When encoding a proc-macro crate, there may be gaps in the table (since
we only encode the crate root and proc-macro items). Account for this by
checking if the entry is present, rather than using `unwrap()`
Replace simple `if let` constructs with Option::map
Replaces a few constructs of the form
```
if let Some(x) = var {
Some(...)
} else {
None
}
```
with calls to `Option::map`.
`@rustbot` modify labels +C-cleanup +T-compiler
Fixes: #79725
Some macros can create a situation where `fn_sig_span` and `body_span`
map to different files.
New documentation on coverage tests incorrectly assumed multiple test
binaries could just be listed at the end of the `llvm-cov` command,
but it turns out each binary needs a `--object` prefix.
This PR fixes the bug and updates the documentation to correct that
issue. It also fixes a few other minor issues in internal implementation
comments, and adds documentation on getting coverage results for doc
tests.
Validate naked functions definitions
Validate that naked functions are defined in terms of a single inline assembly
block that uses only `const` and `sym` operands and has `noreturn` option.
Implemented as future incompatibility lint with intention to migrate it into
hard error. When it becomes a hard error it will ensure that naked functions are
either unsafe or contain an unsafe block around the inline assembly. It will
guarantee that naked functions do not reference functions parameters (obsoleting
part of existing checks from #79411). It will limit the definitions of naked
functions to what can be reliably supported. It will also reject naked functions
implemented using legacy LLVM style assembly since it cannot satisfy those
conditions.
https://github.com/rust-lang/rfcs/pull/2774https://github.com/rust-lang/rfcs/pull/2972
Prior to this commit, debuginfo was always generated by mapping a name
to a Place. This has the side-effect that `SimplifyLocals` cannot remove
locals that are only used for debuginfo because their other uses have
been const-propagated.
To allow these locals to be removed, we now allow debuginfo to point to
a constant value. The `ConstProp` pass detects when debuginfo points to
a local with a known constant value and replaces it with the value. This
allows the later `SimplifyLocals` pass to remove the local.
Previously, if you had a lot of inherent impl blocks on a type like:
struct Foo;
impl Foo { fn foo_1() {} }
...
impl Foo { fn foo_100_000() {} }
The compiler would be very slow at processing it, because
an internal algorithm would run in O(n^2), where n is the number
of impl blocks. Now, we add a new algorithm that allocates but
is faster asymptotically.
If there is an overlap between multiple impl blocks in terms of
identifiers, we still run a O(m^2) algorithm on groups of impl
blocks that have overlaps, but that m refers to the size of the
connected component, which is hopefully smaller than the n
that refers to the sum of all connected components.
- This allows us to delay figuring out the index of a capture
in the closure structure when all projections to atleast form
a capture have been applied to the builder
Co-authored-by: Roxane Fruytier <roxane.fruytier@hotmail.com>
- Derive TypeFoldable on `hir::place::Place` and associated
structs, to them to be written into typeck results.
Co-authored-by: Jennifer Wills <wills.jenniferg@gmail.com>
Co-authored-by: Logan Mosier <logmosier@gmail.com>
extend `WithOptConstParam` docs, move rustdoc test
This should hopefully make things a bit clearer, feel free to comment on anything which can still be improved.
cc `@ecstatic-morse` `@nikomatsakis` `@RalfJung`
Const parameters can not be inferred with `_` help note
This should close: #79557
# Example output
```
error[E0747]: type provided when a constant was expected
--> inferred_const_note.rs:6:19
|
6 | let a = foo::<_, 2>([0, 1, 2]);
| ^
|
= help: Const parameters can not be inferred with `_`
error: aborting due to previous error
For more information about this error, try `rustc --explain E0747`.
```
r? `@lcnr`
The liveness uses a mixed representation of RWUs based on the
observation that most of them have invalid reader and invalid
writer. The packed variant uses 32 bits and unpacked 96 bits.
Unpacked data contains reader live node and writer live node.
Since live nodes are used only to determine their validity,
RWUs can always be stored in a packed form with four bits for
each: reader bit, writer bit, used bit, and one extra padding
bit to simplify packing and unpacking operations.
