Now that we require at least LLVM 13, that codegen backend is always
using its intrinsic `fptosi.sat` and `fptoui.sat` conversions, so it
doesn't need the manual implementation. However, the GCC backend still
needs it, so we can move all of that code down there.
Update the minimum external LLVM to 13
With this change, we'll have stable support for LLVM 13 through 15 (pending release).
For reference, the previous increase to LLVM 12 was #90175.
r? `@nagisa`
Add support for generating unique profraw files by default when using `-C instrument-coverage`
Currently, enabling the rustc flag `-C instrument-coverage` instruments the given crate and by default uses the naming scheme `default.profraw` for any instrumented profile files generated during the execution of a binary linked against this crate. This leads to multiple binaries being executed overwriting one another and causing only the last executable run to contain actual coverage results.
This can be overridden by manually setting the environment variable `LLVM_PROFILE_FILE` to use a unique naming scheme.
This PR adds a change to add support for a reasonable default for rustc to use when enabling coverage instrumentation similar to how the Rust compiler treats generating these same `profraw` files when PGO is enabled.
The new naming scheme is set to `default_%m_%p.profraw` to ensure the uniqueness of each file being generated using [LLVMs special pattern strings](https://clang.llvm.org/docs/SourceBasedCodeCoverage.html#running-the-instrumented-program).
Today the compiler sets the default for PGO `profraw` files to `default_%m.profraw` to ensure a unique file for each run. The same can be done for the instrumented profile files generated via the `-C instrument-coverage` flag as well which LLVM has API support for.
Linked Issue: https://github.com/rust-lang/rust/issues/100381
r? `@wesleywiser`
debuginfo: Generalize C++-like encoding for enums.
The updated encoding should be able to handle niche layouts where more than one variant has fields (as introduced in https://github.com/rust-lang/rust/pull/94075).
The new encoding is more uniform as there is no structural difference between direct-tag, niche-tag, and no-tag layouts anymore. The only difference between those cases is that the "dataful" variant in a niche-tag enum will have a `(start, end)` pair denoting the tag range instead of a single value.
The new encoding now also supports 128-bit tags, which occur in at least some standard library types. These tags are represented as `u64` pairs so that debuggers (which don't always have support for 128-bit integers) can reliably deal with them. The downside is that this adds quite a bit of complexity to the encoding and especially to the corresponding NatVis.
The new encoding seems to increase the size of (x86_64-pc-windows-msvc) debuginfo by 10-15%. The size of binaries is not affected (release builds were built with `-Cdebuginfo=2`, numbers are in kilobytes):
EXE | before | after | relative
-- | -- | -- | --
cargo (debug) | 40453 | 40450 | +0%
ripgrep (debug) | 10275 | 10273 | +0%
cargo (release) | 16186 | 16185 | +0%
ripgrep (release) | 4727 | 4726 | +0%
PDB | before | after | relative
-- | -- | -- | --
cargo (debug) | 236524 | 261412 | +11%
ripgrep (debug) | 53140 | 59060 | +11%
cargo (release) | 148516 | 169620 | +14%
ripgrep (release) | 10676 | 11804 | +11%
Given that the new encoding is more general, this is to be expected. Only platforms using C++-like debuginfo are affected -- which currently is only `*-pc-windows-msvc`.
*TODO*
- [x] Properly update documentation
- [x] Add regression tests for new optimized enum layouts as introduced by #94075.
r? `@wesleywiser`
https://reviews.llvm.org/D120026 changed atomics on thumbv6m to
use libatomic, to ensure that atomic load/store are compatible with
atomic RMW/CAS. However, Rust wants to expose only load/store
without libcalls.
https://reviews.llvm.org/D130480 added support for this behind
the +atomics-32 target feature, so enable that feature.
Introduce an ArchiveBuilderBuilder
This avoids monomorphizing all linker code for each codegen backend and will allow passing in extra information to the archive builder from the codegen backend. I'm going to use this in https://github.com/rust-lang/rust/pull/97485 to allow passing in the right function to extract symbols from object files to a generic archive builder to be used by cg_llvm, cg_clif and cg_gcc.
This avoids monomorphizing all linker code for each codegen backend and
will allow passing in extra information to the archive builder from the
codegen backend.
codegen: use new {re,de,}allocator annotations in llvm
This obviates the patch that teaches LLVM internals about
_rust_{re,de}alloc functions by putting annotations directly in the IR
for the optimizer.
The sole test change is required to anchor FileCheck to the body of the
`box_uninitialized` method, so it doesn't see the `allocalign` on
`__rust_alloc` and get mad about the string `alloca` showing up. Since I
was there anyway, I added some checks on the attributes to prove the
right attributes got set.
r? `@nikic`
This obviates the patch that teaches LLVM internals about
_rust_{re,de}alloc functions by putting annotations directly in the IR
for the optimizer.
The sole test change is required to anchor FileCheck to the body of the
`box_uninitialized` method, so it doesn't see the `allocalign` on
`__rust_alloc` and get mad about the string `alloca` showing up. Since I
was there anyway, I added some checks on the attributes to prove the
right attributes got set.
While we're here, we also emit allocator attributes on
__rust_alloc_zeroed. This should allow LLVM to perform more
optimizations for zeroed blocks, and probably fixes#90032. [This
comment](https://github.com/rust-lang/rust/issues/24194#issuecomment-308791157)
mentions "weird UB-like behaviour with bitvec iterators in
rustc_data_structures" so we may need to back this change out if things
go wrong.
