Fix `--remap-path-prefix` not correctly remapping `rust-src` component paths and unify handling of path mapping with virtualized paths
This PR fixes#73167 ("Binaries end up containing path to the rust-src component despite `--remap-path-prefix`") by preventing real local filesystem paths from reaching compilation output if the path is supposed to be remapped.
`RealFileName::Named` introduced in #72767 is now renamed as `LocalPath`, because this variant wraps a (most likely) valid local filesystem path.
`RealFileName::Devirtualized` is renamed as `Remapped` to be used for remapped path from a real path via `--remap-path-prefix` argument, as well as real path inferred from a virtualized (during compiler bootstrapping) `/rustc/...` path. The `local_path` field is now an `Option<PathBuf>`, as it will be set to `None` before serialisation, so it never reaches any build output. Attempting to serialise a non-`None` `local_path` will cause an assertion faliure.
When a path is remapped, a `RealFileName::Remapped` variant is created. The original path is preserved in `local_path` field and the remapped path is saved in `virtual_name` field. Previously, the `local_path` is directly modified which goes against its purpose of "suitable for reading from the file system on the local host".
`rustc_span::SourceFile`'s fields `unmapped_path` (introduced by #44940) and `name_was_remapped` (introduced by #41508 when `--remap-path-prefix` feature originally added) are removed, as these two pieces of information can be inferred from the `name` field: if it's anything other than a `FileName::Real(_)`, or if it is a `FileName::Real(RealFileName::LocalPath(_))`, then clearly `name_was_remapped` would've been false and `unmapped_path` would've been `None`. If it is a `FileName::Real(RealFileName::Remapped{local_path, virtual_name})`, then `name_was_remapped` would've been true and `unmapped_path` would've been `Some(local_path)`.
cc `@eddyb` who implemented `/rustc/...` path devirtualisation
This PR implements span quoting, allowing proc-macros to produce spans
pointing *into their own crate*. This is used by the unstable
`proc_macro::quote!` macro, allowing us to get error messages like this:
```
error[E0412]: cannot find type `MissingType` in this scope
--> $DIR/auxiliary/span-from-proc-macro.rs:37:20
|
LL | pub fn error_from_attribute(_args: TokenStream, _input: TokenStream) -> TokenStream {
| ----------------------------------------------------------------------------------- in this expansion of procedural macro `#[error_from_attribute]`
...
LL | field: MissingType
| ^^^^^^^^^^^ not found in this scope
|
::: $DIR/span-from-proc-macro.rs:8:1
|
LL | #[error_from_attribute]
| ----------------------- in this macro invocation
```
Here, `MissingType` occurs inside the implementation of the proc-macro
`#[error_from_attribute]`. Previosuly, this would always result in a
span pointing at `#[error_from_attribute]`
This will make many proc-macro-related error message much more useful -
when a proc-macro generates code containing an error, users will get an
error message pointing directly at that code (within the macro
definition), instead of always getting a span pointing at the macro
invocation site.
This is implemented as follows:
* When a proc-macro crate is being *compiled*, it causes the `quote!`
macro to get run. This saves all of the sapns in the input to `quote!`
into the metadata of *the proc-macro-crate* (which we are currently
compiling). The `quote!` macro then expands to a call to
`proc_macro::Span::recover_proc_macro_span(id)`, where `id` is an
opaque identifier for the span in the crate metadata.
* When the same proc-macro crate is *run* (e.g. it is loaded from disk
and invoked by some consumer crate), the call to
`proc_macro::Span::recover_proc_macro_span` causes us to load the span
from the proc-macro crate's metadata. The proc-macro then produces a
`TokenStream` containing a `Span` pointing into the proc-macro crate
itself.
The recursive nature of 'quote!' can be difficult to understand at
first. The file `src/test/ui/proc-macro/quote-debug.stdout` shows
the output of the `quote!` macro, which should make this eaier to
understand.
