debuginfo: Simplify TypeMap used during LLVM debuginfo generation.
This PR simplifies the TypeMap that is used in `rustc_codegen_llvm::debuginfo::metadata`. It was unnecessarily complicated because it was originally implemented when types were not yet normalized before codegen. So it did it's own normalization and kept track of multiple unnormalized types being mapped to a single unique id.
This PR is based on https://github.com/rust-lang/rust/pull/93503, which is not merged yet.
The PR also removes the arena used for allocating string ids and instead uses `InlinableString` from the [inlinable_string](https://crates.io/crates/inlinable_string) crate. That might not be the best choice, since that crate does not seem to be very actively maintained. The [flexible-string](https://crates.io/crates/flexible-string) crate would be an alternative.
r? `@ghost`
Use undef for (some) partially-uninit constants
There needs to be some limit to avoid perf regressions on large arrays
with undef in each element (see comment in the code).
Fixes: #84565
Original PR: #83698
Depends on LLVM 14: #93577
properly handle fat pointers to uninhabitable types
Calculate the pointee metadata size by using `tcx.struct_tail_erasing_lifetimes` instead of duplicating the logic in `fat_pointer_kind`. Open to alternatively suggestions on how to fix this.
Fixes#94149
r? ````@michaelwoerister```` since you touched this code last, I think!
Partially move cg_ssa towards using a single builder
Not all codegen backends can handle hopping between blocks well. For example Cranelift requires blocks to be terminated before switching to building a new block. Rust-gpu requires a `RefCell` to allow hopping between blocks and cg_gcc currently has a buggy implementation of hopping between blocks. This PR reduces the amount of cases where cg_ssa switches between blocks before they are finished and mostly fixes the block hopping in cg_gcc. (~~only `scalar_to_backend` doesn't handle it correctly yet in cg_gcc~~ fixed that one.)
`@antoyo` please review the cg_gcc changes.
Change `char` type in debuginfo to DW_ATE_UTF
Rust previously encoded the `char` type as DW_ATE_unsigned_char. The more appropriate encoding is `DW_ATE_UTF`.
Clang also uses the DW_ATE_UTF for `char32_t` in C++.
This fixes the display of the `char` type in the Windows debuggers. Without this change, the variable did not show in the locals window.
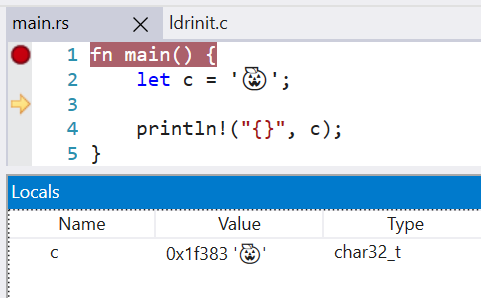
LLDB 13 is also able to display the char value, when before it failed with `need to add support for DW_TAG_base_type 'char' encoded with DW_ATE = 0x8, bit_size = 32`
r? `@wesleywiser`
Rust previously encoded the `char` type as DW_ATE_unsigned_char. The more
appropriate encoding is DW_ATE_UTF.
Clang uses this same debug encoding for char32_t.
This fixes the display of `char` types in Windows debuggers as well as LLDB.
The previous implementation was written before types were properly
normalized for code generation and had to assume a more complicated
relationship between types and their debuginfo -- generating separate
identifiers for debuginfo nodes that were based on normalized types.
Since types are now already normalized, we can use them as identifiers
for debuginfo nodes.
Improve `unused_unsafe` lint
I’m going to add some motivation and explanation below, particularly pointing the changes in behavior from this PR.
_Edit:_ Looking for existing issues, looks like this PR fixes#88260.
_Edit2:_ Now also contains code that closes#90776.
Main motivation: Fixes some issues with the current behavior. This PR is
more-or-less completely re-implementing the unused_unsafe lint; it’s also only
done in the MIR-version of the lint, the set of tests for the `-Zthir-unsafeck`
version no longer succeeds (and is thus disabled, see `lint-unused-unsafe.rs`).
On current nightly,
```rs
unsafe fn unsf() {}
fn inner_ignored() {
unsafe {
#[allow(unused_unsafe)]
unsafe {
unsf()
}
}
}
```
doesn’t create any warnings. This situation is not unrealistic to come by, the
inner `unsafe` block could e.g. come from a macro. Actually, this PR even
includes removal of one unused `unsafe` in the standard library that was missed
in a similar situation. (The inner `unsafe` coming from an external macro hides
the warning, too.)
The reason behind this problem is how the check currently works:
* While generating MIR, it already skips nested unsafe blocks (i.e. unsafe
nested in other unsafe) so that the inner one is always the one considered
unused
* To differentiate the cases of no unsafe operations inside the `unsafe` vs.
a surrounding `unsafe` block, there’s some ad-hoc magic walking up the HIR to
look for surrounding used `unsafe` blocks.
There’s a lot of problems with this approach besides the one presented above.
E.g. the MIR-building uses checks for `unsafe_op_in_unsafe_fn` lint to decide
early whether or not `unsafe` blocks in an `unsafe fn` are redundant and ought
to be removed.
```rs
unsafe fn granular_disallow_op_in_unsafe_fn() {
unsafe {
#[deny(unsafe_op_in_unsafe_fn)]
{
unsf();
}
}
}
```
```
error: call to unsafe function is unsafe and requires unsafe block (error E0133)
--> src/main.rs:13:13
|
13 | unsf();
| ^^^^^^ call to unsafe function
|
note: the lint level is defined here
--> src/main.rs:11:16
|
11 | #[deny(unsafe_op_in_unsafe_fn)]
| ^^^^^^^^^^^^^^^^^^^^^^
= note: consult the function's documentation for information on how to avoid undefined behavior
warning: unnecessary `unsafe` block
--> src/main.rs:10:5
|
9 | unsafe fn granular_disallow_op_in_unsafe_fn() {
| --------------------------------------------- because it's nested under this `unsafe` fn
10 | unsafe {
| ^^^^^^ unnecessary `unsafe` block
|
= note: `#[warn(unused_unsafe)]` on by default
```
Here, the intermediate `unsafe` was ignored, even though it contains a unsafe
operation that is not allowed to happen in an `unsafe fn` without an additional `unsafe` block.
