Under some conditions, the toolchain will produce a sequence of linker
arguments that result in a NEEDED list that puts libc before libgcc_s;
e.g.,
[0] NEEDED 0x2046ba libc.so.1
[1] NEEDED 0x204723 libm.so.2
[2] NEEDED 0x204736 libsocket.so.1
[3] NEEDED 0x20478b libumem.so.1
[4] NEEDED 0x204763 libgcc_s.so.1
Both libc and libgcc_s provide an unwinder implementation, but libgcc_s
provides some extra symbols upon which Rust directly depends. If libc
is first in the NEEDED list we will find some of those symbols in libc
but others in libgcc_s, resulting in undefined behaviour as the two
implementations do not use compatible interior data structures.
This solution is not perfect, but is the simplest way to produce correct
binaries on illumos for now.
Fix#84467 linker_args with --target=sparcv9-sun-solaris
Trying to cross-compile for sparcv9-sun-solaris
getting a error message for -zignore
Introduced when -z -ignore was seperated here
22d0ab0
No formatting done
Reproduce
``` bash
rustup target add sparcv9-sun-solaris
cargo new --bin hello && cd hello && cargo run --target=sparcv9-sun-solaris
```
config.toml
[target.sparcv9-sun-solaris]
linker = "gcc"
This commit implements both the native linking modifiers infrastructure
as well as an initial attempt at the individual modifiers from the RFC.
It also introduces a feature flag for the general syntax along with
individual feature flags for each modifier.
Moved -z ignore to add_as_needed
Trying to cross-compile for sparcv9-sun-solaris
getting an error message for -zignore
Introduced when -z -ignore was separated here
22d0ab0
No formatting done
Reproduce
``` bash
rustup target add sparcv9-sun-solaris
cargo new --bin hello && cd hello && cargo run --target=sparcv9-sun-solaris
```
config.toml
[target.sparcv9-sun-solaris]
linker = "gcc"
Implement RFC 1260 with feature_name `imported_main`.
This is the second extraction part of #84062 plus additional adjustments.
This (mostly) implements RFC 1260.
However there's still one test case failure in the extern crate case. Maybe `LocalDefId` doesn't work here? I'm not sure.
cc https://github.com/rust-lang/rust/issues/28937
r? `@petrochenkov`
Update grab bag
This PR slides a bunch of crate versions forward until suddenly a bunch of deps fall out of the tree!
In doing so this mostly picks up a version bump in the `redox_users` crate which makes most of the features default to optional.
crossbeam-utils 0.7 => 0.8.3 (where applicable)
https://github.com/crossbeam-rs/crossbeam/blob/master/crossbeam-utils/CHANGELOG.md
directories 3.0.1 => 3.0.2
ignore 0.4.16 => 0.4.17
tempfile 3.0.5 => tempfile 3.2
Removes constant_time_eq from deps exceptions
Removes arrayref from deps exceptions
And also removes:
- blake2b_simd
- const_fn (the package, not the feature)
- constant_time_eq
- redox_users 0.3.4
- rust-argon2
rustc: Use LLVM's new saturating float-to-int intrinsics
This commit updates rustc, with an applicable LLVM version, to use
LLVM's new `llvm.fpto{u,s}i.sat.*.*` intrinsics to implement saturating
floating-point-to-int conversions. This results in a little bit tighter
codegen for x86/x86_64, but the main purpose of this is to prepare for
upcoming changes to the WebAssembly backend in LLVM where wasm's
saturating float-to-int instructions will now be implemented with these
intrinsics.
This change allows simplifying a good deal of surrounding code, namely
removing a lot of wasm-specific behavior. WebAssembly no longer has any
special-casing of saturating arithmetic instructions and the need for
`fptoint_may_trap` is gone and all handling code for that is now
removed. This means that the only wasm-specific logic is in the
`fpto{s,u}i` instructions which only get used for "out of bounds is
undefined behavior". This does mean that for the WebAssembly target
specifically the Rust compiler will no longer be 100% compatible with
pre-LLVM 12 versions, but it seems like that's unlikely to be relied on
by too many folks.
Note that this change does immediately regress the codegen of saturating
float-to-int casts on WebAssembly due to the specialization of the LLVM
intrinsic not being present in our LLVM fork just yet. I'll be following
up with an LLVM update to pull in those patches, but affects a few other
SIMD things in flight for WebAssembly so I wanted to separate this change.
Eventually the entire `cast_float_to_int` function can be removed when
LLVM 12 is the minimum version, but that will require sinking the
complexity of it into other backends such as Cranelfit.
This commit updates rustc, with an applicable LLVM version, to use
LLVM's new `llvm.fpto{u,s}i.sat.*.*` intrinsics to implement saturating
floating-point-to-int conversions. This results in a little bit tighter
codegen for x86/x86_64, but the main purpose of this is to prepare for
upcoming changes to the WebAssembly backend in LLVM where wasm's
saturating float-to-int instructions will now be implemented with these
intrinsics.
