The general theme of this is to make parser a better independent
library.
The specific thing we do here is replacing callback based TreeSink with
a data structure. That is, rather than calling user-provided tree
construction methods, the parser now spits out a very bare-bones tree,
effectively a log of a DFS traversal.
This makes the parser usable without any *specifc* tree sink, and allows
us to, eg, move tests into this crate.
Now, it's also true that this is a distinction without a difference, as
the old and the new interface are equivalent in expressiveness. Still,
this new thing seems somewhat simpler. But yeah, I admit I don't have a
suuper strong motivation here, just a hunch that this is better.
The general problem we are dealing with here is this:
```
macro_rules! thrice {
($e:expr) => { $e * 3}
}
fn main() {
let x = thrice!(1 + 2);
}
```
we really want this to print 9 rather than 7.
The way rustc solves this is rather ad-hoc. In rustc, token trees are
allowed to include whole AST fragments, so 1+2 is passed through macro
expansion as a single unit. This is a significant violation of token
tree model.
In rust-analyzer, we intended to handle this in a more elegant way,
using token trees with "invisible" delimiters. The idea was is that we
introduce a new kind of parenthesis, "left $"/"right $", and let the
parser intelligently handle this.
The idea was inspired by the relevant comment in the proc_macro crate:
https://doc.rust-lang.org/stable/proc_macro/enum.Delimiter.html#variant.None
> An implicit delimiter, that may, for example, appear around tokens
> coming from a “macro variable” $var. It is important to preserve
> operator priorities in cases like $var * 3 where $var is 1 + 2.
> Implicit delimiters might not survive roundtrip of a token stream
> through a string.
Now that we are older and wiser, we conclude that the idea doesn't work.
_First_, the comment in the proc-macro crate is wishful thinking. Rustc
currently completely ignores none delimiters. It solves the (1 + 2) * 3
problem by having magical token trees which can't be duplicated:
* https://rust-lang.zulipchat.com/#narrow/stream/185405-t-compiler.2Frust-analyzer/topic/TIL.20that.20token.20streams.20are.20magic
* https://rust-lang.zulipchat.com/#narrow/stream/131828-t-compiler/topic/Handling.20of.20Delimiter.3A.3ANone.20by.20the.20parser
_Second_, it's not like our implementation in rust-analyzer works. We
special-case expressions (as opposed to treating all kinds of $var
captures the same) and we don't know how parser error recovery should
work with these dollar-parenthesis.
So, in this PR we simplify the whole thing away by not pretending that
we are doing something proper and instead just explicitly special-casing
expressions by wrapping them into real `()`.
In the future, to maintain bug-parity with `rustc` what we are going to
do is probably adding an explicit `CAPTURED_EXPR` *token* which we can
explicitly account for in the parser.
If/when rustc starts handling delimiter=none properly, we'll port that
logic as well, in addition to special handling.
I don't like our macro tests -- they are brittle and don't inspire
confidence. I think the reason for that is that we try to unit-test
them, but that is at odds with reality, where macro expansion
fundamentally depends on name resolution.
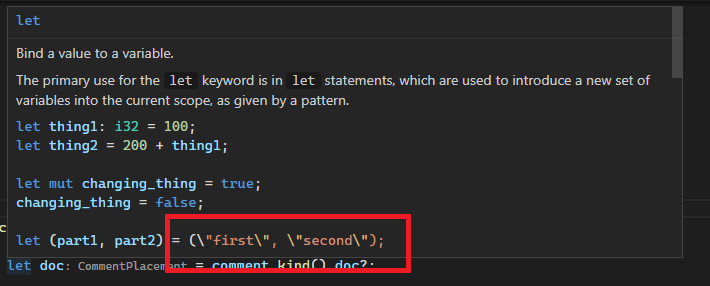
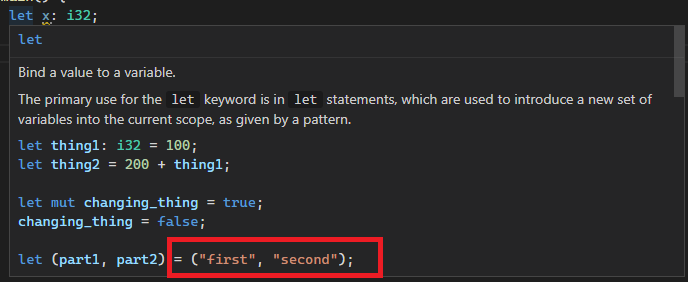
Consider these expples
{ 92 }
async { 92 }
'a: { 92 }
#[a] { 92 }
Previously the tree for them were
BLOCK_EXPR
{ ... }
EFFECT_EXPR
async
BLOCK_EXPR
{ ... }
EFFECT_EXPR
'a:
BLOCK_EXPR
{ ... }
BLOCK_EXPR
#[a]
{ ... }
As you see, it gets progressively worse :) The last two items are
especially odd. The last one even violates the balanced curleys
invariant we have (#10357) The new approach is to say that the stuff in
`{}` is stmt_list, and the block is stmt_list + optional modifiers
BLOCK_EXPR
STMT_LIST
{ ... }
BLOCK_EXPR
async
STMT_LIST
{ ... }
BLOCK_EXPR
'a:
STMT_LIST
{ ... }
BLOCK_EXPR
#[a]
STMT_LIST
{ ... }
FragmentKind played two roles:
* entry point to the parser
* syntactic category of a macro call
These are different use-cases, and warrant different types. For example,
macro can't expand to visibility, but we have such fragment today.
