manifest to have it work better with the other improvements I'm making to [promote-release](https://github.com/rust-lang/promote-release).
A new way to invoke the tool was added: `./x.py run src/tools/build-manifest`. The new invocation disables the generation of `.sha256` files and the generation of GPG signatures, as those steps are not tied to the Rust version we're building the manifest of: handling them in `promote-release` will improve the maintenability of our release process. Invocations through the old command (`./x.py dist hash-and-sign`) are referred inside the source code as "legacy". The new invocation also enables internal parallelism, disabled on legacy to avoid overloading our old server.
Improvements were also made on how the checksums included in the manifest are generated:
* The manifest is first generated with placeholder checksums, and then a function walks through the manifes and calculates only the needed hashes. Before this PR, all the hashes were calculated beforehand, including the hashes of unused files.
* Calculating the hashes is now done in parallel with rayon, to better utilize all the available disk bandwidth.
* The `sha2` crate is now used instead of the `sha256sum` CLI tool: this avoids the overhead of calling another process, but more importantly enables hardware acceleration whenever available (the `sha256sum` CLI tool doesn't support it at all).
r? @Mark-Simulacrum
This PR is best reviewed commit-by-commit.
Use `tracing` spans to trace the entire MIR interp stack
r? @RalfJung
While being very verbose, this allows really good tracking of what's going on. While I considered schemes like the previous indenter that we had (which we could get by using the `tracing-tree` crate), this will break down horribly with things like multithreaded rustc. Instead, we can now use `RUSTC_LOG` to restrict the things being traced. You could specify a filter in a way that only shows the logging of a specific frame.

If we lower the span's level to `debug`, then in `info` level logging we'd not see the frames, but in `debug` level we would see them. The filtering rules in `tracing` are super powerful, but I'm not sure if we can specify a filter so we do see `debug` level events, but *not* the `frame` spans. The documentation at https://docs.rs/tracing-subscriber/0.2.10/tracing_subscriber/struct.EnvFilter.html makes me think that we can only turn on things, not turn off things at a more precise level.
cc @hawkw
This commit improves the way build-manifest calculates the checksums
included in the manifest, speeding it up:
* Instead of calculating all the hashes beforehand and then using the
ones we need, the manifest is first generated with placeholder hashes,
and then a function walks through the manifest and calculates only the
needed checksums.
* Calculating the checksums is now done in parallel with rayon, to
better utilize all the available disk bandwidth.
* Calculating the checksums now uses the sha2 crate instead of the
sha256sum CLI tool: this avoids the overhead of calling another
process, but more importantly uses hardware acceleration whenever
available (the CLI tool doesn't support it at all).
Refactor versions detection in build-manifest
This PR refactors how `build-manifest` handles versions, making the following changes:
* `build-manifest` now detects the "package releases" on its own, without relying on rustbuild providing them through CLI arguments. This drastically simplifies calling the tool outside of `x.py`, and will allow to ship the prebuilt tool in a tarball in the future, with the goal of stopping to invoke `x.py` during `promote-release`.
* The `tar` command is not used to extract the version and the git hash from tarballs anymore. The `flate2` and `tar` crates are used instead. This makes detecting those pieces of data way faster, as the archive is decompressed just once and we stop parsing the archive once all the information is retrieved.
* The code to extract the version and the git hash now stores all the collected data dynamically, without requiring to add new fields to the `Builder` struct every time.
I tested the changes locally and it should behave the same as before.
r? `@Mark-Simulacrum`
Small improvements in liveness pass
* Remove redundant debug logging (`add_variable` already contains logging).
* Remove redundant fields for a number of live nodes and variables.
* Delay conversion from a symbol to a string until linting.
* Inline contents of specials struct.
* Remove unnecessary local variable exit_ln.
* Use newtype_index for Variable and LiveNode.
* Access live nodes directly through self.lnks[ln].
No functional changes intended (except those related to the logging).
Make `ensure_sufficient_stack()` non-generic, using cargo-llvm-lines
Inspired by [this blog post](https://blog.mozilla.org/nnethercote/2020/08/05/how-to-speed-up-the-rust-compiler-some-more-in-2020/) from `@nnethercote,` I used [cargo-llvm-lines](https://github.com/dtolnay/cargo-llvm-lines/) on the rust compiler itself, to improve it's compile time. This PR contains only one low-hanging fruit, but I also want to share some measurements.
The function `ensure_sufficient_stack()` was monomorphized 1500 times, and with it the `stacker` and `psm` crates, for a total of 1.5% of all llvm IR lines. With some trickery I convert the generic closure into a dynamic one, and thus all that code is only monomorphized once.