This change allows simplifying a good deal of surrounding code, namely
removing a lot of wasm-specific behavior. WebAssembly no longer has any
special-casing of saturating arithmetic instructions and the need for
`fptoint_may_trap` is gone and all handling code for that is now
removed. This means that the only wasm-specific logic is in the
`fpto{s,u}i` instructions which only get used for "out of bounds is
undefined behavior". This does mean that for the WebAssembly target
specifically the Rust compiler will no longer be 100% compatible with
pre-LLVM 12 versions, but it seems like that's unlikely to be relied on
by too many folks.
Note that this change does immediately regress the codegen of saturating
float-to-int casts on WebAssembly due to the specialization of the LLVM
intrinsic not being present in our LLVM fork just yet. I'll be following
up with an LLVM update to pull in those patches, but affects a few other
SIMD things in flight for WebAssembly so I wanted to separate this change.
Eventually the entire `cast_float_to_int` function can be removed when
LLVM 12 is the minimum version, but that will require sinking the
complexity of it into other backends such as Cranelfit.
The issue was that the resulting debuginfo was too complex for LLVM to
translate into CodeView records correctly. As a result, it simply
ignored the debuginfo which meant Windows debuggers could not display
any closed over variables when stepping inside a closure.
This fixes that by spilling additional variables to the stack so that
the resulting debuginfo is simple (just `*my_variable.dbg.spill`) and
LLVM can generate the correct CV records.
Use AnonConst for asm! constants
This replaces the old system which used explicit promotion. See #83169 for more background.
The syntax for `const` operands is still the same as before: `const <expr>`.
Fixes#83169
Because the implementation is heavily based on inline consts, we suffer from the same issues:
- We lose the ability to use expressions derived from generics. See the deleted tests in `src/test/ui/asm/const.rs`.
- We are hitting the same ICEs as inline consts, for example #78174. It is unlikely that we will be able to stabilize this before inline consts are stabilized.
Use FromStr trait for number option parsing
Replace `parse_uint` with generic `parse_number` based on `FromStr`.
Use it for parsing inlining threshold to avoid casting later.
Add an Mmap wrapper to rustc_data_structures
This wrapper implements StableAddress and falls back to directly reading the file on wasm32.
Taken from #83640, which I will close due to the perf regression.
Translate counters from Rust 1-based to LLVM 0-based counter ids
A colleague contacted me and asked why Rust's counters start at 1, when
Clangs appear to start at 0. There is a reason why Rust's internal
counters start at 1 (see the docs), and I tried to keep them consistent
when codegenned to LLVM's coverage mapping format. LLVM should be
tolerant of missing counters, but as my colleague pointed out,
`llvm-cov` will silently fail to generate a coverage report for a
function based on LLVM's assumption that the counters are 0-based.
See:
https://github.com/llvm/llvm-project/blob/main/llvm/lib/ProfileData/Coverage/CoverageMapping.cpp#L170
Apparently, if, for example, a function has no branches, it would have
exactly 1 counter. `CounterValues.size()` would be 1, and (with the
1-based index), the counter ID would be 1. This would fail the check
and abort reporting coverage for the function.
It turns out that by correcting for this during coverage map generation,
by subtracting 1 from the Rust Counter ID (both when generating the
counter increment intrinsic call, and when adding counters to the map),
some uncovered functions (including in tests) now appear covered! This
corrects the coverage for a few tests!
r? `@tmandry`
FYI: `@wesleywiser`
A colleague contacted me and asked why Rust's counters start at 1, when
Clangs appear to start at 0. There is a reason why Rust's internal
counters start at 1 (see the docs), and I tried to keep them consistent
when codegenned to LLVM's coverage mapping format. LLVM should be
tolerant of missing counters, but as my colleague pointed out,
`llvm-cov` will silently fail to generate a coverage report for a
function based on LLVM's assumption that the counters are 0-based.
See:
https://github.com/llvm/llvm-project/blob/main/llvm/lib/ProfileData/Coverage/CoverageMapping.cpp#L170
Apparently, if, for example, a function has no branches, it would have
exactly 1 counter. `CounterValues.size()` would be 1, and (with the
1-based index), the counter ID would be 1. This would fail the check
and abort reporting coverage for the function.
It turns out that by correcting for this during coverage map generation,
by subtracting 1 from the Rust Counter ID (both when generating the
counter increment intrinsic call, and when adding counters to the map),
some uncovered functions (including in tests) now appear covered! This
corrects the coverage for a few tests!
linker: Use `--as-needed` by default when linker supports it
Do it in a centralized way in `link.rs` instead of individual target specs.
Majority of relevant target specs were already passing it.
coverage bug fixes and optimization support
Adjusted LLVM codegen for code compiled with `-Zinstrument-coverage` to
address multiple, somewhat related issues.
Fixed a significant flaw in prior coverage solution: Every counter
generated a new counter variable, but there should have only been one
counter variable per function. This appears to have bloated .profraw
files significantly. (For a small program, it increased the size by
about 40%. I have not tested large programs, but there is anecdotal
evidence that profraw files were way too large. This is a good fix,
regardless, but hopefully it also addresses related issues.