Also closures were problematic and the workaround/algorithms used on current
nightly didn’t work properly. (I skipped trying to fully understand what it was
supposed to do, because this PR uses a completely different approach.)
```rs
fn nested() {
unsafe {
unsafe { unsf() }
}
}
```
```
warning: unnecessary `unsafe` block
--> src/main.rs:10:9
|
9 | unsafe {
| ------ because it's nested under this `unsafe` block
10 | unsafe { unsf() }
| ^^^^^^ unnecessary `unsafe` block
|
= note: `#[warn(unused_unsafe)]` on by default
```
vs
```rs
fn nested() {
let _ = || unsafe {
let _ = || unsafe { unsf() };
};
}
```
```
warning: unnecessary `unsafe` block
--> src/main.rs:9:16
|
9 | let _ = || unsafe {
| ^^^^^^ unnecessary `unsafe` block
|
= note: `#[warn(unused_unsafe)]` on by default
warning: unnecessary `unsafe` block
--> src/main.rs:10:20
|
10 | let _ = || unsafe { unsf() };
| ^^^^^^ unnecessary `unsafe` block
```
*note that this warning kind-of suggests that **both** unsafe blocks are redundant*
--------------------------------------------------------------------------------
I also dislike the fact that it always suggests keeping the outermost `unsafe`.
E.g. for
```rs
fn granularity() {
unsafe {
unsafe { unsf() }
unsafe { unsf() }
unsafe { unsf() }
}
}
```
I prefer if `rustc` suggests removing the more-course outer-level `unsafe`
instead of the fine-grained inner `unsafe` blocks, which it currently does on nightly:
```
warning: unnecessary `unsafe` block
--> src/main.rs:10:9
|
9 | unsafe {
| ------ because it's nested under this `unsafe` block
10 | unsafe { unsf() }
| ^^^^^^ unnecessary `unsafe` block
|
= note: `#[warn(unused_unsafe)]` on by default
warning: unnecessary `unsafe` block
--> src/main.rs:11:9
|
9 | unsafe {
| ------ because it's nested under this `unsafe` block
10 | unsafe { unsf() }
11 | unsafe { unsf() }
| ^^^^^^ unnecessary `unsafe` block
warning: unnecessary `unsafe` block
--> src/main.rs:12:9
|
9 | unsafe {
| ------ because it's nested under this `unsafe` block
...
12 | unsafe { unsf() }
| ^^^^^^ unnecessary `unsafe` block
```
--------------------------------------------------------------------------------
Needless to say, this PR addresses all these points. For context, as far as my
understanding goes, the main advantage of skipping inner unsafe blocks was that
a test case like
```rs
fn top_level_used() {
unsafe {
unsf();
unsafe { unsf() }
unsafe { unsf() }
unsafe { unsf() }
}
}
```
should generate some warning because there’s redundant nested `unsafe`, however
every single `unsafe` block _does_ contain some statement that uses it. Of course
this PR doesn’t aim change the warnings on this kind of code example, because
the current behavior, warning on all the inner `unsafe` blocks, makes sense in this case.
As mentioned, during MIR building all the unsafe blocks *are* kept now, and usage
is attributed to them. The way to still generate a warning like
```
warning: unnecessary `unsafe` block
--> src/main.rs:11:9
|
9 | unsafe {
| ------ because it's nested under this `unsafe` block
10 | unsf();
11 | unsafe { unsf() }
| ^^^^^^ unnecessary `unsafe` block
|
= note: `#[warn(unused_unsafe)]` on by default
warning: unnecessary `unsafe` block
--> src/main.rs:12:9
|
9 | unsafe {
| ------ because it's nested under this `unsafe` block
...
12 | unsafe { unsf() }
| ^^^^^^ unnecessary `unsafe` block
warning: unnecessary `unsafe` block
--> src/main.rs:13:9
|
9 | unsafe {
| ------ because it's nested under this `unsafe` block
...
13 | unsafe { unsf() }
| ^^^^^^ unnecessary `unsafe` block
```
in this case is by emitting a `unused_unsafe` warning for all of the `unsafe`
blocks that are _within a **used** unsafe block_.
The previous code had a little HIR traversal already anyways to collect a set of
all the unsafe blocks (in order to afterwards determine which ones are unused
afterwards). This PR uses such a traversal to do additional things including logic
like _always_ warn for an `unsafe` block that’s inside of another **used**
unsafe block. The traversal is expanded to include nested closures in the same go,
this simplifies a lot of things.
The whole logic around `unsafe_op_in_unsafe_fn` is a little complicated, there’s
some test cases of corner-cases in this PR. (The implementation involves
differentiating between whether a used unsafe block was used exclusively by
operations where `allow(unsafe_op_in_unsafe_fn)` was active.) The main goal was
to make sure that code should compile successfully if all the `unused_unsafe`-warnings
are addressed _simultaneously_ (by removing the respective `unsafe` blocks)
no matter how complicated the patterns of `unsafe_op_in_unsafe_fn` being
disallowed and allowed throughout the function are.
--------------------------------------------------------------------------------
One noteworthy design decision I took here: An `unsafe` block
with `allow(unused_unsafe)` **is considered used** for the purposes of
linting about redundant contained unsafe blocks. So while
```rs
fn granularity() {
unsafe { //~ ERROR: unnecessary `unsafe` block
unsafe { unsf() }
unsafe { unsf() }
unsafe { unsf() }
}
}
```
warns for the outer `unsafe` block,
```rs
fn top_level_ignored() {
#[allow(unused_unsafe)]
unsafe {
#[deny(unused_unsafe)]
{
unsafe { unsf() } //~ ERROR: unnecessary `unsafe` block
unsafe { unsf() } //~ ERROR: unnecessary `unsafe` block
unsafe { unsf() } //~ ERROR: unnecessary `unsafe` block
}
}
}
```
warns on the inner ones.