This PR also supports custom quoting spans in custom quote macros (e.g.
the `quote` crate). All span quoting goes through the
`proc_macro::quote_span` method, which can be called by a custom quote
macro to perform span quoting. An example of this usage is provided in
`src/test/ui/proc-macro/auxiliary/custom-quote.rs`
Custom quoting currently has a few limitations:
In order to quote a span, we need to generate a call to
`proc_macro::Span::recover_proc_macro_span`. However, proc-macros
support renaming the `proc_macro` crate, so we can't simply hardcode
this path. Previously, the `quote_span` method used the path
`crate::Span` - however, this only works when it is called by the
builtin `quote!` macro in the same crate. To support being called from
arbitrary crates, we need access to the name of the `proc_macro` crate
to generate a path. This PR adds an additional argument to `quote_span`
to specify the name of the `proc_macro` crate. Howver, this feels kind
of hacky, and we may want to change this before stabilizing anything
quote-related.
Additionally, using `quote_span` currently requires enabling the
`proc_macro_internals` feature. The builtin `quote!` macro
has an `#[allow_internal_unstable]` attribute, but this won't work for
custom quote implementations. This will likely require some additional
tricks to apply `allow_internal_unstable` to the span of
`proc_macro::Span::recover_proc_macro_span`.
using allow_internal_unstable (as recommended)
Fixes: #84836
```shell
$ ./build/x86_64-unknown-linux-gnu/stage1/bin/rustc src/test/run-make-fulldeps/coverage/no_cov_crate.rs
error[E0554]: `#![feature]` may not be used on the dev release channel
--> src/test/run-make-fulldeps/coverage/no_cov_crate.rs:2:1
|
2 | #![feature(no_coverage)]
| ^^^^^^^^^^^^^^^^^^^^^^^^
error: aborting due to previous error
For more information about this error, try `rustc --explain E0554`.
```
The Eq trait has a special hidden function. MIR `InstrumentCoverage`
would add this function to the coverage map, but it is never called, so
the `Eq` trait would always appear uncovered.
Fixes: #83601
The fix required creating a new function attribute `no_coverage` to mark
functions that should be ignored by `InstrumentCoverage` and the
coverage `mapgen` (during codegen).
While testing, I also noticed two other issues:
* spanview debug file output ICEd on a function with no body. The
workaround for this is included in this PR.
* `assert_*!()` macro coverage can appear covered if followed by another
`assert_*!()` macro. Normally they appear uncovered. I submitted a new
Issue #84561, and added a coverage test to demonstrate this issue.
This PR modifies the macro expansion infrastructure to handle attributes
in a fully token-based manner. As a result:
* Derives macros no longer lose spans when their input is modified
by eager cfg-expansion. This is accomplished by performing eager
cfg-expansion on the token stream that we pass to the derive
proc-macro
* Inner attributes now preserve spans in all cases, including when we
have multiple inner attributes in a row.
This is accomplished through the following changes:
* New structs `AttrAnnotatedTokenStream` and `AttrAnnotatedTokenTree` are introduced.
These are very similar to a normal `TokenTree`, but they also track
the position of attributes and attribute targets within the stream.
They are built when we collect tokens during parsing.
An `AttrAnnotatedTokenStream` is converted to a regular `TokenStream` when
we invoke a macro.
* Token capturing and `LazyTokenStream` are modified to work with
`AttrAnnotatedTokenStream`. A new `ReplaceRange` type is introduced, which
is created during the parsing of a nested AST node to make the 'outer'
AST node aware of the attributes and attribute target stored deeper in the token stream.
* When we need to perform eager cfg-expansion (either due to `#[derive]` or `#[cfg_eval]`),
we tokenize and reparse our target, capturing additional information about the locations of
`#[cfg]` and `#[cfg_attr]` attributes at any depth within the target.
This is a performance optimization, allowing us to perform less work
in the typical case where captured tokens never have eager cfg-expansion run.
Use AnonConst for asm! constants
This replaces the old system which used explicit promotion. See #83169 for more background.
The syntax for `const` operands is still the same as before: `const <expr>`.
