Implement intrinsics with fallback bodies
fixes#93145 (though we can port many more intrinsics)
cc #63585
The way this works is that the backend logic for generating custom code for intrinsics has been made fallible. The only failure path is "this intrinsic is unknown". The `Instance` (that was `InstanceDef::Intrinsic`) then gets converted to `InstanceDef::Item`, which represents the fallback body. A regular function call to that body is then codegenned. This is currently implemented for
* codegen_ssa (so llvm and gcc)
* codegen_cranelift
other backends will need to adjust, but they can just keep doing what they were doing if they prefer (though adding new intrinsics to the compiler will then require them to implement them, instead of getting the fallback body).
cc `@scottmcm` `@WaffleLapkin`
### todo
* [ ] miri support
* [x] default intrinsic name to name of function instead of requiring it to be specified in attribute
* [x] make sure that the bodies are always available (must be collected for metadata)
Subdiagnostics don't need to be lazily translated, they can always be
eagerly translated. Eager translation is slightly more complex as we need
to have a `DiagCtxt` available to perform the translation, which involves
slightly more threading of that context.
This slight increase in complexity should enable later simplifications -
like passing `DiagCtxt` into `AddToDiagnostic` and moving Fluent messages
into the diagnostic structs rather than having them in separate files
(working on that was what led to this change).
Signed-off-by: David Wood <david@davidtw.co>
For some cases where it's clear that an error has already occurred,
e.g.:
- there's a comment stating exactly that, or
- things like HIR lowering, where we are lowering an error kind
The commit also tweaks some comments around delayed bug sites.
`cargo update`
Run `cargo update`, with some pinning and fixes necessitated by that. This *should* unblock #112865
There's a couple of places where I only pinned a dependency in one location - this seems like a bit of a hack, but better than duplicating the FIXME across all `Cargo.toml` where a dependency is introduced.
cc `@Nilstrieb`
Dejargonize `subst`
In favor of #110793, replace almost every occurence of `subst` and `substitution` from rustc codes, but they still remains in subtrees under `src/tools/` like clippy and test codes (I'd like to replace them after this)
The check within changed from `delay_span_bug` to `delay_good_path_bug`
in #110476, and removing the check altogether was considered. It's a
very weak sanity check and gets in the way of removing good path delayed
bugs altogether, so this PR just removes it.
Allow restricted trait impls under `#[allow_internal_unstable(min_specialization)]`
This is a follow-up to #119963 and a companion to #120866, though it can land independently from the latter.
---
We have several compiler crates that only enable `#[feature(min_specialization)]` because it is required by their expansions of `newtype_index!`, in order to implement traits marked with `#[rustc_specialization_trait]`.
This PR allows those traits to be implemented internally by macros with `#[allow_internal_unstable(min_specialization)]`, without needing specialization to be enabled in the enclosing crate.
Harmonize `AsyncFn` implementations, make async closures conditionally impl `Fn*` traits
This PR implements several changes to the built-in and libcore-provided implementations of `Fn*` and `AsyncFn*` to address two problems:
1. async closures do not implement the `Fn*` family traits, leading to breakage: https://crater-reports.s3.amazonaws.com/pr-120361/index.html
2. *references* to async closures do not implement `AsyncFn*`, as a consequence of the existing blanket impls of the shape `AsyncFn for F where F: Fn, F::Output: Future`.
In order to fix (1.), we implement `Fn` traits appropriately for async closures. It turns out that async closures can:
* always implement `FnOnce`, meaning that they're drop-in compatible with `FnOnce`-bound combinators like `Option::map`.
* conditionally implement `Fn`/`FnMut` if they have no captures, which means that existing usages of async closures should *probably* work without breakage (crater checking this: https://github.com/rust-lang/rust/pull/120712#issuecomment-1930587805).
In order to fix (2.), we make all of the built-in callables implement `AsyncFn*` via built-in impls, and instead adjust the blanket impls for `AsyncFn*` provided by libcore to match the blanket impls for `Fn*`.
These crates all needed specialization for `newtype_index!`, which will no
longer be necessary when the current nightly eventually becomes the next
bootstrap compiler.
Fix `ErrorGuaranteed` unsoundness with stash/steal.
When you stash an error, the error count is incremented. You can then use the non-zero error count to get an `ErrorGuaranteed`. You can then steal the error, which decrements the error count. You can then cancel the error.
