Provide cabi_realloc on wasm32-wasip2 by default
This commit provides a component model intrinsic in the standard library
by default on the `wasm32-wasip2` target. This intrinsic is not
required by the component model itself but is quite common to use, for
example it's needed if a wasm module receives a string or a list.
The intention of this commit is to provide an overridable definition in
the standard library through a weak definition of this function. That
means that downstream crates can provide their own customized and more
specific versions if they'd like, but the standard library's version
should suffice for general-purpose use.
Add `Context::ext`
This change enables `Context` to carry arbitrary extension data via a single `&mut dyn Any` field.
```rust
#![feature(context_ext)]
impl Context {
fn ext(&mut self) -> &mut dyn Any;
}
impl ContextBuilder {
fn ext(self, data: &'a mut dyn Any) -> Self;
fn from(cx: &'a mut Context<'_>) -> Self;
fn waker(self, waker: &'a Waker) -> Self;
}
```
Basic usage:
```rust
struct MyExtensionData {
executor_name: String,
}
let mut ext = MyExtensionData {
executor_name: "foo".to_string(),
};
let mut cx = ContextBuilder::from_waker(&waker).ext(&mut ext).build();
if let Some(ext) = cx.ext().downcast_mut::<MyExtensionData>() {
println!("{}", ext.executor_name);
}
```
Currently, `Context` only carries a `Waker`, but there is interest in having it carry other kinds of data. Examples include [LocalWaker](https://github.com/rust-lang/rust/issues/118959), [a reactor interface](https://github.com/rust-lang/libs-team/issues/347), and [multiple arbitrary values by type](https://docs.rs/context-rs/latest/context_rs/). There is also a general practice in the ecosystem of sharing data between executors and futures via thread-locals or globals that would arguably be better shared via `Context`, if it were possible.
The `ext` field would provide a low friction (to stabilization) solution to enable experimentation. It would enable experimenting with what kinds of data we want to carry as well as with what data structures we may want to use to carry such data.
Dedicated fields for specific kinds of data could still be added directly on `Context` when we have sufficient experience or understanding about the problem they are solving, such as with `LocalWaker`. The `ext` field would be for data for which we don't have such experience or understanding, and that could be graduated to dedicated fields once proven.
Both the provider and consumer of the extension data must be aware of the concrete type behind the `Any`. This means it is not possible for the field to carry an abstract interface. However, the field can carry a concrete type which in turn carries an interface. There are different ways one can imagine an interface-carrying concrete type to work, hence the benefit of being able to experiment with such data structures.
## Passing interfaces
Interfaces can be placed in a concrete type, such as a struct, and then that type can be casted to `Any`. However, one gotcha is `Any` cannot contain non-static references. This means one cannot simply do:
```rust
struct Extensions<'a> {
interface1: &'a mut dyn Trait1,
interface2: &'a mut dyn Trait2,
}
let mut ext = Extensions {
interface1: &mut impl1,
interface2: &mut impl2,
};
let ext: &mut dyn Any = &mut ext;
```
To work around this without boxing, unsafe code can be used to create a safe projection using accessors. For example:
```rust
pub struct Extensions {
interface1: *mut dyn Trait1,
interface2: *mut dyn Trait2,
}
impl Extensions {
pub fn new<'a>(
interface1: &'a mut (dyn Trait1 + 'static),
interface2: &'a mut (dyn Trait2 + 'static),
scratch: &'a mut MaybeUninit<Self>,
) -> &'a mut Self {
scratch.write(Self {
interface1,
interface2,
})
}
pub fn interface1(&mut self) -> &mut dyn Trait1 {
unsafe { self.interface1.as_mut().unwrap() }
}
pub fn interface2(&mut self) -> &mut dyn Trait2 {
unsafe { self.interface2.as_mut().unwrap() }
}
}
let mut scratch = MaybeUninit::uninit();
let ext: &mut Extensions = Extensions::new(&mut impl1, &mut impl2, &mut scratch);
// ext can now be casted to `&mut dyn Any` and back, and used safely
let ext: &mut dyn Any = ext;
```
## Context inheritance
Sometimes when futures poll other futures they want to provide their own `Waker` which requires creating their own `Context`. Unfortunately, polling sub-futures with a fresh `Context` means any properties on the original `Context` won't get propagated along to the sub-futures. To help with this, some additional methods are added to `ContextBuilder`.