Fixes: #82144
Invalid LLVM coverage data produced when compiled with -C opt-level=1
Existing tests now work up to at least `opt-level=3`. This required a
detailed analysis of the LLVM IR, comparisons with Clang C++ LLVM IR
when compiled with coverage, and a lot of trial and error with codegen
adjustments.
The biggest hurdle was figuring out how to continue to support coverage
results for unused functions and generics. Rust's coverage results have
three advantages over Clang's coverage results:
1. Rust's coverage map does not include any overlapping code regions,
making coverage counting unambiguous.
2. Rust generates coverage results (showing zero counts) for all unused
functions, including generics. (Clang does not generate coverage for
uninstantiated template functions.)
3. Rust's unused functions produce minimal stubbed functions in LLVM IR,
sufficient for including in the coverage results; while Clang must
generate the complete LLVM IR for each unused function, even though
it will never be called.
This PR removes the previous hack of attempting to inject coverage into
some other existing function instance, and generates dedicated instances
for each unused function. This change, and a few other adjustments
(similar to what is required for `-C link-dead-code`, but with lower
impact), makes it possible to support LLVM optimizations.
Fixes: #79651
Coverage report: "Unexecuted instantiation:..." for a generic function
from multiple crates
Fixed by removing the aforementioned hack. Some "Unexecuted
instantiation" notices are unavoidable, as explained in the
`used_crate.rs` test, but `-Zinstrument-coverage` has new options to
back off support for either unused generics, or all unused functions,
which avoids the notice, at the cost of less coverage of unused
functions.
Fixes: #82875
Invalid LLVM coverage data produced with crate brotli_decompressor
Fixed by disabling the LLVM function attribute that forces inlining, if
`-Z instrument-coverage` is enabled. This attribute is applied to
Rust functions with `#[inline(always)], and in some cases, the forced
inlining breaks coverage instrumentation and reports.
FYI: `@wesleywiser`
r? `@tmandry`
Adjusted LLVM codegen for code compiled with `-Zinstrument-coverage` to
address multiple, somewhat related issues.
Fixed a significant flaw in prior coverage solution: Every counter
generated a new counter variable, but there should have only been one
counter variable per function. This appears to have bloated .profraw
files significantly. (For a small program, it increased the size by
about 40%. I have not tested large programs, but there is anecdotal
evidence that profraw files were way too large. This is a good fix,
regardless, but hopefully it also addresses related issues.
Fixes: #82144
Invalid LLVM coverage data produced when compiled with -C opt-level=1
Existing tests now work up to at least `opt-level=3`. This required a
detailed analysis of the LLVM IR, comparisons with Clang C++ LLVM IR
when compiled with coverage, and a lot of trial and error with codegen
adjustments.
The biggest hurdle was figuring out how to continue to support coverage
results for unused functions and generics. Rust's coverage results have
three advantages over Clang's coverage results:
1. Rust's coverage map does not include any overlapping code regions,
making coverage counting unambiguous.
2. Rust generates coverage results (showing zero counts) for all unused
functions, including generics. (Clang does not generate coverage for
uninstantiated template functions.)
3. Rust's unused functions produce minimal stubbed functions in LLVM IR,
sufficient for including in the coverage results; while Clang must
generate the complete LLVM IR for each unused function, even though
it will never be called.
This PR removes the previous hack of attempting to inject coverage into
some other existing function instance, and generates dedicated instances
for each unused function. This change, and a few other adjustments
(similar to what is required for `-C link-dead-code`, but with lower
impact), makes it possible to support LLVM optimizations.
Fixes: #79651
Coverage report: "Unexecuted instantiation:..." for a generic function
from multiple crates
Fixed by removing the aforementioned hack. Some "Unexecuted
instantiation" notices are unavoidable, as explained in the
`used_crate.rs` test, but `-Zinstrument-coverage` has new options to
back off support for either unused generics, or all unused functions,
which avoids the notice, at the cost of less coverage of unused
functions.
Fixes: #82875
Invalid LLVM coverage data produced with crate brotli_decompressor
Fixed by disabling the LLVM function attribute that forces inlining, if
`-Z instrument-coverage` is enabled. This attribute is applied to
Rust functions with `#[inline(always)], and in some cases, the forced
inlining breaks coverage instrumentation and reports.
Make source-based code coverage compatible with MIR inlining
When codegenning code coverage use the instance that coverage data was
originally generated for, to ensure basic level of compatibility with
MIR inlining.
Fixes#83061
Implement (but don't use) valtree and refactor in preparation of use
This PR does not cause any functional change. It refactors various things that are needed to make valtrees possible. This refactoring got big enough that I decided I'd want it reviewed as a PR instead of trying to make one huge PR with all the changes.
cc `@rust-lang/wg-const-eval` on the following commits:
* 2027184 implement valtree
* eeecea9 fallible Scalar -> ScalarInt
* 042f663 ScalarInt convenience methods
cc `@eddyb` on ef04a6d
cc `@rust-lang/wg-mir-opt` for cf1700c (`mir::Constant` can now represent either a `ConstValue` or a `ty::Const`, and it is totally possible to have two different representations for the same value)
When codegenning code coverage use the instance that coverage data was
originally generated for, to ensure basic level of compatibility with
MIR inlining.