A slightly clearer diagnostic when misusing const
Fixes#79598
This produces the following diagnostic:
"expected one of `>`, a const expression, lifetime, or type, found keyword `const`"
Instead of the previous, more confusing:
"expected one of `>`, const, lifetime, or type, found keyword `const`"
This might not be completely clear as some users might not understand what a const expression is, but I do believe this is an improvement.
check the recursion limit when finding a struct's tail
fixes#79437
This does a `delay_span_bug` (via `ty_error_with_message`) rather than emit a new error message, under the assumption that there will be an error elsewhere (even if the type isn't infinitely recursive, just deeper than the recursion limit, this appears to be the case).
Fixes#79661
In incremental compilation mode, we update a `DefPathHash -> DefId`
mapping every time we create a `DepNode` for a foreign `DefId`.
This mapping is written out to the on-disk incremental cache, and is
read by the next compilation session to allow us to lazily decode
`DefId`s.
When we decode a `DepNode` from the current incremental cache, we need
to ensure that any previously-recorded `DefPathHash -> DefId` mapping
gets recorded in the new mapping that we write out. However, PR #74967
didn't do this in all cases, leading to us being unable to decode a
`DefPathHash` in certain circumstances.
This PR refactors some of the code around `DepNode` deserialization to
prevent this kind of mistake from happening again.
Fix perf regression caused by #79284https://github.com/rust-lang/rust/pull/79284 only moved code around but this changed inlining and caused a large perf regression. This fixes it for me, though I'm less confident than usual because the regression was not observable with my usual (i.e. incremental) compilation settings.
r? `@Mark-Simulacrum`
Coverage tests for remaining TerminatorKinds and async, improve Assert
Tested and validate results for panic unwind, panic abort, assert!()
macro, TerminatorKind::Assert (for example, numeric overflow), and
async/await.
Implemented a previous documented idea to change Assert handling to be
the same as FalseUnwind and Goto, so it doesn't get its own
BasicCoverageBlock anymore. This changed a couple of coverage regions,
but I validated those changes are not any worse than the prior results,
and probably help assure some consistency (even if some people might
disagree with how the code region is consistently computed).
Fixed issue with async/await. AggregateKind::Generator needs to be
handled like AggregateKind::Closure; coverage span for the outer async
function should not "cover" the async body, which is actually executed
in a separate "closure" MIR.
Fix some clippy lints
Happy to revert these if you think they're less readable, but personally I like them better now (especially the `else { if { ... } }` to `else if { ... }` change).
Added one more test (two files) showing coverage of generics and unused
functions across crates.
Created and referenced new Issues, as requested.
Added comments.
Added a note about the possible effects of compiler options on LLVM
coverage maps.
Fixes multiple issue with counters, with simplification
Includes a change to the implicit else span in ast_lowering, so coverage
of the implicit else no longer spans the `then` block.
Adds coverage for unused closures and async function bodies.
Fixes: #78542
Adding unreachable regions for known MIR missing from coverage map
Cleaned up PR commits, and removed link-dead-code requirement and tests
Coverage no longer depends on Issue #76038 (`-C link-dead-code` is
no longer needed or enforced, so MSVC can use the same tests as
Linux and MacOS now)
Restrict adding unreachable regions to covered files
Improved the code that adds coverage for uncalled functions (with MIR
but not-codegenned) to avoid generating coverage in files not already
included in the files with covered functions.
Resolved last known issue requiring --emit llvm-ir workaround
Fixed bugs in how unreachable code spans were added.
Tested and validate results for panic unwind, panic abort, assert!()
macro, TerminatorKind::Assert (for example, numeric overflow), and
async/await.
Implemented a previous documented idea to change Assert handling to be
the same as FalseUnwind and Goto, so it doesn't get its own
BasicCoverageBlock anymore. This changed a couple of coverage regions,
but I validated those changes are not any worse than the prior results,
and probably help assure some consistency (even if some people might
disagree with how the code region is consistently computed).
Fixed issue with async/await. AggregateKind::Generator needs to be
handled like AggregateKind::Closure; coverage span for the outer async
function should not "cover" the async body, which is actually executed
in a separate "closure" MIR.