Here's how to derive a new `Context` from another, overriding only the `Waker`:
```rust
let mut cx = ContextBuilder::from(parent_cx).waker(&new_waker).build();
```
Avoid expanding to unstable internal method
Fixes#123156
Rather than expanding to `std::rt::begin_panic`, the expansion is now to `unreachable!()`. The resulting behavior is identical. A test that previously triggered the same error as #123156 has been added to ensure it does not regress.
r? compiler
rename ptr::from_exposed_addr -> ptr::with_exposed_provenance
As discussed on [Zulip](https://rust-lang.zulipchat.com/#narrow/stream/136281-t-opsem/topic/To.20expose.20or.20not.20to.20expose/near/427757066).
The old name, `from_exposed_addr`, makes little sense as it's not the address that is exposed, it's the provenance. (`ptr.expose_addr()` stays unchanged as we haven't found a better option yet. The intended interpretation is "expose the provenance and return the address".)
The new name nicely matches `ptr::without_provenance`.
Make inductive cycles always ambiguous
This makes inductive cycles always result in ambiguity rather than be treated like a stack-dependent error.
This has some interactions with specialization, and so breaks a few UI tests that I don't agree should've ever worked in the first place, and also breaks a handful of crates in a way that I don't believe is a problem.
On the bright side, it puts us in a better spot when it comes to eventually enabling coinduction everywhere.
## Results
This was cratered in https://github.com/rust-lang/rust/pull/116494#issuecomment-2008657494, which boils down to two regressions:
* `lu_packets` - This code should have never compiled in the first place. More below.
* **ALL** other regressions are due to `commit_verify@0.11.0-beta.1` (edit: and `commit_verify@0.10.x`) - This actually seems to be fixed in version `0.11.0-beta.5`, which is the *most* up to date version, but it's still prerelease on crates.io so I don't think cargo ends up picking `beta.5` when building dependent crates.
### `lu_packets`
Firstly, this crate uses specialization, so I think it's automatically worth breaking. However, I've minimized [the regression](https://crater-reports.s3.amazonaws.com/pr-116494-3/try%23d614ed876e31a5f3ad1d0fbf848fcdab3a29d1d8/gh/lcdr.lu_packets/log.txt) to:
```rust
// Upstream crate
pub trait Serialize {}
impl Serialize for &() {}
impl<S> Serialize for &[S] where for<'a> &'a S: Serialize {}
// ----------------------------------------------------------------------- //
// Downstream crate
#![feature(specialization)]
#![allow(incomplete_features, unused)]
use upstream::Serialize;
trait Replica {
fn serialize();
}
impl<T> Replica for T {
default fn serialize() {}
}
impl<T> Replica for Option<T>
where
for<'a> &'a T: Serialize,
{
fn serialize() {}
}
```
Specifically this fails when computing the specialization graph for the `downstream` crate.
The code ends up cycling on `&[?0]: Serialize` when we equate `&?0 = &[?1]` during impl matching, which ends up needing to prove `&[?1]: Serialize`, which since cycles are treated like ambiguity, ends up in a **fatal overflow**. For some reason this requires two crates, squashing them into one crate doesn't work.
Side-note: This code is subtly order dependent. When minimizing, I ended up having the code start failing on `nightly` very easily after removing and reordering impls. This seems to me all the more reason to remove this behavior altogether.
## Side-note: Item Bounds (edit: this was fixed independently in #121123)
Due to the changes in #120584 where we now consider an alias's item bounds *and* all the item bounds of the alias's nested self type aliases, I've had to add e6b64c61941120f734657106ae2479d05b463197 which is a hack to make sure we're not eagerly normalizing bounds that have nothing to do with the predicate we're trying to solve, and which result in.
This is fixed in a more principled way in #121123.
---
r? lcnr for an initial review
Update sysinfo to 0.30.8
Fixes a Mac specific issue when using `metrics = true` in `config.toml`.
```config.toml
# Collect information and statistics about the current build and writes it to
# disk. Enabling this or not has no impact on the resulting build output. The
# schema of the file generated by the build metrics feature is unstable, and
# this is not intended to be used during local development.
metrics = true
```
During repeated builds, as the generated `metrics.json` grew, eventually `refresh_cpu()` would be called in quick enough succession (specifically: under 200ms) that a divide by zero would occur, leading to a `NaN` which would not be serialized, then when the `metrics.json` was re-read it would fail to parse.