Remove the -Zinsert-sideeffect
This removes all of the code we had in place to work-around LLVM's
handling of forward progress. From this removal excluded is a workaround
where we'd insert a `sideeffect` into clearly infinite loops such as
`loop {}`. This code remains conditionally effective when the LLVM
version is earlier than 12.0, which fixed the forward progress related
miscompilations at their root.
This removes all of the code we had in place to work-around LLVM's
handling of forward progress. From this removal excluded is a workaround
where we'd insert a `sideeffect` into clearly infinite loops such as
`loop {}`. This code remains conditionally effective when the LLVM
version is earlier than 12.0, which fixed the forward progress related
miscompilations at their root.
Store HIR attributes in a side table
Same idea as #72015 but for attributes.
The objective is to reduce incr-comp invalidations due to modified attributes.
Notably, those due to modified doc comments.
Implementation:
- collect attributes during AST->HIR lowering, in `LocalDefId -> ItemLocalId -> &[Attributes]` nested tables;
- access the attributes through a `hir_owner_attrs` query;
- local refactorings to use this access;
- remove `attrs` from HIR data structures one-by-one.
Change in behaviour:
- the HIR visitor traverses all attributes at once instead of parent-by-parent;
- attribute arrays are sometimes duplicated: for statements and variant constructors;
- as a consequence, attributes are marked as used after unused-attribute lint emission to avoid duplicate lints.
~~Current bug: the lint level is not correctly applied in `std::backtrace_rs`, triggering an unused attribute warning on `#![no_std]`. I welcome suggestions.~~
This updates all places where match branches check on StatementKind or UseContext.
This doesn't properly implement them, but adds TODOs where they are, and also adds some best
guesses to what they should be in some cases.
I'm still not totally sure if this is the right way to implement the memcpy, but that portion
compiles correctly now. Now to fix the compile errors everywhere else :).
Implement NOOP_METHOD_CALL lint
Implements the beginnings of https://github.com/rust-lang/lang-team/issues/67 - a lint for detecting noop method calls (e.g, calling `<&T as Clone>::clone()` when `T: !Clone`).
This PR does not fully realize the vision and has a few limitations that need to be addressed either before merging or in subsequent PRs:
* [ ] No UFCS support
* [ ] The warning message is pretty plain
* [ ] Doesn't work for `ToOwned`
The implementation uses [`Instance::resolve`](https://doc.rust-lang.org/nightly/nightly-rustc/rustc_middle/ty/instance/struct.Instance.html#method.resolve) which is normally later in the compiler. It seems that there are some invariants that this function relies on that we try our best to respect. For instance, it expects substitutions to have happened, which haven't yet performed, but we check first for `needs_subst` to ensure we're dealing with a monomorphic type.