Fix `unknown-crate` when using -Z self-profile with rustdoc
... by removing a duplicate `crate_name` field in `interface::Config`,
making it clear that rustdoc should be passing it to `config::Options` instead.
Unblocks https://github.com/rust-lang/rustc-perf/issues/797.
Revert "Auto merge of #79209
r? `@nikomatsakis`
This has caused some issues (#79560) so better to revert and try to come up with a proper fix without rush.
Do not show negative polarity trait implementations in diagnostic messages for similar implementations
This fixes#79458.
Previously, this code:
```rust
#[derive(Clone)]
struct Foo<'a, T> {
x: &'a mut T,
}
```
would have suggested that `<&mut T as Clone>` was an implementation that was found. This is due to the fact that the standard library now has `impl<'_, T> !Clone for &'_ mut T`, and explicit negative polarity implementations were not filtered out in diagnostic output when suggesting similar implementations.
This PR fixes this issue by filtering out negative polarity trait implementations in `find_similar_impl_candidates` within `rustc_trait_selection::traits::error_reporting::InferCtxtPrivExt<'tcx>`. It also adds a UI regression test for this issue and fixes UI tests that had incorrectly been modified to expect the invalid output.
r? `@scottmcm`
Use true previous lint level when detecting overriden forbids
Previously, cap-lints was ignored when checking the previous forbid level, which
meant that it was a hard error to do so. This is different from the normal
behavior of lints, which are silenced by cap-lints; if the forbid would not take
effect regardless, there is not much point in complaining about the fact that we
are reducing its level.
It might be considered a bug that even `--cap-lints deny` would suffice to
silence the error on overriding forbid, depending on if one cares about failing
the build or precisely forbid being set. But setting cap-lints to deny is quite
odd and not really done in practice, so we don't try to handle it specially.
This also unifies the code paths for nested and same-level scopes. However, the
special case for CLI lint flags is left in place (introduced by #70918) to fix
the regression noted in #70819. That means that CLI flags do not lint on forbid
being overridden by a non-forbid level. It is unclear whether this is a bug or a
desirable feature, but it is certainly inconsistent. CLI flags are a
sufficiently different "type" of place though that this is deemed out of scope
for this commit.
r? `@pnkfelix` perhaps?
cc #77713 -- not marking as "Fixes" because of the lack of proper unused attribute handling in this PR
Warn if `dsymutil` returns an error code
This checks the error code returned by `dsymutil` and warns if it failed. It
also provides the stdout and stderr logs from `dsymutil`, similar to the native
linker step.
I tried to think of ways to test this change, but so far I haven't found a good way, as you'd likely need to inject some nonsensical args into `dsymutil` to induce failure, which feels too artificial to me. Also, https://github.com/rust-lang/rust/issues/79361 suggests Rust is on the verge of disabling `dsymutil` by default, so perhaps it's okay for this change to be untested. In any case, I'm happy to add a test if someone sees a good approach.
Fixes https://github.com/rust-lang/rust/issues/78770
Add wasm32 support to inline asm
There is some contention around inline asm and wasm, and I really only made this to figure out the process of hacking on rustc, but I figured as long as the code existed, it was worth uploading.
cc `@Amanieu`
Implement lazy decoding of DefPathTable during incremental compilation
PR https://github.com/rust-lang/rust/pull/75813 implemented lazy decoding of the `DefPathTable` from crate metadata. However, it requires decoding the entire `DefPathTable` when incremental compilation is active, so that we can map a decoded `DefPathHash` to a `DefId` from an arbitrary crate.
This PR adds support for lazy decoding of dependency `DefPathTable`s when incremental compilation si active.
When we load the incremental cache and dep
graph, we need the ability to map a `DefPathHash` to a `DefId` in the
current compilation session (if the corresponding definition still
exists).