Move ty::print methods to Drop-based scope guards
Primary goal is reducing codegen of the TLS access for each closure, which shaves ~3 seconds of bootstrap time over rustc as a whole.
Adopt let else in more places
Continuation of #89933, #91018, #91481, #93046, #93590, #94011.
I have extended my clippy lint to also recognize tuple passing and match statements. The diff caused by fixing it is way above 1 thousand lines. Thus, I split it up into multiple pull requests to make reviewing easier. This is the biggest of these PRs and handles the changes outside of rustdoc, rustc_typeck, rustc_const_eval, rustc_trait_selection, which were handled in PRs #94139, #94142, #94143, #94144.
Even if we emit metadata disabling branch protection, this metadata may
conflict with other modules (e.g. during LTO) that have different branch
protection metadata set.
This is an unstable flag and feature, so ideally the flag not being
specified should act as if the feature wasn't implemented in the first
place.
Additionally this PR also ensures we emit an error if
`-Zbranch-protection` is set on targets other than the supported
aarch64. For now the error is being output from codegen, but ideally it
should be moved to earlier in the pipeline before stabilization.
Rollup of 10 pull requests
Successful merges:
- #89892 (Suggest `impl Trait` return type when incorrectly using a generic return type)
- #91675 (Add MemTagSanitizer Support)
- #92806 (Add more information to `impl Trait` error)
- #93497 (Pass `--test` flag through rustdoc to rustc so `#[test]` functions can be scraped)
- #93814 (mips64-openwrt-linux-musl: correct soft-foat)
- #93847 (kmc-solid: Use the filesystem thread-safety wrapper)
- #93877 (asm: Allow the use of r8-r14 as clobbers on Thumb1)
- #93892 (Only mark projection as ambiguous if GAT substs are constrained)
- #93915 (Implement --check-cfg option (RFC 3013), take 2)
- #93953 (Add the `known-bug` test directive, use it, and do some cleanup)
Failed merges:
r? `@ghost`
`@rustbot` modify labels: rollup
Add MemTagSanitizer Support
Add support for the LLVM [MemTagSanitizer](https://llvm.org/docs/MemTagSanitizer.html).
On hardware which supports it (see caveats below), the MemTagSanitizer can catch bugs similar to AddressSanitizer and HardwareAddressSanitizer, but with lower overhead.
On a tag mismatch, a SIGSEGV is signaled with code SEGV_MTESERR / SEGV_MTEAERR.
# Usage
`-Zsanitizer=memtag -C target-feature="+mte"`
# Comments/Caveats
* MemTagSanitizer is only supported on AArch64 targets with hardware support
* Requires `-C target-feature="+mte"`
* LLVM MemTagSanitizer currently only performs stack tagging.
# TODO
* Tests
* Example
This should provide a small perf improvement for debug builds,
and should more than cancel out the regression from adding noundef,
which was only significant in debug builds.
Fix ICE when using Box<T, A> with pointer sized A
Fixes#78459
Note that using `Box<T, A>` with a more than pointer sized `A` or using a pointer sized `A` with a Box of a DST will produce a different ICE (#92054) which is not fixed by this PR.
Add support for control-flow protection
This change adds a flag for configuring control-flow protection in the LLVM backend. In Clang, this flag is exposed as `-fcf-protection` with options `none|branch|return|full`. This convention is followed for `rustc`, though as a codegen option: `rustc -Z cf-protection=<none|branch|return|full>`. Tracking issue for future work is #93754.
llvm: migrate to new parameter-bearing uwtable attr
In https://reviews.llvm.org/D114543 the uwtable attribute gained a flag
so that we can ask for sync uwtables instead of async, as the former are
much cheaper. The default is async, so that's what I've done here, but I
left a TODO that we might be able to do better.
While in here I went ahead and dropped support for removing uwtable
attributes in rustc: we never did it, so I didn't write the extra C++
bridge code to make it work. Maybe I should have done the same thing
with the `sync|async` parameter but we'll see.
Specifically, change `Ty` from this:
```
pub type Ty<'tcx> = &'tcx TyS<'tcx>;
```
to this
```
pub struct Ty<'tcx>(Interned<'tcx, TyS<'tcx>>);
```
There are two benefits to this.
- It's now a first class type, so we can define methods on it. This
means we can move a lot of methods away from `TyS`, leaving `TyS` as a
barely-used type, which is appropriate given that it's not meant to
be used directly.
- The uniqueness requirement is now explicit, via the `Interned` type.
E.g. the pointer-based `Eq` and `Hash` comes from `Interned`, rather
than via `TyS`, which wasn't obvious at all.
Much of this commit is boring churn. The interesting changes are in
these files:
- compiler/rustc_middle/src/arena.rs
- compiler/rustc_middle/src/mir/visit.rs
- compiler/rustc_middle/src/ty/context.rs
- compiler/rustc_middle/src/ty/mod.rs
Specifically:
- Most mentions of `TyS` are removed. It's very much a dumb struct now;
`Ty` has all the smarts.
- `TyS` now has `crate` visibility instead of `pub`.
- `TyS::make_for_test` is removed in favour of the static `BOOL_TY`,
which just works better with the new structure.
- The `Eq`/`Ord`/`Hash` impls are removed from `TyS`. `Interned`s impls
of `Eq`/`Hash` now suffice. `Ord` is now partly on `Interned`
(pointer-based, for the `Equal` case) and partly on `TyS`
(contents-based, for the other cases).
