It looks like the last time had left some remaining cfg's -- which made me think
that the stage0 bump was actually successful. This brings us to a released 1.62
beta though.
This was relying on the presence of a bitcast to avoid using the
constant global initializer for a load using a different type.
With opaque pointers, we need to check this explicitly.
Ensure all error checking for `#[debugger_visualizer]` is done up front and not when the `debugger_visualizer` query is run.
Clean up potential ODR violations when embedding pretty printers into the `__rustc_debug_gdb_scripts_section__` section.
Respond to PR comments and update documentation.
don't encode only locally used attrs
Part of https://github.com/rust-lang/compiler-team/issues/505.
We now filter builtin attributes before encoding them in the crate metadata in case they should only be used in the local crate. To prevent accidental misuse `get_attrs` now requires the caller to state which attribute they are interested in. For places where that isn't trivially possible, I've added a method `fn get_attrs_unchecked` which I intend to remove in a followup PR.
After this pull request landed, we can then slowly move all attributes to only be used in the local crate while being certain that we don't accidentally try to access them from extern crates.
cc https://github.com/rust-lang/rust/pull/94963#issuecomment-1082924289
Implement a lint to warn about unused macro rules
This implements a new lint to warn about unused macro rules (arms/matchers), similar to the `unused_macros` lint added by #41907 that warns about entire macros.
```rust
macro_rules! unused_empty {
(hello) => { println!("Hello, world!") };
() => { println!("empty") }; //~ ERROR: 1st rule of macro `unused_empty` is never used
}
fn main() {
unused_empty!(hello);
}
```
Builds upon #96149 and #96156.
Fixes#73576
Begin fixing all the broken doctests in `compiler/`
Begins to fix#95994.
All of them pass now but 24 of them I've marked with `ignore HELP (<explanation>)` (asking for help) as I'm unsure how to get them to work / if we should leave them as they are.
There are also a few that I marked `ignore` that could maybe be made to work but seem less important.
Each `ignore` has a rough "reason" for ignoring after it parentheses, with
- `(pseudo-rust)` meaning "mostly rust-like but contains foreign syntax"
- `(illustrative)` a somewhat catchall for either a fragment of rust that doesn't stand on its own (like a lone type), or abbreviated rust with ellipses and undeclared types that would get too cluttered if made compile-worthy.
- `(not-rust)` stuff that isn't rust but benefits from the syntax highlighting, like MIR.
- `(internal)` uses `rustc_*` code which would be difficult to make work with the testing setup.
Those reason notes are a bit inconsistently applied and messy though. If that's important I can go through them again and try a more principled approach. When I run `rg '```ignore \(' .` on the repo, there look to be lots of different conventions other people have used for this sort of thing. I could try unifying them all if that would be helpful.
I'm not sure if there was a better existing way to do this but I wrote my own script to help me run all the doctests and wade through the output. If that would be useful to anyone else, I put it here: https://github.com/Elliot-Roberts/rust_doctest_fixing_tool
Refactor the WriteBackendMethods and ExtraBackendMethods traits
The new interface is slightly less confusing and is easier to implement for non-LLVM backends.
Only crate root def-ids don't have a parent, and in majority of cases the argument of `DefIdTree::parent` cannot be a crate root.
So we now panic by default in `parent` and introduce a new non-panicing function `opt_parent` for cases where the argument can be a crate root.
Same applies to `local_parent`/`opt_local_parent`.
not need `Option` for `dbg_scope`
This PR fixes a few FIXME about not using `Option` in `dbg_scope` field of `DebugScope`, during `create_function_debug_context` func in codegen parts.
Added a `BitSet<SourceScope>` parameter to `make_mir_scope` to indicate whether the `DebugScope` has been instantiated.
cc ````@eddyb````
Generate synthetic object file to ensure all exported and used symbols participate in the linking
Fix#50007 and #47384
This is the synthetic object file approach that I described in https://github.com/rust-lang/rust/pull/95363#issuecomment-1079932354, allowing all exported and used symbols to be linked while still allowing them to be GCed.
Related #93791, #95363
r? `@petrochenkov`
cc `@carbotaniuman`
Drop support for legacy PM with LLVM 15
LLVM 15 already removes some of the legacy PM APIs we're using. This patch forces use of NewPM with LLVM 15 (with `-Z new-llvm-pass-manager=no` throwing a warning) and stubs out various FFI methods with a report_fatal_error on LLVM 15.
For LLVMPassManagerBuilderPopulateLTOPassManager() I went with adding our own wrapper, as the alternative would be to muck about with weak symbols, which seems to be non-trivial as far as cross-platform support is concerned (std has `weak!` for this purpose, but only as an internal utility.)
Fixes#96072.
Fixes#96362.
asm: Add a kreg0 register class on x86 which includes k0
Previously we only exposed a kreg register class which excludes the k0
register since it can't be used in many instructions. However k0 is a
valid register and we need to have a way of marking it as clobbered for
clobber_abi.
Fixes#94977
Previously we only exposed a kreg register class which excludes the k0
register since it can't be used in many instructions. However k0 is a
valid register and we need to have a way of marking it as clobbered for
clobber_abi.