This PR introduces `ExpandsTo` enum to separate this two use-cases.
I suspect we might further split `FragmentKind` into `$x:specifier` enum
specific to MBE, and a general parser entry point, but that's for
another PR!
9970: feat: Implement attribute input token mapping, fix attribute item token mapping r=Veykril a=Veykril
The token mapping for items with attributes got overwritten partially by the attributes non-item input, since attributes have two different inputs, the item and the direct input both.
This PR gives attributes a second TokenMap for its direct input. We now shift all normal input IDs by the item input maximum(we maybe wanna swap this see below) similar to what we do for macro-rules/def. For mapping down we then have to figure out whether we are inside the direct attribute input or its item input to pick the appropriate mapping which can be done with some token range comparisons.
Fixes https://github.com/rust-analyzer/rust-analyzer/issues/9867
Co-authored-by: Lukas Wirth <lukastw97@gmail.com>
We generally avoid "syntax only" helper wrappers, which don't do much:
they make code easier to write, but harder to read. They also make
investigations harder, as "find_usages" needs to be invoked both for the
wrapped and unwrapped APIs
9260: tree-wide: make rustdoc links spiky so they are clickable r=matklad a=lf-
Rustdoc was complaining about these while I was running with --document-private-items and I figure they should be fixed.
Co-authored-by: Jade <software@lfcode.ca>
8560: Escape characters in doc comments in macros correctly r=jonas-schievink a=ChayimFriedman2
Previously they were escaped twice, both by `.escape_default()` and the debug view of strings (`{:?}`). This leads to things like newlines or tabs in documentation comments being `\\n`, but we unescape literals only once, ending up with `\n`.
This was hard to spot because CMark unescaped them (at least for `'` and `"`), but it did not do so in code blocks.
This also was the root cause of #7781. This issue was solved by using `.escape_debug()` instead of `.escape_default()`, but the real issue remained.
We can bring the `.escape_default()` back by now, however I didn't do it because it is probably slower than `.escape_debug()` (more work to do), and also in order to change the code the least.
Example (the keyword and primitive docs are `include!()`d at https://doc.rust-lang.org/src/std/lib.rs.html#570-578, and thus originate from macro):
Before:
After:
Co-authored-by: Chayim Refael Friedman <chayimfr@gmail.com>
Previously they were escaped twice, both by `.escape_default()` and the debug view of strings (`{:?}`). This leads to things like newlines or tabs in documentation comments being `\\n`, but we unescape literals only once, ending up with `\n`.
This was hard to spot because CMark unescaped them (at least for `'` and `"`), but it did not do so in code blocks.
This also was the root cause of #7781. This issue was solved by using `.escape_debug()` instead of `.escape_default()`, but the real issue remained.
We can bring the `.escape_default()` back by now, however I didn't do it because it is probably slower than `.escape_debug()` (more work to do), and also in order to change the code the least.
use vec![] instead of Vec::new() + push()
avoid redundant clones
use chars instead of &str for single char patterns in ends_with() and starts_with()
allocate some Vecs with capacity to avoid unneccessary resizing
7994: Speed up mbe matching in heavy recursive cases r=edwin0cheng a=edwin0cheng
In some cases (e.g. #4186), mbe matching is very slow due to a lot of copy and allocation for bindings, this PR try to solve this problem by introduce a semi "link-list" approach for bindings building.
I used this [test case](https://github.com/weiznich/minimal_example_for_rust_81262) (for `features(32-column-tables)`) to run following command to benchmark:
```
time rust-analyzer analysis-stats --load-output-dirs ./
```
Before this PR : 2 mins
After this PR: 3 seconds.
However, for 64-column-tables cases, we still need 4 mins to complete.
I will try to investigate in the following weeks.
bors r+
Co-authored-by: Edwin Cheng <edwin0cheng@gmail.com>
{kind=link}
{kind=link}
{kind=link}