Example code:
```
fn unsound(dcx: &DiagCtxt) -> ErrorGuaranteed {
let sp = rustc_span::DUMMY_SP;
let k = rustc_errors::StashKey::Cycle;
dcx.struct_err("bogus").stash(sp, k); // increment error count on stash
let guar = dcx.has_errors().unwrap(); // ErrorGuaranteed from error count > 0
let err = dcx.steal_diagnostic(sp, k).unwrap(); // decrement error count on steal
err.cancel(); // cancel error
guar // ErrorGuaranteed with no error emitted!
}
```
This commit fixes the problem in the simplest way: by not counting stashed errors in `DiagCtxt::{err_count,has_errors}`.
However, just doing this without any other changes leads to over 40 ui test failures. Mostly because of uninteresting extra errors (many saying "type annotations needed" when type inference fails), and in a few cases, due to delayed bugs causing ICEs when no normal errors are printed.
To fix these, this commit adds `DiagCtxt::stashed_err_count`, and uses it in three places alongside `DiagCtxt::{has_errors,err_count}`. It's dodgy to rely on it, because unlike `DiagCtxt::err_count` it can go up and down. But it's needed to preserve existing behaviour, and at least the three places that need it are now obvious.
r? oli-obk
Invert diagnostic lints.
That is, change `diagnostic_outside_of_impl` and `untranslatable_diagnostic` from `allow` to `deny`, because more than half of the compiler has been converted to use translated diagnostics.
This commit removes more `deny` attributes than it adds `allow` attributes, which proves that this change is warranted.
r? ````@davidtwco````
When you stash an error, the error count is incremented. You can then
use the non-zero error count to get an `ErrorGuaranteed`. You can then
steal the error, which decrements the error count. You can then cancel
the error.
Example code:
```
fn unsound(dcx: &DiagCtxt) -> ErrorGuaranteed {
let sp = rustc_span::DUMMY_SP;
let k = rustc_errors::StashKey::Cycle;
dcx.struct_err("bogus").stash(sp, k); // increment error count on stash
let guar = dcx.has_errors().unwrap(); // ErrorGuaranteed from error count > 0
let err = dcx.steal_diagnostic(sp, k).unwrap(); // decrement error count on steal
err.cancel(); // cancel error
guar // ErrorGuaranteed with no error emitted!
}
```
This commit fixes the problem in the simplest way: by not counting
stashed errors in `DiagCtxt::{err_count,has_errors}`.
However, just doing this without any other changes leads to over 40 ui
test failures. Mostly because of uninteresting extra errors (many saying
"type annotations needed" when type inference fails), and in a few
cases, due to delayed bugs causing ICEs when no normal errors are
printed.
To fix these, this commit adds `DiagCtxt::stashed_err_count`, and uses
it in three places alongside `DiagCtxt::{has_errors,err_count}`. It's
dodgy to rely on it, because unlike `DiagCtxt::err_count` it can go up
and down. But it's needed to preserve existing behaviour, and at least
the three places that need it are now obvious.
Remove unused args from functions
`#[instrument]` suppresses the unused arguments from a function, *and* suppresses unused methods too! This PR removes things which are only used via `#[instrument]` calls, and fixes some other errors (privacy?) that I will comment inline.
It's possible that some of these arguments were being passed in for the purposes of being instrumented, but I am unconvinced by most of them.
Introduce `enter_forall` to supercede `instantiate_binder_with_placeholders`
r? `@lcnr`
Long term we'd like to experiment with decrementing the universe count after "exiting" binders so that we do not end up creating infer vars in non-root universes even when they logically reside in the root universe. The fact that we dont do this currently results in a number of issues in the new trait solver where we consider goals to be ambiguous because otherwise it would require lowering the universe of an infer var. i.e. the goal `?x.0 eq <T as Trait<?y.1>>::Assoc` where the alias is rigid would not be able to instantiate `?x` with the alias as there would be a universe error.
This PR is the first-ish sort of step towards being able to implement this as eventually we would want to decrement the universe in `enter_forall`. Unfortunately its Difficult to actually implement decrementing universes nicely so this is a separate step which moves us closer to the long term goal ✨
Normalize type outlives obligations in NLL for new solver
Normalize the type outlives assumptions and obligations in MIR borrowck. This should fix any of the lazy-norm-related MIR borrowck problems.
Also some cleanups from last PR:
1. Normalize obligations in a loop in lexical region resolution
2. Use `deeply_normalize_with_skipped_universes` in lexical resolution since we may have, e.g. `for<'a> Alias<'a>: 'b`.
r? lcnr
That is, change `diagnostic_outside_of_impl` and
`untranslatable_diagnostic` from `allow` to `deny`, because more than
half of the compiler has be converted to use translated diagnostics.
This commit removes more `deny` attributes than it adds `allow`
attributes, which proves that this change is warranted.