The new test cases require LLVM 15, so we copy them into LLVM
14-supporting versions, which we can delete when we drop LLVM 14.
Enable raw-dylib for bin crates
Fixes#93842
When `raw-dylib` is used in a `bin` crate, we need to collect all of the `raw-dylib` functions, generate the import library and add that to the linker command line.
I also changed the tests so that 1) the C++ dlls are created after the Rust dlls, thus there is no chance of accidentally using them in the Rust linking process and 2) disabled generating import libraries when building with MSVC.
Add fine-grained LLVM CFI support to the Rust compiler
This PR improves the LLVM Control Flow Integrity (CFI) support in the Rust compiler by providing forward-edge control flow protection for Rust-compiled code only by aggregating function pointers in groups identified by their return and parameter types.
Forward-edge control flow protection for C or C++ and Rust -compiled code "mixed binaries" (i.e., for when C or C++ and Rust -compiled code share the same virtual address space) will be provided in later work as part of this project by identifying C char and integer type uses at the time types are encoded (see Type metadata in the design document in the tracking issue https://github.com/rust-lang/rust/issues/89653).
LLVM CFI can be enabled with -Zsanitizer=cfi and requires LTO (i.e., -Clto).
Thank you again, `@eddyb,` `@nagisa,` `@pcc,` and `@tmiasko` for all the help!
Add support for LLVM ShadowCallStack.
LLVMs ShadowCallStack provides backward edge control flow integrity protection by using a separate shadow stack to store and retrieve a function's return address.
LLVM currently only supports this for AArch64 targets. The x18 register is used to hold the pointer to the shadow stack, and therefore this only works on ABIs which reserve x18. Further details are available in the [LLVM ShadowCallStack](https://clang.llvm.org/docs/ShadowCallStack.html) docs.
# Usage
`-Zsanitizer=shadow-call-stack`
# Comments/Caveats
* Currently only enabled for the aarch64-linux-android target
* Requires the platform to define a runtime to initialize the shadow stack, see the [LLVM docs](https://clang.llvm.org/docs/ShadowCallStack.html) for more detail.
This commit improves the LLVM Control Flow Integrity (CFI) support in
the Rust compiler by providing forward-edge control flow protection for
Rust-compiled code only by aggregating function pointers in groups
identified by their return and parameter types.
Forward-edge control flow protection for C or C++ and Rust -compiled
code "mixed binaries" (i.e., for when C or C++ and Rust -compiled code
share the same virtual address space) will be provided in later work as
part of this project by identifying C char and integer type uses at the
time types are encoded (see Type metadata in the design document in the
tracking issue #89653).
LLVM CFI can be enabled with -Zsanitizer=cfi and requires LTO (i.e.,
-Clto).
make vtable pointers entirely opaque
This implements the scheme discussed in https://github.com/rust-lang/unsafe-code-guidelines/issues/338: vtable pointers should be considered entirely opaque and not even readable by Rust code, similar to function pointers.
- We have a new kind of `GlobalAlloc` that symbolically refers to a vtable.
- Miri uses that kind of allocation when generating a vtable.
- The codegen backends, upon encountering such an allocation, call `vtable_allocation` to obtain an actually dataful allocation for this vtable.
- We need new intrinsics to obtain the size and align from a vtable (for some `ptr::metadata` APIs), since direct accesses are UB now.
I had to touch quite a bit of code that I am not very familiar with, so some of this might not make much sense...
r? `@oli-obk`
Allow to disable thinLTO buffer to support lto-embed-bitcode lld feature
Hello
This change is to fix issue (https://github.com/rust-lang/rust/issues/84395) in which passing "-lto-embed-bitcode=optimized" to lld when linking rust code via linker-plugin-lto doesn't produce the expected result.
Instead of emitting a single unified module into a llvmbc section of the linked elf, it emits multiple submodules.
This is caused because rustc emits the BC modules after running llvm `createWriteThinLTOBitcodePass` pass.
Which in turn triggers a thinLTO linkage and causes the said issue.
This patch allows via compiler flag (-Cemit-thin-lto=<bool>) to select between running `createWriteThinLTOBitcodePass` and `createBitcodeWriterPass`.
Note this pattern of selecting between those 2 passes is common inside of LLVM code.
The default is to match the old behavior.
Only compile #[used] as llvm.compiler.used for ELF targets
This returns `#[used]` to how it worked prior to the LLVM 13 update. The intention is not that this is a stable promise.
I'll add tests later today. The tests will test things that we don't actually promise, though.
It's a deliberately small patch, mostly comments. And assuming it's reviewed and lands in time, IMO it should at least be considered for uplifting to beta (so that it can be in 1.59), as the change broke many crates in the ecosystem, even if they are relying on behavior that is not guaranteed.
# Background
LLVM has two ways of preventing removal of an unused variable: `llvm.compiler.used`, which must be present in object files, but allows the linker to remove the value, and `llvm.used` which is supposed to apply to the linker as well, if possible.
Prior to LLVM 13, `llvm.used` and `llvm.compiler.used` were the same on ELF targets, although they were different elsewhere. Prior to our update to LLVM 13, we compiled `#[used]` using `llvm.used` unconditionally, even though we only ever promised behavior like `llvm.compiler.used`.