Fixes#94977
Allow self-profiler to only record potentially costly arguments when argument recording is turned on
As discussed [on zulip](https://rust-lang.zulipchat.com/#narrow/stream/247081-t-compiler.2Fperformance/topic/Identifying.20proc-macro.20slowdowns/near/277304909) with `@wesleywiser,` I'd like to record proc-macro expansions in the self-profiler, with some detailed data (per-expansion spans for example, to follow #95473).
At the same time, I'd also like to avoid doing expensive things when tracking a generic activity's arguments, if they were not specifically opted into the event filter mask, to allow the self-profiler to be used in hotter contexts.
This PR tries to offer:
- a way to ensure a closure to record arguments will only be called in that situation, so that potentially costly arguments can still be recorded when needed. With the additional requirement that, if possible, it would offer a way to record non-owned data without adding many `generic_activity_with_arg_{...}`-style methods. This lead to the `generic_activity_with_arg_recorder` single entry-point, and the closure parameter would offer the new methods, able to be executed in a context where costly argument could be created without disturbing the profiled piece of code.
- some facilities/patterns allowing to record more rustc specific data in this situation, without making `rustc_data_structures` where the self-profiler is defined, depend on other rustc crates (causing circular dependencies): in particular, spans. They are quite tricky to turn into strings (if the default `Debug` impl output does not match the context one needs them for), and since I'd also like to avoid the allocation there when arg recording is turned off today, that has turned into another flexibility requirement for the API in this PR (separating the span-specific recording into an extension trait). **edit**: I've removed this from the PR so that it's easier to review, and opened https://github.com/rust-lang/rust/pull/95739.
- allow for extensibility in the future: other ways to record arguments, or additional data attached to them could be added in the future (e.g. recording the argument's name as well as its data).
Some areas where I'd love feedback:
- the API and names: the `EventArgRecorder` and its method for example. As well as the verbosity that comes from the increased flexibility.
- if I should convert the existing `generic_activity_with_arg{s}` to just forward to `generic_activity_with_arg_recorder` + `recorder.record_arg` (or remove them altogether ? Probably not): I've used the new API in the simple case I could find of allocating for an arg that may not be recorded, and the rest don't seem costly.
- [x] whether this API should panic if no arguments were recorded by the user-provided closure (like this PR currently does: it seems like an error to use an API dedicated to record arguments but not call the methods to then do so) or if this should just record a generic activity without arguments ?
- whether the `record_arg` function should be `#[inline(always)]`, like the `generic_activity_*` functions ?
As mentioned, r? `@wesleywiser` following our recent discussion.
Rollup of 9 pull requests
Successful merges:
- #93969 (Only add codegen backend to dep info if -Zbinary-dep-depinfo is used)
- #94605 (Add missing links in platform support docs)
- #95372 (make unaligned_references lint deny-by-default)
- #95859 (Improve diagnostics for unterminated nested block comment)
- #95961 (implement SIMD gather/scatter via vector getelementptr)
- #96004 (Consider lifetimes when comparing types for equality in MIR validator)
- #96050 (Remove some now-dead code that was only relevant before deaggregation.)
- #96070 ([test] Add test cases for untested functions for BTreeMap)
- #96099 (MaybeUninit array cleanup)
Failed merges:
r? `@ghost`
`@rustbot` modify labels: rollup
implement SIMD gather/scatter via vector getelementptr
Fixes https://github.com/rust-lang/portable-simd/issues/271
However, I don't *really* know what I am doing here... Cc ``@workingjubilee`` ``@calebzulawski``
I didn't do anything for cranelift -- ``@bjorn3`` not sure if it's okay for that backend to temporarily break. I'm happy to cherry-pick a patch that adds cranelift support. :)
We may sometimes emit an `invoke` instead of a `call` for inline
assembly during the MIR -> LLVM IR lowering. But we failed to update
the IR builder's current basic block before writing the results to the
outputs. This would result in invalid IR because the basic block would
end in a `store` instruction, which isn't a valid terminator.
Since September, the toolchain has not been generating reliable DWARF
information for static variables when LTO is on. This has affected
projects in the embedded space where the use of LTO is typical. In our
case, it has kept us from bumping past the 2021-09-22 nightly toolchain
lest our debugger break. This has been a pretty dramatic regression for
people using debuggers and static variables. See #90357 for more info
and a repro case.
This commit is a mechanical revert of
d5de680e20 from PR #89041, which caused
the issue. (Note on that PR that the commit's author has requested it be
reverted.)
I have locally verified that this fixes#90357 by restoring the
functionality of both the repro case I posted on that bug, and debugger
behavior on real programs. There do not appear to be test cases for this
in the toolchain; if I've missed them, point me at 'em and I'll update
them.
Skip needless bitset for debuginfo
Found this while digging around looking at the inlining logic.
Seemed obvious enough so I decided to try to take care of it.