Fixes#83169
Because the implementation is heavily based on inline consts, we suffer from the same issues:
- We lose the ability to use expressions derived from generics. See the deleted tests in `src/test/ui/asm/const.rs`.
- We are hitting the same ICEs as inline consts, for example #78174. It is unlikely that we will be able to stabilize this before inline consts are stabilized.
Don't ICE when using `#[global_alloc]` on a non-item statement
Fixes#83469
We need to return an `Annotatable::Stmt` if we were passed an
`Annotatable::Stmt`
Emit error when trying to use assembler syntax directives in `asm!`
The `.intel_syntax` and `.att_syntax` assembler directives should not be used, in favor of not specifying a syntax for intel, and in favor of the explicit `att_syntax` option using the inline assembly options.
Closes#79869
StructField -> FieldDef ("field definition")
Field -> ExprField ("expression field", not "field expression")
FieldPat -> PatField ("pattern field", not "field pattern")
Also rename visiting and other methods working on them.
Edition-specific preludes
This changes `{std,core}::prelude` to export edition-specific preludes under `rust_2015`, `rust_2018` and `rust_2021`. (As suggested in https://github.com/rust-lang/rust/issues/51418#issuecomment-395630382.) For now they all just re-export `v1::*`, but this allows us to add things to the 2021edition prelude soon.
This also changes the compiler to make the automatically injected prelude import dependent on the selected edition.
cc `@rust-lang/libs` `@djc`
Implement built-in attribute macro `#[cfg_eval]` + some refactoring
This PR implements a built-in attribute macro `#[cfg_eval]` as it was suggested in https://github.com/rust-lang/rust/pull/79078 to avoid `#[derive()]` without arguments being abused as a way to configure input for other attributes.
The macro is used for eagerly expanding all `#[cfg]` and `#[cfg_attr]` attributes in its input ("fully configuring" the input).
The effect is identical to effect of `#[derive(Foo, Bar)]` which also fully configures its input before passing it to macros `Foo` and `Bar`, but unlike `#[derive]` `#[cfg_eval]` can be applied to any syntax nodes supporting macro attributes, not only certain items.
`cfg_eval` was the first name suggested in https://github.com/rust-lang/rust/pull/79078, but other alternatives are also possible, e.g. `cfg_expand`.
```rust
#[cfg_eval]
#[my_attr] // Receives `struct S {}` as input, the field is configured away by `#[cfg_eval]`
struct S {
#[cfg(FALSE)]
field: u8,
}
```
Tracking issue: https://github.com/rust-lang/rust/issues/82679
Crate root is sufficiently different from `mod` items, at least at syntactic level.
Also remove customization point for "`mod` item or crate root" from AST visitors.
The derived implementation of `partial_cmp` compares matching fields one
by one, stopping the computation when the result of a comparison is not
equal to `Some(Equal)`.
On the other hand the derived implementation for `lt`, `le`, `gt` and
`ge` continues the computation when the result of a field comparison is
`None`, consequently those operators are not transitive and inconsistent
with `partial_cmp`.
Fix the inconsistency by using the default implementation that fall-backs
to the `partial_cmp`. This also avoids creating very deeply nested
closures that were quite costly to compile.
Fix bug with assert!() calling the wrong edition of panic!().
The span of `panic!` produced by the `assert` macro did not carry the right edition. This changes `assert` to call the right version.
Also adds tests for the 2021 edition of panic and assert, that would've caught this.
Box the biggest ast::ItemKind variants
This PR is a different approach on https://github.com/rust-lang/rust/pull/81400, aiming to save memory in humongous ASTs.
The three affected item kind enums are:
- `ast::ItemKind` (208 -> 112 bytes)
- `ast::AssocItemKind` (176 -> 72 bytes)
- `ast::ForeignItemKind` (176 -> 72 bytes)
Implement Rust 2021 panic
This implements the Rust 2021 versions of `panic!()`. See https://github.com/rust-lang/rust/issues/80162 and https://github.com/rust-lang/rfcs/pull/3007.
