Optimize initialization of arrays using repeat expressions
This PR was inspired by [this thread](https://www.reddit.com/r/rust/comments/6o8ok9/understanding_rust_performances_a_newbie_question/) on Reddit.
It tries to bring array initialization in the same ballpark as `Vec::from_elem()` for unoptimized builds.
For optimized builds this should relieve LLVM of having to figure out the construct we generate is in fact a `memset()`.
To that end this emits `llvm.memset()` when:
* the array is of integer type and all elements are zero (`Vec::from_elem()` also explicitly optimizes for this case)
* the array elements are byte sized
If the array is zero-sized initialization is omitted entirely.
APFloat: Rewrite It In Rust and use it for deterministic floating-point CTFE.
As part of the CTFE initiative, we're forced to find a solution for floating-point operations.
By design, IEEE-754 does not explicitly define everything in a deterministic manner, and there is some variability between platforms, at the very least (e.g. NaN payloads).
If types are to evaluate constant expressions involving type (or in the future, const) generics, that evaluation needs to be *fully deterministic*, even across `rustc` host platforms.
That is, if `[T; T::X]` was used in a cross-compiled library, and the evaluation of `T::X` executed a floating-point operation, that operation has to be reproducible on *any other host*, only knowing `T` and the definition of the `X` associated const (as either AST or HIR).
Failure to uphold those rules allows an associated type (e.g. `<Foo as Iterator>::Item`) to be seen as two (or more) different types, depending on the current host, and such type safety violations typically allow writing of a `transmute` in safe code, given enough generics.
The options considered by @rust-lang/compiler were:
1. Ban floating-point operations in generic const-evaluation contexts
2. Emulate floating-point operations in an uniformly deterministic fashion
The former option may seem appealing at first, but floating-point operations *are allowed today*, so they can't be banned wholesale, a distinction has to be made between the code that already works, and future generic contexts. *Moreover*, every computation that succeeded *has to be cached*, otherwise the generic case can be reproduced without any generics. IMO there are too many ways it can go wrong, and a single violation can be enough for an unsoundness hole.
Not to mention we may end up really wanting floating-point operations *anyway*, in CTFE.
I went with the latter option, and seeing how LLVM *already* has a library for this exact purpose (as it needs to perform optimizations independently of host floating-point capabilities), i.e. `APFloat`, that was what I ended up basing this PR on.
But having been burned by the low reusability of bindings that link to LLVM, and because I would *rather* the floating-point operations to be wrong than not deterministic or not memory-safe (`APFloat` does far more pointer juggling than I'm comfortable with), I decided to RIIR.
This way, we have a guarantee of *no* `unsafe` code, a bit more control over the where native floating-point might accidentally be involved, and non-LLVM backends can share it.
I've also ported all the testcases over, *before* any functionality, to catch any mistakes.
Currently the PR replaces all CTFE operations to go through `apfloat::ieee::{Single,Double}`, keeping only the bits of the `f32` / `f64` memory representation in between operations.
Converting from a string also double-checks that `core::num` and `apfloat` agree on the interpretation of a floating-point number literal, in case either of them has any bugs left around.
r? @nikomatsakis
f? @nagisa @est31
<hr/>
Huge thanks to @edef1c for first demoing usable `APFloat` bindings and to @chandlerc for fielding my questions on IRC about `APFloat` peculiarities (also upstreaming some bugfixes).
Add MIR Validate statement
This adds statements to MIR that express when types are to be validated (following [Types as Contracts](https://internals.rust-lang.org/t/types-as-contracts/5562)). Obviously nothing is stabilized, and in fact a `-Z` flag has to be passed for behavior to even change at all.
This is meant to make experimentation with Types as Contracts in miri possible. The design is definitely not final.
Cc @nikomatsakis @aturon
Thread through the original error when opening archives
This updates the management of opening archives to thread through the original
piece of error information from LLVM over to the end consumer, trans.
Run translation and LLVM in parallel when compiling with multiple CGUs
This is still a work in progress but the bulk of the implementation is done, so I thought it would be good to get it in front of more eyes.
This PR makes the compiler start running LLVM while translation is still in progress, effectively allowing for more parallelism towards the end of the compilation pipeline. It also allows the main thread to switch between either translation or running LLVM, which allows to reduce peak memory usage since not all LLVM module have to be kept in memory until linking. This is especially good for incr. comp. but it works just as well when running with `-Ccodegen-units=N`.