- There are many tedious sigil adjustments, i.e. adding or removing `*`
or `&`. They seem to be unavoidable.
In https://reviews.llvm.org/D114543 the uwtable attribute gained a flag
so that we can ask for sync uwtables instead of async, as the former are
much cheaper. The default is async, so that's what I've done here, but I
left a TODO that we might be able to do better.
While in here I went ahead and dropped support for removing uwtable
attributes in rustc: we never did it, so I didn't write the extra C++
bridge code to make it work. Maybe I should have done the same thing
with the `sync|async` parameter but we'll see.
This change adds a flag for configuring control-flow protection in the
LLVM backend. In Clang, this flag is exposed as `-fcf-protection` with
options `none|branch|return|full`. This convention is followed for
`rustc`, though as a codegen option: `rustc -Z
cf-protection=<none|branch|return|full>`.
Co-authored-by: BlackHoleFox <blackholefoxdev@gmail.com>
Apply noundef attribute to &T, &mut T, Box<T>, bool
This doesn't handle `char` because it's a bit awkward to distinguish it from `u32` at this point in codegen.
Note that this _does not_ change whether or not it is UB for `&`, `&mut`, or `Box` to point to undef. It only applies to the pointer itself, not the pointed-to memory.
Fixes (partially) #74378.
r? `@nikic` cc `@RalfJung`
Split `pauth` target feature
Per discussion on https://github.com/rust-lang/rust/issues/86941 we'd like to split `pauth` into `paca` and `pacg` in order to better support possible future environments that only have the keys available for address or generic authentication. At the moment LLVM has the one `pauth` target_feature while Linux presents separate `paca` and `pacg` flags for feature detection.
Because the use of [target_feature](https://rust-lang.github.io/rfcs/2045-target-feature.html) will "allow the compiler to generate code under the assumption that this code will only be reached in hosts that support the feature", it does not make sense to simply translate `paca` into the LLVM feature `pauth`, as it will generate code as if `pacg` is available.
To accommodate this we error if only one of the two features is present. If LLVM splits them in the future we can remove this restriction without making a breaking change.
r? ```@Amanieu```
debuginfo: Fix DW_AT_containing_type vtable debuginfo regression
This PR brings back the `DW_AT_containing_type` attribute for vtables after it has accidentally been removed in #89597.
It also implements a more accurate description of vtables. Instead of describing them as an array of void pointers, the compiler will now emit a struct type description with a field for each entry of the vtable.
r? ``@wesleywiser``
This PR should fix issue https://github.com/rust-lang/rust/issues/93164.
~~The PR is blocked on https://github.com/rust-lang/rust/pull/93154 because both of them modify the `codegen/debug-vtable.rs` test case.~~
This doesn't handle `char` because it's a bit awkward to distinguish it
from u32 at this point in codegen.
Note that for some types (like `&Struct` and `&mut Struct`),
we already apply `dereferenceable`, which implies `noundef`,
so the IR does not change.
Stabilize `-Z instrument-coverage` as `-C instrument-coverage`
(Tracking issue for `instrument-coverage`: https://github.com/rust-lang/rust/issues/79121)
This PR stabilizes support for instrumentation-based code coverage, previously provided via the `-Z instrument-coverage` option. (Continue supporting `-Z instrument-coverage` for compatibility for now, but show a deprecation warning for it.)
Many, many people have tested this support, and there are numerous reports of it working as expected.
Move the documentation from the unstable book to stable rustc documentation. Update uses and documentation to use the `-C` option.
Addressing questions raised in the tracking issue:
> If/when stabilized, will the compiler flag be updated to -C instrument-coverage? (If so, the -Z variant could also be supported for some time, to ease migrations for existing users and scripts.)
This stabilization PR updates the option to `-C` and keeps the `-Z` variant to ease migration.
> The Rust coverage implementation depends on (and automatically turns on) -Z symbol-mangling-version=v0. Will stabilizing this feature depend on stabilizing v0 symbol-mangling first? If so, what is the current status and timeline?
This stabilization PR depends on https://github.com/rust-lang/rust/pull/90128 , which stabilizes `-C symbol-mangling-version=v0` (but does not change the default symbol-mangling-version).
> The Rust coverage implementation implements the latest version of LLVM's Coverage Mapping Format (version 4), which forces a dependency on LLVM 11 or later. A compiler error is generated if attempting to compile with coverage, and using an older version of LLVM.
Given that LLVM 13 has now been released, requiring LLVM 11 for coverage support seems like a reasonable requirement. If people don't have at least LLVM 11, nothing else breaks; they just can't use coverage support. Given that coverage support currently requires a nightly compiler and LLVM 11 or newer, allowing it on a stable compiler built with LLVM 11 or newer seems like an improvement.
The [tracking issue](https://github.com/rust-lang/rust/issues/79121) and the [issue label A-code-coverage](https://github.com/rust-lang/rust/labels/A-code-coverage) link to a few open issues related to `instrument-coverage`, but none of them seem like showstoppers. All of them seem like improvements and refinements we can make after stabilization.
The original `-Z instrument-coverage` support went through a compiler-team MCP at https://github.com/rust-lang/compiler-team/issues/278 . Based on that, `@pnkfelix` suggested that this needed a stabilization PR and a compiler-team FCP.
Windows: Disable LLVM crash dialog boxes.
This disables the crash dialog box on Windows. When LLVM hits an assertion, it will open a dialog box with Abort/Retry/Ignore. This is annoying on CI because CI will just hang until it times out (which can take hours).
Instead of opening a dialog box, it will print a message like this:
```
Assertion failed: isa<X>(Val) && "cast<Ty>() argument of incompatible type!", file D:\Proj\rust\rust\src\llvm-project\llvm\include\llvm/Support/Casting.h, line 255
```
Closes#92829
The "CI" environment var isn't universal (for example, I think Azure
uses TF_BUILD). However, we are mostly concerned with rust-lang/rust's
own CI which currently is GitHub Actions which does set "CI". And I
think most other providers use "CI" as well.
debuginfo: Make sure that type names for closure and generator environments are unique in debuginfo.