- `emitted_at` isn't used outside the crate.
- `code` and `messages` are public fields, so there's no point have
trivial getters/setters for them.
- `suggestions` is public, so the comment about "functionality on
`Diagnostic`" isn't needed.
Normalize region obligation in lexical region resolution with next-gen solver
This normalizes region obligations when we `resolve_regions`, since they may be unnormalized with deferred projection equality.
It's pretty hard to add tests that exercise this without also triggering MIR borrowck errors (because we don't normalize there yet). I've added one test with two revisions that should test that we both 1. normalize region obligations in the param env, and 2. normalize registered region obligations during lexical region resolution.
Remove various `has_errors` or `err_count` uses
follow up to https://github.com/rust-lang/rust/pull/119895
r? `@nnethercote` since you recently did something similar.
There are so many more of these, but I wanted to get a PR out instead of growing the commit list indefinitely. The commits all work on their own and can be reviewed commit by commit.
Because it's almost always static.
This makes `impl IntoDiagnosticArg for DiagnosticArgValue` trivial,
which is nice.
There are a few diagnostics constructed in
`compiler/rustc_mir_build/src/check_unsafety.rs` and
`compiler/rustc_mir_transform/src/errors.rs` that now need symbols
converted to `String` with `to_string` instead of `&str` with `as_str`,
but that' no big deal, and worth it for the simplifications elsewhere.
Error codes are integers, but `String` is used everywhere to represent
them. Gross!
This commit introduces `ErrCode`, an integral newtype for error codes,
replacing `String`. It also introduces a constant for every error code,
e.g. `E0123`, and removes the `error_code!` macro. The constants are
imported wherever used with `use rustc_errors::codes::*`.
With the old code, we have three different ways to specify an error code
at a use point:
```
error_code!(E0123) // macro call
struct_span_code_err!(dcx, span, E0123, "msg"); // bare ident arg to macro call
\#[diag(name, code = "E0123")] // string
struct Diag;
```
With the new code, they all use the `E0123` constant.
```
E0123 // constant
struct_span_code_err!(dcx, span, E0123, "msg"); // constant
\#[diag(name, code = E0123)] // constant
struct Diag;
```
The commit also changes the structure of the error code definitions:
- `rustc_error_codes` now just defines a higher-order macro listing the
used error codes and nothing else.
- Because that's now the only thing in the `rustc_error_codes` crate, I
moved it into the `lib.rs` file and removed the `error_codes.rs` file.
- `rustc_errors` uses that macro to define everything, e.g. the error
code constants and the `DIAGNOSTIC_TABLES`. This is in its new
`codes.rs` file.
When encountering a type mismatch error involving `dyn Trait`, mention
the existence of boxed trait objects if the other type involved
implements `Trait`.
Partially addresses #102629.
Provide structured suggestion to use trait objects in some cases of `if` arm type divergence
```
error[E0308]: `if` and `else` have incompatible types
--> $DIR/suggest-box-on-divergent-if-else-arms.rs:15:9
|
LL | let _ = if true {
| _____________-
LL | | Struct
| | ------ expected because of this
LL | | } else {
LL | | foo()
| | ^^^^^ expected `Struct`, found `Box<dyn Trait>`
LL | | };
| |_____- `if` and `else` have incompatible types
|
= note: expected struct `Struct`
found struct `Box<dyn Trait>`
help: `Struct` implements `Trait` so you can box it to coerce to the trait object `Box<dyn Trait>`
|
LL | Box::new(Struct)
| +++++++++ +
error[E0308]: `if` and `else` have incompatible types
--> $DIR/suggest-box-on-divergent-if-else-arms.rs:20:9
|
LL | let _ = if true {
| _____________-
LL | | foo()
| | ----- expected because of this
LL | | } else {
LL | | Struct
| | ^^^^^^ expected `Box<dyn Trait>`, found `Struct`
LL | | };
| |_____- `if` and `else` have incompatible types
|
= note: expected struct `Box<dyn Trait>`
found struct `Struct`
= note: for more on the distinction between the stack and the heap, read https://doc.rust-lang.org/book/ch15-01-box.html, https://doc.rust-lang.org/rust-by-example/std/box.html, and https://doc.rust-lang.org/std/boxed/index.html
help: store this in the heap by calling `Box::new`
|
LL | Box::new(Struct)
| +++++++++ +
error[E0308]: `if` and `else` have incompatible types
--> $DIR/suggest-box-on-divergent-if-else-arms.rs:25:9
|
LL | fn bar() -> impl Trait {
| ---------- the found opaque type
...