Thank you to ```@davidtwco,``` ```@Aaron1011,``` and ```@wesleywiser``` for helping me at various points through out this PR ❤️.
Set codegen thread names
Set names on threads spawned during codegen. Various debugging and profiling tools can take advantage of this to show a more useful identifier for threads.
For example, gdb will show thread names in `info threads`:
```
(gdb) info threads
Id Target Id Frame
1 Thread 0x7fffefa7ec40 (LWP 2905) "rustc" __pthread_clockjoin_ex (threadid=140737214134016, thread_return=0x0, clockid=<optimized out>, abstime=<optimized out>, block=<optimized out>)
at pthread_join_common.c:145
2 Thread 0x7fffefa7b700 (LWP 2957) "rustc" 0x00007ffff125eaa8 in llvm::X86_MC::initLLVMToSEHAndCVRegMapping(llvm::MCRegisterInfo*) ()
from /home/wesley/.rustup/toolchains/stage1/lib/librustc_driver-f866439e29074957.so
3 Thread 0x7fffeef0f700 (LWP 3116) "rustc" futex_wait_cancelable (private=0, expected=0, futex_word=0x7fffe8602ac8) at ../sysdeps/nptl/futex-internal.h:183
* 4 Thread 0x7fffeed0e700 (LWP 3123) "rustc" rustc_codegen_ssa:🔙:write::spawn_work (cgcx=..., work=...) at /home/wesley/code/rust/rust/compiler/rustc_codegen_ssa/src/back/write.rs:1573
6 Thread 0x7fffe113b700 (LWP 3150) "opt foof.7rcbfp" 0x00007ffff2940e62 in llvm::CallGraph::populateCallGraphNode(llvm::CallGraphNode*) ()
from /home/wesley/.rustup/toolchains/stage1/lib/librustc_driver-f866439e29074957.so
8 Thread 0x7fffe0d39700 (LWP 3158) "opt foof.7rcbfp" 0x00007fffefe8998e in malloc_consolidate (av=av@entry=0x7ffe2c000020) at malloc.c:4492
9 Thread 0x7fffe0f3a700 (LWP 3162) "opt foof.7rcbfp" 0x00007fffefef27c4 in __libc_open64 (file=0x7fffe0f38608 "foof.foof.7rcbfp3g-cgu.6.rcgu.o", oflag=524865) at ../sysdeps/unix/sysv/linux/open64.c:48
(gdb)
```
and Windows Performance Analyzer will also show this information when profiling:
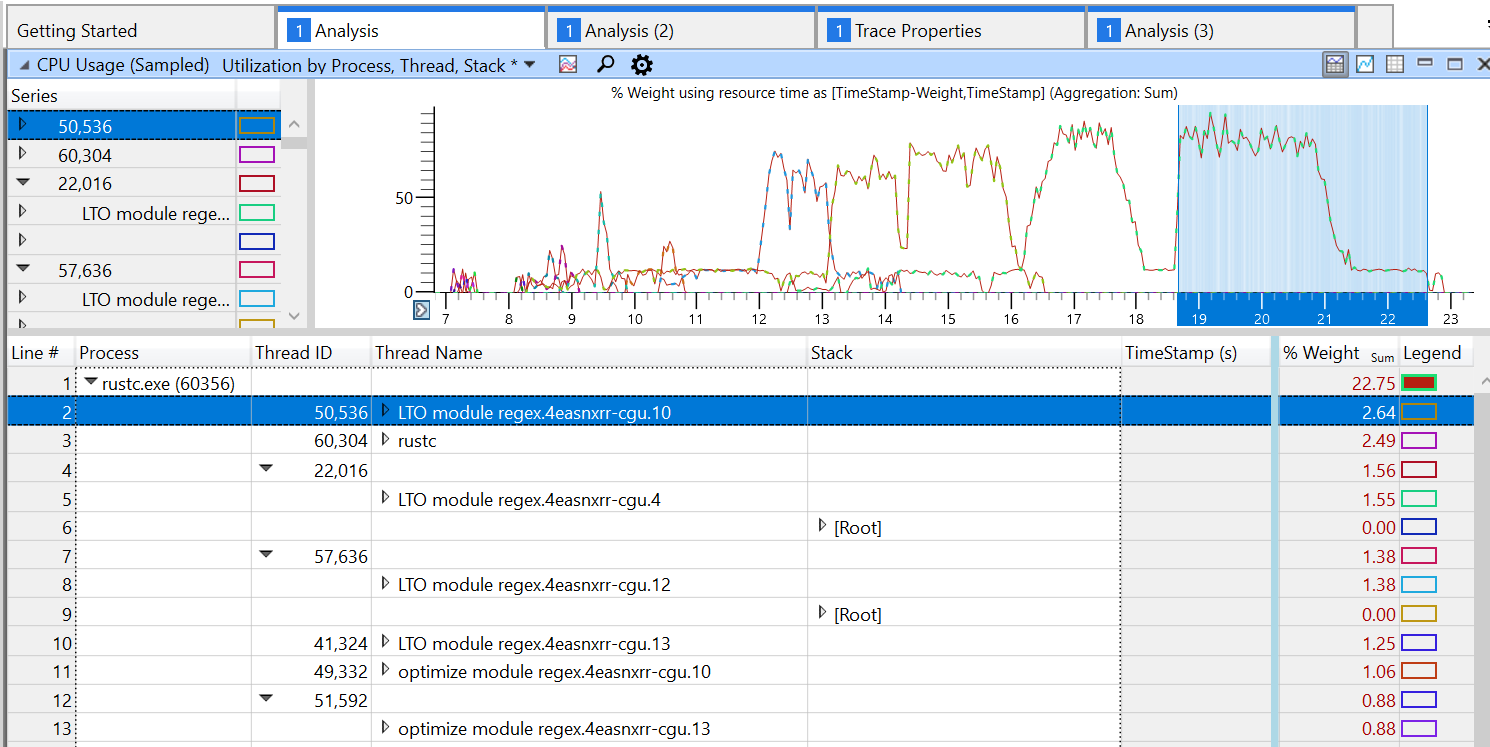
rustc_codegen_ssa: tune codegen according to available concurrency
This change tunes ahead-of-time codegening according to the amount of
concurrency available, rather than according to the number of CPUs on
the system. This can lower memory usage by reducing the number of
compiled LLVM modules in memory at once, particularly across several
rustc instances.
Previously, each rustc instance would assume that it should codegen
ahead of time to meet the demand of number-of-CPUs workers. But often, a
rustc instance doesn't have nearly that much concurrency available to
it, because the concurrency availability is split, via the jobserver,
across all active rustc instances spawned by the driving cargo process,
and is further limited by the `-j` flag argument. Therefore, each rustc
might have had several times the number of LLVM modules in memory than
it really needed to meet demand. If the modules were large, the effect
on memory usage would be noticeable.