Is this what you had in mind, `@eddyb?`
Before this fix, the debuginfo for the fields was generated from the
struct defintion of Box<T>, but (at least at the moment) the compiler
pretends that Box<T> is just a (fat) pointer, so the fields need to be
`pointer` and `vtable` instead of `__0: Unique<T>` and `__1: Allocator`.
This is meant as a temporary mitigation until we can make sure that
simply treating Box as a regular struct in debuginfo does not cause too
much breakage in the ecosystem.
Fold aarch64 feature +fp into +neon
Arm's FEAT_FP and Feat_AdvSIMD describe the same thing on AArch64:
The Neon unit, which handles both floating point and SIMD instructions.
Moreover, a configuration for AArch64 must include both or neither.
Arm says "entirely proprietary" toolchains may omit floating point:
https://developer.arm.com/documentation/102374/0101/Data-processing---floating-point
In the Programmer's Guide for Armv8-A, Arm says AArch64 can have
both FP and Neon or neither in custom implementations:
https://developer.arm.com/documentation/den0024/a/AArch64-Floating-point-and-NEON
In "Bare metal boot code for Armv8-A", enabling Neon and FP
is just disabling the same trap flag:
https://developer.arm.com/documentation/dai0527/a
In an unlikely future where "Neon and FP" become unrelated,
we can add "[+-]fp" as its own feature flag.
Until then, we can simplify programming with Rust on AArch64 by
folding both into "[+-]neon", which is valid as it supersets both.
"[+-]neon" is retained for niche uses such as firmware, kernels,
"I just hate floats", and so on.
I am... pretty sure no one is relying on this.
An argument could be made that, as we are not an "entirely proprietary" toolchain, we should not support AArch64 without floats at all. I think that's a bit excessive. However, I want to recognize the intent: programming for AArch64 should be simplified where possible. For x86-64, programmers regularly set up illegal feature configurations because it's hard to understand them, see https://github.com/rust-lang/rust/issues/89586. And per the above notes, plus the discussion in https://github.com/rust-lang/rust/issues/86941, there should be no real use cases for leaving these features split: the two should in fact always go together.
- Fixesrust-lang/rust#95002.
- Fixesrust-lang/rust#95064.
- Fixesrust-lang/rust#95122.
Arm's FEAT_FP and Feat_AdvSIMD describe the same thing on AArch64:
The Neon unit, which handles both floating point and SIMD instructions.
Moreover, a configuration for AArch64 must include both or neither.
Arm says "entirely proprietary" toolchains may omit floating point:
https://developer.arm.com/documentation/102374/0101/Data-processing---floating-point
In the Programmer's Guide for Armv8-A, Arm says AArch64 can have
both FP and Neon or neither in custom implementations:
https://developer.arm.com/documentation/den0024/a/AArch64-Floating-point-and-NEON
In "Bare metal boot code for Armv8-A", enabling Neon and FP
is just disabling the same trap flag:
https://developer.arm.com/documentation/dai0527/a
In an unlikely future where "Neon and FP" become unrelated,
we can add "[+-]fp" as its own feature flag.
Until then, we can simplify programming with Rust on AArch64 by
folding both into "[+-]neon", which is valid as it supersets both.
"[+-]neon" is retained for niche uses such as firmware, kernels,
"I just hate floats", and so on.
Implement -Z oom=panic
This PR removes the `#[rustc_allocator_nounwind]` attribute on `alloc_error_handler` which allows it to unwind with a panic instead of always aborting. This is then used to implement `-Z oom=panic` as per RFC 2116 (tracking issue #43596).
Perf and binary size tests show negligible impact.
debuginfo: Refactor debuginfo generation for types
This PR implements the refactoring of the `rustc_codegen_llvm::debuginfo::metadata` module as described in MCP https://github.com/rust-lang/compiler-team/issues/482.
In particular it
- changes names to use `di_node` instead of `metadata`
- uniformly names all functions that build new debuginfo nodes `build_xyz_di_node`
- renames `CrateDebugContext` to `CodegenUnitDebugContext` (which is more accurate)
- removes outdated parts from `compiler/rustc_codegen_llvm/src/debuginfo/doc.md`
- moves `TypeMap` and functions that work directly work with it to a new `type_map` module
- moves enum related builder functions to a new `enums` module
- splits enum debuginfo building for the native and cpp-like cases, since they are mostly separate
- uses `SmallVec` instead of `Vec` in many places
- removes the old infrastructure for dealing with recursion cycles (`create_and_register_recursive_type_forward_declaration()`, `RecursiveTypeDescription`, `set_members_of_composite_type()`, `MemberDescription`, `MemberDescriptionFactory`, `prepare_xyz_metadata()`, etc)
- adds `type_map::build_type_with_children()` as a replacement for dealing with recursion cycles
- adds many (doc-)comments explaining what's going on
- changes cpp-like naming for C-Style enums so they don't get a `enum$<...>` name (because the NatVis visualizer does not apply to them)
- fixes detection of what is a C-style enum because some enums where classified as C-style even though they have fields
- changes cpp-like naming for generator enums so that NatVis works for them
- changes the position of discriminant debuginfo node so it is consistently nested inside the top-level union instead of, sometimes, next to it
The following could be done in subsequent PRs:
- add caching for `closure_saved_names_of_captured_variables`
- add caching for `generator_layout_and_saved_local_names`
- fix inconsistent handling of what is considered a C-style enum wrt to debuginfo
- rename `metadata` module to `types`
- move common generator fields to front instead of appending them
This PR is based on https://github.com/rust-lang/rust/pull/93644 which is not merged yet.