In LLVM 13, ELF targets gained some support for preventing linker removal of `llvm.used` via the SHF_RETAIN section flag. This has some compatibility issues though: Concretely: some older versions `ld.gold` (specifically ones prior to v2.36, released in Jan 2021) had a bug where it would fail to place a `#[used] #[link_section = ".init_array"]` static in between `__init_array_start`/`__init_array_end`, leading to code that does this failing to run a static constructor. This is technically not a thing we guarantee will work, is a common use case, and is needed in `libstd` (for example, to get access to `std::env::args()` even if Rust does not control `main`, such as when in a `cdylib` crate).
As a result, when updating to LLVM 13, we unconditionally switched to using `llvm.compiler.used`, which mirror the guarantees we make for `#[used]` and doesn't require the latest ld.gold. Unfortunately, this happened to break quite a bit of things in the ecosystem, as non-ELF targets had come to rely on `#[used]` being slightly stronger. In particular, there are cases where it will even break static constructors on these targets[^initinit] (and in fact, breaks way more use cases, as Mach-O uses special sections as an interface to the OS/linker/loader in many places).
As a result, we only switch to `llvm.compiler.used` on ELF[^elfish] targets. The rationale here is:
1. It is (hopefully) identical to the semantics we used prior to the LLVM13 update as prior to that update we unconditionally used `llvm.used`, but on ELF `llvm.used` was the same as `llvm.compiler.used`.
2. It seems to be how Clang compiles this, and given that they have similar (but stronger) compatibility promises, that makes sense.
[^initinit]: For Mach-O targets: It is not always guaranteed that `__DATA,__mod_init_func` is a GC root if it does not have the `S_MOD_INIT_FUNC_POINTERS` flag which we cannot add. In most cases, when ld64 transformed this section into `__DATA_CONST,__mod_init_func` it gets applied, but it's not clear that that is intentional (let alone guaranteed), and the logic is complex enough that it probably happens sometimes, and people in the wild report it occurring.
[^elfish]: Actually, there's not a great way to tell if it's ELF, so I've approximated it.
This is pretty ad-hoc and hacky! We probably should have a firmer set of guarantees here, but this change should relax the pressure on coming up with that considerably, returning it to previous levels.
---
Unsure who should review so leaving it open, but for sure CC `@nikic`
Remove branch target prologues from `#[naked] fn`
This patch hacks around rust-lang/rust#98768 for now via injecting appropriate attributes into the LLVMIR we emit for naked functions. I intend to pursue this upstream so that these attributes can be removed in general, but it's slow going wading through C++ for me.
Revert "Work around invalid DWARF bugs for fat LTO"
Since September, the toolchain has not been generating reliable DWARF
information for static variables when LTO is on. This has affected
projects in the embedded space where the use of LTO is typical. In our
case, it has kept us from bumping past the 2021-09-22 nightly toolchain
lest our debugger break. This has been a pretty dramatic regression for
people using debuggers and static variables. See #90357 for more info
and a repro case.
This commit is a mechanical revert of
d5de680e20 from PR #89041, which caused
the issue. (Note on that PR that the commit's author has requested it be
reverted.)
I have locally verified that this fixes#90357 by restoring the
functionality of both the repro case I posted on that bug, and debugger
behavior on real programs. There do not appear to be test cases for this
in the toolchain; if I've missed them, point me at 'em and I'll update
them.
Adding the option to control from rustc CLI
if the resulted ".o" bitcode module files are with
thinLTO info or regular LTO info.
Allows using "-lto-embed-bitcode=optimized" during linkage
correctly.
Signed-off-by: Ziv Dunkelman <ziv.dunkelman@nextsilicon.com>
Keep unstable target features for asm feature checking
Inline assembly uses the target features to determine which registers
are available on the current target. However it needs to be able to
access unstable target features for this.
Fixes#99071
Inline assembly uses the target features to determine which registers
are available on the current target. However it needs to be able to
access unstable target features for this.
Fixes#99071
There are several indications that we should not ZST as a ScalarInt:
- We had two ways to have ZST valtrees, either an empty `Branch` or a `Leaf` with a ZST in it.
`ValTree::zst()` used the former, but the latter could possibly arise as well.
- Likewise, the interpreter had `Immediate::Uninit` and `Immediate::Scalar(Scalar::ZST)`.
- LLVM codegen already had to special-case ZST ScalarInt.
So instead add new ZST variants to those types that did not have other variants
which could be used for this purpose.
DWARF version 5 brings a number of improvements over version 4. Quoting from
the announcement [1]:
> Version 5 incorporates improvements in many areas: better data compression,
> separation of debugging data from executable files, improved description of
> macros and source files, faster searching for symbols, improved debugging
> optimized code, as well as numerous improvements in functionality and
> performance.
On platforms where DWARF version 5 is supported (Linux, primarily), this commit
adds support for it behind a new `-Z dwarf-version=5` flag.
[1]: https://dwarfstd.org/Public_Review.php
Use less string interning
This removes string interning in a couple of places where doing so won't result in perf improvements. I also switched one place to use pre-interned symbols.
Change enum->int casts to not go through MIR casts.
follow-up to https://github.com/rust-lang/rust/pull/96814
this simplifies all backends and even gives LLVM more information about the return value of `Rvalue::Discriminant`, enabling optimizations in more cases.
Work around llvm 12's memory ordering restrictions.
Older llvm has the pre-C++17 restriction on success and failure memory ordering, requiring the former to be at least as strong as the latter. So, for llvm 12, this upgrades the success ordering to a stronger one if necessary.
See https://github.com/rust-lang/rust/issues/68464
rustc_target: Remove some redundant target properties
`is_like_emscripten` is equivalent to `os == "emscripten"`, so it's removed.