# Measurements
Getting these numbers took some fiddling with CLI flags and I [modified](https://github.com/Julian-Wollersberger/cargo-llvm-lines/blob/master/src/main.rs#L115) cargo-llvm-lines to read from a folder instead of invoking cargo. Commands I used:
```
./x.py clean
RUSTFLAGS="--emit=llvm-ir -C link-args=-fuse-ld=lld -Z self-profile=profile" CARGOFLAGS_BOOTSTRAP="-Ztimings" RUSTC_BOOTSTRAP=1 ./x.py build -i --stage 1 library/std
# Then manually copy all .ll files into a folder I hardcoded in cargo-llvm-lines in main.rs#L115
cd ../cargo-llvm-lines
cargo run llvm-lines
```
The result is this list (see [first 500 lines](https://github.com/Julian-Wollersberger/cargo-llvm-lines/blob/master/llvm-lines-rustc-before.txt) ), before the change:
```
Lines Copies Function name
----- ------ -------------
16894211 (100%) 58417 (100%) (TOTAL)
2223855 (13.2%) 502 (0.9%) rustc_query_system::query::plumbing::get_query_impl::{{closure}}
1331918 (7.9%) 1287 (2.2%) hashbrown::raw::RawTable<T>::reserve_rehash
774434 (4.6%) 12043 (20.6%) core::ptr::drop_in_place
294170 (1.7%) 499 (0.9%) rustc_query_system::dep_graph::graph::DepGraph<K>::with_task_impl
245410 (1.5%) 1552 (2.7%) psm::on_stack::with_on_stack
210311 (1.2%) 1 (0.0%) rustc_target::spec::load_specific
200962 (1.2%) 513 (0.9%) rustc_query_system::query::plumbing::get_query_impl
190704 (1.1%) 1 (0.0%) rustc_middle::ty::query::<impl rustc_middle::ty::context::TyCtxt>::alloc_self_profile_query_strings
180272 (1.1%) 468 (0.8%) rustc_query_system::query::plumbing::load_from_disk_and_cache_in_memory
177396 (1.1%) 114 (0.2%) rustc_query_system::query::plumbing::force_query_impl
161134 (1.0%) 445 (0.8%) rustc_query_system::dep_graph::graph::DepGraph<K>::with_anon_task
141551 (0.8%) 186 (0.3%) rustc_query_system::query::plumbing::incremental_verify_ich
110191 (0.7%) 7 (0.0%) rustc_middle::ty::context::_DERIVE_rustc_serialize_Decodable_D_FOR_TypeckResults::<impl rustc_serialize::serialize::Decodable<__D> for rustc_middle::ty::context::TypeckResults>::decode::{{closure}}
108590 (0.6%) 420 (0.7%) core::ops::function::FnOnce::call_once
88488 (0.5%) 21 (0.0%) rustc_query_system::dep_graph::graph::DepGraph<K>::try_mark_previous_green
86368 (0.5%) 1 (0.0%) rustc_middle::ty::query::stats::query_stats
85654 (0.5%) 3973 (6.8%) <&T as core::fmt::Debug>::fmt
84475 (0.5%) 1 (0.0%) rustc_middle::ty::query::Queries::try_collect_active_jobs
81220 (0.5%) 862 (1.5%) <hashbrown::raw::RawIterHash<T> as core::iter::traits::iterator::Iterator>::next
77636 (0.5%) 54 (0.1%) core::slice::sort::recurse
66484 (0.4%) 461 (0.8%) <hashbrown::raw::RawIter<T> as core::iter::traits::iterator::Iterator>::next
```
All `.ll` files together had 4.4GB. After my change they had 4.2GB. So a few percent less code LLVM has to process. Hurray!
Sadly, I couldn't measure an actual wall-time improvement. Watching YouTube while compiling added to much noise...
Here is the top of the list after the change:
```
16460866 (100%) 58341 (100%) (TOTAL)
1903085 (11.6%) 504 (0.9%) rustc_query_system::query::plumbing::get_query_impl::{{closure}}
1331918 (8.1%) 1287 (2.2%) hashbrown::raw::RawTable<T>::reserve_rehash
777796 (4.7%) 12031 (20.6%) core::ptr::drop_in_place
551462 (3.4%) 1519 (2.6%) rustc_data_structures::stack::ensure_sufficient_stack::{{closure}}
```
Note that the total was reduced by 430 000 lines and `psm::on_stack::with_on_stack` has disappeared. Instead `rustc_data_structures::stack::ensure_sufficient_stack::{{closure}}` appeared. I'm confused about that one, but it seems to consist of inlined calls to `rustc_query_system::*` stuff.