That error looks like this (collected from Ferrocene's CI):
```
Compiling rustdoc-tool v0.0.0 (/Users/distiller/project/src/tools/rustdoc)
Finished release [optimized] target(s) in 38.37s
thread 'main' panicked at src/utils/metrics.rs:180:21:
serde_json::from_slice::<JsonRoot>(&contents) failed with invalid type: null, expected f64 at line 1 column 9598
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Build completed unsuccessfully in 0:00:40
Exited with code exit status 1
```
Related: https://github.com/GuillaumeGomez/sysinfo/pull/1236
rustdoc: synthetic auto trait impls: accept unresolved region vars for now
https://github.com/rust-lang/rust/pull/123348#issuecomment-2032494255:
> Right, [in #123340] I've intentionally changed a `vid_map.get(vid).unwrap_or(r)` to a `vid_map[vid]` making rustdoc panic if `rustc::AutoTraitFinder` returns a region inference variable that cannot be resolved because that is really fishy. I can change it back with a `FIXME: investigate` […]. [O]nce I [fully] understand [the arcane] `rustc::AutoTraitFinder` [I] can fix the underlying issue if there's one.
>
> `rustc::AutoTraitFinder` can also return placeholder regions `RePlaceholder` which doesn't seem right either and which makes rustdoc ICE, too (we have a GitHub issue for that already[, namely #120606]).
Fixes#123370.
Fixes#112242.
r? ``@GuillaumeGomez``
CFI: Support non-general coroutines
Previously, we assumed all `ty::Coroutine` were general coroutines and attempted to generalize them through the `Coroutine` trait. Select appropriate traits for each kind of coroutine.
I have this marked as a draft because it currently only fixes async coroutines, and I think it make sense to try to fix gen/async gen coroutines before this is merged.
If the issue [mentioned](https://github.com/rust-lang/rust/pull/123106#issuecomment-2030794213) in the original PR is actually affecting someone, we can land this as is to remedy it.
Check that nested statics in thread locals are duplicated per thread.
follow-up to #123310
cc ``@compiler-errors`` ``@RalfJung``
fwiw: I have no idea how thread local statics make that work under LLVM, and miri fails on this example, which I would have expected to be the correct behaviour.
Since the `#[thread_local]` attribute is just an internal implementation detail, I'm just going to start hard erroring on nested mutable statics in thread locals.
Make sure to insert `Sized` bound first into clauses list
#120323 made it so that we don't insert an implicit `Sized` bound whenever we see an *explicit* `Sized` bound. However, since the code that inserts implicit sized bounds puts the bound as the *first* in the list, that means that it had the **side-effect** of possibly meaning we check `Sized` *after* checking other trait bounds.
If those trait bounds result in ambiguity or overflow or something, it may change how we winnow candidates. (**edit: SEE** #123303) This is likely the cause for the regression in https://github.com/rust-lang/rust/issues/123279#issuecomment-2028899598, since the impl...
```rust
impl<T: Job + Sized> AsJob for T { // <----- changing this to `Sized + Job` or just `Job` (which turns into `Sized + Job`) will FIX the issue.
}
```
...looks incredibly suspicious.
Fixes [after beta-backport] #123279.
Alternative is to revert #120323. I don't have a strong opinion about this, but think it may be nice to keep the diagnostic changes around.
De-LLVM the unchecked shifts [MCP#693]
This is just one part of the MCP (https://github.com/rust-lang/compiler-team/issues/693), but it's the one that IMHO removes the most noise from the standard library code.
Seems net simpler this way, since MIR already supported heterogeneous shifts anyway, and thus it's not more work for backends than before.
r? WaffleLapkin
Add `Ord::cmp` for primitives as a `BinOp` in MIR
Update: most of this OP was written months ago. See https://github.com/rust-lang/rust/pull/118310#issuecomment-2016940014 below for where we got to recently that made it ready for review.
---
There are dozens of reasonable ways to implement `Ord::cmp` for integers using comparison, bit-ops, and branches. Those differences are irrelevant at the rust level, however, so we can make things better by adding `BinOp::Cmp` at the MIR level:
1. Exactly how to implement it is left up to the backends, so LLVM can use whatever pattern its optimizer best recognizes and cranelift can use whichever pattern codegens the fastest.
2. By not inlining those details for every use of `cmp`, we drastically reduce the amount of MIR generated for `derive`d `PartialOrd`, while also making it more amenable to MIR-level optimizations.