`is_like_fuchsia` is equivalent to `os == "fuchsia"`, so it's removed.
`is_like_osx` also falls into the same category and is equivalent to `vendor == "apple"`, but it's commonly used so I kept it as is for now.
`is_like_(solaris,windows,wasm)` are combinations of different operating systems or architectures (see compiler/rustc_target/src/spec/tests/tests_impl.rs) so they are also kept as is.
I think `is_like_wasm` (and maybe `is_like_osx`) are sufficiently closed sets, so we can remove these fields as well and replace them with methods like `fn is_like_wasm() { arch == "wasm32" || arch == "wasm64" }`.
On other hand, `is_like_solaris` and `is_like_windows` are sufficiently open and I can imagine custom targets introducing other values for `os`.
This is kind of a gray area.
Older llvm has the pre-C++17 restriction on success and failure memory
ordering, requiring the former to be at least as strong as the latter.
So, for llvm 12, this upgrades the success ordering to a stronger one if
necessary.
Remove the source archive functionality of ArchiveWriter
We now build archives through strictly additive means rather than taking an existing archive and potentially substracting parts. This is simpler and makes it easier to swap out the archive writer in https://github.com/rust-lang/rust/pull/97485.
once cell renamings
This PR does the renamings proposed in https://github.com/rust-lang/rust/issues/74465#issuecomment-1153703128
- Move/rename `lazy::{OnceCell, Lazy}` to `cell::{OnceCell, LazyCell}`
- Move/rename `lazy::{SyncOnceCell, SyncLazy}` to `sync::{OnceLock, LazyLock}`
(I used `Lazy...` instead of `...Lazy` as it seems to be more consistent, easier to pronounce, etc)
```@rustbot``` label +T-libs-api -T-libs
Support lint expectations for `--force-warn` lints (RFC 2383)
Rustc has a `--force-warn` flag, which overrides lint level attributes and forces the diagnostics to always be warn. This means, that for lint expectations, the diagnostic can't be suppressed as usual. This also means that the expectation would not be fulfilled, even if a lint had been triggered in the expected scope.
This PR now also tracks the expectation ID in the `ForceWarn` level. I've also made some minor adjustments, to possibly catch more bugs and make the whole implementation more robust.
This will probably conflict with https://github.com/rust-lang/rust/pull/97718. That PR should ideally be reviewed and merged first. The conflict itself will be trivial to fix.
---
r? `@wesleywiser`
cc: `@flip1995` since you've helped with the initial review and also discussed this topic with me. 🙃
Follow-up of: https://github.com/rust-lang/rust/pull/87835
Issue: https://github.com/rust-lang/rust/issues/85549
Yeah, and that's it.
This adds the typeid and `vcall_visibility` metadata to vtables when the
-Cvirtual-function-elimination flag is set.
The typeid is generated in the same way as for the
`llvm.type.checked.load` intrinsic from the trait_ref.
The offset that is added to the typeid is always 0. This is because LLVM
assumes that vtables are constructed according to the definition in the
Itanium ABI. This includes an "address point" of the vtable. In C++ this
is the offset in the vtable where information for RTTI is placed. Since
there is no RTTI information in Rust's vtables, this "address point" is
always 0. This "address point" in combination with the offset passed to
the `llvm.type.checked.load` intrinsic determines the final function
that should be loaded from the vtable in the
`WholeProgramDevirtualization` pass in LLVM. That's why the
`llvm.type.checked.load` intrinsics are generated with the typeid of the
trait, rather than with that of the function that is called. This
matches what `clang` does for C++.
The vcall_visibility metadata depends on three factors:
1. LTO level: Currently this is always fat LTO, because LLVM only
supports this optimization with fat LTO.
2. Visibility of the trait: If the trait is publicly visible, VFE
can only act on its vtables after linking.
3. Number of CGUs: if there is more than one CGU, also vtables with
restricted visibility could be seen outside of the CGU, so VFE can
only act on them after linking.
To reflect this, there are three visibility levels: Public, LinkageUnit,
and TranslationUnit.
Add the intrinsic
declare {i8*, i1} @llvm.type.checked.load(i8* %ptr, i32 %offset, metadata %type)
This is used in the VFE optimization when lowering loading functions
from vtables to LLVM IR. The `metadata` is used to map the function to
all vtables this function could belong to. This ensures that functions
from vtables that might be used somewhere won't get removed.
To apply the optimization the `Virtual Function Elim` module flag has to
be set. To apply this optimization post-link the `LTOPostLink` module
flag has to be set.
Add Apple WatchOS compile targets
Hello,
I would like to add the following target triples for Apple WatchOS as Tier 3 platforms:
armv7k-apple-watchos
arm64_32-apple-watchos
x86_64-apple-watchos-sim
There are some pre-requisites Pull Requests:
https://github.com/rust-lang/compiler-builtins/pull/456 (merged)
https://github.com/alexcrichton/cc-rs/pull/662 (pending)
https://github.com/rust-lang/libc/pull/2717 (merged)
There will be a subsequent PR with standard library changes for WatchOS. Previous compiler and library changes were in a single PR (https://github.com/rust-lang/rust/pull/94736) which is now closed in favour of separate PRs.
Many thanks!
Vlad.
### Tier 3 Target Requirements
Adds support for Apple WatchOS compile targets.