Further note the other two big culprits in this list: `rustc_query_system` and `hashbrown`. These two are monomorphized many times, the query system summing to more than 20% of all lines, not even counting code that's probably inlined elsewhere.
Assuming compile times scale linearly with llvm-lines, that means a possible 20% compile time reduction.
Reducing eg. `get_query_impl` would probably need a major refactoring of the qery system though. _Everything_ in there is generic over multiple types, has associated types and passes generic Self arguments by value. Which means you can't simply make things `dyn`.
---------------------------------------
This PR is a small step to make rustc compile faster and thus make contributing to rustc less painful. Nonetheless I love Rust and I find the work around rustc fascinating :)
Add sample defaults for config.toml
- Allow including defaults in `src/bootstrap/defaults` using `profile = "..."`.
- Add default config files, with a README noting they're experimental and asking you to open an issue if you run into trouble. The config files have comments explaining why the defaults are set.
- Combine config files using the `merge` dependency.
This introduces a new dependency on `merge` that hasn't yet been vetted.
I want to improve the output when `include = "x"` isn't found:
```
thread 'main' panicked at 'fs::read_to_string(&file) failed with No such file or directory (os error 2) ("configuration file did not exist")', src/bootstrap/config.rs:522:28
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failed to run: /home/joshua/rustc/build/bootstrap/debug/bootstrap test tidy
Build completed unsuccessfully in 0:00:00
```
However that seems like it could be fixed in a follow-up.
Closes#76619
- Allow including defaults in `src/bootstrap/defaults` using `profile = "..."`
- Add default config files
- Combine config files using the merge dependency.
- Add comments to default config files
- Add a README asking to open an issue if the defaults are bad
- Give a loud error if trying to merge `.target`, since it's not
currently supported
- Use an exhaustive match
- Use `<none>` in config.toml.example to avoid confusion
- Fix bugs in `Merge` derives
Previously, it would completely ignore the profile defaults if there
were any settings in `config.toml`. I sent an email to the `merge` maintainer
asking them to make the behavior in this commit the default.
This introduces a new dependency on `merge` that hasn't yet been vetted.
I want to improve the output when `include = "x"` isn't found:
```
thread 'main' panicked at 'fs::read_to_string(&file) failed with No such file or directory (os error 2) ("configuration file did not exist")', src/bootstrap/config.rs:522:28
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failed to run: /home/joshua/rustc/build/bootstrap/debug/bootstrap test tidy
Build completed unsuccessfully in 0:00:00
```
However that seems like it could be fixed in a follow-up.
Upgrade libz-sys to 1.1.2
The current version has warnings that become errors on new versions of clang shipped in XCode:
```
warning: src/zlib/gzlib.c:214:15: error: implicitly declaring library function 'snprintf' with type 'int (char *, unsigned long, const char *, ...)' [-Werror,-Wimplicit-function-declaration]
warning: (void)snprintf(state->path, len + 1, "%s", (const char *)path);
warning: ^
warning: src/zlib/gzlib.c:214:15: note: include the header <stdio.h> or explicitly provide a declaration for 'snprintf'
warning: 1 error generated.
warning: src/zlib/gzwrite.c:428:11: error: implicitly declaring library function 'vsnprintf' with type 'int (char *, unsigned long, const char *, __builtin_va_list)' [-Werror,-Wimplicit-function-declaration
warning: len = vsnprintf(next, state->size, format, va);
warning: ^
warning: src/zlib/gzwrite.c:428:11: note: include the header <stdio.h> or explicitly provide a declaration for 'vsnprintf'
warning: 1 error generated.
```
r? `@Mark-Simulacrum`
/cc `@joshtriplett`
Issue 72408 nested closures exponential
This fixes#72408.
Nested closures were resulting in exponential compilation time.
This PR is enhancing asymptotic complexity, but also increasing the constant, so I would love to see perf run results.
This fixes#72408.
Nested closures were resulting in exponential compilation time.
As a performance optimization this change introduces MiniSet,
which is a simple small storage optimized set.
Auto-generate lint documentation.
This adds a tool which will generate the lint documentation in the rustc book automatically. This is motivated by keeping the documentation up-to-date, and consistently formatted. It also ensures the examples are correct and that they actually generate the expected lint. The lint groups table is also auto-generated. See https://github.com/rust-lang/compiler-team/issues/349 for the original proposal.
An outline of how this works:
- The `declare_lint!` macro now accepts a doc comment where the documentation is written. This is inspired by how clippy works.