This is accomplished by storing the old `DefId` (that is, the `DefId`
from the previous compilation session) for each `DefPathHash` we need to
remap. Since a `DefPathHash` includes the owning crate, the old crate is
guaranteed to be the right one (if the definition still exists). We then
use the old `DefIndex` as an initial guess, which we validate by
comparing the expected and actual `DefPathHash`es. In most cases,
foreign crates will be completely unchanged, which means that we our
guess will be correct. If our guess is wrong, we fall back to decoding
the entire `DefPathTable` for the foreign crate. This still represents
an improvement over the status quo, since we can skip decoding the
entire `DefPathTable` for other crates (where all of our guesses were
correct).
Validate lint docs separately.
This addresses some concerns raised in https://github.com/rust-lang/rust/pull/76549#issuecomment-727638552 about errors with the lint docs being confusing and cumbersome. Errors from validating the lint documentation were being generated during `x.py doc` (and `x.py dist`), since extraction and validation are being done in a single step. This changes it so that extraction and validation are separated, so that `x.py doc` will not error if there is a validation problem, and tests are moved to `x.py test src/tools/lint-docs`.
This includes the following changes:
* Separate validation to `x.py test`.
* Added some more documentation on how to more easily modify and test the docs.
* Added more help to the error messages to hopefully provide more information on how to fix things.
The first commit just moves the code around, so you may consider looking at the other commits for a smaller diff.
Stop adding '*' at the end of slice and str typenames for MSVC case
When computing debug info for MSVC debuggers, Rust compiler emits C++ style type names for compatibility with .natvis visualizers. All Ref types are treated as equivalences of C++ pointers in this process, and, as a result, their type names end with a '\*'. Since Slice and Str are treated as Ref by the compiler, their type names also end with a '\*'. This causes the .natvis engine for WinDbg fails to display data of Slice and Str objects. We addressed this problem simply by removing the '*' at the end of type names for Slice and Str types.
Debug info in WinDbg before the fix:

Debug info in WinDbg after the fix:
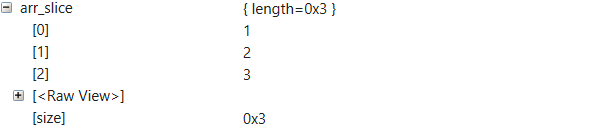
This change has also been tested with debuggers for Visual Studio, VS Code C++ and VS Code LLDB to make sure that it does not affect the behavior of other kinds of debugger.
This checks the error code returned by `dsymutil` and warns if it failed. It
also provides the stdout and stderr logs from `dsymutil`, similar to the native
linker step.
Fixes https://github.com/rust-lang/rust/issues/78770
Update error to reflect that integer literals can have float suffixes
For example, `1` is parsed as an integer literal, but it can be turned
into a float with the suffix `f32`. Now the error calls them "numeric
literals" and notes that you can add a float suffix since they can be
either integers or floats.
Fix overlap detection of `usize`/`isize` range patterns
`usize` and `isize` are a bit of a special case in the match usefulness algorithm, because the range of values they contain depends on the platform. Specifically, we don't want `0..usize::MAX` to count as an exhaustive match (see also [`precise_pointer_size_matching`](https://github.com/rust-lang/rust/issues/56354)). The way this was initially implemented is by treating those ranges like float ranges, i.e. with limited cleverness. This means we didn't catch the following as unreachable:
```rust
match 0usize {
0..10 => {},
10..20 => {},
5..15 => {}, // oops, should be detected as unreachable
_ => {},
}
```
This PRs fixes this oversight. Now the only difference between `usize` and `u64` range patterns is in what ranges count as exhaustive.
r? `@varkor`
`@rustbot` label +A-exhaustiveness-checking
This commit modifies the `check_attr` pass so that attribute placement
on generic parameters is checked for validity.
Signed-off-by: David Wood <david@davidtw.co>
Don't run `resolve_vars_if_possible` in `normalize_erasing_regions`
Neither `@eddyb` nor I could figure out what this was for. I changed it to `assert_eq!(normalized_value, infcx.resolve_vars_if_possible(&normalized_value));` and it passed the UI test suite.