Below are details on how this target meets the requirements for tier 3:
> tier 3 target must have a designated developer or developers (the "target maintainers") on record to be CCed when issues arise regarding the target. (The mechanism to track and CC such developers may evolve over time.)
`@deg4uss3r` has volunteered to be the target maintainer. I am also happy to help if a second maintainer is required.
> Targets must use naming consistent with any existing targets; for instance, a target for the same CPU or OS as an existing Rust target should use the same name for that CPU or OS. Targets should normally use the same names and naming conventions as used elsewhere in the broader ecosystem beyond Rust (such as in other toolchains), unless they have a very good reason to diverge. Changing the name of a target can be highly disruptive, especially once the target reaches a higher tier, so getting the name right is important even for a tier 3 target.
Uses the same naming as the LLVM target, and the same convention as other Apple targets.
> Target names should not introduce undue confusion or ambiguity unless absolutely necessary to maintain ecosystem compatibility. For example, if the name of the target makes people extremely likely to form incorrect beliefs about what it targets, the name should be changed or augmented to disambiguate it.
I don't believe there is any ambiguity here.
> Tier 3 targets may have unusual requirements to build or use, but must not create legal issues or impose onerous legal terms for the Rust project or for Rust developers or users.
I don't see any legal issues here.
> The target must not introduce license incompatibilities.
> Anything added to the Rust repository must be under the standard Rust license (MIT OR Apache-2.0).
> The target must not cause the Rust tools or libraries built for any other host (even when supporting cross-compilation to the target) to depend on any new dependency less permissive than the Rust licensing policy. This applies whether the dependency is a Rust crate that would require adding new license exceptions (as specified by the tidy tool in the rust-lang/rust repository), or whether the dependency is a native library or binary. In other words, the introduction of the target must not cause a user installing or running a version of Rust or the Rust tools to be subject to any new license requirements.
> If the target supports building host tools (such as rustc or cargo), those host tools must not depend on proprietary (non-FOSS) libraries, other than ordinary runtime libraries supplied by the platform and commonly used by other binaries built for the target. For instance, rustc built for the target may depend on a common proprietary C runtime library or console output library, but must not depend on a proprietary code generation library or code optimization library. Rust's license permits such combinations, but the Rust project has no interest in maintaining such combinations within the scope of Rust itself, even at tier 3.
> Targets should not require proprietary (non-FOSS) components to link a functional binary or library.
> "onerous" here is an intentionally subjective term. At a minimum, "onerous" legal/licensing terms include but are not limited to: non-disclosure requirements, non-compete requirements, contributor license agreements (CLAs) or equivalent, "non-commercial"/"research-only"/etc terms, requirements conditional on the employer or employment of any particular Rust developers, revocable terms, any requirements that create liability for the Rust project or its developers or users, or any requirements that adversely affect the livelihood or prospects of the Rust project or its developers or users.
I see no issues with any of the above.
> Neither this policy nor any decisions made regarding targets shall create any binding agreement or estoppel by any party. If any member of an approving Rust team serves as one of the maintainers of a target, or has any legal or employment requirement (explicit or implicit) that might affect their decisions regarding a target, they must recuse themselves from any approval decisions regarding the target's tier status, though they may otherwise participate in discussions.
> This requirement does not prevent part or all of this policy from being cited in an explicit contract or work agreement (e.g. to implement or maintain support for a target). This requirement exists to ensure that a developer or team responsible for reviewing and approving a target does not face any legal threats or obligations that would prevent them from freely exercising their judgment in such approval, even if such judgment involves subjective matters or goes beyond the letter of these requirements.
Only relevant to those making approval decisions.
> Tier 3 targets should attempt to implement as much of the standard libraries as possible and appropriate (core for most targets, alloc for targets that can support dynamic memory allocation, std for targets with an operating system or equivalent layer of system-provided functionality), but may leave some code unimplemented (either unavailable or stubbed out as appropriate), whether because the target makes it impossible to implement or challenging to implement. The authors of pull requests are not obligated to avoid calling any portions of the standard library on the basis of a tier 3 target not implementing those portions.
core and alloc can be used. std support will be added in a subsequent PR.
> The target must provide documentation for the Rust community explaining how to build for the target, using cross-compilation if possible. If the target supports running tests (even if they do not pass), the documentation must explain how to run tests for the target, using emulation if possible or dedicated hardware if necessary.
Use --target=<target> option to cross compile, just like any target. Tests can be run using the WatchOS simulator (see https://developer.apple.com/documentation/xcode/running-your-app-in-the-simulator-or-on-a-device).
> Tier 3 targets must not impose burden on the authors of pull requests, or other developers in the community, to maintain the target. In particular, do not post comments (automated or manual) on a PR that derail or suggest a block on the PR based on a tier 3 target. Do not send automated messages or notifications (via any medium, including via `@)` to a PR author or others involved with a PR regarding a tier 3 target, unless they have opted into such messages.
> Backlinks such as those generated by the issue/PR tracker when linking to an issue or PR are not considered a violation of this policy, within reason. However, such messages (even on a separate repository) must not generate notifications to anyone involved with a PR who has not requested such notifications.
I don't foresee this being a problem.
> Patches adding or updating tier 3 targets must not break any existing tier 2 or tier 1 target, and must not knowingly break another tier 3 target without approval of either the compiler team or the maintainers of the other tier 3 target.
> In particular, this may come up when working on closely related targets, such as variations of the same architecture with different features. Avoid introducing unconditional uses of features that another variation of the target may not have; use conditional compilation or runtime detection, as appropriate, to let each target run code supported by that target.