With this change, the required amount of ahead-of-time codegen scales up
with the actual number of workers running within a rustc instance. Note
that the number of workers running can be less than the actual
concurrency available to a rustc instance. However, if more concurrency
is actually available, workers are spun up quickly as job tokens are
acquired, and the ahead-of-time codegen scales up quickly as well.
Set path of the compile unit to the source directory
As part of the effort to implement split dwarf debug info, we ended up
setting the compile unit location to the output directory rather than
the source directory. Furthermore, it seems like we failed to remap the
prefixes for this as well!
The desired behaviour is to instead set the `DW_AT_GNU_dwo_name` to a
path relative to compiler's working directory. This still allows
debuggers to find the split dwarf files, while not changing the
behaviour of the code that is compiling with regular debug info, and not
changing the compiler's behaviour with regards to reproducibility.
Fixes#82074
cc `@alexcrichton` `@davidtwco`
remove redundant option/result wrapping of return values
If a function always returns `Ok(something)`, we can return `something` directly and remove the corresponding error handling in the callers.
clippy::unnecessary_wraps
Add new `rustc` target for Arm64 machines that can target the iphonesimulator
This PR lands a new target (`aarch64-apple-ios-sim`) that targets arm64 iphone simulator, previously unreachable from Apple Silicon machines.
resolves#81632
r? `@shepmaster`
Fix debug information for function arguments of type &str or slice.
Issue details:
When lowering MIR to LLVM IR, the compiler decomposes every &str and slice argument into a data pointer and a usize. Then, the original argument is reconstructed from the pointer and the usize arguments in the body of the function that owns it. Since the original argument is declared in the body of a function, it should be marked as a LocalVariable instead of an ArgumentVairable. This confusion causes MSVC debuggers unable to visualize &str and slice arguments correctly. (See https://github.com/rust-lang/rust/issues/81894 for more details).
Fix details:
Making sure that the debug variable for every &str and slice argument is marked as LocalVariable instead of ArgumentVariable in computing_per_local_var_debug_info. This change has been verified on VS Code debugger, VS debugger, WinDbg and LLDB.
Don't fail to remove files if they are missing
In the backend we may want to remove certain temporary files, but in
certain other situations these files might not be produced in the first
place. We don't exactly care about that, and the intent is really that
these files are gone after a certain point in the backend.
Here we unify the backend file removing calls to use `ensure_removed`
which will attempt to delete a file, but will not fail if it does not
exist (anymore).
The tradeoff to this approach is, of course, that we may miss instances
were we are attempting to remove files at wrong paths due to some bug –
compilation would silently succeed but the temporary files would remain
there somewhere.
Only store a LocalDefId in some HIR nodes
Some HIR nodes are guaranteed to be HIR owners: Item, TraitItem, ImplItem, ForeignItem and MacroDef.
As a consequence, we do not need to store the `HirId`'s `local_id`, and we can directly store a `LocalDefId`.
This allows to avoid a bit of the dance with `tcx.hir().local_def_id` and `tcx.hir().local_def_id_to_hir_id` mappings.
This change tunes ahead-of-time codegening according to the amount of
concurrency available, rather than according to the number of CPUs on
the system. This can lower memory usage by reducing the number of
compiled LLVM modules in memory at once, particularly across several
rustc instances.
Previously, each rustc instance would assume that it should codegen
ahead of time to meet the demand of number-of-CPUs workers. But often, a
rustc instance doesn't have nearly that much concurrency available to
it, because the concurrency availability is split, via the jobserver,
across all active rustc instances spawned by the driving cargo process,
and is further limited by the `-j` flag argument. Therefore, each rustc
might have had several times the number of LLVM modules in memory than
it really needed to meet demand. If the modules were large, the effect
on memory usage would be noticeable.
With this change, the required amount of ahead-of-time codegen scales up
with the actual number of workers running within a rustc instance. Note
that the number of workers running can be less than the actual
concurrency available to a rustc instance. However, if more concurrency
is actually available, workers are spun up quickly as job tokens are
acquired, and the ahead-of-time codegen scales up quickly as well.
In the backend we may want to remove certain temporary files, but in
certain other situations these files might not be produced in the first
place. We don't exactly care about that, and the intent is really that
these files are gone after a certain point in the backend.
Here we unify the backend file removing calls to use `ensure_removed`
which will attempt to delete a file, but will not fail if it does not
exist (anymore).
The tradeoff to this approach is, of course, that we may miss instances
were we are attempting to remove files at wrong paths due to some bug –
compilation would silently succeed but the temporary files would remain
there somewhere.
As part of the effort to implement split dwarf debug info, we ended up
setting the compile unit location to the output directory rather than
the source directory. Furthermore, it seems like we failed to remap the
prefixes for this as well!
The desired behaviour is to instead set the `DW_AT_GNU_dwo_name` to a
path relative to compiler's working directory. This still allows
debuggers to find the split dwarf files, while not changing the
behaviour of the code that is compiling with regular debug info, and not
changing the compiler's behaviour with regards to reproducibility.