Before this change, closure/generator environments coming from different instantiations of the same generic function were all assigned the same name even though they were distinct types with potentially different data layout. Now we append the generic arguments of the originating function to the type name.
This commit also emits `{closure_env#0}` as the name of these types in order to disambiguate them from the accompanying closure function (which keeps being called `{closure#0}`). Previously both were assigned the same name.
NOTE: Changing debuginfo names like this can break pretty printers and other debugger plugins. I think it's OK in this particular case because the names we are changing were ambiguous anyway. In general though it would be great to have a process for doing changes like these.
Before this change, closure/generator environments coming from different
instantiations of the same generic function were all assigned the same
name even though they were distinct types with potentially different data
layout. Now we append the generic arguments of the originating function
to the type name.
This commit also emits '{closure_env#0}' as the name of these types in
order to disambiguate them from the accompanying closure function
'{closure#0}'. Previously both were assigned the same name.
Rollup of 10 pull requests
Successful merges:
- #92611 (Add links to the reference and rust by example for asm! docs and lints)
- #93158 (wasi: implement `sock_accept` and enable networking)
- #93239 (Add os::unix::net::SocketAddr::from_path)
- #93261 (Some unwinding related cg_ssa cleanups)
- #93295 (Avoid double panics when using `TempDir` in tests)
- #93353 (Unimpl {Add,Sub,Mul,Div,Rem,BitXor,BitOr,BitAnd}<$t> for Saturating<$t>)
- #93356 (Edit docs introduction for `std::cmp::PartialOrd`)
- #93375 (fix typo `documenation`)
- #93399 (rustbuild: Fix compiletest warning when building outside of root.)
- #93404 (Fix a typo from #92899)
Failed merges:
r? `@ghost`
`@rustbot` modify labels: rollup
Fix debuginfo for pointers/references to unsized types
This PR makes the compiler emit fat pointer debuginfo in all cases. Before, we sometimes got thin-pointer debuginfo, making it impossible to fully interpret the pointed to memory in debuggers. The code is actually cleaner now, especially around generation of trait object pointer debuginfo.
Fixes https://github.com/rust-lang/rust/issues/92718
~~Blocked on https://github.com/rust-lang/rust/pull/92729.~~
LLDB does not seem to see fields if they are marked with DW_AT_artificial
which breaks pretty printers that use these fields for decoding fat pointers.
Use error-on-mismatch policy for PAuth module flags.
This agrees with Clang, and avoids an error when using LTO with mixed
C/Rust. LLVM considers different behaviour flags to be a mismatch,
even when the flag value itself is the same.
This also makes the flag setting explicit for all uses of
LLVMRustAddModuleFlag.
----
I believe that this fixes#92885, but have only reproduced it locally on Linux hosts so cannot confirm that it fixes the issue as reported.
I have not included a test for this because it is covered by an existing test (`src/test/run-make-fulldeps/cross-lang-lto-clang`). It is not without its problems, though:
* The test requires Clang and `--run-clang-based-tests-with=...` to run, and this is not the case on the CI.
* Any test I add would have a similar requirement.
* With this patch applied, the test gets further, but it still fails (for other reasons). I don't think that affects #92885.
Work around missing code coverage data causing llvm-cov failures
If we do not add code coverage instrumentation to the `Body` of a
function, then when we go to generate the function record for it, we
won't write any data and this later causes llvm-cov to fail when
processing data for the entire coverage report.
I've identified two main cases where we do not currently add code
coverage instrumentation to the `Body` of a function:
1. If the function has a single `BasicBlock` and it ends with a
`TerminatorKind::Unreachable`.
2. If the function is created using a proc macro of some kind.
For case 1, this is typically not important as this most often occurs as
a result of function definitions that take or return uninhabited
types. These kinds of functions, by definition, cannot even be called so
they logically should not be counted in code coverage statistics.
For case 2, I haven't looked into this very much but I've noticed while
testing this patch that (other than functions which are covered by case
1) the skipped function coverage debug message is occasionally triggered
in large crate graphs by functions generated from a proc macro. This may
have something to do with weird spans being generated by the proc macro
but this is just a guess.
I think it's reasonable to land this change since currently, we fail to
generate *any* results from llvm-cov when a function has no coverage
instrumentation applied to it. With this change, we get coverage data
for all functions other than the two cases discussed above.
Fixes#93054 which occurs because of uncallable functions which shouldn't
have code coverage anyway.
I will open an issue for missing code coverage of proc macro generated
functions and leave a link here once I have a more minimal repro.
r? ``@tmandry``
cc ``@richkadel``
This agrees with Clang, and avoids an error when using LTO with mixed
C/Rust. LLVM considers different behaviour flags to be a mismatch,
even when the flag value itself is the same.
This also makes the flag setting explicit for all uses of
LLVMRustAddModuleFlag.
If we do not add code coverage instrumentation to the `Body` of a
function, then when we go to generate the function record for it, we
won't write any data and this later causes llvm-cov to fail when
processing data for the entire coverage report.
I've identified two main cases where we do not currently add code
coverage instrumentation to the `Body` of a function:
1. If the function has a single `BasicBlock` and it ends with a
`TerminatorKind::Unreachable`.
2. If the function is created using a proc macro of some kind.
For case 1, this typically not important as this most often occurs as
the result of function definitions that take or return uninhabited
types. These kinds of functions, by definition, cannot even be called so
they logically should not be counted in code coverage statistics.
For case 2, I haven't looked into this very much but I've noticed while
testing this patch that (other than functions which are covered by case
1) the skipped function coverage debug message is occasionally triggered
in large crate graphs by functions generated from a proc macro. This may
have something to do with weird spans being generated by the proc macro
but this is just a guess.