Having extremely careful `if` ordering to μoptimize resource usage on broadwell (#63767) is great, but it really feels to me like libcore is the wrong place to put that logic. Similarly, using subtraction [tricks](https://graphics.stanford.edu/~seander/bithacks.html#CopyIntegerSign) (#105840) is arguably even nicer, but depends on the optimizer understanding it (https://github.com/llvm/llvm-project/issues/73417) to be practical. Or maybe [bitor is better than add](https://discourse.llvm.org/t/representing-in-ir/67369/2?u=scottmcm)? But maybe only on a future version that [has `or disjoint` support](https://discourse.llvm.org/t/rfc-add-or-disjoint-flag/75036?u=scottmcm)? And just because one of those forms happens to be good for LLVM, there's no guarantee that it'd be the same form that GCC or Cranelift would rather see -- especially given their very different optimizers. Not to mention that if LLVM gets a spaceship intrinsic -- [which it should](https://rust-lang.zulipchat.com/#narrow/stream/131828-t-compiler/topic/Suboptimal.20inlining.20in.20std.20function.20.60binary_search.60/near/404250586) -- we'll need at least a rustc intrinsic to be able to call it.
As for simplifying it in Rust, we now regularly inline `{integer}::partial_cmp`, but it's quite a large amount of IR. The best way to see that is with 8811efa88b (diff-d134c32d028fbe2bf835fef2df9aca9d13332dd82284ff21ee7ebf717bfa4765R113) -- I added a new pre-codegen MIR test for a simple 3-tuple struct, and this PR change it from 36 locals and 26 basic blocks down to 24 locals and 8 basic blocks. Even better, as soon as the construct-`Some`-then-match-it-in-same-BB noise is cleaned up, this'll expose the `Cmp == 0` branches clearly in MIR, so that an InstCombine (#105808) can simplify that to just a `BinOp::Eq` and thus fix some of our generated code perf issues. (Tracking that through today's `if a < b { Less } else if a == b { Equal } else { Greater }` would be *much* harder.)