Fixes#82074
For better throughput during parallel processing by LLVM, we used to sort
CGUs largest to smallest. This would lead to better thread utilization
by, for example, preventing a large CGU from being processed last and
having only one LLVM thread working while the rest remained idle.
However, this strategy would lead to high memory usage, as it meant the
LLVM-IR for all of the largest CGUs would be resident in memory at once.
Instead, we can compromise by ordering CGUs such that the largest and
smallest are first, second largest and smallest are next, etc. If there
are large size variations, this can reduce memory usage significantly.
Indicate both start and end of pass RSS in time-passes output
Previously, only the end of pass RSS was indicated. This could easily
lead one to believe that the change in RSS from one pass to the next was
attributable to the second pass, when in fact it occurred between the
end of the first pass and the start of the second.
Also, improve alignment of columns.
Sample of output:
```
time: 0.739; rss: 607MB -> 637MB item_types_checking
time: 8.429; rss: 637MB -> 775MB item_bodies_checking
time: 11.063; rss: 470MB -> 775MB type_check_crate
time: 0.232; rss: 775MB -> 777MB match_checking
time: 0.139; rss: 777MB -> 779MB liveness_and_intrinsic_checking
time: 0.372; rss: 775MB -> 779MB misc_checking_2
time: 8.188; rss: 779MB -> 1019MB MIR_borrow_checking
time: 0.062; rss: 1019MB -> 1021MB MIR_effect_checking
```
codegen: assume constants cannot fail to evaluate
https://github.com/rust-lang/rust/pull/80579 landed, so we can finally remove this old hack from codegen and instead assume that consts never fail to evaluate. :)
r? `@oli-obk`
Previously, only the end of pass RSS was indicated. This could easily
lead one to believe that the change in RSS from one pass to the next was
attributable to the second pass, when in fact it occurred between the
end of the first pass and the start of the second.
Also, improve alignment of columns.
clean up some const error reporting around promoteds
These are some error reporting simplifications enabled by https://github.com/rust-lang/rust/pull/80579.
Further simplifications are possible but could be blocked on making `const_err` a hard error.
r? ``````@oli-obk``````
Use -target when linking binaries for Mac Catalyst
When running `rustc` with `-target x86_64-apple-ios-macabi`, the linker
eventually gets run with `-arch x86_64`, because the linker back end splits the
LLVM target triple and uses the first token as the target architecture. However,
this does not work for the Mac Catalyst ABI, which is a separate target from
Darwin.
Specifying the full target triple with `-target` allows Mac Catalyst binaries to
link and run.
closes#80202
rustc: Stabilize `-Zrun-dsymutil` as `-Csplit-debuginfo`
This commit adds a new stable codegen option to rustc,
`-Csplit-debuginfo`. The old `-Zrun-dsymutil` flag is deleted and now
subsumed by this stable flag. Additionally `-Zsplit-dwarf` is also
subsumed by this flag but still requires `-Zunstable-options` to
actually activate. The `-Csplit-debuginfo` flag takes one of
three values:
* `off` - This indicates that split-debuginfo from the final artifact is
not desired. This is not supported on Windows and is the default on
Unix platforms except macOS. On macOS this means that `dsymutil` is
not executed.
* `packed` - This means that debuginfo is desired in one location
separate from the main executable. This is the default on Windows
(`*.pdb`) and macOS (`*.dSYM`). On other Unix platforms this subsumes
`-Zsplit-dwarf=single` and produces a `*.dwp` file.
* `unpacked` - This means that debuginfo will be roughly equivalent to
object files, meaning that it's throughout the build directory
rather than in one location (often the fastest for local development).
This is not the default on any platform and is not supported on Windows.
Each target can indicate its own default preference for how debuginfo is
handled. Almost all platforms default to `off` except for Windows and
macOS which default to `packed` for historical reasons.
Some equivalencies for previous unstable flags with the new flags are:
* `-Zrun-dsymutil=yes` -> `-Csplit-debuginfo=packed`
* `-Zrun-dsymutil=no` -> `-Csplit-debuginfo=unpacked`
* `-Zsplit-dwarf=single` -> `-Csplit-debuginfo=packed`
* `-Zsplit-dwarf=split` -> `-Csplit-debuginfo=unpacked`
Note that `-Csplit-debuginfo` still requires `-Zunstable-options` for
non-macOS platforms since split-dwarf support was *just* implemented in
rustc.
There's some more rationale listed on #79361, but the main gist of the
motivation for this commit is that `dsymutil` can take quite a long time
to execute in debug builds and provides little benefit. This means that
incremental compile times appear that much worse on macOS because the
compiler is constantly running `dsymutil` over every single binary it
produces during `cargo build` (even build scripts!). Ideally rustc would
switch to not running `dsymutil` by default, but that's a problem left
to get tackled another day.