LL | let _ = if true {
| _____________-
LL | | Struct
| | ------ expected because of this
LL | | } else {
LL | | bar()
| | ^^^^^ expected `Struct`, found opaque type
LL | | };
| |_____- `if` and `else` have incompatible types
|
= note: expected struct `Struct`
found opaque type `impl Trait`
help: `Struct` implements `Trait` so you can box both arms and coerce to the trait object `Box<dyn Trait>`
|
LL ~ Box::new(Struct) as Box<dyn Trait>
LL | } else {
LL ~ Box::new(bar())
|
error[E0308]: `if` and `else` have incompatible types
--> $DIR/suggest-box-on-divergent-if-else-arms.rs:30:9
|
LL | fn bar() -> impl Trait {
| ---------- the expected opaque type
...
LL | let _ = if true {
| _____________-
LL | | bar()
| | ----- expected because of this
LL | | } else {
LL | | Struct
| | ^^^^^^ expected opaque type, found `Struct`
LL | | };
| |_____- `if` and `else` have incompatible types
|
= note: expected opaque type `impl Trait`
found struct `Struct`
help: `Struct` implements `Trait` so you can box both arms and coerce to the trait object `Box<dyn Trait>`
|
LL ~ Box::new(bar()) as Box<dyn Trait>
LL | } else {
LL ~ Box::new(Struct)
|
```
Partially address #102629.
When encountering
```rust
let _ = if true {
Struct
} else {
foo() // -> Box<dyn Trait>
};
```
if `Struct` implements `Trait`, suggest boxing the then arm tail expression.
Part of #102629.
We have several methods indicating the presence of errors, lint errors,
and delayed bugs. I find it frustrating that it's very unclear which one
you should use in any particular spot. This commit attempts to instill a
basic principle of "use the least general one possible", because that
reflects reality in practice -- `has_errors` is the least general one
and has by far the most uses (esp. via `abort_if_errors`).
Specifics:
- Add some comments giving some usage guidelines.
- Prefer `has_errors` to comparing `err_count` to zero.
- Remove `has_errors_or_span_delayed_bugs` because it's a weird one: in
the cases where we need to count delayed bugs, we should really be
counting lint errors as well.
- Rename `is_compilation_going_to_fail` as
`has_errors_or_lint_errors_or_span_delayed_bugs`, for consistency with
`has_errors` and `has_errors_or_lint_errors`.
- Change a few other `has_errors_or_lint_errors` calls to `has_errors`,
as per the "least general" principle.
This didn't turn out to be as neat as I hoped when I started, but I
think it's still an improvement.
Expose Obligations created during type inference.
This PR is a first pass at exposing the trait obligations generated and solved for during the type-check progress. Exposing these obligations allows for rustc plugins to use the public interface for proof trees (provided by the next gen trait solver).
The changes proposed track *all* obligations during the type-check process, this is desirable to not only look at the trees of failed obligations, but also those of successfully proved obligations. This feature is placed behind an unstable compiler option `track-trait-obligations` which should be used together with the `next-solver` option. I should note that the main interface is the function `inspect_typeck` made public in `rustc_hir_typeck/src/lib.rs` which allows the caller to provide a callback granting access to the `FnCtxt`.
r? `@lcnr`
Pass each obligation to an fn callback with its respective inference context. This avoids needing to keep around copies of obligations or inference contexts.
Specify usability of inspect_typeck in comment.
Rework how diagnostic lints are stored.
`Diagnostic::code` has the type `DiagnosticId`, which has `Error` and
`Lint` variants. Plus `Diagnostic::is_lint` is a bool, which should be
redundant w.r.t. `Diagnostic::code`.
Seems simple. Except it's possible for a lint to have an error code, in
which case its `code` field is recorded as `Error`, and `is_lint` is
required to indicate that it's a lint. This is what happens with
`derive(LintDiagnostic)` lints. Which means those lints don't have a
lint name or a `has_future_breakage` field because those are stored in
the `DiagnosticId::Lint`.
It's all a bit messy and confused and seems unintentional.
This commit:
- removes `DiagnosticId`;
- changes `Diagnostic::code` to `Option<String>`, which means both
errors and lints can straightforwardly have an error code;
- changes `Diagnostic::is_lint` to `Option<IsLint>`, where `IsLint` is a
new type containing a lint name and a `has_future_breakage` bool, so
all lints can have those, error code or not.
r? `@oli-obk`
Make sure to instantiate placeholders correctly in old solver
When creating the query substitution guess for an input placeholder type like `!1_T` (in universe 1), we were guessing the response substitution with something like `!0_T`. This failed to unify with `!1_T`, causing an ICE.