---
r? `@ghost`
But first I should check that perf is ok with this
~~...and my true nemesis, tidy.~~
Previously, we assumed all `ty::Coroutine` were general coroutines and
attempted to generalize them through the `Coroutine` trait. Select
appropriate traits for each kind of coroutine.
Update to new browser-ui-test version
This new version brings a lot of new internal improvements (mostly around validating the commands input).
It also improved some command names and arguments.
r? `@notriddle`
rustdoc-search: shard the search result descriptions
## Preview
This makes no visual changes to rustdoc search. It's a pure perf improvement.
<details><summary>old</summary>
Preview: <http://notriddle.com/rustdoc-html-demo-10/doc/std/index.html?search=vec>
WebPageTest Comparison with before branch on a sort of worst case (searching `vec`, winds up downloading most of the shards anyway): <https://www.webpagetest.org/video/compare.php?tests=240317_AiDc61_2EM,240317_AiDcM0_2EN>
Waterfall diagram:
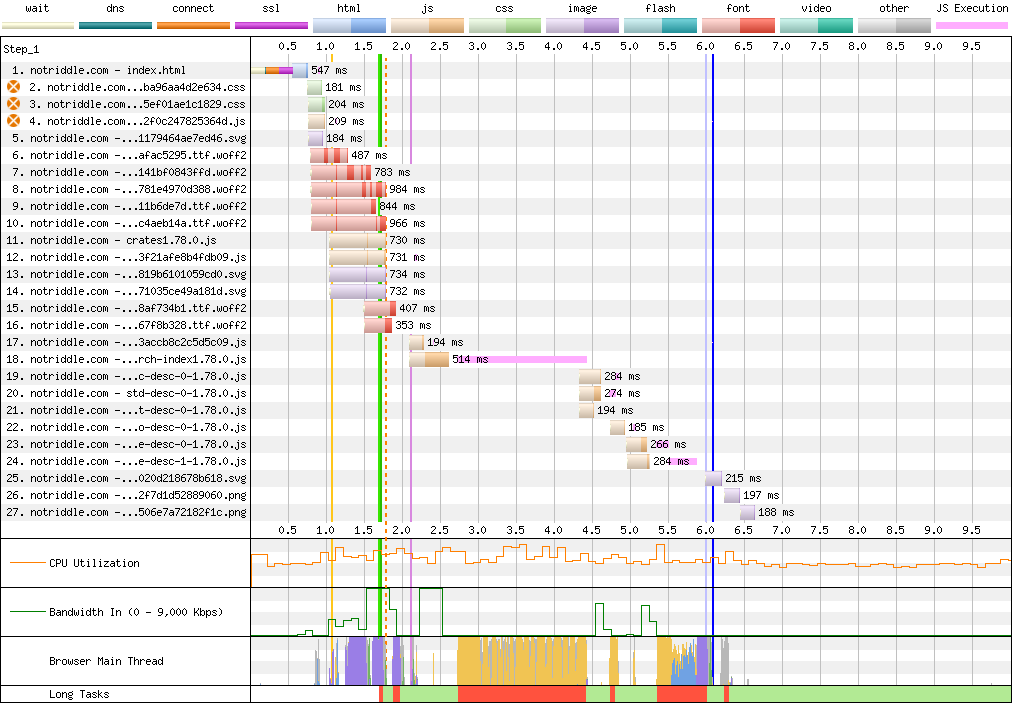
</details>
Preview: <http://notriddle.com/rustdoc-html-demo-10/doc2/std/index.html?search=vec>
WebPageTest Comparison with before branch on a sort of worst case (searching `vec`, winds up downloading most of the shards anyway): <https://www.webpagetest.org/video/compare.php?tests=240322_BiDcCH_13R,240322_AiDcJY_104>
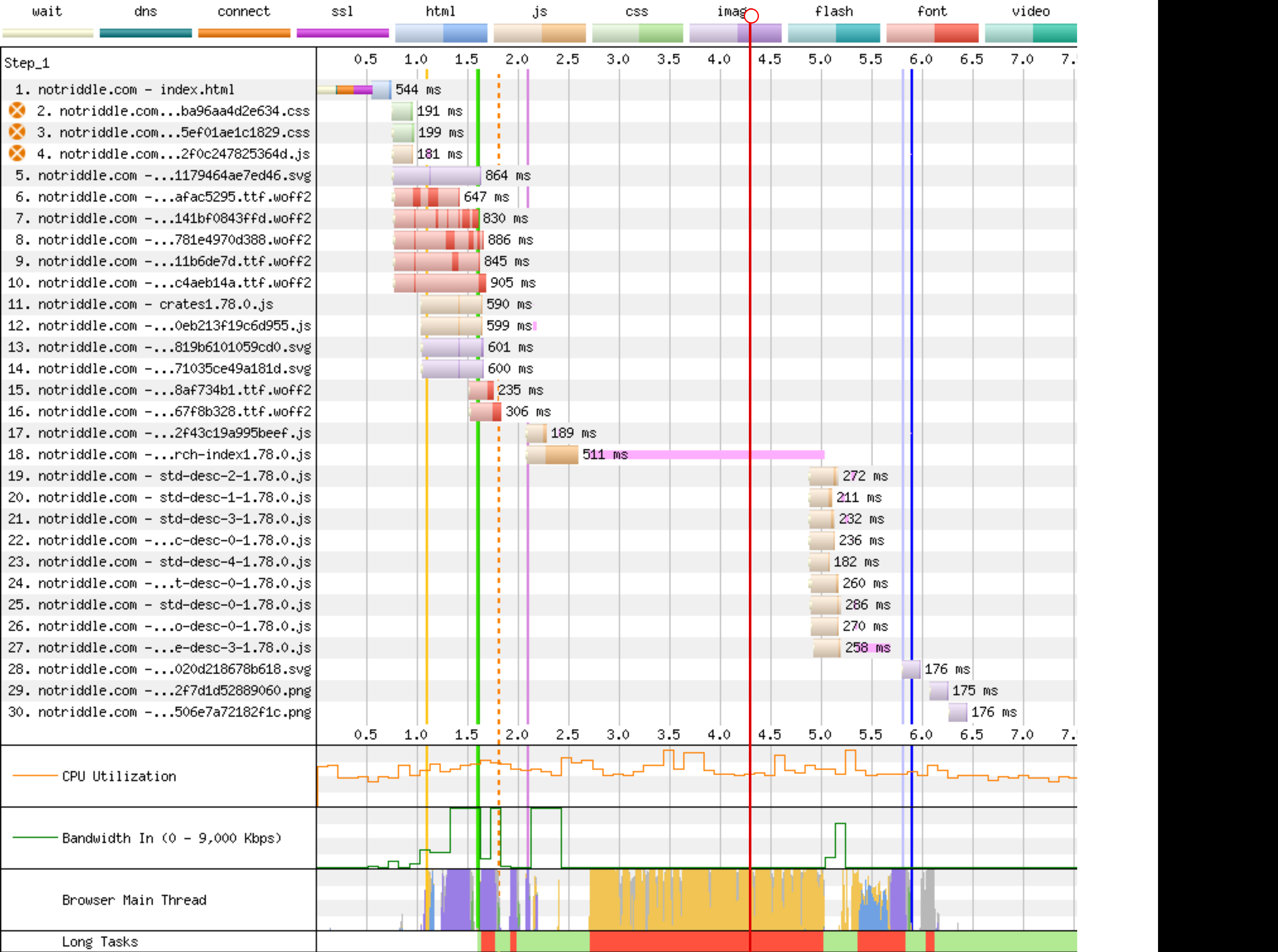
## Description
r? `@GuillaumeGomez`
The descriptions are, on almost all crates[^1], the majority of the size of the search index, even though they aren't really used for searching. This makes it relatively easy to separate them into their own files.