It does so by replacing `{std, core}::panic!()` by a bulitin macro that expands to either `$crate::panic::panic_2015!(..)` or `$crate::panic::panic_2021!(..)` depending on the edition of the caller.
This does not yet make std's panic an alias for core's panic on Rust 2021 as the RFC proposes. That will be a separate change: c5273bdfb2 That change is blocked on figuring out what to do with https://github.com/rust-lang/rust/issues/80846 first.
Expand assert!(expr, args..) to include $crate for hygiene on 2021.
This makes `assert!(expr, args..)` properly hygienic in Rust 2021.
This is part of rust-lang/rfcs#3007, see #80162.
Before edition 2021, this was a breaking change, as `std::panic` and `core::panic` are different. In edition 2021 they will be identical, making it possible to apply proper hygiene here.
Fixes#81007
Previously, we would fail to collect tokens in the proper place when
only builtin attributes were present. As a result, we would end up with
attribute tokens in the collected `TokenStream`, leading to duplication
when we attempted to prepend the attributes from the AST node.
We now explicitly track when token collection must be performed due to
nomterminal parsing.
Before 2021, this was a breaking change, as std::panic and core::panic
are different. In edition 2021 they will be identical, making it
possible again to apply proper hygiene here.
This makes it possible to have both std::panic and core::panic as a
builtin macro, by using different builtin macro names for each.
Also removes SyntaxExtension::is_derive_copy, as the macro name (e.g.
sym::Copy) is now tracked and provides that information directly.
- Adds optional default values to const generic parameters in the AST
and HIR
- Parses these optional default values
- Adds a `const_generics_defaults` feature gate
We now collect tokens for the underlying node wrapped by `StmtKind`
instead of storing tokens directly in `Stmt`.
`LazyTokenStream` now supports capturing a trailing semicolon after it
is initially constructed. This allows us to avoid refactoring statement
parsing to wrap the parsing of the semicolon in `parse_tokens`.
Attributes on item statements
(e.g. `fn foo() { #[bar] struct MyStruct; }`) are now treated as
item attributes, not statement attributes, which is consistent with how
we handle attributes on other kinds of statements. The feature-gating
code is adjusted so that proc-macro attributes are still allowed on item
statements on stable.
Two built-in macros (`#[global_allocator]` and `#[test]`) needed to be
adjusted to support being passed `Annotatable::Stmt`.
Add lint for panic!("{}")
This adds a lint that warns about `panic!("{}")`.
`panic!(msg)` invocations with a single argument use their argument as panic payload literally, without using it as a format string. The same holds for `assert!(expr, msg)`.
This lints checks if `msg` is a string literal (after expansion), and warns in case it contained braces. It suggests to insert `"{}", ` to use the message literally, or to add arguments to use it as a format string.
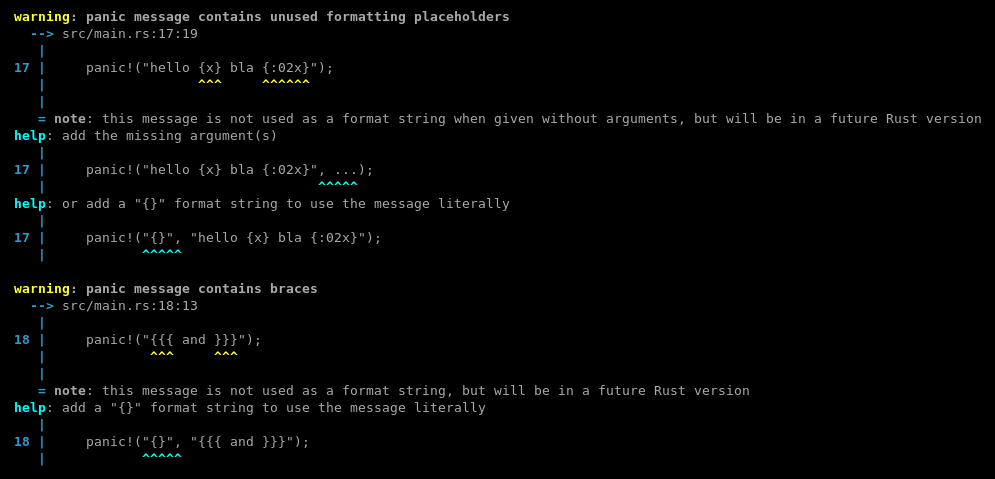
This lint is also a good starting point for adding warnings about `panic!(not_a_string)` later, once [`panic_any()`](https://github.com/rust-lang/rust/pull/74622) becomes a stable alternative.