Right now, the changes are all done in one big commit. They could be split into smaller commits but hopefully the list of changes above makes it tractable to review them as a single commit too.
For now: r? `@ghost` (let's see if this affects compile times)
This commit
- changes names to use di_node instead of metadata
- uniformly names all functions that build new debuginfo nodes build_xyz_di_node
- renames CrateDebugContext to CodegenUnitDebugContext (which is more accurate)
- moves TypeMap and functions that work directly work with it to a new type_map module
- moves and reimplements enum related builder functions to a new enums module
- splits enum debuginfo building for the native and cpp-like cases, since they are mostly separate
- uses SmallVec instead of Vec in many places
- removes the old infrastructure for dealing with recursion cycles (create_and_register_recursive_type_forward_declaration(), RecursiveTypeDescription, set_members_of_composite_type(), MemberDescription, MemberDescriptionFactory, prepare_xyz_metadata(), etc)
- adds type_map::build_type_with_children() as a replacement for dealing with recursion cycles
- adds many (doc-)comments explaining what's going on
- changes cpp-like naming for C-Style enums so they don't get a enum$<...> name (because the NatVis visualizer does not apply to them)
- fixes detection of what is a C-style enum because some enums where classified as C-style even though they have fields
- changes the position of discriminant debuginfo node so it is consistently nested inside the top-level union instead of, sometimes, next to it
Improve `AdtDef` interning.
This commit makes `AdtDef` use `Interned`. Much of the commit is tedious
changes to introduce getter functions. The interesting changes are in
`compiler/rustc_middle/src/ty/adt.rs`.
r? `@fee1-dead`
This commit makes `AdtDef` use `Interned`. Much the commit is tedious
changes to introduce getter functions. The interesting changes are in
`compiler/rustc_middle/src/ty/adt.rs`.
Only emit pointer-like metadata for `Box<T, A>` when `A` is ZST
Basically copy the change in #94043, but for debuginfo.
r? ``@michaelwoerister``
Fixes#94725
Clarify `Layout` interning.
`Layout` is another type that is sometimes interned, sometimes not, and
we always use references to refer to it so we can't take any advantage
of the uniqueness properties for hashing or equality checks.
This commit renames `Layout` as `LayoutS`, and then introduces a new
`Layout` that is a newtype around an `Interned<LayoutS>`. It also
interns more layouts than before. Previously layouts within layouts
(via the `variants` field) were never interned, but now they are. Hence
the lifetime on the new `Layout` type.
Unlike other interned types, these ones are in `rustc_target` instead of
`rustc_middle`. This reflects the existing structure of the code, which
does layout-specific stuff in `rustc_target` while `TyAndLayout` is
generic over the `Ty`, allowing the type-specific stuff to occur in
`rustc_middle`.
The commit also adds a `HashStable` impl for `Interned`, which was
needed. It hashes the contents, unlike the `Hash` impl which hashes the
pointer.
r? `@fee1-dead`
`Layout` is another type that is sometimes interned, sometimes not, and
we always use references to refer to it so we can't take any advantage
of the uniqueness properties for hashing or equality checks.
This commit renames `Layout` as `LayoutS`, and then introduces a new
`Layout` that is a newtype around an `Interned<LayoutS>`. It also
interns more layouts than before. Previously layouts within layouts
(via the `variants` field) were never interned, but now they are. Hence
the lifetime on the new `Layout` type.
Unlike other interned types, these ones are in `rustc_target` instead of
`rustc_middle`. This reflects the existing structure of the code, which
does layout-specific stuff in `rustc_target` while `TyAndLayout` is
generic over the `Ty`, allowing the type-specific stuff to occur in
`rustc_middle`.
The commit also adds a `HashStable` impl for `Interned`, which was
needed. It hashes the contents, unlike the `Hash` impl which hashes the
pointer.
Introduce `ConstAllocation`.
Currently some `Allocation`s are interned, some are not, and it's very
hard to tell at a use point which is which.
This commit introduces `ConstAllocation` for the known-interned ones,
which makes the division much clearer. `ConstAllocation::inner()` is
used to get the underlying `Allocation`.
In some places it's natural to use an `Allocation`, in some it's natural
to use a `ConstAllocation`, and in some places there's no clear choice.
I've tried to make things look as nice as possible, while generally
favouring `ConstAllocation`, which is the type that embodies more
information. This does require quite a few calls to `inner()`.
