7904: Improved completion sorting r=JoshMcguigan a=JoshMcguigan
I was working on extending #3954 to apply completion scores in more places (I'll have another PR open for that soon) when I discovered that actually completion sorting was not working for me at all in `coc.nvim`. This led me down a bit of a rabbit hole of how coc and vs code each sort completion items.
Before this PR, rust-analyzer was setting the `sortText` field on completion items to `None` if we hadn't applied any completion score for that item, or to the label of the item with a leading whitespace character if we had applied any completion score. Completion score is defined in rust-analyzer as an enum with two variants, `TypeMatch` and `TypeAndNameMatch`.
In vs code the above strategy works, because if `sortText` isn't set [they default it to the label](b4ead4ed66). However, coc [does not do this](e211e36147/src/completion/complete.ts (L245)).
I was going to file a bug report against coc, but I read the [LSP spec for the `sortText` field](https://microsoft.github.io/language-server-protocol/specifications/specification-current/#textDocument_completion) and I feel like it is ambiguous and coc could claim what they do is a valid interpretation of the spec.
Further, the existing rust-analyzer behavior of prepending a leading whitespace character for completion items with any completion score does not handle sorting `TypeAndNameMatch` completions above `TypeMatch` completions. They were both being treated the same.
The first change this PR makes is to set the `sortText` field to either "1" for `TypeAndNameMatch` completions, "2" for `TypeMatch` completions, or "3" for completions which are neither of those. This change works around the potential ambiguity in the LSP spec and fixes completion sorting for users of coc. It also allows `TypeAndNameMatch` items to be sorted above just `TypeMatch` items (of course both of these will be sorted above completion items without a score).
The second change this PR makes is to use the actual completion scores for ref matches. The existing code ignored the actual score and always assumed these would be a high priority completion item.
#### Before
Here coc just sorts based on how close the items are in the file.

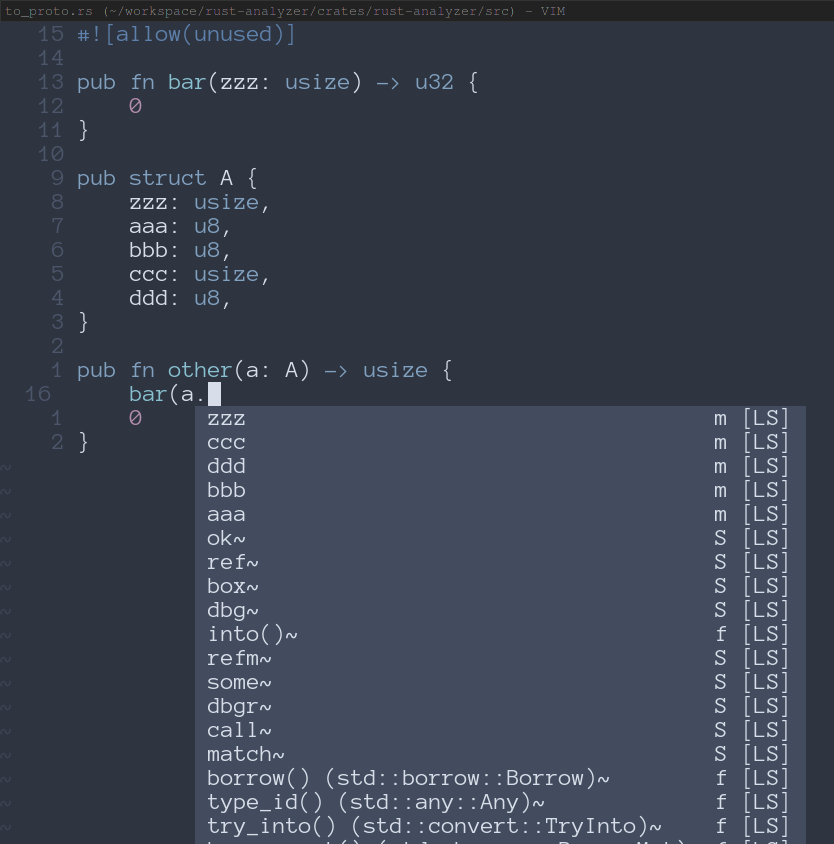
#### After
Here we correctly get `zzz` first, since that is both a type and name match. Then we get `ccc` which is just a type match.
Co-authored-by: Josh Mcguigan <joshmcg88@gmail.com>
7961: add user docs for ssr assist r=JoshMcguigan a=JoshMcguigan
@matklad
This is a small follow up on #7874, adding user docs for the SSR assist functionality. Since most other assists aren't handled this way I wasn't sure exactly how we wanted to document this, so feel free to suggest alternatives.
Co-authored-by: Josh Mcguigan <joshmcg88@gmail.com>
6822: Read version of rustc that compiled proc macro r=edwin0cheng a=jsomedon
Signed-off-by: Jay Somedon <jay.somedon@outlook.com>
This PR is to fix#6174.
I basically
* added two methods, `read_version` and `read_section`(used by `read_version`)
* two new crates `snap` and `object` to be used by those two methods
I just noticed that some part of code were auto-reformatted by rust-analyzer on file save. Does it matter?
Co-authored-by: Jay Somedon <jay.somedon@outlook.com>
Co-authored-by: Edwin Cheng <edwin0cheng@gmail.com>
7878: Remove `item_scope` field from `Body` r=jonas-schievink a=jonas-schievink
Closes https://github.com/rust-analyzer/rust-analyzer/issues/7632
Instead of storing an `ItemScope` filled with inner items, we store the list of `BlockId`s for all block expressions that are part of a `Body`. Code can then query the `block_def_map` for those.
bors r+
Co-authored-by: Jonas Schievink <jonasschievink@gmail.com>
Co-authored-by: Jonas Schievink <jonas.schievink@ferrous-systems.com>
{kind=link}
{kind=link}