coverage bug fixes and optimization support
Adjusted LLVM codegen for code compiled with `-Zinstrument-coverage` to
address multiple, somewhat related issues.
Fixed a significant flaw in prior coverage solution: Every counter
generated a new counter variable, but there should have only been one
counter variable per function. This appears to have bloated .profraw
files significantly. (For a small program, it increased the size by
about 40%. I have not tested large programs, but there is anecdotal
evidence that profraw files were way too large. This is a good fix,
regardless, but hopefully it also addresses related issues.
Fixes: #82144
Invalid LLVM coverage data produced when compiled with -C opt-level=1
Existing tests now work up to at least `opt-level=3`. This required a
detailed analysis of the LLVM IR, comparisons with Clang C++ LLVM IR
when compiled with coverage, and a lot of trial and error with codegen
adjustments.
The biggest hurdle was figuring out how to continue to support coverage
results for unused functions and generics. Rust's coverage results have
three advantages over Clang's coverage results:
1. Rust's coverage map does not include any overlapping code regions,
making coverage counting unambiguous.
2. Rust generates coverage results (showing zero counts) for all unused
functions, including generics. (Clang does not generate coverage for
uninstantiated template functions.)
3. Rust's unused functions produce minimal stubbed functions in LLVM IR,
sufficient for including in the coverage results; while Clang must
generate the complete LLVM IR for each unused function, even though
it will never be called.
This PR removes the previous hack of attempting to inject coverage into
some other existing function instance, and generates dedicated instances
for each unused function. This change, and a few other adjustments
(similar to what is required for `-C link-dead-code`, but with lower
impact), makes it possible to support LLVM optimizations.
Fixes: #79651
Coverage report: "Unexecuted instantiation:..." for a generic function
from multiple crates
Fixed by removing the aforementioned hack. Some "Unexecuted
instantiation" notices are unavoidable, as explained in the
`used_crate.rs` test, but `-Zinstrument-coverage` has new options to
back off support for either unused generics, or all unused functions,
which avoids the notice, at the cost of less coverage of unused
functions.
Fixes: #82875
Invalid LLVM coverage data produced with crate brotli_decompressor
Fixed by disabling the LLVM function attribute that forces inlining, if
`-Z instrument-coverage` is enabled. This attribute is applied to
Rust functions with `#[inline(always)], and in some cases, the forced
inlining breaks coverage instrumentation and reports.
FYI: `@wesleywiser`
r? `@tmandry`
Adjusted LLVM codegen for code compiled with `-Zinstrument-coverage` to
address multiple, somewhat related issues.
Fixed a significant flaw in prior coverage solution: Every counter
generated a new counter variable, but there should have only been one
counter variable per function. This appears to have bloated .profraw
files significantly. (For a small program, it increased the size by
about 40%. I have not tested large programs, but there is anecdotal
evidence that profraw files were way too large. This is a good fix,
regardless, but hopefully it also addresses related issues.
Fixes: #82144
Invalid LLVM coverage data produced when compiled with -C opt-level=1
Existing tests now work up to at least `opt-level=3`. This required a
detailed analysis of the LLVM IR, comparisons with Clang C++ LLVM IR
when compiled with coverage, and a lot of trial and error with codegen
adjustments.
The biggest hurdle was figuring out how to continue to support coverage
results for unused functions and generics. Rust's coverage results have
three advantages over Clang's coverage results:
1. Rust's coverage map does not include any overlapping code regions,
making coverage counting unambiguous.
2. Rust generates coverage results (showing zero counts) for all unused
functions, including generics. (Clang does not generate coverage for
uninstantiated template functions.)
3. Rust's unused functions produce minimal stubbed functions in LLVM IR,
sufficient for including in the coverage results; while Clang must
generate the complete LLVM IR for each unused function, even though
it will never be called.
This PR removes the previous hack of attempting to inject coverage into
some other existing function instance, and generates dedicated instances
for each unused function. This change, and a few other adjustments
(similar to what is required for `-C link-dead-code`, but with lower
impact), makes it possible to support LLVM optimizations.