Additionally, this PR pulls out information about whether there's a description into a bitmap. This allows us to sort, truncate, *then* download.
This PR also bumps us to ES8. Out of the browsers we support, all of them support async functions according to caniuse.
https://caniuse.com/async-functions
[^1]:
<https://microsoft.github.io/windows-docs-rs/>, a crate with
44MiB of pure names and no descriptions for them, is an outlier
and should not be counted. But this PR should improve it, by replacing a long line of empty strings with a compressed bitmap with a single Run section. Just not very much.
## Detailed sizes
```console
$ cat test.sh
set -ex
cp ../search-index*.js search-index.js
awk 'FNR==NR {a++;next} FNR<a-3' search-index.js{,} | awk 'NR>1 {gsub(/\],\\$/,""); gsub(/^\["[^"]+",/,""); print} {next}' | sed -E "s:\\\\':':g" > search-index.json
jq -c '.t' search-index.json > t.json
jq -c '.n' search-index.json > n.json
jq -c '.q' search-index.json > q.json
jq -c '.D' search-index.json > D.json
jq -c '.e' search-index.json > e.json
jq -c '.i' search-index.json > i.json
jq -c '.f' search-index.json > f.json
jq -c '.c' search-index.json > c.json
jq -c '.p' search-index.json > p.json
jq -c '.a' search-index.json > a.json
du -hs t.json n.json q.json D.json e.json i.json f.json c.json p.json a.json
$ bash test.sh
+ cp ../search-index1.78.0.js search-index.js
+ awk 'FNR==NR {a++;next} FNR<a-3' search-index.js search-index.js
+ awk 'NR>1 {gsub(/\],\\$/,""); gsub(/^\["[^"]+",/,""); print} {next}'
+ sed -E 's:\\'\'':'\'':g'
+ jq -c .t search-index.json
+ jq -c .n search-index.json
+ jq -c .q search-index.json
+ jq -c .D search-index.json
+ jq -c .e search-index.json
+ jq -c .i search-index.json
+ jq -c .f search-index.json
+ jq -c .c search-index.json
+ jq -c .p search-index.json
+ jq -c .a search-index.json
+ du -hs t.json n.json q.json D.json e.json i.json f.json c.json p.json a.json
64K t.json
800K n.json
8.0K q.json
4.0K D.json
16K e.json
192K i.json
544K f.json
4.0K c.json
36K p.json
20K a.json
```
These are, roughly, the size of each section in the standard library (this tool actually excludes libtest, for parsing-json-with-awk reasons, but libtest is tiny so it's probably not important).
t = item type, like "struct", "free fn", or "type alias". Since one byte is used for every item, this implies that there are approximately 64 thousand items in the standard library.
n = name, and that's now the largest section of the search index with the descriptions removed from it
q = parent *module* path, stored parallel to the items within
D = the size of each description shard, stored as vlq hex numbers
e = empty description bit flags, stored as a roaring bitmap
i = parent *type* index as a link into `p`, stored as decimal json numbers; used only for associated types; might want to switch to vlq hex, since that's shorter, but that would be a separate pr
f = function signature, stored as lists of lists that index into `p`
c = deprecation flag, stored as a roaring bitmap
p = parent *type*, stored separately and linked into from `i` and `f`
a = alias, as [[key, value]] pairs
## Search performance
http://notriddle.com/rustdoc-html-demo-11/perf-shard/index.html
For example, in stm32f4:
<table><thead><tr><th>before<th>after</tr></thead>
<tbody><tr><td>
```
Testing T -> U ... in_args = 0, returned = 0, others = 200
wall time = 617
Testing T, U ... in_args = 0, returned = 0, others = 200
wall time = 198
Testing T -> T ... in_args = 0, returned = 0, others = 200
wall time = 282
Testing crc32 ... in_args = 0, returned = 0, others = 0
wall time = 426
Testing spi::pac ... in_args = 0, returned = 0, others = 0
wall time = 673
```
</td><td>
```
Testing T -> U ... in_args = 0, returned = 0, others = 200
wall time = 716
Testing T, U ... in_args = 0, returned = 0, others = 200
wall time = 207
Testing T -> T ... in_args = 0, returned = 0, others = 200
wall time = 289
Testing crc32 ... in_args = 0, returned = 0, others = 0
wall time = 418
Testing spi::pac ... in_args = 0, returned = 0, others = 0
wall time = 687
```
</td></tr><tr><td>
```
user: 005.345 s
sys: 002.955 s
wall: 006.899 s
child_RSS_high: 583664 KiB
group_mem_high: 557876 KiB
```
</td><td>
```
user: 004.652 s
sys: 000.565 s
wall: 003.865 s
child_RSS_high: 538696 KiB
group_mem_high: 511724 KiB
```
</td></tr>
</table>
This perf tester is janky and unscientific enough that the apparent differences might just be noise. If it's not an order of magnitude, it's probably not real.