This PR reworks the query substitution guess code to work a bit more like the new solver. I'm *pretty* sure this is correct, though I'd really appreciate some scrutiny from someone (*cough* lcnr) who knows a bit more about query instantiation :)
Fixes#119941
r? lcnr
`OutputTypeParameterMismatch` -> `SignatureMismatch`
I'm probably missing something that made this rename more complicated. What did you end up getting stuck on when renaming this selection error, `@lcnr?`
**also** I renamed the `FulfillmentErrorCode` variants. This is just churn but I wanted to do it forever. I can move it out of this PR if desired.
r? lcnr
Silence some follow-up errors [3/x]
this is one piece of the requested cleanups from https://github.com/rust-lang/rust/pull/117449
Keep error types around, even in obligations.
These help silence follow-up errors, as we now figure out that some types (most notably inference variables) are equal to an error type.
But it also allows figuring out more types in the presence of errors, possibly causing more errors.
`Diagnostic::code` has the type `DiagnosticId`, which has `Error` and
`Lint` variants. Plus `Diagnostic::is_lint` is a bool, which should be
redundant w.r.t. `Diagnostic::code`.
Seems simple. Except it's possible for a lint to have an error code, in
which case its `code` field is recorded as `Error`, and `is_lint` is
required to indicate that it's a lint. This is what happens with
`derive(LintDiagnostic)` lints. Which means those lints don't have a
lint name or a `has_future_breakage` field because those are stored in
the `DiagnosticId::Lint`.
It's all a bit messy and confused and seems unintentional.
This commit:
- removes `DiagnosticId`;
- changes `Diagnostic::code` to `Option<String>`, which means both
errors and lints can straightforwardly have an error code;
- changes `Diagnostic::is_lint` to `Option<IsLint>`, where `IsLint` is a
new type containing a lint name and a `has_future_breakage` bool, so
all lints can have those, error code or not.
In #119606 I added them and used a `_mv` suffix, but that wasn't great.
A `with_` prefix has three different existing uses.
- Constructors, e.g. `Vec::with_capacity`.
- Wrappers that provide an environment to execute some code, e.g.
`with_session_globals`.
- Consuming chaining methods, e.g. `Span::with_{lo,hi,ctxt}`.
The third case is exactly what we want, so this commit changes
`DiagnosticBuilder::foo_mv` to `DiagnosticBuilder::with_foo`.
Thanks to @compiler-errors for the suggestion.
We have `span_delayed_bug` and often pass it a `DUMMY_SP`. This commit
adds `delayed_bug`, which matches pairs like `err`/`span_err` and
`warn`/`span_warn`.
Because it takes an error code after the span. This avoids the confusing
overlap with the `DiagCtxt::struct_span_err` method, which doesn't take
an error code.
unify query canonicalization mode
Exclude from canonicalization only the static lifetimes that appear in the param env because of #118965 . Any other occurrence can be canonicalized safely AFAICT.
r? `@lcnr`
The existing uses are replaced in one of three ways.
- In a function that also has calls to `emit`, just rearrange the code
so that exactly one of `delay_as_bug` or `emit` is called on every
path.
- In a function returning a `DiagnosticBuilder`, use
`downgrade_to_delayed_bug`. That's good enough because it will get
emitted later anyway.
- In `unclosed_delim_err`, one set of errors is being replaced with
another set, so just cancel the original errors.
This works for most of its call sites. This is nice, because `emit` very
much makes sense as a consuming operation -- indeed,
`DiagnosticBuilderState` exists to ensure no diagnostic is emitted
twice, but it uses runtime checks.
For the small number of call sites where a consuming emit doesn't work,
the commit adds `DiagnosticBuilder::emit_without_consuming`. (This will
be removed in subsequent commits.)
Likewise, `emit_unless` becomes consuming. And `delay_as_bug` becomes
consuming, while `delay_as_bug_without_consuming` is added (which will
also be removed in subsequent commits.)
All this requires significant changes to `DiagnosticBuilder`'s chaining
methods. Currently `DiagnosticBuilder` method chaining uses a
non-consuming `&mut self -> &mut Self` style, which allows chaining to
be used when the chain ends in `emit()`, like so:
```
struct_err(msg).span(span).emit();
```
But it doesn't work when producing a `DiagnosticBuilder` value,
requiring this:
```
let mut err = self.struct_err(msg);
err.span(span);
err
```
This style of chaining won't work with consuming `emit` though. For
that, we need to use to a `self -> Self` style. That also would allow
`DiagnosticBuilder` production to be chained, e.g.:
```
self.struct_err(msg).span(span)
```
However, removing the `&mut self -> &mut Self` style would require that
individual modifications of a `DiagnosticBuilder` go from this:
```
err.span(span);
```
to this:
```
err = err.span(span);
```
There are *many* such places. I have a high tolerance for tedious
refactorings, but even I gave up after a long time trying to convert
them all.