I think it's reasonable to land this change since currently, we fail to
generate *any* results from llvm-cov when a function has no coverage
instrumentation applied to it. With this change, we get coverage data
for all functions other than the two cases discussed above.
Improve SIMD casts
* Allows `simd_cast` intrinsic to take `usize` and `isize`
* Adds `simd_as` intrinsic, which is the same as `simd_cast` except for saturating float-to-int conversions (matching the behavior of `as`).
cc `@workingjubilee`
Implement raw-dylib support for windows-gnu
Add support for `#[link(kind = "raw-dylib")]` on windows-gnu targets. Work around binutils's linker's inability to read import libraries produced by LLVM by calling out to the binutils `dlltool` utility to create an import library from a temporary .DEF file; this approach is effectively a slightly refined version of `@mati865's` earlier attempt at this strategy in PR #88801. (In particular, this attempt at this strategy adds support for `#[link_ordinal(...)]` as well.)
In support of #58713.
Avoid unnecessary monomorphization of inline asm related functions
This should reduce build time for codegen backends by avoiding duplicated monomorphization of certain inline asm related functions for each passed in closure type.
Remove LLVMRustMarkAllFunctionsNounwind
This was originally introduced in #10916 as a way to remove all landing
pads when performing LTO. However this is no longer necessary today
since rustc properly marks all functions and call-sites as nounwind
where appropriate.
In fact this is incorrect in the presence of `extern "C-unwind"` which
must create a landing pad when compiled with `-C panic=abort` so that
foreign exceptions are caught and properly turned into aborts.
Remove deprecated LLVM-style inline assembly
The `llvm_asm!` was deprecated back in #87590 1.56.0, with intention to remove
it once `asm!` was stabilized, which already happened in #91728 1.59.0. Now it
is time to remove `llvm_asm!` to avoid continued maintenance cost.
Closes#70173.
Closes#92794.
Closes#87612.
Closes#82065.
cc `@rust-lang/wg-inline-asm`
r? `@Amanieu`
This was originally introduced in #10916 as a way to remove all landing
pads when performing LTO. However this is no longer necessary today
since rustc properly marks all functions and call-sites as nounwind
where appropriate.
In fact this is incorrect in the presence of `extern "C-unwind"` which
must create a landing pad when compiled with `-C panic=abort` so that
foreign exceptions are caught and properly turned into aborts.
[code coverage] Fix missing dead code in modules that are never called
The issue here is that the logic used to determine which CGU to put the dead function stubs in doesn't handle cases where a module is never assigned to a CGU (which is what happens when all of the code in the module is dead).
The partitioning logic also caused issues in #85461 where inline functions were duplicated into multiple CGUs resulting in duplicate symbols.
This commit fixes the issue by removing the complex logic used to assign dead code stubs to CGUs and replaces it with a much simpler model: we pick one CGU to hold all the dead code stubs. We pick a CGU which has exported items which increases the likelihood the linker won't throw away our dead functions and we pick the smallest to minimize the impact on compilation times for crates with very large CGUs.
Fixes#91661Fixes#86177Fixes#85718Fixes#79622
r? ```@tmandry```
cc ```@richkadel```
This PR is not urgent so please don't let it interrupt your holidays! 🎄🎁
Store a `Symbol` instead of an `Ident` in `VariantDef`/`FieldDef`
The field is also renamed from `ident` to `name`. In most cases,
we don't actually need the `Span`. A new `ident` method is added
to `VariantDef` and `FieldDef`, which constructs the full `Ident`
using `tcx.def_ident_span()`. This method is used in the cases
where we actually need an `Ident`.
This makes incremental compilation properly track changes
to the `Span`, without all of the invalidations caused by storing
a `Span` directly via an `Ident`.
The field is also renamed from `ident` to `name. In most cases,
we don't actually need the `Span`. A new `ident` method is added
to `VariantDef` and `FieldDef`, which constructs the full `Ident`
using `tcx.def_ident_span()`. This method is used in the cases
where we actually need an `Ident`.
This makes incremental compilation properly track changes
to the `Span`, without all of the invalidations caused by storing
a `Span` directly via an `Ident`.
Consolidate checking for msvc when generating debuginfo
If the target we're generating code for is msvc, then we do two main
things differently: we generate type names in a C++ style instead of a
Rust style and we generate debuginfo for enums differently.
I've refactored the code so that there is one function
(`cpp_like_debuginfo`) which determines if we should use the C++ style
of naming types and other debuginfo generation or the regular Rust one.
r? ``@michaelwoerister``
This PR is not urgent so please don't let it interrupt your holidays! 🎄🎁
If the target we're generating code for is msvc, then we do two main
things differently: we generate type names in a C++ style instead of a
Rust style and we generate debuginfo for enums differently.
I've refactored the code so that there is one function
(`cpp_like_debuginfo`) which determines if we should use the C++ style
of naming types and other debuginfo generation or the regular Rust one.
In #79570, `-Z split-dwarf-kind={none,single,split}` was replaced by `-C
split-debuginfo={off,packed,unpacked}`. `-C split-debuginfo`'s packed
and unpacked aren't exact parallels to single and split, respectively.
On Unix, `-C split-debuginfo=packed` will put debuginfo into object
files and package debuginfo into a DWARF package file (`.dwp`) and
`-C split-debuginfo=unpacked` will put debuginfo into dwarf object files
and won't package it.
In the initial implementation of Split DWARF, split mode wrote sections
which did not require relocation into a DWARF object (`.dwo`) file which
was ignored by the linker and then packaged those DWARF objects into
DWARF packages (`.dwp`). In single mode, sections which did not require
relocation were written into object files but ignored by the linker and
were not packaged. However, both split and single modes could be
packaged or not, the primary difference in behaviour was where the
debuginfo sections that did not require link-time relocation were
written (in a DWARF object or the object file).