The commit also tweaks how `PartialOrd` works for `Interned`. The
previous code was too clever by half, building on `T: Ord` to make the
code shorter. That caused problems with deriving `PartialOrd` and `Ord`
for `ConstAllocation`, so I changed it to build on `T: PartialOrd`,
which is slightly more verbose but much more standard and avoided the
problems.
r? `@fee1-dead`
Currently some `Allocation`s are interned, some are not, and it's very
hard to tell at a use point which is which.
This commit introduces `ConstAllocation` for the known-interned ones,
which makes the division much clearer. `ConstAllocation::inner()` is
used to get the underlying `Allocation`.
In some places it's natural to use an `Allocation`, in some it's natural
to use a `ConstAllocation`, and in some places there's no clear choice.
I've tried to make things look as nice as possible, while generally
favouring `ConstAllocation`, which is the type that embodies more
information. This does require quite a few calls to `inner()`.
The commit also tweaks how `PartialOrd` works for `Interned`. The
previous code was too clever by half, building on `T: Ord` to make the
code shorter. That caused problems with deriving `PartialOrd` and `Ord`
for `ConstAllocation`, so I changed it to build on `T: PartialOrd`,
which is slightly more verbose but much more standard and avoided the
problems.
This ensures that information about target features configured with
`-C target-feature=...` or detected with `-C target-cpu=native` is
retained for subsequent consumers of LLVM bitcode.
This is crucial for linker plugin LTO, since this information is not
conveyed to the plugin otherwise.
Add !align metadata on loads of &/&mut/Box
Note that this refers to the alignment of what the loaded value points
to, _not_ the alignment of the loaded value itself.
r? `@ghost` (blocked on #94158)
Remove LLVM attribute removal
This was necessary before, because `declare_raw_fn` would always apply
the default optimization attributes to every declared function.
Then `attributes::from_fn_attrs` would have to remove the default
attributes in the case of, e.g. `#[optimize(speed)]` in a `-Os` build.
(see [`src/test/codegen/optimize-attr-1.rs`](03a8cc7df1/src/test/codegen/optimize-attr-1.rs (L33)))
However, every relevant callsite of `declare_raw_fn` (i.e. where we
actually generate code for the function, and not e.g. a call to an
intrinsic, where optimization attributes don't [?] matter)
calls `from_fn_attrs`, so we can remove the attribute setting
from `declare_raw_fn`, and rely on `from_fn_attrs` to apply the correct
attributes all at once.
r? `@ghost` (blocked on #94221)
`@rustbot` label S-blocked
Direct users towards using Rust target feature names in CLI
This PR consists of a couple of changes on how we handle target features.
In particular there is a bug-fix wherein we avoid passing through features that aren't prefixed by `+` or `-` to LLVM. These appear to be causing LLVM to assert, which is pretty poor a behaviour (and also makes it pretty clear we expect feature names to be prefixed).
The other commit, I anticipate to be somewhat more controversial is outputting a warning when users specify a LLVM-specific, or otherwise unknown, feature name on the CLI. In those situations we request users to either replace it with a known Rust feature name (e.g. `bmi` -> `bmi1`) or file a feature request. I've a couple motivations for this: first of all, if users are specifying these features on the command line, I'm pretty confident there is also a need for these features to be usable via `#[cfg(target_feature)]` machinery. And second, we're growing a fair number of backends recently and having ability to provide some sort of unified-ish interface in this place seems pretty useful to me.
Sponsored by: standard.ai
If they are trying to use features rustc doesn't yet know about,
request a feature request.
Additionally, also warn against using feature names without leading `+`
or `-` signs.
This was necessary before, because `declare_raw_fn` would always apply
the default optimization attributes to every declared function,
and then `attributes::from_fn_attrs` would have to remove the default
attributes in the case of, e.g. `#[optimize(speed)]` in a `-Os` build.
However, every relevant callsite of `declare_raw_fn` (i.e. where we
actually generate code for the function, and not e.g. a call to an
intrinsic, where optimization attributes don't [?] matter)
calls `from_fn_attrs`, so we can simply remove the attribute setting
from `declare_raw_fn`, and rely on `from_fn_attrs` to apply the correct
attributes all at once.
LLVM really dislikes this and will assert, saying something along the
lines of:
```
rustc: llvm/lib/MC/MCSubtargetInfo.cpp:60: void ApplyFeatureFlag(
llvm::FeatureBitset&, llvm::StringRef, llvm::ArrayRef<llvm::SubtargetFeatureKV>
): Assertion
`SubtargetFeatures::hasFlag(Feature) && "Feature flags should start with '+' or '-'"`
failed.
```
No branch protection metadata unless enabled
Even if we emit metadata disabling branch protection, this metadata may
conflict with other modules (e.g. during LTO) that have different branch
protection metadata set.
This is an unstable flag and feature, so ideally the flag not being
specified should act as if the feature wasn't implemented in the first
place.
Additionally this PR also ensures we emit an error if
`-Zbranch-protection` is set on targets other than the supported
aarch64. For now the error is being output from codegen, but ideally it
should be moved to earlier in the pipeline before stabilization.
debuginfo: Simplify TypeMap used during LLVM debuginfo generation.