- A new tool `src/tools/lint-docs` scrapes the documentation and adds it to the rustc book during the build.
- It runs each example and verifies its output and embeds the output in the book.
- It does a few formatting checks.
- It verifies that every lint is documented.
- Groups are collected from `rustc -W help`.
I updated the documentation for all the missing lints. I have also added an "Explanation" section to each lint providing a reason for the lint and suggestions on how to resolve it.
This can lead towards a future enhancement of possibly showing these docs via the `--explain` flag to make them easily accessible and discoverable.
Thanks to marcusklaas' hard work in https://github.com/raphlinus/pulldown-cmark/pull/469, this fixes a lot of rustdoc bugs!
- Get rid of unnecessary `RefCell`
- Fix duplicate warnings for broken implicit reference link
- Remove unnecessary copy of links
Tracing update
This does not bring the more significant changes that are coming down the pipeline, but since I've already prepared the PR leaving it up :)
See https://github.com/rust-lang/rust/pull/76210#issuecomment-685065938:
> Unfortunately, tracing 0.1.20 — which contained the change to reduce the amount of code generated by the tracing macros — had to be yanked, as it broke previously-compiling code for some downstream crates. I've not yet had the chance to fix this and release a new patch. So, in order to benefit from the changes to reduce generated code, you'll need to wait until there's a new version of tracing as well as tracing-attributes and tracing-core.
Add derive macro for specifying diagnostics using attributes.
Introduces `#[derive(SessionDiagnostic)]`, a derive macro for specifying structs that can be converted to Diagnostics using directions given by attributes on the struct and its fields. Currently, the following attributes have been implemented:
- `#[code = "..."]` -- this sets the Diagnostic's error code, and must be provided on the struct iself (ie, not on a field). Equivalent to calling `code`.
- `#[message = "..."]` -- this sets the Diagnostic's primary error message.
- `#[label = "..."]` -- this must be applied to fields of type `Span`, and is equivalent to `span_label`
- `#[suggestion(..)]` -- this allows a suggestion message to be supplied. This attribute must be applied to a field of type `Span` or `(Span, Applicability)`, and is equivalent to calling `span_suggestion`. Valid arguments are:
- `message = "..."` -- this sets the suggestion message.
- (Optional) `code = "..."` -- this suggests code for the suggestion. Defaults to empty.
`suggestion`also comes with other variants: `#[suggestion_short(..)]`, `#[suggestion_hidden(..)]` and `#[suggestion_verbose(..)]` which all take the same keys.
Within the strings passed to each attribute, fields can be referenced without needing to be passed explicitly into the format string -- eg, `#[error = "{ident} already declared"] ` will set the error message to `format!("{} already declared", &self.ident)`. Any fields on the struct can be referenced in this way.
Additionally, for any of these attributes, Option fields can be used to only optionally apply the decoration -- for example:
```rust
#[derive(SessionDiagnostic)]
#[code = "E0123"]
struct SomeKindOfError {
...
#[suggestion(message = "informative error message")]
opt_sugg: Option<(Span, Applicability)>
...
}
```
will not emit a suggestion if `opt_sugg` is `None`.
We plan on iterating on this macro further; this PR is a start.
Closes#61132.
r? `@oli-obk`
Support dataflow problems on arbitrary lattices
This PR implements last of the proposed extensions I mentioned in the design meeting for the original dataflow refactor. It extends the current dataflow framework to work with arbitrary lattices, not just `BitSet`s. This is a prerequisite for dataflow-enabled MIR const-propagation. Personally, I am skeptical of the usefulness of doing const-propagation pre-monomorphization, since many useful constants only become known after monomorphization (e.g. `size_of::<T>()`) and users have a natural tendency to hand-optimize the rest. It's probably worth exprimenting with, however, and others have shown interest cc `@rust-lang/wg-mir-opt.`
The `Idx` associated type is moved from `AnalysisDomain` to `GenKillAnalysis` and replaced with an associated `Domain` type that must implement `JoinSemiLattice`. Like before, each `Analysis` defines the "bottom value" for its domain, but can no longer override the dataflow join operator. Analyses that want to use set intersection must now use the `lattice::Dual` newtype. `GenKillAnalysis` impls have an additional requirement that `Self::Domain: BorrowMut<BitSet<Self::Idx>>`, which effectively means that they must use `BitSet<Self::Idx>` or `lattice::Dual<BitSet<Self::Idx>>` as their domain.
Most of these changes were mechanical. However, because a `Domain` is no longer always a powerset of some index type, we can no longer use an `IndexVec<BasicBlock, GenKillSet<A::Idx>>>` to store cached block transfer functions. Instead, we use a boxed `dyn Fn` trait object. I discuss a few alternatives to the current approach in a commit message.