<details><summary>
Outdated, I figured out the issue - `needs_infer()` needs to come _after_ erasing the lifetimes
</summary>
Strangely, if I change it to `assert!(!normalized_value.needs_infer())` it panics almost immediately:
```
query stack during panic:
#0 [normalize_generic_arg_after_erasing_regions] normalizing `<str::IsWhitespace as str::pattern::Pattern>::Searcher`
#1 [needs_drop_raw] computing whether `str::iter::Split<str::IsWhitespace>` needs drop
#2 [mir_built] building MIR for `str::<impl str>::split_whitespace`
#3 [unsafety_check_result] unsafety-checking `str::<impl str>::split_whitespace`
#4 [mir_const] processing MIR for `str::<impl str>::split_whitespace`
#5 [mir_promoted] processing `str::<impl str>::split_whitespace`
#6 [mir_borrowck] borrow-checking `str::<impl str>::split_whitespace`
#7 [analysis] running analysis passes on this crate
end of query stack
```
I'm not entirely sure what's going on - maybe the two disagree?
</details>
For context, this came up while reviewing https://github.com/rust-lang/rust/pull/77467/ (cc `@lcnr).`
Possibly this needs a crater run?
r? `@nikomatsakis`
cc `@matthewjasper`
Support repr(simd) on ADTs containing a single array field
This is a squash and rebase of `@gnzlbg's` #63531
I've never actually written code in the compiler before so just fumbled my way around until it would build 😅
I imagine there'll be some work we need to do in `rustc_codegen_cranelift` too for this now, but might need some input from `@bjorn3` to know what that is.
cc `@rust-lang/project-portable-simd`
-----
This PR allows using `#[repr(simd)]` on ADTs containing a single array field:
```rust
#[repr(simd)] struct S0([f32; 4]);
#[repr(simd)] struct S1<const N: usize>([f32; N]);
#[repr(simd)] struct S2<T, const N: usize>([T; N]);
```
This should allow experimenting with portable packed SIMD abstractions on nightly that make use of const generics.
Extend doc keyword feature by allowing any ident
Part of #51315.
As suggested by ``@danielhenrymantilla`` in [this comment](https://github.com/rust-lang/rust/issues/51315#issuecomment-733879934), this PR extends `#[doc(keyword = "...")]` to allow any ident to be used as keyword. The final goal is to allow (proc-)macro crates' owners to write documentation of the keywords they might introduce.
r? ``@jyn514``
Sync rustc_codegen_cranelift
This implements a few extra simd intrinsics, fixes yet another 128bit bug and updates a few dependencies. It also fixes an cg_clif subtree update that did compile, but that caused a panic when compiling libcore. Other than that this is mostly cleanups.
`@rustbot` modify labels: +A-codegen +A-cranelift +T-compiler
rustc_parse: fix ConstBlock expr span
The span for a ConstBlock expression should presumably run through the end of the block it contains and not stop at the keyword, just like is done with similar block-containing expression kinds, such as a TryBlock
Properly handle attributes on statements
We now collect tokens for the underlying node wrapped by `StmtKind`
nstead of storing tokens directly in `Stmt`.
`LazyTokenStream` now supports capturing a trailing semicolon after it
is initially constructed. This allows us to avoid refactoring statement
parsing to wrap the parsing of the semicolon in `parse_tokens`.
Attributes on item statements
(e.g. `fn foo() { #[bar] struct MyStruct; }`) are now treated as
item attributes, not statement attributes, which is consistent with how
we handle attributes on other kinds of statements. The feature-gating
code is adjusted so that proc-macro attributes are still allowed on item
statements on stable.
Two built-in macros (`#[global_allocator]` and `#[test]`) needed to be
adjusted to support being passed `Annotatable::Stmt`.
For example, `1` is parsed as an integer literal, but it can be turned
into a float with the suffix `f32`. Now the error calls them "numeric
literals" and notes that you can add a float suffix since they can be
either integers or floats.
Split match exhaustiveness into two files
I feel the constructor-related things in the `_match` module make enough sense on their own so I split them off. It makes `_match` feel less like a complicated mess. I'm not aware of PRs in progress against this module apart from my own so hopefully I'm not annoying too many people.