Instead, this commit has it both ways: the existing `&mut self -> Self`
chaining methods are kept, and new `self -> Self` chaining methods are
added, all of which have a `_mv` suffix (short for "move"). Changes to
the existing `forward!` macro lets this happen with very little
additional boilerplate code. I chose to add the suffix to the new
chaining methods rather than the existing ones, because the number of
changes required is much smaller that way.
This doubled chainging is a bit clumsy, but I think it is worthwhile
because it allows a *lot* of good things to subsequently happen. In this
commit, there are many `mut` qualifiers removed in places where
diagnostics are emitted without being modified. In subsequent commits:
- chaining can be used more, making the code more concise;
- more use of chaining also permits the removal of redundant diagnostic
APIs like `struct_err_with_code`, which can be replaced easily with
`struct_err` + `code_mv`;
- `emit_without_diagnostic` can be removed, which simplifies a lot of
machinery, removing the need for `DiagnosticBuilderState`.
Use `resolutions(()).effective_visiblities` to avoid cycle errors in `report_object_error`
Inside of `report_object_error`, using the `effective_visibilities` query causes cycles since it calls `type_of`, which itself may call `typeck`, which may end up reporting its own object-safety errors.
Fixes#119346Fixes#119502
Tweak suggestions for bare trait used as a type
```
error[E0782]: trait objects must include the `dyn` keyword
--> $DIR/not-on-bare-trait-2021.rs:11:11
|
LL | fn bar(x: Foo) -> Foo {
| ^^^
|
help: use a generic type parameter, constrained by the trait `Foo`
|
LL | fn bar<T: Foo>(x: T) -> Foo {
| ++++++++ ~
help: you can also use `impl Foo`, but users won't be able to specify the type paramer when calling the `fn`, having to rely exclusively on type inference
|
LL | fn bar(x: impl Foo) -> Foo {
| ++++
help: alternatively, use a trait object to accept any type that implements `Foo`, accessing its methods at runtime using dynamic dispatch
|
LL | fn bar(x: &dyn Foo) -> Foo {
| ++++
error[E0782]: trait objects must include the `dyn` keyword
--> $DIR/not-on-bare-trait-2021.rs:11:19
|
LL | fn bar(x: Foo) -> Foo {
| ^^^
|
help: use `impl Foo` to return an opaque type, as long as you return a single underlying type
|
LL | fn bar(x: Foo) -> impl Foo {
| ++++
help: alternatively, you can return an owned trait object
|
LL | fn bar(x: Foo) -> Box<dyn Foo> {
| +++++++ +
```
Fix#119525:
```
error[E0038]: the trait `Ord` cannot be made into an object
--> $DIR/bare-trait-dont-suggest-dyn.rs:3:33
|
LL | fn ord_prefer_dot(s: String) -> Ord {
| ^^^ `Ord` cannot be made into an object
|
note: for a trait to be "object safe" it needs to allow building a vtable to allow the call to be resolvable dynamically; for more information visit <https://doc.rust-lang.org/reference/items/traits.html#object-safety>
--> $SRC_DIR/core/src/cmp.rs:LL:COL
|
= note: the trait cannot be made into an object because it uses `Self` as a type parameter
::: $SRC_DIR/core/src/cmp.rs:LL:COL
|
= note: the trait cannot be made into an object because it uses `Self` as a type parameter
help: consider using an opaque type instead
|
LL | fn ord_prefer_dot(s: String) -> impl Ord {
| ++++
```
`Diagnostic` has 40 methods that return `&mut Self` and could be
considered setters. Four of them have a `set_` prefix. This doesn't seem
necessary for a type that implements the builder pattern. This commit
removes the `set_` prefixes on those four methods.
Implement constant propagation on top of MIR SSA analysis
This implements the idea I proposed in https://github.com/rust-lang/rust/pull/110719#issuecomment-1718324700
Based on https://github.com/rust-lang/rust/pull/109597
The value numbering "GVN" pass formulates each rvalue that appears in MIR with an abstract form (the `Value` enum), and assigns an integer `VnIndex` to each. This abstract form can be used to deduplicate values, reusing an earlier local that holds the same value instead of recomputing. This part is proposed in #109597.