## Future possibilities
* Currently, results are not shown until the descriptions are downloaded. Theoretically, the description-less results could be shown. But actually doing that, and making sure it works properly, would require extra work (we have to be careful to avoid layout jumps).
* More than just descriptions can be sharded this way. But we have to be careful to make sure the size wins are worth the round trips. Ideally, data that’s needed only for display should be sharded while data needed for search isn’t.
* [Full text search](https://internals.rust-lang.org/t/full-text-search-for-rustdoc-and-doc-rs/20427) also needs this kind of infrastructure. A good implementation might store a compressed bloom filter in the search index, then download the full keyword in shards. But, we have to be careful not just of the amount readers have to download, but also of the amount that [publishers](https://gist.github.com/notriddle/c289e77f3ed469d1c0238d1d135d49e1) have to store.
fix: build on haiku by adding missing import
Fix the build on Haiku by adding a missing import
```
error[E0433]: failed to resolve: use of undeclared crate or module `slice`
--> /localhome/somers/.rustup/toolchains/nightly-x86_64-unknown-freebsd/lib/rustlib/src/rust/library/std/src/sys/pal/unix/thread.rs:272:24
|
272 | let name = slice::from_raw_parts(info.name.as_ptr() as *const u8, info.name.len());
| ^^^^^ use of undeclared crate or module `slice`
|
help: consider importing one of these items
|
1 + use alloc::slice;
|
1 + use core::slice;
|
1 + use crate::slice;
```
Closes#123343
rustdoc: heavily simplify the synthesis of auto trait impls
`gd --numstat HEAD~2 HEAD src/librustdoc/clean/auto_trait.rs`
**+315 -705** 🟩🟥🟥🟥⬛
---
As outlined in issue #113015, there are currently 3[^1] large separate routines that “clean” `rustc_middle::ty` data types related to generics & predicates to rustdoc data types. Every single one has their own kinds of bugs. While I've patched a lot of bugs in each of the routines in the past, it's about time to unify them. This PR is only the first in a series. It completely **yanks** the custom “bounds cleaning” of mod `auto_trait` and reuses the routines found in mod `simplify`. As alluded to, `simplify` is also flawed but it's still more complete than `auto_trait`'s routines. [See also my review comment over at `tests/rustdoc/synthetic_auto/bounds.rs`](https://github.com/rust-lang/rust/pull/123340#discussion_r1546900539).
This is preparatory work for rewriting “bounds cleaning” from scratch in follow-up PRs in order to finally [fix] #113015.
Apart from that, I've eliminated all potential sources of *instability* in the rendered output.
See also #119597. I'm pretty sure this fixes#119597.
This PR does not attempt to fix [any other issues related to synthetic auto trait impls](https://github.com/rust-lang/rust/issues?q=is%3Aissue+is%3Aopen+label%3AA-synthetic-impls%20label%3AA-auto-traits).
However, it's definitely meant to be a *stepping stone* by making `auto_trait` more contributor-friendly.
---
* Replace `FxHash{Map,Set}` with `FxIndex{Map,Set}` to guarantee a stable iteration order
* Or as a perf opt, `UnordSet` (a thin wrapper around `FxHashSet`) in cases where we never iterate over the set.
* Yes, we do make use of `swap_remove` but that shouldn't matter since all the callers are deterministic. It does make the output less “predictable” but it's still better than before. Ofc, I rely on `rustc_infer` being deterministic. I hope that holds.
* Utilizing `clean::simplify` over the custom “bounds cleaning” routines wipes out the last reference to `collect_referenced_late_bound_regions` in rustdoc (`simplify` uses `bound_vars`) which was a source of instability / unpredictability (cc #116388)
* Remove the types `RegionTarget` and `RegionDeps` from `librustdoc`. They were duplicates of the identical types found in `rustc`. Just import them from `rustc`. For some reason, they were duplicated when splitting `auto_trait` in two in #49711.