The majority of new lines of code are to preserve existing Graphviz diagrams for those unlucky enough to have to debug dataflow analyses. I find these diagrams incredibly useful when things are going wrong and considered regressing them unacceptable, especially the pretty-printing of `MovePathIndex`s, which are used in many dataflow analyses. This required a parallel `fmt` trait used only for printing dataflow domains, as well as a refactoring of the `graphviz` module now that we cannot expect the domain to be a `BitSet`. Some features did have to be removed, such as the gen/kill display mode (which I didn't use but existed to mirror the output of the old dataflow framework) and line wrapping. Since I had to rewrite much of it anyway, I took the opportunity to switch to a `Visitor` for printing dataflow state diffs instead of using cursors, which are error prone for code that must be generic over both forward and backward analyses. As a side-effect of this change, we no longer have quadratic behavior when writing graphviz diagrams for backward dataflow analyses.
r? `@pnkfelix`
Update expect-test to 1.0
The only change is that `expect_file` now uses path relative to the
current file (same as `include!`). Before, it used paths relative to
the workspace root, which makes no sense.
The only change is that `expect_file` now uses path relative to the
current file (same as `include!`). Before, it used paths relative to
the workspace root, which makes no sense.
Rollup of 14 pull requests
Successful merges:
- #75832 (Move to intra-doc links for wasi/ext/fs.rs, os_str_bytes.rs…)
- #75852 (Switch to intra-doc links in `core::hash`)
- #75874 (Shorten liballoc doc intra link while readable)
- #75881 (Expand rustdoc theme chooser x padding)
- #75885 (Fix another clashing_extern_declarations false positive.)
- #75892 (Fix typo in TLS Model in Unstable Book)
- #75910 (Add test for issue #27130)
- #75917 (Move to intra doc links for core::ptr::non_null)
- #75975 (Allow --bess ing expect-tests in tools)
- #75990 (Add __fastfail for Windows on arm/aarch64)
- #76015 (Fix loading pretty-printers in rust-lldb script)
- #76022 (Clean up rustdoc front-end source code)
- #76029 (Move to intra-doc links for library/core/src/sync/atomic.rs)
- #76057 (Move retokenize hack to save_analysis)
Failed merges:
r? @ghost