Fixes: #79651
Coverage report: "Unexecuted instantiation:..." for a generic function
from multiple crates
Fixed by removing the aforementioned hack. Some "Unexecuted
instantiation" notices are unavoidable, as explained in the
`used_crate.rs` test, but `-Zinstrument-coverage` has new options to
back off support for either unused generics, or all unused functions,
which avoids the notice, at the cost of less coverage of unused
functions.
Fixes: #82875
Invalid LLVM coverage data produced with crate brotli_decompressor
Fixed by disabling the LLVM function attribute that forces inlining, if
`-Z instrument-coverage` is enabled. This attribute is applied to
Rust functions with `#[inline(always)], and in some cases, the forced
inlining breaks coverage instrumentation and reports.
Make source-based code coverage compatible with MIR inlining
When codegenning code coverage use the instance that coverage data was
originally generated for, to ensure basic level of compatibility with
MIR inlining.
Fixes#83061
Implement (but don't use) valtree and refactor in preparation of use
This PR does not cause any functional change. It refactors various things that are needed to make valtrees possible. This refactoring got big enough that I decided I'd want it reviewed as a PR instead of trying to make one huge PR with all the changes.
cc `@rust-lang/wg-const-eval` on the following commits:
* 2027184 implement valtree
* eeecea9 fallible Scalar -> ScalarInt
* 042f663 ScalarInt convenience methods
cc `@eddyb` on ef04a6d
cc `@rust-lang/wg-mir-opt` for cf1700c (`mir::Constant` can now represent either a `ConstValue` or a `ty::Const`, and it is totally possible to have two different representations for the same value)
When codegenning code coverage use the instance that coverage data was
originally generated for, to ensure basic level of compatibility with
MIR inlining.
Remove the -Zinsert-sideeffect
This removes all of the code we had in place to work-around LLVM's
handling of forward progress. From this removal excluded is a workaround
where we'd insert a `sideeffect` into clearly infinite loops such as
`loop {}`. This code remains conditionally effective when the LLVM
version is earlier than 12.0, which fixed the forward progress related
miscompilations at their root.
This removes all of the code we had in place to work-around LLVM's
handling of forward progress. From this removal excluded is a workaround
where we'd insert a `sideeffect` into clearly infinite loops such as
`loop {}`. This code remains conditionally effective when the LLVM
version is earlier than 12.0, which fixed the forward progress related
miscompilations at their root.
Store HIR attributes in a side table
Same idea as #72015 but for attributes.
The objective is to reduce incr-comp invalidations due to modified attributes.
Notably, those due to modified doc comments.
Implementation:
- collect attributes during AST->HIR lowering, in `LocalDefId -> ItemLocalId -> &[Attributes]` nested tables;
- access the attributes through a `hir_owner_attrs` query;
- local refactorings to use this access;
- remove `attrs` from HIR data structures one-by-one.
Change in behaviour:
- the HIR visitor traverses all attributes at once instead of parent-by-parent;
- attribute arrays are sometimes duplicated: for statements and variant constructors;
- as a consequence, attributes are marked as used after unused-attribute lint emission to avoid duplicate lints.
~~Current bug: the lint level is not correctly applied in `std::backtrace_rs`, triggering an unused attribute warning on `#![no_std]`. I welcome suggestions.~~
This updates all places where match branches check on StatementKind or UseContext.
This doesn't properly implement them, but adds TODOs where they are, and also adds some best
guesses to what they should be in some cases.
I'm still not totally sure if this is the right way to implement the memcpy, but that portion
compiles correctly now. Now to fix the compile errors everywhere else :).
Implement NOOP_METHOD_CALL lint
Implements the beginnings of https://github.com/rust-lang/lang-team/issues/67 - a lint for detecting noop method calls (e.g, calling `<&T as Clone>::clone()` when `T: !Clone`).
This PR does not fully realize the vision and has a few limitations that need to be addressed either before merging or in subsequent PRs:
* [ ] No UFCS support
* [ ] The warning message is pretty plain
* [ ] Doesn't work for `ToOwned`
The implementation uses [`Instance::resolve`](https://doc.rust-lang.org/nightly/nightly-rustc/rustc_middle/ty/instance/struct.Instance.html#method.resolve) which is normally later in the compiler. It seems that there are some invariants that this function relies on that we try our best to respect. For instance, it expects substitutions to have happened, which haven't yet performed, but we check first for `needs_subst` to ensure we're dealing with a monomorphic type.