This PR simplifies the TypeMap that is used in `rustc_codegen_llvm::debuginfo::metadata`. It was unnecessarily complicated because it was originally implemented when types were not yet normalized before codegen. So it did it's own normalization and kept track of multiple unnormalized types being mapped to a single unique id.
This PR is based on https://github.com/rust-lang/rust/pull/93503, which is not merged yet.
The PR also removes the arena used for allocating string ids and instead uses `InlinableString` from the [inlinable_string](https://crates.io/crates/inlinable_string) crate. That might not be the best choice, since that crate does not seem to be very actively maintained. The [flexible-string](https://crates.io/crates/flexible-string) crate would be an alternative.
r? `@ghost`
Use undef for (some) partially-uninit constants
There needs to be some limit to avoid perf regressions on large arrays
with undef in each element (see comment in the code).
Fixes: #84565
Original PR: #83698
Depends on LLVM 14: #93577
properly handle fat pointers to uninhabitable types
Calculate the pointee metadata size by using `tcx.struct_tail_erasing_lifetimes` instead of duplicating the logic in `fat_pointer_kind`. Open to alternatively suggestions on how to fix this.
Fixes#94149
r? ````@michaelwoerister```` since you touched this code last, I think!
Partially move cg_ssa towards using a single builder
Not all codegen backends can handle hopping between blocks well. For example Cranelift requires blocks to be terminated before switching to building a new block. Rust-gpu requires a `RefCell` to allow hopping between blocks and cg_gcc currently has a buggy implementation of hopping between blocks. This PR reduces the amount of cases where cg_ssa switches between blocks before they are finished and mostly fixes the block hopping in cg_gcc. (~~only `scalar_to_backend` doesn't handle it correctly yet in cg_gcc~~ fixed that one.)
`@antoyo` please review the cg_gcc changes.
Change `char` type in debuginfo to DW_ATE_UTF
Rust previously encoded the `char` type as DW_ATE_unsigned_char. The more appropriate encoding is `DW_ATE_UTF`.
Clang also uses the DW_ATE_UTF for `char32_t` in C++.
This fixes the display of the `char` type in the Windows debuggers. Without this change, the variable did not show in the locals window.
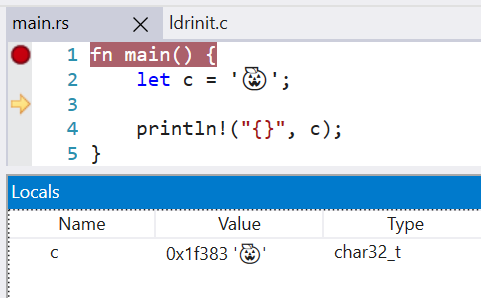
LLDB 13 is also able to display the char value, when before it failed with `need to add support for DW_TAG_base_type 'char' encoded with DW_ATE = 0x8, bit_size = 32`
r? `@wesleywiser`
Rust previously encoded the `char` type as DW_ATE_unsigned_char. The more
appropriate encoding is DW_ATE_UTF.
Clang uses this same debug encoding for char32_t.
This fixes the display of `char` types in Windows debuggers as well as LLDB.
The previous implementation was written before types were properly
normalized for code generation and had to assume a more complicated
relationship between types and their debuginfo -- generating separate
identifiers for debuginfo nodes that were based on normalized types.
Since types are now already normalized, we can use them as identifiers
for debuginfo nodes.
Improve `unused_unsafe` lint
I’m going to add some motivation and explanation below, particularly pointing the changes in behavior from this PR.
_Edit:_ Looking for existing issues, looks like this PR fixes#88260.
_Edit2:_ Now also contains code that closes#90776.
Main motivation: Fixes some issues with the current behavior. This PR is
more-or-less completely re-implementing the unused_unsafe lint; it’s also only
done in the MIR-version of the lint, the set of tests for the `-Zthir-unsafeck`
version no longer succeeds (and is thus disabled, see `lint-unused-unsafe.rs`).
On current nightly,
```rs
unsafe fn unsf() {}
fn inner_ignored() {
unsafe {
#[allow(unused_unsafe)]
unsafe {
unsf()
}
}
}
```
doesn’t create any warnings. This situation is not unrealistic to come by, the
inner `unsafe` block could e.g. come from a macro. Actually, this PR even
includes removal of one unused `unsafe` in the standard library that was missed
in a similar situation. (The inner `unsafe` coming from an external macro hides
the warning, too.)
The reason behind this problem is how the check currently works:
* While generating MIR, it already skips nested unsafe blocks (i.e. unsafe
nested in other unsafe) so that the inner one is always the one considered
unused
* To differentiate the cases of no unsafe operations inside the `unsafe` vs.
a surrounding `unsafe` block, there’s some ad-hoc magic walking up the HIR to
look for surrounding used `unsafe` blocks.
There’s a lot of problems with this approach besides the one presented above.
E.g. the MIR-building uses checks for `unsafe_op_in_unsafe_fn` lint to decide
early whether or not `unsafe` blocks in an `unsafe fn` are redundant and ought
to be removed.
