Suggest character encoding is incorrect when encountering random null bytes
This adds a note whenever null bytes are seen at the start of a token unexpectedly, since those tend to come from UTF-16 encoded files without a [BOM](https://en.wikipedia.org/wiki/Byte_order_mark) (if a UTF-16 BOM appears it won't be valid UTF-8, but if there is no BOM it be both valid UTF-16 and valid but garbled UTF-8). This approach was suggested in https://github.com/rust-lang/rust/issues/73979#issuecomment-653976451.
Closes#73979.
Skip Ty w/o infer ty/const in trait select
Remove some allocations & also add `skip_current_subtree` to skip subtrees with no inferred items.
r? `@eddyb` since marked in the FIXME
This adds recovery when in array type syntax user writes
[X; Y<Z, ...>]
instead of
[X; Y::<Z, ...>]
Fixes#82566
Note that whenever we parse an expression and know that the next token
cannot be `,`, we should be calling
check_mistyped_turbofish_with_multiple_type_params for this recovery.
Previously we only did this for statement parsing (e.g. `let x = f<a,
b>;`). We now also do it when parsing the length field in array type
syntax.
check_mistyped_turbofish_with_multiple_type_params was previously
expecting type arguments between angle brackets, which is not right, as
we can also see const expressions. We now use generic argument parser
instead of type parser.
Test with one, two, and three generic arguments added to check
consistentcy between
1. check_no_chained_comparison: Called after parsing a nested binop
application like `x < A > ...` where angle brackets are interpreted as
binary operators and `A` is an expression.
2. check_mistyped_turbofish_with_multiple_type_params: called by
`parse_full_stmt` when we expect to see a semicolon after parsing an
expression but don't see it.
(In `T2<1, 2>::C;`, the expression is `T2 < 1`)
When token-based attribute handling is implemeneted in #80689,
we will need to access tokens from `HasAttrs` (to perform
cfg-stripping), and we will to access attributes from `HasTokens` (to
construct a `PreexpTokenStream`).
This PR merges the `HasAttrs` and `HasTokens` traits into a new
`AstLike` trait. The previous `HasAttrs` impls from `Vec<Attribute>` and `AttrVec`
are removed - they aren't attribute targets, so the impls never really
made sense.
Use small hash set in `mir_inliner_callees`
Use small hash set in `mir_inliner_callees` to avoid temporary
allocation when possible and quadratic behaviour for large number of
callees.
Improve anonymous lifetime note to indicate the target span
Improvement for #81650
Cc #81995
Message after this improvement:
(Improve note in the middle)
```
error[E0311]: the parameter type `T` may not live long enough
--> src/main.rs:25:11
|
24 | fn play_with<T: Animal + Send>(scope: &Scope, animal: T) {
| -- help: consider adding an explicit lifetime bound...: `T: 'a +`
25 | scope.spawn(move |_| {
| ^^^^^
|
note: the parameter type `T` must be valid for the anonymous lifetime defined on the function body at 24:40...
--> src/main.rs:24:40
|
24 | fn play_with<T: Animal + Send>(scope: &Scope, animal: T) {
| ^^^^^
note: ...so that the type `[closure@src/main.rs:25:17: 27:6]` will meet its required lifetime bounds
--> src/main.rs:25:11
|
25 | scope.spawn(move |_| {
| ^^^^^
```
r? ``````@estebank``````
Replace const_cstr with cstr crate
This PR replaces the `const_cstr` macro inside `rustc_data_structures` with `cstr` macro from [cstr](https://crates.io/crates/cstr) crate.
The two macros basically serve the same purpose, which is to generate `&'static CStr` from a string literal. `cstr` is better because it validates the literal at compile time, while the existing `const_cstr` does it at runtime when `debug_assertions` is enabled. In addition, the value `cstr` generates can be used in constant context (which is seemingly not needed anywhere currently, though).