cleanup: Remove `ParseSess::injected_crate_name`
Its only remaining use is in pretty-printing where the necessary information can be easily re-computed.
The discussion seems to have resolved that this lint is a bit "noisy" in
that applying it in all places would result in a reduction in
readability.
A few of the trivial functions (like `Path::new`) are fine to leave
outside of closures.
The general rule seems to be that anything that is obviously an
allocation (`Box`, `Vec`, `vec![]`) should be in a closure, even if it
is a 0-sized allocation.
rustc_target: Further cleanup use of target options
Follow up to https://github.com/rust-lang/rust/pull/77729.
Implements items 2 and 4 from the list in https://github.com/rust-lang/rust/pull/77729#issue-500228243.
The first commit collapses uses of `target.options.foo` into `target.foo`.
The second commit renames some target options to avoid tautology:
`target.target_endian` -> `target.endian`
`target.target_c_int_width` -> `target.c_int_width`
`target.target_os` -> `target.os`
`target.target_env` -> `target.env`
`target.target_vendor` -> `target.vendor`
`target.target_family` -> `target.os_family`
`target.target_mcount` -> `target.mcount`
r? `@Mark-Simulacrum`
with an eye on merging `TargetOptions` into `Target`.
`TargetOptions` as a separate structure is mostly an implementation detail of `Target` construction, all its fields logically belong to `Target` and available from `Target` through `Deref` impls.
This allows us to avoid synthesizing tokens in `prepend_attr`, since we
have the original tokens available.
We still need to synthesize tokens when expanding `cfg_attr`,
but this is an unavoidable consequence of the syntax of `cfg_attr` -
the user does not supply the `#` and `[]` tokens that a `cfg_attr`
expands to.
Preparation for a subsequent change that replaces
rustc_target::config::Config with its wrapped Target.
On its own, this commit breaks the build. I don't like making
build-breaking commits, but in this instance I believe that it
makes review easier, as the "real" changes of this PR can be
seen much more easily.
Result of running:
find compiler/ -type f -exec sed -i -e 's/target\.target\([)\.,; ]\)/target\1/g' {} \;
find compiler/ -type f -exec sed -i -e 's/target\.target$/target/g' {} \;
find compiler/ -type f -exec sed -i -e 's/target.ptr_width/target.pointer_width/g' {} \;
./x.py fmt
Since 63793 the discriminant_value intrinsic is safe to call. Remove
unnecessary unsafe block around calls to this intrinsic in built-in
derive macros.
We currently only attach tokens when parsing a `:stmt` matcher for a
`macro_rules!` macro. Proc-macro attributes on statements are still
unstable, and need additional work.
Previous implementation used the `Parser::parse_expr` function in order
to extract the format expression. If the first comma following the
format expression was mistakenly replaced with a dot, then the next
format expression was eaten by the function, because it looked as a
syntactically valid expression, which resulted in incorrectly spanned
error messages.
The way the format expression is exctracted is changed: we first look at
the first available token in the first argument supplied to the
`format!` macro call. If it is a string literal, then it is promoted as
a format expression immediatly, otherwise we fall back to the original
`parse_expr`-related method.
This allows us to ensure that the parser won't consume too much tokens
when a typo is made.
A test has been created so that it is ensured that the issue is properly
fixed.
{kind=link}