```rs
unsafe fn granular_disallow_op_in_unsafe_fn() {
unsafe {
#[deny(unsafe_op_in_unsafe_fn)]
{
unsf();
}
}
}
```
```
error: call to unsafe function is unsafe and requires unsafe block (error E0133)
--> src/main.rs:13:13
|
13 | unsf();
| ^^^^^^ call to unsafe function
|
note: the lint level is defined here
--> src/main.rs:11:16
|
11 | #[deny(unsafe_op_in_unsafe_fn)]
| ^^^^^^^^^^^^^^^^^^^^^^
= note: consult the function's documentation for information on how to avoid undefined behavior
warning: unnecessary `unsafe` block
--> src/main.rs:10:5
|
9 | unsafe fn granular_disallow_op_in_unsafe_fn() {
| --------------------------------------------- because it's nested under this `unsafe` fn
10 | unsafe {
| ^^^^^^ unnecessary `unsafe` block
|
= note: `#[warn(unused_unsafe)]` on by default
```
Here, the intermediate `unsafe` was ignored, even though it contains a unsafe
operation that is not allowed to happen in an `unsafe fn` without an additional `unsafe` block.
Also closures were problematic and the workaround/algorithms used on current
nightly didn’t work properly. (I skipped trying to fully understand what it was
supposed to do, because this PR uses a completely different approach.)
```rs
fn nested() {
unsafe {
unsafe { unsf() }
}
}
```
```
warning: unnecessary `unsafe` block
--> src/main.rs:10:9
|
9 | unsafe {
| ------ because it's nested under this `unsafe` block
10 | unsafe { unsf() }
| ^^^^^^ unnecessary `unsafe` block
|
= note: `#[warn(unused_unsafe)]` on by default
```
vs
```rs
fn nested() {
let _ = || unsafe {
let _ = || unsafe { unsf() };
};
}
```
```
warning: unnecessary `unsafe` block
--> src/main.rs:9:16
|
9 | let _ = || unsafe {
| ^^^^^^ unnecessary `unsafe` block
|
= note: `#[warn(unused_unsafe)]` on by default
warning: unnecessary `unsafe` block
--> src/main.rs:10:20
|
10 | let _ = || unsafe { unsf() };
| ^^^^^^ unnecessary `unsafe` block
```
*note that this warning kind-of suggests that **both** unsafe blocks are redundant*
--------------------------------------------------------------------------------
I also dislike the fact that it always suggests keeping the outermost `unsafe`.
E.g. for
```rs
fn granularity() {
unsafe {
unsafe { unsf() }
unsafe { unsf() }
unsafe { unsf() }
}
}
```
I prefer if `rustc` suggests removing the more-course outer-level `unsafe`
instead of the fine-grained inner `unsafe` blocks, which it currently does on nightly:
```
warning: unnecessary `unsafe` block
--> src/main.rs:10:9
|
9 | unsafe {
| ------ because it's nested under this `unsafe` block
10 | unsafe { unsf() }
| ^^^^^^ unnecessary `unsafe` block
|
= note: `#[warn(unused_unsafe)]` on by default
warning: unnecessary `unsafe` block
--> src/main.rs:11:9
|
9 | unsafe {
| ------ because it's nested under this `unsafe` block
10 | unsafe { unsf() }
11 | unsafe { unsf() }
| ^^^^^^ unnecessary `unsafe` block
warning: unnecessary `unsafe` block
--> src/main.rs:12:9
|
9 | unsafe {
| ------ because it's nested under this `unsafe` block
...
12 | unsafe { unsf() }
| ^^^^^^ unnecessary `unsafe` block
```
--------------------------------------------------------------------------------
Needless to say, this PR addresses all these points. For context, as far as my
understanding goes, the main advantage of skipping inner unsafe blocks was that
a test case like
```rs
fn top_level_used() {
unsafe {
unsf();
unsafe { unsf() }
unsafe { unsf() }
unsafe { unsf() }
}
}
```
should generate some warning because there’s redundant nested `unsafe`, however
every single `unsafe` block _does_ contain some statement that uses it. Of course
this PR doesn’t aim change the warnings on this kind of code example, because
the current behavior, warning on all the inner `unsafe` blocks, makes sense in this case.
As mentioned, during MIR building all the unsafe blocks *are* kept now, and usage
is attributed to them. The way to still generate a warning like
```
warning: unnecessary `unsafe` block
--> src/main.rs:11:9
|
9 | unsafe {
| ------ because it's nested under this `unsafe` block
10 | unsf();
11 | unsafe { unsf() }
| ^^^^^^ unnecessary `unsafe` block
|
= note: `#[warn(unused_unsafe)]` on by default
warning: unnecessary `unsafe` block
--> src/main.rs:12:9
|
9 | unsafe {
| ------ because it's nested under this `unsafe` block
...
12 | unsafe { unsf() }
| ^^^^^^ unnecessary `unsafe` block
warning: unnecessary `unsafe` block
--> src/main.rs:13:9
|
9 | unsafe {
| ------ because it's nested under this `unsafe` block
...