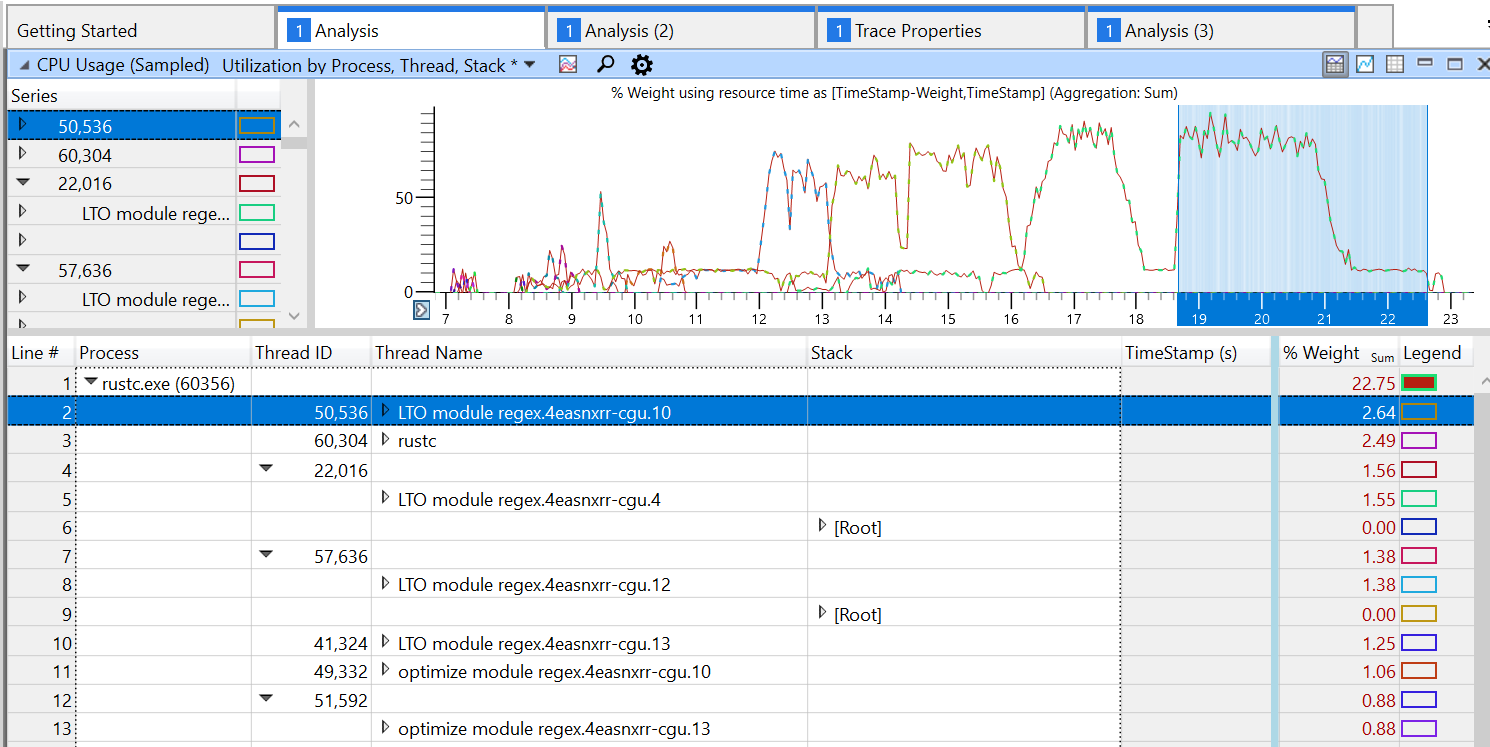
Set codegen thread names
Set names on threads spawned during codegen. Various debugging and profiling tools can take advantage of this to show a more useful identifier for threads.