I have a lot of questions about the conventions in naming and modules around the compiler. Like, why is the module named `_match`? Could I rename it to `usefulness` maybe? Should `deconstruct_pat` be a submodule of `_match` since only `_match` uses it? Is it ok to move big piles of code around even if it makes git blame more difficult?
r? `@varkor`
`@rustbot` modify labels: +A-exhaustiveness-checking
Add support for Arm64 Catalyst on ARM Macs
This is an iteration on https://github.com/rust-lang/rust/pull/63467 which was merged a while ago. In the aforementioned PR, I added support for the `X86_64-apple-ios-macabi` target triple, which is Catalyst, iOS apps running on macOS.
Very soon, Apple will launch ARM64 based Macs which will introduce `aarch64_apple_darwin.rs`, macOS apps using the Darwin ABI running on ARM. This PR adds support for Catalyst apps on ARM Macs: iOS apps compiled for the darwin ABI.
I don't have access to a Apple Developer Transition Kit (DTK), so I can't really test if the generated binaries work correctly. I'm vaguely hopeful that somebody with access to a DTK could give this a spin.
This preserves the current lint behavior for now.
Linting after item statements currently prevents the compiler from bootstrapping.
Fixing this is blocked on fixing this upstream in Cargo, and bumping the Cargo
submodule.
When parsing a statement (e.g. inside a function body),
we now consider `struct Foo {};` and `$stmt;` to each consist
of two statements: `struct Foo {}` and `;`, and `$stmt` and `;`.
As a result, an attribute macro invoke as
`fn foo() { #[attr] struct Bar{}; }` will see `struct Bar{}` as its
input. Additionally, the 'unused semicolon' lint now fires in more
places.
We now collect tokens for the underlying node wrapped by `StmtKind`
instead of storing tokens directly in `Stmt`.
`LazyTokenStream` now supports capturing a trailing semicolon after it
is initially constructed. This allows us to avoid refactoring statement
parsing to wrap the parsing of the semicolon in `parse_tokens`.
Attributes on item statements
(e.g. `fn foo() { #[bar] struct MyStruct; }`) are now treated as
item attributes, not statement attributes, which is consistent with how
we handle attributes on other kinds of statements. The feature-gating
code is adjusted so that proc-macro attributes are still allowed on item
statements on stable.
Two built-in macros (`#[global_allocator]` and `#[test]`) needed to be
adjusted to support being passed `Annotatable::Stmt`.
Cache pretty-print/retokenize result to avoid compile time blowup
Fixes#79242
If a `macro_rules!` recursively builds up a nested nonterminal
(passing it to a proc-macro at each step), we will end up repeatedly
pretty-printing/retokenizing the same nonterminals. Unfortunately, the
'probable equality' check we do has a non-trivial cost, which leads to a
blowup in compilation time.
As a workaround, we cache the result of the 'probable equality' check,
which eliminates the compilation time blowup for the linked issue. This
commit only touches a single file (other than adding tests), so it
should be easy to backport.
The proper solution is to remove the pretty-print/retokenize hack
entirely. However, this will almost certainly break a large number of
crates that were relying on hygiene bugs created by using the reparsed
`TokenStream`. As a result, we will definitely not want to backport
such a change.
Always print lints from plugins, if they're available
Currently you can get a list of lints and lint groups by running `rustc
-Whelp`. This prints an additional line at the end:
```
Compiler plugins can provide additional lints and lint groups. To see a listing of these, re-run `rustc -W help` with a crate filename.
```
Clippy is such a "compiler plugin", that provides additional lints.
Running `clippy-driver -Whelp` (`rustc` wrapper) still only prints the
rustc lints with the above message at the end. But when running
`clippy-driver -Whelp main.rs`, where `main.rs` is any rust file, it
also prints Clippy lints. I don't think this is a good approach from a
UX perspective: Why is a random file necessary to print a help message?
This PR changes this behavior: Whenever a compiler callback
registers lints, it is assumed that these lints come from a plugin and
are printed without having to specify a Rust source file.
Fixesrust-lang/rust-clippy#6122
cc `@Manishearth` `@ebroto` for the Clippy changes.