13 | unsafe { unsf() }
| ^^^^^^ unnecessary `unsafe` block
```
in this case is by emitting a `unused_unsafe` warning for all of the `unsafe`
blocks that are _within a **used** unsafe block_.
The previous code had a little HIR traversal already anyways to collect a set of
all the unsafe blocks (in order to afterwards determine which ones are unused
afterwards). This PR uses such a traversal to do additional things including logic
like _always_ warn for an `unsafe` block that’s inside of another **used**
unsafe block. The traversal is expanded to include nested closures in the same go,
this simplifies a lot of things.
The whole logic around `unsafe_op_in_unsafe_fn` is a little complicated, there’s
some test cases of corner-cases in this PR. (The implementation involves
differentiating between whether a used unsafe block was used exclusively by
operations where `allow(unsafe_op_in_unsafe_fn)` was active.) The main goal was
to make sure that code should compile successfully if all the `unused_unsafe`-warnings
are addressed _simultaneously_ (by removing the respective `unsafe` blocks)
no matter how complicated the patterns of `unsafe_op_in_unsafe_fn` being
disallowed and allowed throughout the function are.
--------------------------------------------------------------------------------
One noteworthy design decision I took here: An `unsafe` block
with `allow(unused_unsafe)` **is considered used** for the purposes of
linting about redundant contained unsafe blocks. So while
```rs
fn granularity() {
unsafe { //~ ERROR: unnecessary `unsafe` block
unsafe { unsf() }
unsafe { unsf() }
unsafe { unsf() }
}
}
```
warns for the outer `unsafe` block,
```rs
fn top_level_ignored() {
#[allow(unused_unsafe)]
unsafe {
#[deny(unused_unsafe)]
{
unsafe { unsf() } //~ ERROR: unnecessary `unsafe` block
unsafe { unsf() } //~ ERROR: unnecessary `unsafe` block
unsafe { unsf() } //~ ERROR: unnecessary `unsafe` block
}
}
}
```
warns on the inner ones.
Move ty::print methods to Drop-based scope guards
Primary goal is reducing codegen of the TLS access for each closure, which shaves ~3 seconds of bootstrap time over rustc as a whole.
Adopt let else in more places
Continuation of #89933, #91018, #91481, #93046, #93590, #94011.
I have extended my clippy lint to also recognize tuple passing and match statements. The diff caused by fixing it is way above 1 thousand lines. Thus, I split it up into multiple pull requests to make reviewing easier. This is the biggest of these PRs and handles the changes outside of rustdoc, rustc_typeck, rustc_const_eval, rustc_trait_selection, which were handled in PRs #94139, #94142, #94143, #94144.
Even if we emit metadata disabling branch protection, this metadata may
conflict with other modules (e.g. during LTO) that have different branch
protection metadata set.
This is an unstable flag and feature, so ideally the flag not being
specified should act as if the feature wasn't implemented in the first
place.
Additionally this PR also ensures we emit an error if
`-Zbranch-protection` is set on targets other than the supported
aarch64. For now the error is being output from codegen, but ideally it
should be moved to earlier in the pipeline before stabilization.
Rollup of 10 pull requests
Successful merges:
- #89892 (Suggest `impl Trait` return type when incorrectly using a generic return type)
- #91675 (Add MemTagSanitizer Support)
- #92806 (Add more information to `impl Trait` error)
- #93497 (Pass `--test` flag through rustdoc to rustc so `#[test]` functions can be scraped)
- #93814 (mips64-openwrt-linux-musl: correct soft-foat)
- #93847 (kmc-solid: Use the filesystem thread-safety wrapper)
- #93877 (asm: Allow the use of r8-r14 as clobbers on Thumb1)
- #93892 (Only mark projection as ambiguous if GAT substs are constrained)
- #93915 (Implement --check-cfg option (RFC 3013), take 2)
- #93953 (Add the `known-bug` test directive, use it, and do some cleanup)
Failed merges:
r? `@ghost`
`@rustbot` modify labels: rollup
Add MemTagSanitizer Support
Add support for the LLVM [MemTagSanitizer](https://llvm.org/docs/MemTagSanitizer.html).
On hardware which supports it (see caveats below), the MemTagSanitizer can catch bugs similar to AddressSanitizer and HardwareAddressSanitizer, but with lower overhead.
On a tag mismatch, a SIGSEGV is signaled with code SEGV_MTESERR / SEGV_MTEAERR.
# Usage
`-Zsanitizer=memtag -C target-feature="+mte"`
# Comments/Caveats
* MemTagSanitizer is only supported on AArch64 targets with hardware support
* Requires `-C target-feature="+mte"`
* LLVM MemTagSanitizer currently only performs stack tagging.
# TODO
* Tests
* Example
This should provide a small perf improvement for debug builds,
and should more than cancel out the regression from adding noundef,
which was only significant in debug builds.
Fix ICE when using Box<T, A> with pointer sized A
Fixes#78459
Note that using `Box<T, A>` with a more than pointer sized `A` or using a pointer sized `A` with a Box of a DST will produce a different ICE (#92054) which is not fixed by this PR.
{kind=link}