No other targets should be affected by the pull request.
Make -Cpasses= only apply to pre-link optimization
This change causes passes specified in -Cpasses= to be applied
only during pre-link optimization, not during LTO. This avoids
such passes running multiple times, which they may not be
designed for.
Fixes https://github.com/rust-lang/rust/issues/97713
This change causes passes specified in -Cpasses= to be applied
only during pre-link optimization, not during LTO. This avoids
such passes running multiple times, which they may not be
designed for.
Fixes https://github.com/rust-lang/rust/issues/97713
Specify DWARF alignment in bits, not bytes.
In DWARF, alignment of types is specified in bits, as is made clear by the
parameter name `AlignInBits`. However, `rustc` was incorrectly passing a byte
alignment. This commit fixes that.
This was noticed in upstream LLVM when I tried to check in a test consisting of
LLVM IR generated from `rustc` and it triggered assertions [1].
[1]: https://reviews.llvm.org/D126835
In DWARF, alignment of types is specified in bits, as is made clear by the
parameter name `AlignInBits`. However, `rustc` was incorrectly passing a byte
alignment. This commit fixes that.
This was noticed in upstream LLVM when I tried to check in a test consisting of
LLVM IR generated from `rustc` and it triggered assertions [1].
[1]: https://reviews.llvm.org/D126835
Add support for emitting functions with `coldcc` to LLVM
The eventual goal is to try using this for things like the internal panicking stuff, to see whether it helps.
Remove migrate borrowck mode
Closes#58781Closes#43234
# Stabilization proposal
This PR proposes the stabilization of `#![feature(nll)]` and the removal of `-Z borrowck`. Current borrow checking behavior of item bodies is currently done by first infering regions *lexically* and reporting any errors during HIR type checking. If there *are* any errors, then MIR borrowck (NLL) never occurs. If there *aren't* any errors, then MIR borrowck happens and any errors there would be reported. This PR removes the lexical region check of item bodies entirely and only uses MIR borrowck. Because MIR borrowck could never *not* be run for a compiled program, this should not break any programs. It does, however, change diagnostics significantly and allows a slightly larger set of programs to compile.
Tracking issue: #43234
RFC: https://github.com/rust-lang/rfcs/blob/master/text/2094-nll.md
Version: 1.63 (2022-06-30 => beta, 2022-08-11 => stable).
## Motivation
Over time, the Rust borrow checker has become "smarter" and thus allowed more programs to compile. There have been three different implementations: AST borrowck, MIR borrowck, and polonius (well, in progress). Additionally, there is the "lexical region resolver", which (roughly) solves the constraints generated through HIR typeck. It is not a full borrow checker, but does emit some errors.
The AST borrowck was the original implementation of the borrow checker and was part of the initially stabilized Rust 1.0. In mid 2017, work began to implement the current MIR borrow checker and that effort ompleted by the end of 2017, for the most part. During 2018, efforts were made to migrate away from the AST borrow checker to the MIR borrow checker - eventually culminating into "migrate" mode - where HIR typeck with lexical region resolving following by MIR borrow checking - being active by default in the 2018 edition.
In early 2019, migrate mode was turned on by default in the 2015 edition as well, but with MIR borrowck errors emitted as warnings. By late 2019, these warnings were upgraded to full errors. This was followed by the complete removal of the AST borrow checker.
In the period since, various errors emitted by the MIR borrow checker have been improved to the point that they are mostly the same or better than those emitted by the lexical region resolver.
While there do remain some degradations in errors (tracked under the [NLL-diagnostics tag](https://github.com/rust-lang/rust/issues?q=is%3Aopen+is%3Aissue+label%3ANLL-diagnostics), those are sufficiently small and rare enough that increased flexibility of MIR borrow check-only is now a worthwhile tradeoff.
## What is stabilized
As said previously, this does not fundamentally change the landscape of accepted programs. However, there are a [few](https://github.com/rust-lang/rust/issues?q=is%3Aopen+is%3Aissue+label%3ANLL-fixed-by-NLL) cases where programs can compile under `feature(nll)`, but not otherwise.
There are two notable patterns that are "fixed" by this stabilization. First, the `scoped_threads` feature, which is a continutation of a pre-1.0 API, can sometimes emit a [weird lifetime error](https://github.com/rust-lang/rust/issues/95527) without NLL. Second, actually seen in the standard library. In the `Extend` impl for `HashMap`, there is an implied bound of `K: 'a` that is available with NLL on but not without - this is utilized in the impl.
As mentioned before, there are a large number of diagnostic differences. Most of them are better, but some are worse. None are serious or happen often enough to need to block this PR. The biggest change is the loss of error code for a number of lifetime errors in favor of more general "lifetime may not live long enough" error. While this may *seem* bad, the former error codes were just attempts to somewhat-arbitrarily bin together lifetime errors of the same type; however, on paper, they end up being roughly the same with roughly the same kinds of solutions.
## What isn't stabilized
This PR does not completely remove the lexical region resolver. In the future, it may be possible to remove that (while still keeping HIR typeck) or to remove it together with HIR typeck.