This commit re-introduces a `-Z split-dwarf-kind` flag, which can be
used to pick between split and single modes when `-C split-debuginfo` is
used to enable Split DWARF (either packed or unpacked).
Signed-off-by: David Wood <david.wood@huawei.com>
No functional changes intended.
The LLVM commit
ec501f15a8
removed the signed version of `createExpression`. This adapts the Rust
LLVM wrappers accordingly.
Continue supporting -Z instrument-coverage for compatibility for now,
but show a deprecation warning for it.
Update uses and documentation to use the -C option.
Move the documentation from the unstable book to stable rustc
documentation.
Mark drop calls in landing pads `cold` instead of `noinline`
Now that deferred inlining has been disabled in LLVM (#92110), this shouldn't cause catastrophic size blowup.
I confirmed that the test cases from https://github.com/rust-lang/rust/issues/41696#issuecomment-298696944 still compile quickly (<1s) after this change. ~Although note that I wasn't able to reproduce the original issue using a recent rustc/llvm with deferred inlining enabled, so those tests may no longer be representative. I was also unable to create a modified test case that reproduced the original issue.~ (edit: I reproduced it on CI by accident--the first commit timed out on the LLVM 12 builder, because I forgot to make it conditional on LLVM version)
r? `@nagisa`
cc `@arielb1` (this effectively reverts #42771 "mark calls in the unwind path as !noinline")
cc `@RalfJung` (fixes#46515)
edit: also fixes#87055
Allow loading LLVM plugins with both legacy and new pass manager
Opening a draft PR to get feedback and start discussion on this feature. There is already a codegen option `passes` which allow giving a list of LLVM pass names, however we currently can't use a LLVM pass plugin (as described here : https://llvm.org/docs/WritingAnLLVMPass.html), the only available passes are the LLVM built-in ones.
The proposed modification would be to add another codegen option `pass-plugins`, which can be set with a list of paths to shared library files. These libraries are loaded using the LLVM function `PassPlugin::Load`, which calls the expected symbol `lvmGetPassPluginInfo`, and register the pipeline parsing and optimization callbacks.
An example usage with a single plugin and 3 passes would look like this in the `.cargo/config`:
```toml
rustflags = [
"-C", "pass-plugins=/tmp/libLLVMPassPlugin",
"-C", "passes=pass1 pass2 pass3",
]
```
This would give the same functionality as the opt LLVM tool directly integrated in rust build system.
Additionally, we can also not specify the `passes` option, and use a plugin which inserts passes in the optimization pipeline, as one could do using clang.
Add codegen option for branch protection and pointer authentication on AArch64
The branch-protection codegen option enables the use of hint-space pointer
authentication code for AArch64 targets.
The issue here is that the logic used to determine which CGU to put the
dead function stubs in doesn't handle cases where a module is never
assigned to a CGU.
The partitioning logic also caused issues in #85461 where inline
functions were duplicated into multiple CGUs resulting in duplicate
symbols.
This commit fixes the issue by removing the complex logic used to assign
dead code stubs to CGUs and replaces it with a much simplier model: we
pick one CGU to hold all the dead code stubs. We pick a CGU which has
exported items which increases the likelihood the linker won't throw
away our dead functions and we pick the smallest to minimize the impact
on compilation times for crates with very large CGUs.
Fixes#86177Fixes#85718Fixes#79622
Remove `SymbolStr`
This was originally proposed in https://github.com/rust-lang/rust/pull/74554#discussion_r466203544. As well as removing the icky `SymbolStr` type, it allows the removal of a lot of `&` and `*` occurrences.
Best reviewed one commit at a time.
r? `@oli-obk`
rustc_codegen_llvm: Give each codegen unit a unique DWARF name on all platforms, not just Apple ones.
To avoid breaking split DWARF, we need to ensure that each codegen unit has a
unique `DW_AT_name`. This is because there's a remote chance that different
codegen units for the same module will have entirely identical DWARF entries
for the purpose of the DWO ID, which would violate Appendix F ("Split Dwarf
Object Files") of the DWARF 5 specification. LLVM uses the algorithm specified
in section 7.32 "Type Signature Computation" to compute the DWO ID, which does
not include any fields that would distinguish compilation units. So we must
embed the codegen unit name into the `DW_AT_name`.
Closes#88521.
Remove `in_band_lifetimes` from `rustc_codegen_llvm`
See #91867 for more information.
This one took a while. This crate has dozens of functions not associated with any type, and most of them were using in-band lifetimes for `'ll` and `'tcx`.
Apply path remapping to DW_AT_GNU_dwo_name when producing split DWARF
`--remap-path-prefix` doesn't apply to paths to `.o` (in case of packed) or `.dwo` (in case of unpacked) files in `DW_AT_GNU_dwo_name`. GCC also has this bug https://gcc.gnu.org/bugzilla/show_bug.cgi?id=91888
platforms, not just Apple ones.
To avoid breaking split DWARF, we need to ensure that each codegen unit has a
unique `DW_AT_name`. This is because there's a remote chance that different
codegen units for the same module will have entirely identical DWARF entries
for the purpose of the DWO ID, which would violate Appendix F ("Split Dwarf
Object Files") of the DWARF 5 specification. LLVM uses the algorithm specified
in section 7.32 "Type Signature Computation" to compute the DWO ID, which does
not include any fields that would distinguish compilation units. So we must
embed the codegen unit name into the `DW_AT_name`.
Closes#88521.
By changing `as_str()` to take `&self` instead of `self`, we can just
return `&str`. We're still lying about lifetimes, but it's a smaller lie
than before, where `SymbolStr` contained a (fake) `&'static str`!
Stabilize `iter::zip`
Hello all!
As the tracking issue (#83574) for `iter::zip` completed the final commenting period without any concerns being raised, I hereby submit this stabilization PR on the issue.