Thank you to ```@davidtwco,``` ```@Aaron1011,``` and ```@wesleywiser``` for helping me at various points through out this PR ❤️.
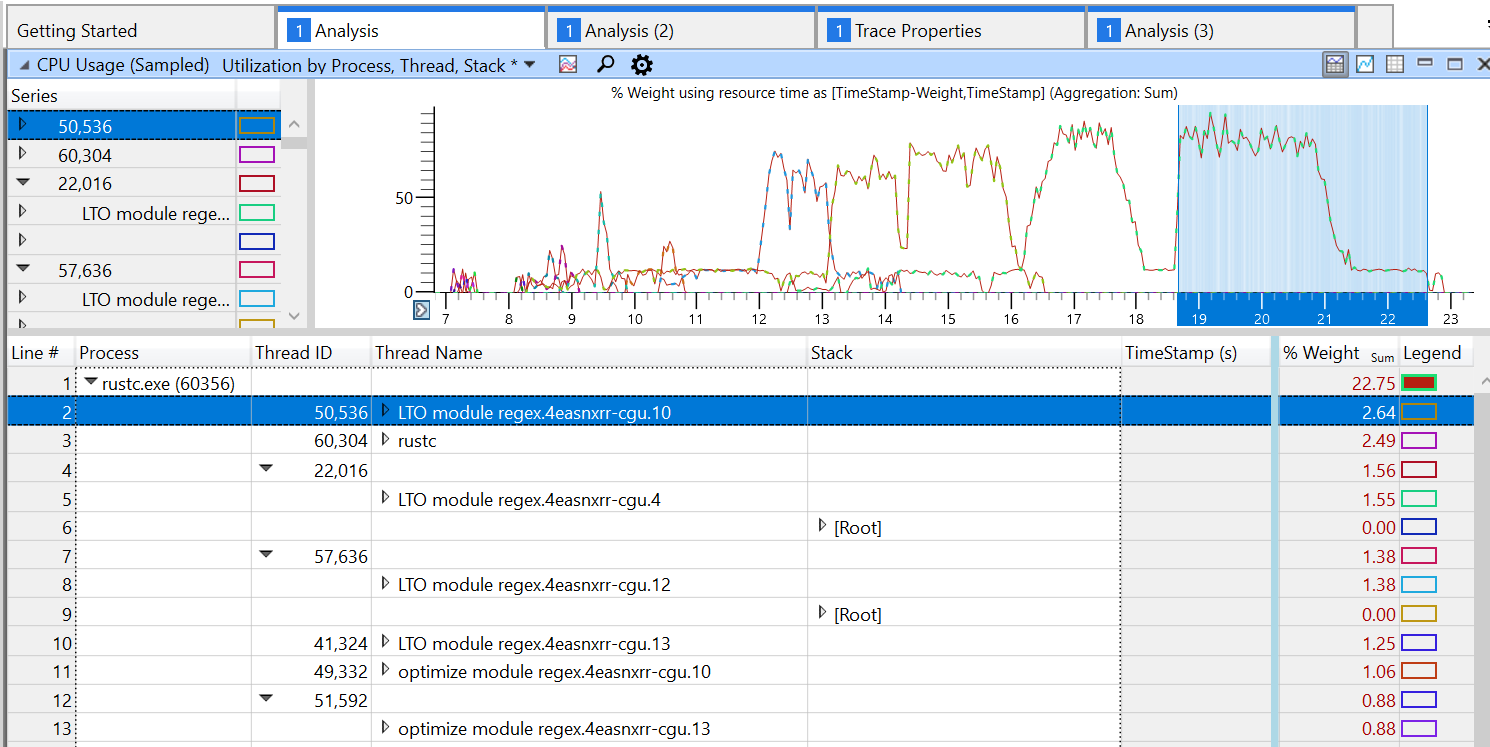
Set codegen thread names
Set names on threads spawned during codegen. Various debugging and profiling tools can take advantage of this to show a more useful identifier for threads.