## Tests
Many test outputs get updated by this PR. However, there are number of tests specifically geared towards NLL under `src/test/ui/nll`
## History
* On 2017-07-14, [tracking issue opened](https://github.com/rust-lang/rust/issues/43234)
* On 2017-07-20, [initial empty MIR pass added](https://github.com/rust-lang/rust/pull/43271)
* On 2017-08-29, [RFC opened](https://github.com/rust-lang/rfcs/pull/2094)
* On 2017-11-16, [Integrate MIR type-checker with NLL](https://github.com/rust-lang/rust/pull/45825)
* On 2017-12-20, [NLL feature complete](https://github.com/rust-lang/rust/pull/46862)
* On 2018-07-07, [Don't run AST borrowck on mir mode](https://github.com/rust-lang/rust/pull/52083)
* On 2018-07-27, [Add migrate mode](https://github.com/rust-lang/rust/pull/52681)
* On 2019-04-22, [Enable migrate mode on 2015 edition](https://github.com/rust-lang/rust/pull/59114)
* On 2019-08-26, [Don't downgrade errors on 2015 edition](https://github.com/rust-lang/rust/pull/64221)
* On 2019-08-27, [Remove AST borrowck](https://github.com/rust-lang/rust/pull/64790)
Finish bumping stage0
It looks like the last time had left some remaining cfg's -- which made me think
that the stage0 bump was actually successful. This brings us to a released 1.62
beta though.
This now brings us to cfg-clean, with the exception of check-cfg-features in bootstrap;
I'd prefer to leave that for a separate PR at this time since it's likely to be more tricky.
cc https://github.com/rust-lang/rust/pull/97147#issuecomment-1132845061
r? `@pietroalbini`
Prepare Rust for opaque pointers
Fix one codegen bug with opaque pointers, and update our IR tests to accept both typed pointer and opaque pointer IR. This is a bit annoying, but unavoidable if we want decent test coverage on both LLVM 14 and LLVM 15.
This prepares Rust for when LLVM will enable opaque pointers by default.
Add support for embedding pretty printers via `#[debugger_visualizer]` attribute
Initial support for [RFC 3191](https://github.com/rust-lang/rfcs/pull/3191) in PR https://github.com/rust-lang/rust/pull/91779 was scoped to supporting embedding NatVis files using a new attribute. This PR implements the pretty printer support as stated in the RFC mentioned above.
This change includes embedding pretty printers in the `.debug_gdb_scripts` just as the pretty printers for rustc are embedded today. Also added additional tests for embedded pretty printers. Additionally cleaned up error checking so all error checking is done up front regardless of the current target.
RFC: https://github.com/rust-lang/rfcs/pull/3191
It looks like the last time had left some remaining cfg's -- which made me think
that the stage0 bump was actually successful. This brings us to a released 1.62
beta though.
This was relying on the presence of a bitcast to avoid using the
constant global initializer for a load using a different type.
With opaque pointers, we need to check this explicitly.
Ensure all error checking for `#[debugger_visualizer]` is done up front and not when the `debugger_visualizer` query is run.
Clean up potential ODR violations when embedding pretty printers into the `__rustc_debug_gdb_scripts_section__` section.
Respond to PR comments and update documentation.
don't encode only locally used attrs
Part of https://github.com/rust-lang/compiler-team/issues/505.
We now filter builtin attributes before encoding them in the crate metadata in case they should only be used in the local crate. To prevent accidental misuse `get_attrs` now requires the caller to state which attribute they are interested in. For places where that isn't trivially possible, I've added a method `fn get_attrs_unchecked` which I intend to remove in a followup PR.
After this pull request landed, we can then slowly move all attributes to only be used in the local crate while being certain that we don't accidentally try to access them from extern crates.
cc https://github.com/rust-lang/rust/pull/94963#issuecomment-1082924289
Implement a lint to warn about unused macro rules
This implements a new lint to warn about unused macro rules (arms/matchers), similar to the `unused_macros` lint added by #41907 that warns about entire macros.
```rust
macro_rules! unused_empty {
(hello) => { println!("Hello, world!") };
() => { println!("empty") }; //~ ERROR: 1st rule of macro `unused_empty` is never used
}
fn main() {
unused_empty!(hello);
}
```
Builds upon #96149 and #96156.
Fixes#73576
Begin fixing all the broken doctests in `compiler/`
Begins to fix#95994.
All of them pass now but 24 of them I've marked with `ignore HELP (<explanation>)` (asking for help) as I'm unsure how to get them to work / if we should leave them as they are.
There are also a few that I marked `ignore` that could maybe be made to work but seem less important.
Each `ignore` has a rough "reason" for ignoring after it parentheses, with
- `(pseudo-rust)` meaning "mostly rust-like but contains foreign syntax"
- `(illustrative)` a somewhat catchall for either a fragment of rust that doesn't stand on its own (like a lone type), or abbreviated rust with ellipses and undeclared types that would get too cluttered if made compile-worthy.
- `(not-rust)` stuff that isn't rust but benefits from the syntax highlighting, like MIR.
- `(internal)` uses `rustc_*` code which would be difficult to make work with the testing setup.
Those reason notes are a bit inconsistently applied and messy though. If that's important I can go through them again and try a more principled approach. When I run `rg '```ignore \(' .` on the repo, there look to be lots of different conventions other people have used for this sort of thing. I could try unifying them all if that would be helpful.
I'm not sure if there was a better existing way to do this but I wrote my own script to help me run all the doctests and wade through the output. If that would be useful to anyone else, I put it here: https://github.com/Elliot-Roberts/rust_doctest_fixing_tool
Refactor the WriteBackendMethods and ExtraBackendMethods traits
The new interface is slightly less confusing and is easier to implement for non-LLVM backends.