In order to help tuning and debugging the work scheduler, the PR adds the `-Ztrans-time-graph` flag which spits out html files that show how work packages where scheduled:

(red is translation, green is llvm)
One side effect here is that `-Ztime-passes` might show something not quite correct because trans and LLVM are not strictly separated anymore. I plan to have some special handling there that will try to produce useful output.
One open question is how to determine whether the trans-thread should switch to intermediate LLVM processing.
TODO:
- [x] Restore `-Z time-passes` output for LLVM.
- [x] Update documentation, esp. for work package scheduling.
- [x] Tune the scheduling algorithm.
cc @alexcrichton @rust-lang/compiler
Support homogeneous aggregates for hard-float ARM
Hard-float ARM targets use the AAPCS-VFP ABI, which passes and returns
homogeneous float/vector aggregates in the VFP registers.
Fixes#43329.
r? @eddyb
Embed MSVC .natvis files into .pdbs and mangle debuginfo for &str, *T, and [T].
No idea if these changes are reasonable - please feel free to suggest changes/rewrites. And these are some of my first real commits to any rust codebase - *don't* be gentle, and nitpick away, I need to learn! ;)
### Overview
Embedding `.natvis` files into `.pdb`s allows MSVC (and potentially other debuggers) to automatically pick up the visualizers without having to do any additional configuration (other than to perhaps add the relevant .pdb paths to symbol search paths.)
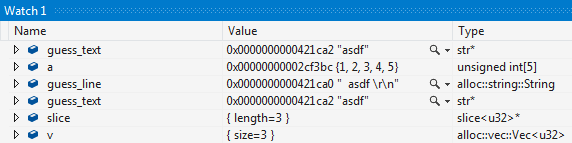
The native debug engine for MSVC parses the type names, making various C++ish assumptions about what they mean and adding various limitations to valid type names. `&str` cannot be matched against a visualizer, but if we emit `str&` instead, it'll be recognized as a reference to a `str`, solving the problem. `[T]` is similarly problematic, but emitting `slice<T>` instead works fine as it looks like a template. I've been unable to get e.g. `slice<u32>&` to match visualizers in VS2015u3, so I've gone with `str*` and `slice<u32>*` instead.
### Possible Issues
* I'm not sure if `slice<T>` is a great mangling for `[T]` or if I should worry about name collisions.
* I'm not sure if `linker.rs` is the right place to be enumerating natvis files.
* I'm not sure if these type name mangling changes should actually be MSVC specific. I recall seeing gdb visualizer tests that might be broken if made more general? I'm hesitant to mess with them without a gdb install. But perhaps I'm just wracking up technical debt.
Should I try `pacman -S mingw-w64-x86_64-gdb` and to make things consistent?
* I haven't touched `const` / `mut` yet, and I'm worried MSVC might trip up on `mut` or their placement.
* I may like terse oneliners too much.
* I don't know if there's broader implications for messing with debug type names here.
* I may have been mistaken about bellow test failures being ignorable / unrelated to this changelist.
### Test Failures on `x86_64-pc-windows-gnu`
```
---- [debuginfo-gdb] debuginfo-gdb\associated-types.rs stdout ----
thread '[debuginfo-gdb] debuginfo-gdb\associated-types.rs' panicked at 'gdb not available but debuginfo gdb debuginfo test requested', src\tools\compiletest\src\runtest.rs:48:16
note: Run with `RUST_BACKTRACE=1` for a backtrace.
[...identical panic causes omitted...]
---- [debuginfo-gdb] debuginfo-gdb\vec.rs stdout ----
thread '[debuginfo-gdb] debuginfo-gdb\vec.rs' panicked at 'gdb not available but debuginfo gdb debuginfo test requested', src\tools\compiletest\src\runtest.rs:48:16
```
### Relevant Issues
* https://github.com/rust-lang/rust/issues/40460 Metaissue for Visual Studio debugging Rust
* https://github.com/rust-lang/rust/issues/36503 Investigate natvis for improved msvc debugging
* https://github.com/PistonDevelopers/VisualRust/issues/160 Debug visualization of Rust data structures
### Pretty Pictures

This elides initialization for zero-sized arrays:
* for zero-sized elements we previously emitted an empty loop
* for arrays with a length of zero we previously emitted a loop with zero
iterations
This emits llvm.memset() instead of a loop over each element when:
* all elements are zero integers
* elements are byte sized
This is mainly for readability of the generated LLVM IR and subsequently
assembly. There is a slight positive performance impact, likely due to
I-cache effects.
Bump master to 1.21.0
This commit bumps the master branch's version to 1.21.0 and also updates the
bootstrap compiler from the freshly minted beta release.
{kind=link}
{kind=link}
{kind=link}