For example, gdb will show thread names in `info threads`:
```
(gdb) info threads
Id Target Id Frame
1 Thread 0x7fffefa7ec40 (LWP 2905) "rustc" __pthread_clockjoin_ex (threadid=140737214134016, thread_return=0x0, clockid=<optimized out>, abstime=<optimized out>, block=<optimized out>)
at pthread_join_common.c:145
2 Thread 0x7fffefa7b700 (LWP 2957) "rustc" 0x00007ffff125eaa8 in llvm::X86_MC::initLLVMToSEHAndCVRegMapping(llvm::MCRegisterInfo*) ()
from /home/wesley/.rustup/toolchains/stage1/lib/librustc_driver-f866439e29074957.so
3 Thread 0x7fffeef0f700 (LWP 3116) "rustc" futex_wait_cancelable (private=0, expected=0, futex_word=0x7fffe8602ac8) at ../sysdeps/nptl/futex-internal.h:183
* 4 Thread 0x7fffeed0e700 (LWP 3123) "rustc" rustc_codegen_ssa:🔙:write::spawn_work (cgcx=..., work=...) at /home/wesley/code/rust/rust/compiler/rustc_codegen_ssa/src/back/write.rs:1573
6 Thread 0x7fffe113b700 (LWP 3150) "opt foof.7rcbfp" 0x00007ffff2940e62 in llvm::CallGraph::populateCallGraphNode(llvm::CallGraphNode*) ()
from /home/wesley/.rustup/toolchains/stage1/lib/librustc_driver-f866439e29074957.so
8 Thread 0x7fffe0d39700 (LWP 3158) "opt foof.7rcbfp" 0x00007fffefe8998e in malloc_consolidate (av=av@entry=0x7ffe2c000020) at malloc.c:4492
9 Thread 0x7fffe0f3a700 (LWP 3162) "opt foof.7rcbfp" 0x00007fffefef27c4 in __libc_open64 (file=0x7fffe0f38608 "foof.foof.7rcbfp3g-cgu.6.rcgu.o", oflag=524865) at ../sysdeps/unix/sysv/linux/open64.c:48
(gdb)
```
and Windows Performance Analyzer will also show this information when profiling:
rustc_codegen_ssa: tune codegen according to available concurrency
This change tunes ahead-of-time codegening according to the amount of
concurrency available, rather than according to the number of CPUs on
the system. This can lower memory usage by reducing the number of
compiled LLVM modules in memory at once, particularly across several
rustc instances.
Previously, each rustc instance would assume that it should codegen
ahead of time to meet the demand of number-of-CPUs workers. But often, a
rustc instance doesn't have nearly that much concurrency available to
it, because the concurrency availability is split, via the jobserver,
across all active rustc instances spawned by the driving cargo process,
and is further limited by the `-j` flag argument. Therefore, each rustc
might have had several times the number of LLVM modules in memory than
it really needed to meet demand. If the modules were large, the effect
on memory usage would be noticeable.
With this change, the required amount of ahead-of-time codegen scales up
with the actual number of workers running within a rustc instance. Note
that the number of workers running can be less than the actual
concurrency available to a rustc instance. However, if more concurrency
is actually available, workers are spun up quickly as job tokens are
acquired, and the ahead-of-time codegen scales up quickly as well.
Set path of the compile unit to the source directory
As part of the effort to implement split dwarf debug info, we ended up
setting the compile unit location to the output directory rather than
the source directory. Furthermore, it seems like we failed to remap the
prefixes for this as well!
The desired behaviour is to instead set the `DW_AT_GNU_dwo_name` to a
path relative to compiler's working directory. This still allows
debuggers to find the split dwarf files, while not changing the
behaviour of the code that is compiling with regular debug info, and not
changing the compiler's behaviour with regards to reproducibility.
Fixes#82074
cc `@alexcrichton` `@davidtwco`
remove redundant option/result wrapping of return values
If a function always returns `Ok(something)`, we can return `something` directly and remove the corresponding error handling in the callers.
clippy::unnecessary_wraps
Add new `rustc` target for Arm64 machines that can target the iphonesimulator
This PR lands a new target (`aarch64-apple-ios-sim`) that targets arm64 iphone simulator, previously unreachable from Apple Silicon machines.
resolves#81632
r? `@shepmaster`
{kind=link}