* Get rid of the useless “type namespace” `AutoTraitFinder` in `librustdoc`
* The struct only held a `DocContext`, it was over-engineered
* Turn the associated functions into free ones
* Eliminates rightward drift; increases legibility
* `rustc` also contains a useless `AutoTraitFinder` struct but I plan on removing that in a follow-up PR
* Rename a bunch of methods to be way more descriptive
* Eliminate `use super::*;`
* Lead to `clean/mod.rs` accumulating a lot of unnecessary imports
* Made `auto_traits` less modular
* Eliminate a custom `TypeFolder`: We can just use the rustc helper `fold_regions` which does that for us
I plan on adding extensive documentation to `librustdoc`'s `auto_trait` in follow-up PRs.
I don't want to do that in this PR because further refactoring & bug fix PRs may alter the overall structure of `librustdoc`'s & `rustc`'s `auto_trait` modules to a great degree. I'm slowly digging into the dark details of `rustc`'s `auto_trait` module again and once I have the full picture I will be able to provide proper docs.
---
While this PR does indeed touch `rustc`'s `auto_trait` — mostly tiny refactorings — I argue this PR doesn't need any compiler reviewers next to rustdoc ones since that module falls under the purview of rustdoc — it used to be part of `librustdoc` after all (#49711).
Sorry for not having split this into more commits. If you'd like me to I can try to split it into more atomic commits retroactively. However, I don't know if that would actually make reviewing easier. I think the best way to review this might just be to place the master version of `auto_trait` on the left of your screen and the patched one on the right, not joking.
r? `@GuillaumeGomez`
[^1]: Or even 4 depending on the way you're counting.
Only allow compiler_builtins to call LLVM intrinsics, not any link_name function
This is another case of accidental reliance on `inline(never)` like I rooted out in https://github.com/rust-lang/rust/pull/118770. Without this PR, attempting to build some large programs with `-Zcross-crate-inline-threshold=yes` with a sysroot also compiled with that flag will result in linker errors like this:
```
= note: /usr/bin/ld: /tmp/cargo-installNrfN4T/x86_64-unknown-linux-gnu/release/deps/libcompiler_builtins-d2a9b69f4e45b883.rlib(compiler_builtins-d2a9b69f4e45b883.compiler_builtins.dbbc6c2ca970faa4-cgu.0.rcgu.o): in function `core::panicking::panic_fmt':
/home/ben/.rustup/toolchains/nightly-x86_64-unknown-linux-gnu/lib/rustlib/src/rust/library/core/src/panicking.rs:72:(.text.unlikely._ZN4core9panicking9panic_fmt17ha407cc99e97c942fE+0x31): undefined reference to `rust_begin_unwind'
```
With `-Zcross-crate-inline-threshold=yes` we can inline `panic_fmt` into `compiler_builtins`. Then we end up with a call to an upstream monomorphization, but one that has a `link_name` set. But unlike LLVM's magic intrinsic names, this link name is going to make it to the linker, and then we have a problem.
This logic looks scuffed, but also we're doing this in 4 other places. Don't know if that means it's good or bad.
1684a753db/compiler/rustc_codegen_cranelift/src/abi/mod.rs (L386)1684a753db/compiler/rustc_ast_passes/src/feature_gate.rs (L306)1684a753db/compiler/rustc_codegen_ssa/src/codegen_attrs.rs (L609)1684a753db/compiler/rustc_codegen_gcc/src/declare.rs (L170)
Note impact of `-Cstrip` on backtraces
It is not always clear to people what the impact of `-Cstrip` options are. They are a common question on sites like StackOverflow, and sometimes people even report bugs with "no backtrace" after deliberately mangling the symbol table. We cannot exhaustively document every permutation, but we should warn people about common effects.
Eagerly instantiate closure/coroutine-like bounds with placeholders to deal with binders correctly
A follow-up to #119849, however it aims to fix a different set of issues. Currently, we have trouble confirming goals where built-in closure/fnptr/coroutine signatures are compared against higher-ranked goals.
Currently, we don't support goals like `for<'a> fn(&'a ()): Fn(&'a ())` because we don't expect the self type of goal to reference any bound regions from the goal, because we don't really know how to deal with the double binder of predicate + self type. However, this definitely can be reached (#121653) -- and in fact, it results in post-mono errors in the case of #112347 where the builtin type (e.g. a coroutine) is hidden behind a TAIT.
The proper fix here is to instantiate the goal before trying to extract the signature from the self type. See final two commits.
r? lcnr