Update compiler-builtins
Update the compiler-builtins dependency to include latest changes.
This allows for `aarch64-unknown-linux-musl` to pass all tests.
Fixes#57820 and fixes#46651
It's a unit-test in a sense that it only checks syntax highlighting.
However, the resulting HTML is written to disk and can be easily
inspected in the browser.
To update the test, run with `--bless` argument or set
`UPDATE_EXPEC=1` env var
Introduce expect snapshot testing library into rustc
Snapshot testing is a technique for writing maintainable unit tests.
Unlike usual `assert_eq!` tests, snapshot tests allow
to *automatically* upgrade expected values on test failure.
In a sense, snapshot tests are inline-version of our beloved
UI-tests.
Example:
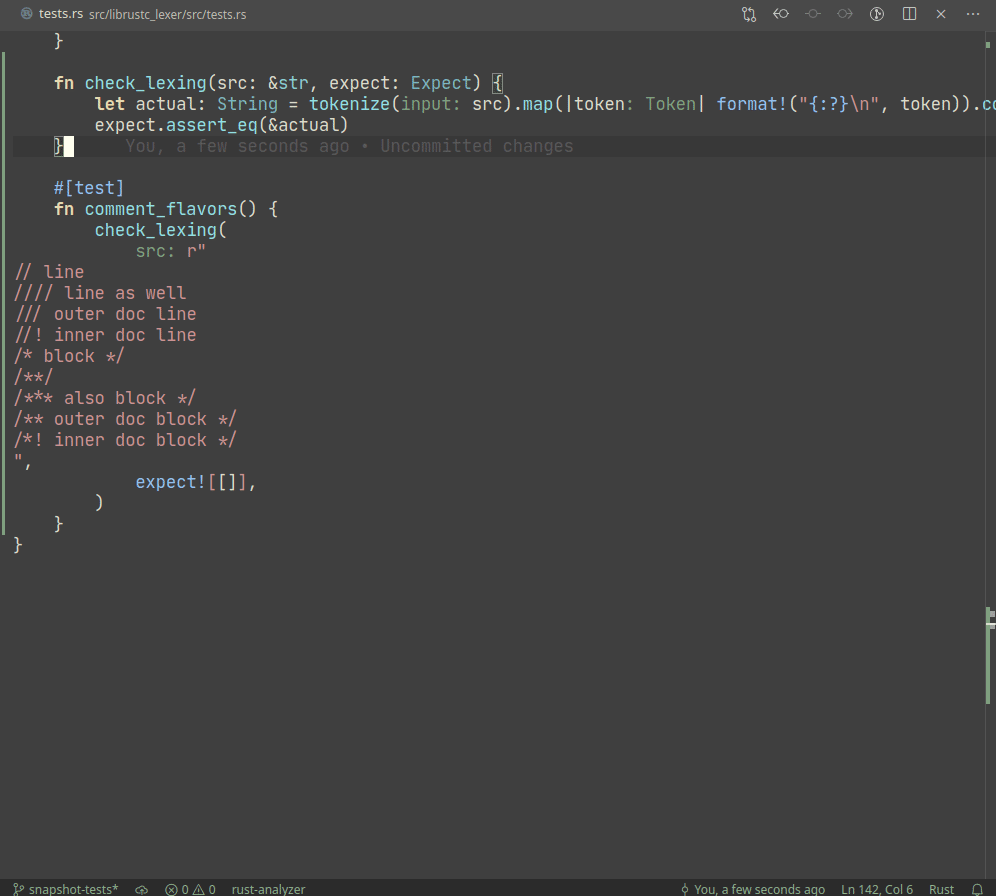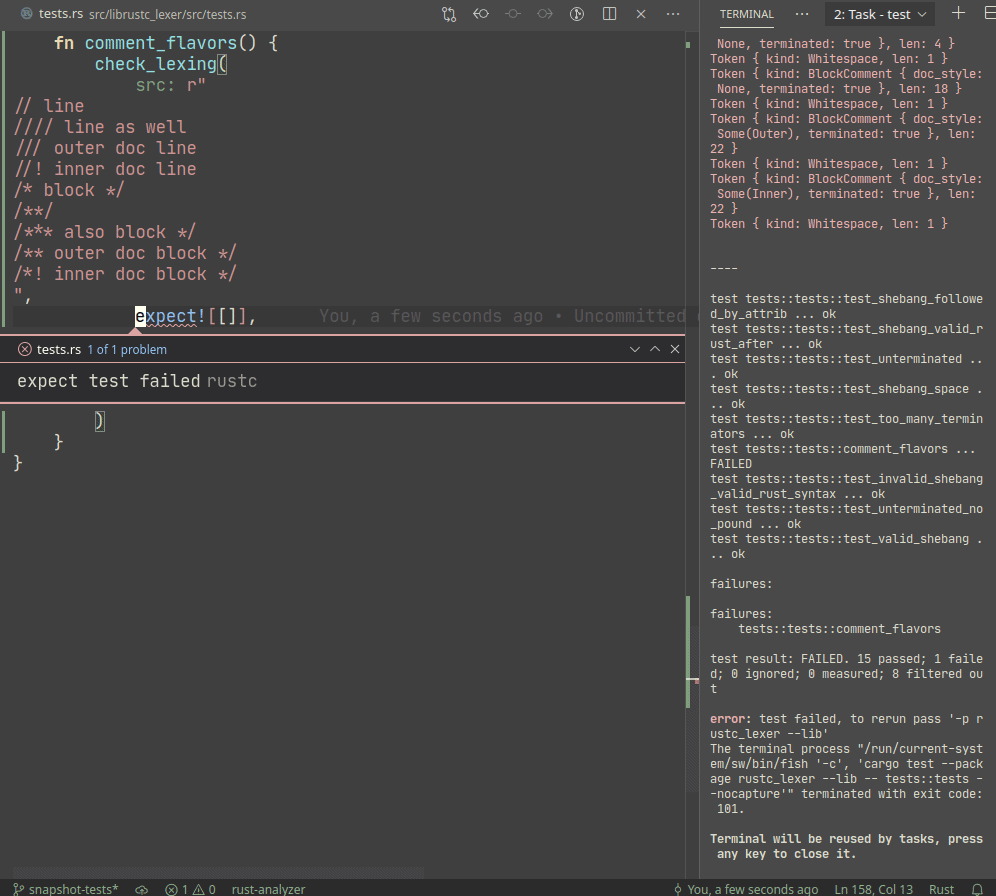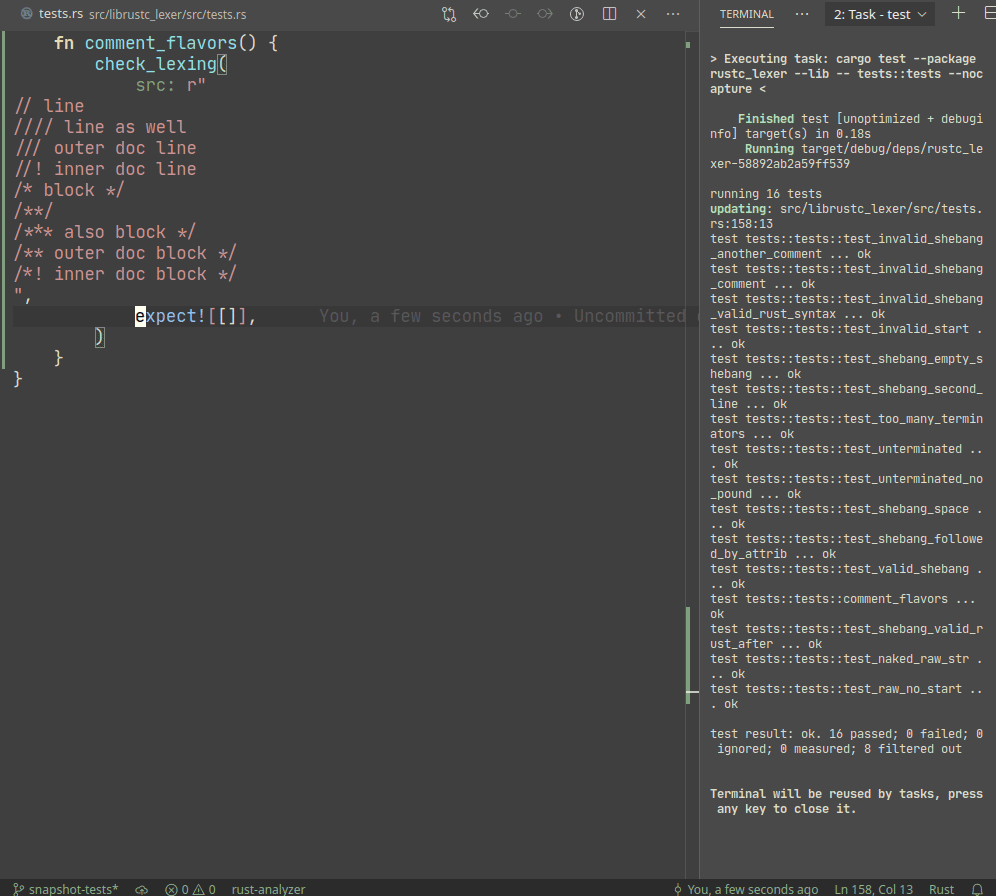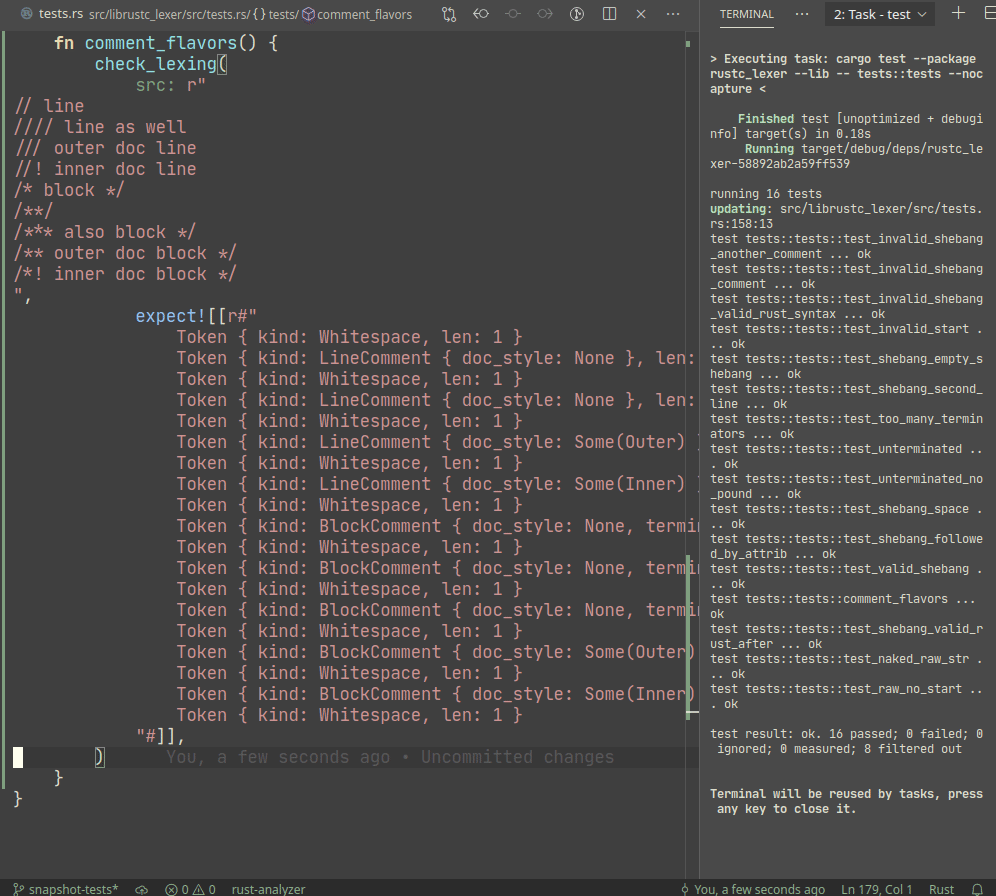
A particular library we use, `expect_test` provides an `expect!`
macro, which creates a sort of self-updating string literal (by using
`file!` macro). Self-update is triggered by setting `UPDATE_EXPECT`
environmental variable (this info is printed during the test failure).