From this abstract representation, we can perform more involved simplifications, for example in https://github.com/rust-lang/rust/pull/111344.
With the abstract representation `Value`, we can also attempt to evaluate each to a constant using the interpreter. This builds a `VnIndex -> OpTy` map. From this map, we can opportunistically replace an operand or a rvalue with a constant if their value has an associated `OpTy`.
The most relevant commit is [Evaluated computed values to constants.](2767c4912e)"
r? `@oli-obk`
rework `-Zverbose`
implements the changes described in https://github.com/rust-lang/compiler-team/issues/706
the first commit is only a name change from `-Zverbose` to `-Zverbose-internals` and does not change behavior. the second commit changes diagnostics.
possible follow up work:
- `ty::pretty` could print more info with `--verbose` than it does currently. `-Z verbose-internals` shows too much info in a way that's not helpful to users. michael had ideas about this i didn't fully understand: https://rust-lang.zulipchat.com/#narrow/stream/233931-t-compiler.2Fmajor-changes/topic/uplift.20some.20-Zverbose.20calls.20and.20rename.20to.E2.80.A6.20compiler-team.23706/near/408984200
- `--verbose` should imply `-Z write-long-types-to-disk=no`. the code in `ty_string_with_limit` should take `--verbose` into account (apparently this affects `Ty::sort_string`, i'm not familiar with this code). writing a file to disk should suggest passing `--verbose`.
r? `@compiler-errors` cc `@estebank`
`IntoDiagnostic` defaults to `ErrorGuaranteed`, because errors are the
most common diagnostic level. It makes sense to do likewise for the
closely-related (and much more widely used) `DiagnosticBuilder` type,
letting us write `DiagnosticBuilder<'a, ErrorGuaranteed>` as just
`DiagnosticBuilder<'a>`. This cuts over 200 lines of code due to many
multi-line things becoming single line things.
subtype_predicate: remove unnecessary probe
There is no reason to probe here. The failure either results in an actual type error, in which cases the probe is useless, or it is used inside of evaluate, in which case we're already inside of the `fn evaluation_probe`, so it is also not necessary.
Yeet unnecessary param envs
We don't need to pass in param-envs around in the lexical region resolution code (or in `MatchAgainstFreshVars` in the solver), since it is only used to eval some consts in `structurally_relate_tys` which I removed.
This is in preparation for normalizing the outlives clauses in `ParamEnv` for the new trait solver.
r? lcnr
This commit replaces this pattern:
```
err.into_diagnostic(dcx)
```
with this pattern:
```
dcx.create_err(err)
```
in a lot of places.
It's a little shorter, makes the error level explicit, avoids some
`IntoDiagnostic` imports, and is a necessary prerequisite for the next
commit which will add a `level` arg to `into_diagnostic`.
This requires adding `track_caller` on `create_err` to avoid mucking up
the output of `tests/ui/track-diagnostics/track4.rs`. It probably should
have been there already.
Collect lang items from AST, get rid of `GenericBound::LangItemTrait`
r? `@cjgillot`
cc #115178
Looking forward, the work to remove `QPath::LangItem` will also be significantly more difficult, but I plan on doing it as well. Specifically, we have to change:
1. A lot of `rustc_ast_lowering` for things like expr `..`
2. A lot of astconv, since we actually instantiate lang and non-lang paths quite differently.
3. A ton of diagnostics and clippy lints that are special-cased via `QPath::LangItem`
Meanwhile, it was pretty easy to remove `GenericBound::LangItemTrait`, so I just did that here.
cache param env canonicalization
Canonicalize ParamEnv only once and store it. Then whenever we try to canonicalize `ParamEnvAnd<'tcx, T>` we only have to canonicalize `T` and then merge the results.
Prelimiary results show ~3-4% savings in diesel and serde benchmarks.
Best to review commits individually. Some commits have a short description.
Initial implementation had a soundness bug (https://github.com/rust-lang/rust/pull/117749#issuecomment-1840453387) due to cache invalidation:
- When canonicalizing `Ty<'?0>` we first try to resolve region variables in the current InferCtxt which may have a constraint `?0 == 'static`. This means that we register `Ty<'?0> => Canonical<Ty<'static>>` in the cache, which is obviously incorrect in another inference context.
- This is fixed by not doing region resolution when canonicalizing the query *input* (vs. response), which is the only place where ParamEnv is used, and then in a later commit we *statically* guard against any form of inference variable resolution of the cached canonical ParamEnv's.
r? `@ghost`
This doesn't change behavior.
It should prevent unintentional resolution of inference variables
during canonicalization, which previously caused a soundness bug.