For example, gdb will show thread names in `info threads`:
```
(gdb) info threads
Id Target Id Frame
1 Thread 0x7fffefa7ec40 (LWP 2905) "rustc" __pthread_clockjoin_ex (threadid=140737214134016, thread_return=0x0, clockid=<optimized out>, abstime=<optimized out>, block=<optimized out>)
at pthread_join_common.c:145
2 Thread 0x7fffefa7b700 (LWP 2957) "rustc" 0x00007ffff125eaa8 in llvm::X86_MC::initLLVMToSEHAndCVRegMapping(llvm::MCRegisterInfo*) ()
from /home/wesley/.rustup/toolchains/stage1/lib/librustc_driver-f866439e29074957.so
3 Thread 0x7fffeef0f700 (LWP 3116) "rustc" futex_wait_cancelable (private=0, expected=0, futex_word=0x7fffe8602ac8) at ../sysdeps/nptl/futex-internal.h:183
* 4 Thread 0x7fffeed0e700 (LWP 3123) "rustc" rustc_codegen_ssa:🔙:write::spawn_work (cgcx=..., work=...) at /home/wesley/code/rust/rust/compiler/rustc_codegen_ssa/src/back/write.rs:1573
6 Thread 0x7fffe113b700 (LWP 3150) "opt foof.7rcbfp" 0x00007ffff2940e62 in llvm::CallGraph::populateCallGraphNode(llvm::CallGraphNode*) ()
from /home/wesley/.rustup/toolchains/stage1/lib/librustc_driver-f866439e29074957.so
8 Thread 0x7fffe0d39700 (LWP 3158) "opt foof.7rcbfp" 0x00007fffefe8998e in malloc_consolidate (av=av@entry=0x7ffe2c000020) at malloc.c:4492
9 Thread 0x7fffe0f3a700 (LWP 3162) "opt foof.7rcbfp" 0x00007fffefef27c4 in __libc_open64 (file=0x7fffe0f38608 "foof.foof.7rcbfp3g-cgu.6.rcgu.o", oflag=524865) at ../sysdeps/unix/sysv/linux/open64.c:48
(gdb)
```
and Windows Performance Analyzer will also show this information when profiling:
Consider inexpensive inlining criteria first
Refactor inlining decisions so that inexpensive criteria are considered first:
1. Based on code generation attributes.
2. Based on MIR availability (examines call graph).
3. Based on MIR body.
Reword labels on E0308 involving async fn return type
Fix for #80658.
When someone writes code like this:
```rust
fn foo() -> u8 {
async fn async_fn() -> () {}
async_fn()
}
```
And they try to compile it, they will see an error that looks like this:
```bash
error[E0308]: mismatched types
--> test.rs:4:5
|
1 | fn foo() -> u8 {
| -- expected `u8` because of return type
2 | async fn async_fn() -> () {}
| -- checked the `Output` of this `async fn`, found opaque type
3 |
4 | async_fn()
| ^^^^^^^^^^ expected `u8`, found opaque type
|
= note: while checking the return type of this `async fn`
= note: expected type `u8`
found opaque type `impl Future`
```
For some targets, rustc uses a "CRT fallback", where it links CRT
object files it ships instead of letting the host compiler link
them.
On musl, rustc currently links crt1, crti and crtn (provided by
libc), but does not link crtbegin and crtend (provided by libgcc).
In particular, crtend is responsible for terminating the .eh_frame
section. Lack of terminator may result in segfaults during
unwinding, as reported in #47551 and encountered by the LLVM 12
update in #81451.
This patch links crtbegin and crtend for musl as well, following
the table at the top of crt_objects.rs.
[librustdoc] Only split lang string on `,`, ` `, and `\t`
Split markdown lang strings into tokens on `,`.
The previous behavior was to split lang strings into tokens on any
character that wasn't a `_`, `_`, or alphanumeric.
This is a potentially breaking change, so please scrutinize! See discussion in #78344.
I noticed some test cases that made me wonder if there might have been some reason for the original behavior:
```
t("{.no_run .example}", false, true, Ignore::None, true, false, false, false, v(), None);
t("{.sh .should_panic}", true, false, Ignore::None, false, false, false, false, v(), None);
t("{.example .rust}", false, false, Ignore::None, true, false, false, false, v(), None);
t("{.test_harness .rust}", false, false, Ignore::None, true, true, false, false, v(), None);
```
It seemed pretty peculiar to specifically test lang strings in braces, with all the tokens prefixed by `.`.
I did some digging, and it looks like the test cases were added way back in [this commit from 2014](https://github.com/rust-lang/rust/commit/3fef7a74ca9a) by `@skade.`
It looks like they were added just to make sure that the splitting was permissive, and aren't testing that those strings in particular are accepted.
Closes https://github.com/rust-lang/rust/issues/78344.
This version adds the ability to use `rdpmc` hardware-based performance
counters instead of wall-clock time for measuring duration. This also
introduces a dependency on the `perf-event-open-sys` crate on Linux
which is used when using hardware counters.
Move pick_by_value_method docs above function header
- Currently style triggers #81183 so we can't add `#[instrument]` to
this function.