Closes#79361
This commit adds a new stable codegen option to rustc,
`-Csplit-debuginfo`. The old `-Zrun-dsymutil` flag is deleted and now
subsumed by this stable flag. Additionally `-Zsplit-dwarf` is also
subsumed by this flag but still requires `-Zunstable-options` to
actually activate. The `-Csplit-debuginfo` flag takes one of
three values:
* `off` - This indicates that split-debuginfo from the final artifact is
not desired. This is not supported on Windows and is the default on
Unix platforms except macOS. On macOS this means that `dsymutil` is
not executed.
* `packed` - This means that debuginfo is desired in one location
separate from the main executable. This is the default on Windows
(`*.pdb`) and macOS (`*.dSYM`). On other Unix platforms this subsumes
`-Zsplit-dwarf=single` and produces a `*.dwp` file.
* `unpacked` - This means that debuginfo will be roughly equivalent to
object files, meaning that it's throughout the build directory
rather than in one location (often the fastest for local development).
This is not the default on any platform and is not supported on Windows.
Each target can indicate its own default preference for how debuginfo is
handled. Almost all platforms default to `off` except for Windows and
macOS which default to `packed` for historical reasons.
Some equivalencies for previous unstable flags with the new flags are:
* `-Zrun-dsymutil=yes` -> `-Csplit-debuginfo=packed`
* `-Zrun-dsymutil=no` -> `-Csplit-debuginfo=unpacked`
* `-Zsplit-dwarf=single` -> `-Csplit-debuginfo=packed`
* `-Zsplit-dwarf=split` -> `-Csplit-debuginfo=unpacked`
Note that `-Csplit-debuginfo` still requires `-Zunstable-options` for
non-macOS platforms since split-dwarf support was *just* implemented in
rustc.
There's some more rationale listed on #79361, but the main gist of the
motivation for this commit is that `dsymutil` can take quite a long time
to execute in debug builds and provides little benefit. This means that
incremental compile times appear that much worse on macOS because the
compiler is constantly running `dsymutil` over every single binary it
produces during `cargo build` (even build scripts!). Ideally rustc would
switch to not running `dsymutil` by default, but that's a problem left
to get tackled another day.
Closes#79361
Refractor a few more types to `rustc_type_ir`
In the continuation of #79169, ~~blocked on that PR~~.
This PR:
- moves `IntVarValue`, `FloatVarValue`, `InferTy` (and friends) and `Variance`
- creates the `IntTy`, `UintTy` and `FloatTy` enums in `rustc_type_ir`, based on their `ast` and `chalk_ir` equilavents, and uses them for types in the rest of the compiler.
~~I will split up that commit to make this easier to review and to have a better commit history.~~
EDIT: done, I split the PR in commits of 200-ish lines each
r? `````@nikomatsakis````` cc `````@jackh726`````
rustc_codegen_ssa: use wall time for codegen_to_LLVM_IR time-passes entry
Use elapsed wall time spent on codegen_to_LLVM_IR for all CGUs as a
whole, rather than the sum for each CGU (the distinction matters for
parallel builds, where some CGUs are processed in parallel).
Use elapsed wall time spent on codegen_to_LLVM_IR for all CGUs as a
whole, rather than the sum for each CGU (the distinction matters for
parallel builds, where some CGUs are processed in parallel).
Fix sysroot option not being honored across rustc
Change link_sanitizer_runtime() to check if the sanitizer library exists in the specified/session sysroot, and if it doesn't exist, use the default sysroot. (See #79253.)
Change link_sanitizer_runtime() to check if the sanitizer library exists
in the specified/session sysroot, and if it doesn't exist, use the
default sysroot.
Optimize DST field access
For
struct X<T: ?Sized>(T)
struct Y<T: ?Sized>(u8, T)
the offset of the unsized field is
0
mem::align_of_val(&self.1)
respectively. This patch changes the expression used to compute these
offsets so that the optimizer can perform this optimization.
Consider
```rust
fn f(x: &X<dyn Any>) -> &dyn Any {
&x.0
}
```
Before:
```asm
test:
movq %rsi, %rdx
movq 16(%rsi), %rax
leaq -1(%rax), %rcx
negq %rax
andq %rcx, %rax
addq %rdi, %rax
retq
```
After:
```asm
test:
movq %rsi, %rdx
movq %rdi, %rax
retq
```
Update and improve `rustc_codegen_{llvm,ssa}` docs
Fixes#75342.
These docs were very out of date and misleading. They even said that
they codegen'd the *AST*!
For some reason, the `rustc_codegen_ssa::base` docs were exactly
identical to the `rustc_codegen_llvm::base` docs. They didn't really
make sense, because they had LLVM-specific information even though
`rustc_codegen_ssa` is supposed to be somewhat generic. So I removed
them as they were misleading.
r? ``@pnkfelix`` maybe?
These docs were very out of date and misleading. They even said that
they codegen'd the *AST*!
For some reason, the `rustc_codegen_ssa::base` docs were exactly
identical to the `rustc_codegen_llvm::base` docs. They didn't really
make sense, because they had LLVM-specific information even though
`rustc_codegen_ssa` is supposed to be somewhat generic. So I removed
them as they were misleading.
{kind=link}