Rollup of 10 pull requests
Successful merges:
- #77758 (suggest turbofish syntax for uninferred const arguments)
- #79000 (Move lev_distance to rustc_ast, make non-generic)
- #79362 (Lower patterns before using the bound variable)
- #79365 (Upgrades the coverage map to Version 4)
- #79402 (Fix typos)
- #79412 (Clean up rustdoc tests by removing unnecessary features)
- #79413 (Fix persisted doctests on Windows / when using workspaces)
- #79420 (Fixes a word typo in librustdoc)
- #79421 (Fix docs formatting for `thir::pattern::_match`)
- #79428 (Fixup compiler docs)
Failed merges:
r? `@ghost`
`@rustbot` modify labels: rollup
Upgrades the coverage map to Version 4
Changes the coverage map injected into binaries compiled with
`-Zinstrument-coverage` to LLVM Coverage Mapping Format, Version 4 (from
Version 3). Note, binaries compiled with this version will require LLVM
tools from at least LLVM Version 11.
r? ``@wesleywiser``
Move lev_distance to rustc_ast, make non-generic
rustc_ast currently has a few dependencies on rustc_lexer. Ideally, an AST
would not have any dependency its lexer, for minimizing
design-time dependencies. Breaking this dependency would also have practical
benefits, since modifying rustc_lexer would not trigger a rebuild of rustc_ast.
This commit does not remove the rustc_ast --> rustc_lexer dependency,
but it does remove one of the sources of this dependency, which is the
code that handles fuzzy matching between symbol names for making suggestions
in diagnostics. Since that code depends only on Symbol, it is easy to move
it to rustc_span. It might even be best to move it to a separate crate,
since other tools such as Cargo use the same algorithm, and have simply
contain a duplicate of the code.
This changes the signature of find_best_match_for_name so that it is no
longer generic over its input. I checked the optimized binaries, and this
function was duplicated for nearly every call site, because most call sites
used short-lived iterator chains, generic over Map and such. But there's
no good reason for a function like this to be generic, since all it does
is immediately convert the generic input (the Iterator impl) to a concrete
Vec<Symbol>. This has all of the costs of generics (duplicated method bodies)
with no benefit.
Changing find_best_match_for_name to be non-generic removed about 10KB of
code from the optimized binary. I know it's a drop in the bucket, but we have
to start reducing binary size, and beginning to tame over-use of generics
is part of that.
Resolve inference variables before trying to remove overloaded indexing
Fixes#79152
This code was already set up to handle indexing an array. However, it
appears that we never end up with an inference variable for the slice
case, so the missing call to `resolve_vars_if_possible` had no effect
until now.
Fixes#79152
This code was already set up to handle indexing an array. However, it
appears that we never end up with an inference variable for the slice
case, so the missing call to `resolve_vars_if_possible` had no effect
until now.
Validate use of parameters in naked functions
* Reject use of parameters inside naked function body.
* Reject use of patterns inside function parameters, to emphasize role
of parameters a signature declaration (mirroring existing behaviour
for function declarations) and avoid generating code introducing
specified bindings.
Closes issues below by considering input to be ill-formed.
Closes#75922.
Closes#77848.
Closes#79350.
Always invoke statement attributes on the statement itself
This is preparation for PR #78296, which will require us to handle
statement items in addition to normal items.
Rename `optin_builtin_traits` to `auto_traits`
They were originally called "opt-in, built-in traits" (OIBITs), but
people realized that the name was too confusing and a mouthful, and so
they were renamed to just "auto traits". The feature flag's name wasn't
updated, though, so that's what this PR does.
There are some other spots in the compiler that still refer to OIBITs,
but I don't think changing those now is worth it since they are internal
and not particularly relevant to this PR.
Also see <https://rust-lang.zulipchat.com/#narrow/stream/131828-t-compiler/topic/opt-in.2C.20built-in.20traits.20(auto.20traits).20feature.20name>.
r? `@oli-obk` (feel free to re-assign if you're not the right reviewer for this)
{kind=link}
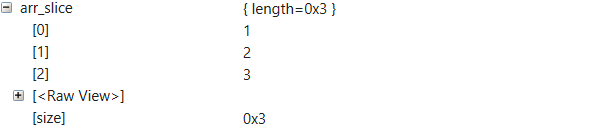{kind=link}
{kind=link}