- Having docs above the header is more consistent with the rest of the
code base.
Cleanup `PpMode` and friends
This PR:
- Separates `PpSourceMode` and `PpHirMode` to remove invalid states
- Renames the variant to remove the redundant `Ppm` prefix
- Adds basic documentation for the different pretty-print modes
- Cleanups some code to make it more idiomatic
Not sure if this is actually useful, but it looks cleaner to me.
Add #[rustc_legacy_const_generics]
This is the first step towards removing `#[rustc_args_required_const]`: a new attribute is added which rewrites function calls of the form `func(a, b, c)` to `func::<{b}>(a, c)`. This allows previously stabilized functions in `stdarch` which use `rustc_args_required_const` to use const generics instead.
This new attribute is not intended to ever be stabilized, it is only intended for use in `stdarch` as a replacement for `#[rustc_args_required_const]`.
```rust
#[rustc_legacy_const_generics(1)]
pub fn foo<const Y: usize>(x: usize, z: usize) -> [usize; 3] {
[x, Y, z]
}
fn main() {
assert_eq!(foo(0 + 0, 1 + 1, 2 + 2), [0, 2, 4]);
assert_eq!(foo::<{1 + 1}>(0 + 0, 2 + 2), [0, 2, 4]);
}
```
r? `@oli-obk`
Improve error msgs when found type is deref of expected
This improves help messages in two cases:
- When expected type is `T` and found type is `&T`, we now look through blocks
and suggest dereferencing the expression of the block, rather than the whole
block.
- In the above case, if the expression is an `&`, we not suggest removing the
`&` instead of adding `*`.
Both of these are demonstrated in the regression test. Before this patch the
first error in the test would be:
error[E0308]: `if` and `else` have incompatible types
--> test.rs:8:9
|
5 | / if true {
6 | | a
| | - expected because of this
7 | | } else {
8 | | b
| | ^ expected `usize`, found `&usize`
9 | | };
| |_____- `if` and `else` have incompatible types
|
help: consider dereferencing the borrow
|
7 | } else *{
8 | b
9 | };
|
Now:
error[E0308]: `if` and `else` have incompatible types
--> test.rs:8:9
|
5 | / if true {
6 | | a
| | - expected because of this
7 | | } else {
8 | | b
| | ^
| | |
| | expected `usize`, found `&usize`
| | help: consider dereferencing the borrow: `*b`
9 | | };
| |_____- `if` and `else` have incompatible types
The second error:
error[E0308]: `if` and `else` have incompatible types
--> test.rs:14:9
|
11 | / if true {
12 | | 1
| | - expected because of this
13 | | } else {
14 | | &1
| | ^^ expected integer, found `&{integer}`
15 | | };
| |_____- `if` and `else` have incompatible types
|
help: consider dereferencing the borrow
|
13 | } else *{
14 | &1
15 | };
|
now:
error[E0308]: `if` and `else` have incompatible types
--> test.rs:14:9
|
11 | / if true {
12 | | 1
| | - expected because of this
13 | | } else {
14 | | &1
| | ^-
| | ||
| | |help: consider removing the `&`: `1`
| | expected integer, found `&{integer}`
15 | | };
| |_____- `if` and `else` have incompatible types
Fixes#82361
---
r? ````@estebank````
fix the false 'defined here' messages
Closes#80853.
Take this code:
```rust
struct S;
fn repro_ref(thing: S) {
thing();
}
```
Previously, the error message would be this:
```
error[E0618]: expected function, found `S`
--> src/lib.rs:4:5
|
3 | fn repro_ref(thing: S) {
| ----- `S` defined here
4 | thing();
| ^^^^^--
| |
| call expression requires function
error: aborting due to previous error
```
This is incorrect as `S` is not defined in the function arguments, `thing` is defined there. With this change, the following is emitted:
```
error[E0618]: expected function, found `S`
--> $DIR/80853.rs:4:5
|
LL | fn repro_ref(thing: S) {
| ----- is of type `S`
LL | thing();
| ^^^^^--
| |
| call expression requires function
|
= note: local variable `S` is not a function
error: aborting due to previous error
```
As you can see, this error message points out that `thing` is of type `S` and later in a note, that `S` is not a function. This change does seem like a downside for some error messages. Take this example:
```
LL | struct Empty2;
| -------------- is of type `Empty2`
```
As you can see, the error message shows that the definition of `Empty2` is of type `Empty2`. Although this isn't wrong, it would be more helpful if it would say something like this (which was there previously):
```
LL | struct Empty2;
| -------------- `Empty2` defined here
```
If there is a better way of doing this, where the `Empty2` example would stay the same as without this change, please inform me.