See PR description for more.
ParamEnv is canonicalized in *queries input* rather than query response.
In such case we don't "preserve universes" of canonical variable.
This means that `universe_map` always has the default value, which is
wasteful to store in the cache.
Renamings:
- find -> opt_hir_node
- get -> hir_node
- find_by_def_id -> opt_hir_node_by_def_id
- get_by_def_id -> hir_node_by_def_id
Fix rebase changes using removed methods
Use `tcx.hir_node_by_def_id()` whenever possible in compiler
Fix clippy errors
Fix compiler
Apply suggestions from code review
Co-authored-by: Vadim Petrochenkov <vadim.petrochenkov@gmail.com>
Add FIXME for `tcx.hir()` returned type about its removal
Simplify with with `tcx.hir_node_by_def_id`
remove redundant imports
detects redundant imports that can be eliminated.
for #117772 :
In order to facilitate review and modification, split the checking code and removing redundant imports code into two PR.
r? `@petrochenkov`
detects redundant imports that can be eliminated.
for #117772 :
In order to facilitate review and modification, split the checking code and
removing redundant imports code into two PR.
recurse into refs when comparing tys for diagnostics
before:

after:
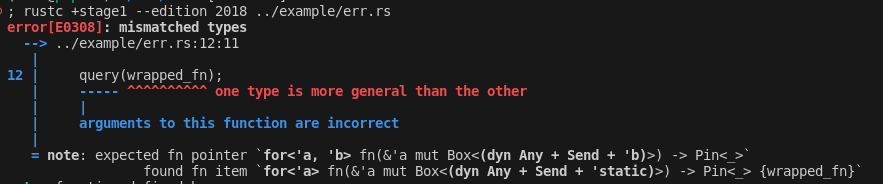
this diff from the test suite is also quite nice imo:
```diff
`@@` -4,8 +4,8 `@@` error[E0308]: mismatched types
LL | debug_assert_eq!(iter.next(), Some(value));
| ^^^^^^^^^^^ expected `Option<<I as Iterator>::Item>`, found `Option<&<I as Iterator>::Item>`
|
- = note: expected enum `Option<<I as Iterator>::Item>`
- found enum `Option<&<I as Iterator>::Item>`
+ = note: expected enum `Option<_>`
+ found enum `Option<&_>`
```
Unify `TraitRefs` and `PolyTraitRefs` in `ValuePairs`
I did this recently with `FnSigs` and `PolyFnSigs` but didn't think to do it with `TraitRefs` and `PolyTraitRefs`.
Currently we always do this:
```
use rustc_fluent_macro::fluent_messages;
...
fluent_messages! { "./example.ftl" }
```
But there is no need, we can just do this everywhere:
```
rustc_fluent_macro::fluent_messages! { "./example.ftl" }
```
which is shorter.
The `fluent_messages!` macro produces uses of
`crate::{D,Subd}iagnosticMessage`, which means that every crate using
the macro must have this import:
```
use rustc_errors::{DiagnosticMessage, SubdiagnosticMessage};
```
This commit changes the macro to instead use
`rustc_errors::{D,Subd}iagnosticMessage`, which avoids the need for the
imports.
Remove `HirId` from `QPath::LangItem`
Remove `HirId` from `QPath::LangItem`, since there was only *one* use-case (`ObligationCauseCode::AwaitableExpr`), which we can instead recover by walking the HIR tree.
Move EagerResolution to rustc_infer::infer::resolve
`EagerResolver` fits better in `rustc_infer::infer::resolver`.
Started to disentagle #118118 that has a lot of unrelated things.
r? `@compiler-errors` `@lcnr`
Cache flags for `ty::Const`
Not sure if this has been attempted yet, but worth a shot. It does make the code simpler in `rustc_type_ir`, since we can assume that consts have a `flags` method that is no-cost.
r? `@ghost`
Remove `PredicateKind::ClosureKind`
We don't need the `ClosureKind` predicate kind -- instead, `Fn`-family trait goals are left as ambiguous, and we only need to make progress on `FnOnce` projection goals for inference purposes.
This is similar to how we do confirmation of `Fn`-family trait and projection goals in the new trait solver, which also doesn't use the `ClosureKind` predicate.
Some hacky logic is added in the second commit so that we can keep the error messages the same.
Remove `-Zperf-stats`.
The included measurements have varied over the years. At one point there were quite a few more, but #49558 deleted a lot that were no longer used. Today there's just four, and it's a motley collection that doesn't seem particularly valuable.
I think it has been well and truly subsumed by self-profiling, which collects way more data.
r? `@wesleywiser`