This library was extracted from rust-analyzer, where we use it for
most of our tests.
There are some other, more popular snapshot testing libraries:
* https://github.com/mitsuhiko/insta
* https://github.com/aaronabramov/k9
The main differences of `expect` are:
* first-class snapshot objects (so, tests can be written as functions,
rather than as macros)
* focus on inline-snapshots (but file snapshots are also supported)
* restricted feature set (only `assert_eq` and `assert_debug_eq`)
* no extra runtime (ie, no `cargo insta`)
See rust-analyzer/rust-analyzer#5101 for a
an extended comparison.
It is unclear if this testing style will stick with rustc in the long
run. At the moment, rustc is mainly tested via integrated UI tests.
But in the library-ified world, unit-tests will become somewhat more
important (that's why use use `rustc_lexer` library-ified library as
an example in this PR). Given that the cost of removal shouldn't be
too high, it probably makes sense to just see if this flies!
Snapshot testing is a technique for writing maintainable unit tests.
Unlike usual `assert_eq!` tests, snapshot tests allow
to *automatically* upgrade expected values on test failure.
In a sense, snapshot tests are inline-version of our beloved
UI-tests.
Example:

A particular library we use, `expect_test` provides an `expect!`
macro, which creates a sort of self-updating string literal (by using
`file!` macro). Self-update is triggered by setting `UPDATE_EXPECT`
environmental variable (this info is printed during the test failure).
This library was extracted from rust-analyzer, where we use it for
most of our tests.
There are some other, more popular snapshot testing libraries:
* https://github.com/mitsuhiko/insta
* https://github.com/aaronabramov/k9
The main differences of `expect` are:
* first-class snapshot objects (so, tests can be written as functions,
rather than as macros)
* focus on inline-snapshots (but file snapshots are also supported)
* restricted feature set (only `assert_eq` and `assert_debug_eq`)
* no extra runtime (ie, no `cargo insta`)
See https://github.com/rust-analyzer/rust-analyzer/pull/5101 for a
an extended comparison.
It is unclear if this testing style will stick with rustc in the long
run. At the moment, rustc is mainly tested via integrated UI tests.
But in the library-ified world, unit-tests will become somewhat more
important (that's why use use `rustc_lexer` library-ified library as
an example in this PR). Given that the cost of removal shouldn't be
too high, it probably makes sense to just see if this flies!
- Move the type parameter from `encode` and `decode` methods to
the trait.
- Remove `UseSpecialized(En|De)codable` traits.
- Remove blanket impls for references.
- Add `RefDecodable` trait to allow deserializing to arena-allocated
references safely.
- Remove ability to (de)serialize HIR.
- Create proc-macros `(Ty)?(En|De)codable` to help implement these new
traits.
Move platform support to the rustc book.
This moves the [Platform Support](https://forge.rust-lang.org/release/platform-support.html) page from the forge to the rustc book. There are several reasons for doing this:
* The forge is not really oriented towards end-users (it mostly contains infrastructure, governance and policy, internal team pages, etc.). This platform support page is useful to user to know which targets are supported.
* This page can now be updated in-sync with any PRs that add or remove a target, or change its status.
* This is now automatically checked on CI to verify the list does not get out of sync. Currently it only checks the presence/absence of an entry, but more sophisticated checks could be added in the future.
I'm not 100% certain this is the best location, but I think it fits. I'd like to see the rustc guide continue to grow, including things like linking information and more platform-specific details.
{kind=link}
{kind=link}