**Update: This is now fixed**
CC `@camelid`
Fix ICE caused by suggestion with no code substitutions
Change suggestion logic to filter and checking _before_ creating
specific resolution suggestion.
Assert earlier that suggestions contain code substitions to make it
easier in the future to debug invalid uses. If we find this becomes too
noisy in the wild, we can always make the emitter resilient to these
cases and remove the assertions.
Fix#78651.
- Currently style triggers #81183 so we can't add `#[instrument]` to
this function.
- Having docs above the header is more consistent with the rest of the
code base.
Make the `Query` enum a simple struct.
A lot of code in `rustc_query_system` is generic over it, only to encode an exceptional error case: query cycles.
The delayed computations are now done at cycle detection.
Refactor inlining decisions so that inexpensive criteria are considered first:
1. Based on code generation attributes.
2. Based on MIR availability (examines call graph).
3. Based on MIR body.
Consider auto derefs before warning about write only fields
Changes from #81473 extended the dead code lint with an ability to detect
fields that are written to but never read from. The implementation skips
over fields on the left hand side of an assignment, without marking them
as live.
A field access might involve an automatic dereference and de-facto read
the field. Conservatively mark expressions with deref adjustments as
live to avoid generating false positive warnings.
Closes#81626.
Implement -Z hir-stats for nested foreign items
An attempt to compute HIR stats for crates with nested foreign items results in an ICE.
```rust
fn main() {
extern "C" { fn f(); }
}
```
```
thread 'rustc' panicked at 'visit_nested_xxx must be manually implemented in this visitor'
```
Provide required implementation of visitor method.
Improve non_fmt_panic lint.
This change:
- fixes the span used by this lint in the case the panic argument is a single macro expansion (e.g. `panic!(a!())`);
- adds a suggestion for `panic!(format!(..))` to remove `format!()` instead of adding `"{}", ` or using `panic_any` like it does now; and
- fixes the incorrect suggestion to replace `panic![123]` by `panic_any(123]`.
Fixes#82109.
Fixes#82110.
Fixes#82111.
Example output:
```
warning: panic message is not a string literal
--> src/main.rs:8:12
|
8 | panic!(format!("error: {}", "oh no"));
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
= note: `#[warn(non_fmt_panic)]` on by default
= note: this is no longer accepted in Rust 2021
= note: the panic!() macro supports formatting, so there's no need for the format!() macro here
help: remove the `format!(..)` macro call
|
8 | panic!("error: {}", "oh no");
| -- --
```
r? `@estebank`
Point out implicit deref coercions in borrow
Fixes#81365
`@Aaron1011` I'm not sure why my code shows the note even in an implicit `Deref` call. See the output for `issue-81365-8.rs`.
rustc_codegen_ssa: tune codegen according to available concurrency
This change tunes ahead-of-time codegening according to the amount of
concurrency available, rather than according to the number of CPUs on
the system. This can lower memory usage by reducing the number of
compiled LLVM modules in memory at once, particularly across several
rustc instances.
Previously, each rustc instance would assume that it should codegen
ahead of time to meet the demand of number-of-CPUs workers. But often, a
rustc instance doesn't have nearly that much concurrency available to
it, because the concurrency availability is split, via the jobserver,
across all active rustc instances spawned by the driving cargo process,
and is further limited by the `-j` flag argument. Therefore, each rustc
might have had several times the number of LLVM modules in memory than
it really needed to meet demand. If the modules were large, the effect
on memory usage would be noticeable.
With this change, the required amount of ahead-of-time codegen scales up
with the actual number of workers running within a rustc instance. Note
that the number of workers running can be less than the actual
concurrency available to a rustc instance. However, if more concurrency
is actually available, workers are spun up quickly as job tokens are
acquired, and the ahead-of-time codegen scales up quickly as well.