As the pull request that introduced the feature (#82917) states, the `iter::zip` function is a shorter way to zip two iterators. As it's generally a quality-of-life/ergonomic improvement, it has been integrated into the codebase without any trouble, and has been
used in many places across the rust compiler and standard library since March without any issues.
For more details, I would refer to `@cuviper's` original PR, or the [function's documentation](https://doc.rust-lang.org/std/iter/fn.zip.html).
Use `OutputFilenames` to generate output file for `-Zllvm-time-trace`
The resulting profile will include the crate name and will be stored in
the `--out-dir` directory.
This implementation makes it convenient to use LLVM time trace together
with cargo, in the contrast to the previous implementation which would
overwrite profiles or store them in `.cargo/registry/..`.
Use module inline assembly to embed bitcode
In LLVM 14, our current method of setting section flags to avoid
embedding the `.llvmbc` section into final compilation artifacts
will no longer work, see issue #90326. The upstream recommendation
is to instead embed the entire bitcode using module-level inline
assembly, which is what this change does.
I've kept the existing code for platforms where we do not need to
set section flags, but possibly we should always be using the
inline asm approach (which would have to look a bit different for MachO).
r? `@nagisa`
The resulting profile will include the crate name and will be stored in
the `--out-dir` directory.
This implementation makes it convenient to use LLVM time trace together
with cargo, in the contrast to the previous implementation which would
overwrite profiles or store them in `.cargo/registry/..`.
replace dynamic library module with libloading
This PR deletes the `rustc_metadata::dynamic_lib` module in favor of the popular and better tested [`libloading` crate](https://github.com/nagisa/rust_libloading/).
We don't benefit from `libloading`'s symbol lifetimes since we end up leaking the loaded library in all cases, but the call-sites look much nicer by improving error handling and abstracting away some transmutes. We also can remove `rustc_metadata`'s direct dependencies on `libc` and `winapi`.
This PR also adds an exception for `libloading` (and its license) to tidy, so this will need sign-off from the compiler team.
code-cov: generate dead functions with private/default linkage
As discovered in #85461, the MSVC linker treats weak symbols slightly
differently than unix-y linkers do. This causes link.exe to fail with
LNK1227 "conflicting weak extern definition" where as other targets are
able to link successfully.
This changes the dead functions from being generated as weak/hidden to
private/default which, as the LLVM reference says:
> Global values with “private” linkage are only directly accessible by
objects in the current module. In particular, linking code into a module
with a private global value may cause the private to be renamed as
necessary to avoid collisions. Because the symbol is private to the
module, all references can be updated. This doesn’t show up in any
symbol table in the object file.
This fixes the conflicting weak symbols but doesn't address the reason
*why* we have conflicting symbols for these dead functions. The test
cases added in this commit contain a minimal repro of the fundamental
issue which is that the logic used to decide what dead code functions
should be codegen'd in the current CGU doesn't take into account that
functions can be duplicated across multiple CGUs (for instance, in the
case of `#[inline(always)]` functions).
Fixing that is likely to be a more complex change (see
https://github.com/rust-lang/rust/issues/85461#issuecomment-985005805).
Fixes#85461
Remove the reg_thumb register class for asm! on ARM
Also restricts r8-r14 from being used on Thumb1 targets as per #90736.
cc ``@Lokathor``
r? ``@joshtriplett``
Use object crate for .rustc metadata generation
We already use the object crate for generating uncompressed .rmeta
metadata object files. This switches the generation of compressed
.rustc object files to use the object crate as well. These have
slightly different requirements in that .rmeta should be completely
excluded from any final compilation artifacts, while .rustc should
be part of shared objects, but not loaded into memory.
The primary motivation for this change is #90326: In LLVM 14, the
current way of setting section flags (and in particular, preventing
the setting of SHF_ALLOC) will no longer work. There are other ways
we could work around this, but switching to the object crate seems
like the most elegant, as we already use it for .rmeta, and as it
makes this independent of the codegen backend. In particular, we
don't need separate handling in codegen_llvm and codegen_gcc.
codegen_cranelift should be able to reuse the implementation as
well, though I have omitted that here, as it is not based on
codegen_ssa.
This change mostly extracts the existing code for .rmeta handling
to allow using it for .rustc as well, and adjusts the codegen
infrastructure to handle the metadata object file separately: We
no longer create a backend-specific module for it, and directly
produce the compiled module instead.
This does not `fix` #90326 by itself yet, as .llvmbc will need to be
handled separately.
r? `@nagisa`
In LLVM 14, our current method of setting section flags to avoid
embedding the `.llvmbc` section into final compilation artifacts
will no longer work, see issue #90326. The upstream recommendation
is to instead embed the entire bitcode using module-level inline
assembly, which is what this change does.
I've kept the existing code for platforms where we do not need to
set section flags, but possibly we should always be using the
inline asm approach.
We already use the object crate for generating uncompressed .rmeta
metadata object files. This switches the generation of compressed
.rustc object files to use the object crate as well. These have
slightly different requirements in that .rmeta should be completely
excluded from any final compilation artifacts, while .rustc should
be part of shared objects, but not loaded into memory.
The primary motivation for this change is #90326: In LLVM 14, the
current way of setting section flags (and in particular, preventing
the setting of SHF_ALLOC) will no longer work. There are other ways
we could work around this, but switching to the object crate seems
like the most elegant, as we already use it for .rmeta, and as it
makes this independent of the codegen backend. In particular, we
don't need separate handling in codegen_llvm and codegen_gcc.
codegen_cranelift should be able to reuse the implementation as
well, though I have omitted that here, as it is not based on
codegen_ssa.
This change mostly extracts the existing code for .rmeta handling
to allow using it for .rustc as well, and adjust the codegen
infrastructure to handle the metadata object file separately: We
no longer create a backend-specific module for it, and directly
produce the compiled module instead.
This does not fix#90326 by itself yet, as .llvmbc will need to be
handled separately.
{kind=link}