Set path of the compile unit to the source directory
As part of the effort to implement split dwarf debug info, we ended up
setting the compile unit location to the output directory rather than
the source directory. Furthermore, it seems like we failed to remap the
prefixes for this as well!
The desired behaviour is to instead set the `DW_AT_GNU_dwo_name` to a
path relative to compiler's working directory. This still allows
debuggers to find the split dwarf files, while not changing the
behaviour of the code that is compiling with regular debug info, and not
changing the compiler's behaviour with regards to reproducibility.
Fixes#82074
cc `@alexcrichton` `@davidtwco`
This improves help messages in two cases:
- When expected type is `T` and found type is `&T`, we now look through blocks
and suggest dereferencing the expression of the block, rather than the whole
block.
- In the above case, if the expression is an `&`, we not suggest removing the
`&` instead of adding `*`.
Both of these are demonstrated in the regression test. Before this patch the
first error in the test would be:
error[E0308]: `if` and `else` have incompatible types
--> test.rs:8:9
|
5 | / if true {
6 | | a
| | - expected because of this
7 | | } else {
8 | | b
| | ^ expected `usize`, found `&usize`
9 | | };
| |_____- `if` and `else` have incompatible types
|
help: consider dereferencing the borrow
|
7 | } else *{
8 | b
9 | };
|
Now:
error[E0308]: `if` and `else` have incompatible types
--> test.rs:8:9
|
5 | / if true {
6 | | a
| | - expected because of this
7 | | } else {
8 | | b
| | ^
| | |
| | expected `usize`, found `&usize`
| | help: consider dereferencing the borrow: `*b`
9 | | };
| |_____- `if` and `else` have incompatible types
The second error:
error[E0308]: `if` and `else` have incompatible types
--> test.rs:14:9
|
11 | / if true {
12 | | 1
| | - expected because of this
13 | | } else {
14 | | &1
| | ^^ expected integer, found `&{integer}`
15 | | };
| |_____- `if` and `else` have incompatible types
|
help: consider dereferencing the borrow
|
13 | } else *{
14 | &1
15 | };
|
now:
error[E0308]: `if` and `else` have incompatible types
--> test.rs:14:9
|
11 | / if true {
12 | | 1
| | - expected because of this
13 | | } else {
14 | | &1
| | ^-
| | ||
| | |help: consider removing the `&`: `1`
| | expected integer, found `&{integer}`
15 | | };
| |_____- `if` and `else` have incompatible types
Fixes#82361
Update the bootstrap compiler
This updates the bootstrap compiler, notably leaving out a change to enable semicolon in macro expressions lint, because stdarch still depends on the old behavior.
Make `treat_err_as_bug` Option<NonZeroUsize>
`rustc -Z treat-err-as-bug=N` already requires `N` to be nonzero when the argument is parsed, so changing the type from `Option<usize>` to `Option<NonZeroUsize>` is a low-hanging fruit in terms of layout optimization.
add s390x-unknown-linux-musl target
This is the first step in bringup for Rust on s390x.
The libc and std crates need modifications as well, but getting this upstream makes that work easier.
add diagnostic items for OsString/PathBuf/Owned as well as to_vec on slice
This is adding diagnostic items to be used by rust-lang/rust-clippy#6730, but my understanding is the clippy-side change does need to be done over there since I am adding a new clippy feature.
Add diagnostic items to the following types:
OsString (os_string_type)
PathBuf (path_buf_type)
Owned (to_owned_trait)
As well as the to_vec method on slice/[T]
Suggest `return`ing tail expressions that match return type
Some newcomers are confused by the behavior of tail expressions,
interpreting that "leaving out the `;` makes it the return value".
To help them go in the right direction, suggest using `return` instead
when applicable.
Improve suggestion for tuple struct pattern matching errors.
Closes#80174
This change allows numbers to be parsed as field names when pattern matching on structs, which allows us to provide better error messages when tuple structs are matched using a struct pattern.
r? ``@estebank``
Inline hot part of PatStack::head_ctor
When building rustc with `-Codegen-units=1` this inline hint ensures
that obtaining already initialized head constructor does not involve
a function call overhead and reduces the instruction count in
match-stress-enum-check full benchmark from 11.9G to 9.8G.
It shouldn't have significant impact on the currently default
configuration where it reflects existing inlining decisions.
{kind=link}