Only crate root def-ids don't have a parent, and in majority of cases the argument of `DefIdTree::parent` cannot be a crate root.
So we now panic by default in `parent` and introduce a new non-panicing function `opt_parent` for cases where the argument can be a crate root.
Same applies to `local_parent`/`opt_local_parent`.
not need `Option` for `dbg_scope`
This PR fixes a few FIXME about not using `Option` in `dbg_scope` field of `DebugScope`, during `create_function_debug_context` func in codegen parts.
Added a `BitSet<SourceScope>` parameter to `make_mir_scope` to indicate whether the `DebugScope` has been instantiated.
cc ````@eddyb````
Generate synthetic object file to ensure all exported and used symbols participate in the linking
Fix#50007 and #47384
This is the synthetic object file approach that I described in https://github.com/rust-lang/rust/pull/95363#issuecomment-1079932354, allowing all exported and used symbols to be linked while still allowing them to be GCed.
Related #93791, #95363
r? `@petrochenkov`
cc `@carbotaniuman`
Drop support for legacy PM with LLVM 15
LLVM 15 already removes some of the legacy PM APIs we're using. This patch forces use of NewPM with LLVM 15 (with `-Z new-llvm-pass-manager=no` throwing a warning) and stubs out various FFI methods with a report_fatal_error on LLVM 15.
For LLVMPassManagerBuilderPopulateLTOPassManager() I went with adding our own wrapper, as the alternative would be to muck about with weak symbols, which seems to be non-trivial as far as cross-platform support is concerned (std has `weak!` for this purpose, but only as an internal utility.)
Fixes#96072.
Fixes#96362.
asm: Add a kreg0 register class on x86 which includes k0
Previously we only exposed a kreg register class which excludes the k0
register since it can't be used in many instructions. However k0 is a
valid register and we need to have a way of marking it as clobbered for
clobber_abi.
Fixes#94977
Previously we only exposed a kreg register class which excludes the k0
register since it can't be used in many instructions. However k0 is a
valid register and we need to have a way of marking it as clobbered for
clobber_abi.
Fixes#94977
Allow self-profiler to only record potentially costly arguments when argument recording is turned on
As discussed [on zulip](https://rust-lang.zulipchat.com/#narrow/stream/247081-t-compiler.2Fperformance/topic/Identifying.20proc-macro.20slowdowns/near/277304909) with `@wesleywiser,` I'd like to record proc-macro expansions in the self-profiler, with some detailed data (per-expansion spans for example, to follow #95473).
At the same time, I'd also like to avoid doing expensive things when tracking a generic activity's arguments, if they were not specifically opted into the event filter mask, to allow the self-profiler to be used in hotter contexts.
This PR tries to offer:
- a way to ensure a closure to record arguments will only be called in that situation, so that potentially costly arguments can still be recorded when needed. With the additional requirement that, if possible, it would offer a way to record non-owned data without adding many `generic_activity_with_arg_{...}`-style methods. This lead to the `generic_activity_with_arg_recorder` single entry-point, and the closure parameter would offer the new methods, able to be executed in a context where costly argument could be created without disturbing the profiled piece of code.
- some facilities/patterns allowing to record more rustc specific data in this situation, without making `rustc_data_structures` where the self-profiler is defined, depend on other rustc crates (causing circular dependencies): in particular, spans. They are quite tricky to turn into strings (if the default `Debug` impl output does not match the context one needs them for), and since I'd also like to avoid the allocation there when arg recording is turned off today, that has turned into another flexibility requirement for the API in this PR (separating the span-specific recording into an extension trait). **edit**: I've removed this from the PR so that it's easier to review, and opened https://github.com/rust-lang/rust/pull/95739.
- allow for extensibility in the future: other ways to record arguments, or additional data attached to them could be added in the future (e.g. recording the argument's name as well as its data).
Some areas where I'd love feedback:
- the API and names: the `EventArgRecorder` and its method for example. As well as the verbosity that comes from the increased flexibility.
- if I should convert the existing `generic_activity_with_arg{s}` to just forward to `generic_activity_with_arg_recorder` + `recorder.record_arg` (or remove them altogether ? Probably not): I've used the new API in the simple case I could find of allocating for an arg that may not be recorded, and the rest don't seem costly.
- [x] whether this API should panic if no arguments were recorded by the user-provided closure (like this PR currently does: it seems like an error to use an API dedicated to record arguments but not call the methods to then do so) or if this should just record a generic activity without arguments ?
- whether the `record_arg` function should be `#[inline(always)]`, like the `generic_activity_*` functions ?
As mentioned, r? `@wesleywiser` following our recent discussion.
Rollup of 9 pull requests
Successful merges:
- #93969 (Only add codegen backend to dep info if -Zbinary-dep-depinfo is used)
- #94605 (Add missing links in platform support docs)
- #95372 (make unaligned_references lint deny-by-default)
- #95859 (Improve diagnostics for unterminated nested block comment)
- #95961 (implement SIMD gather/scatter via vector getelementptr)
- #96004 (Consider lifetimes when comparing types for equality in MIR validator)
- #96050 (Remove some now-dead code that was only relevant before deaggregation.)
- #96070 ([test] Add test cases for untested functions for BTreeMap)
- #96099 (MaybeUninit array cleanup)
Failed merges:
r? `@ghost`
`@rustbot` modify labels: rollup
implement SIMD gather/scatter via vector getelementptr
Fixes https://github.com/rust-lang/portable-simd/issues/271
However, I don't *really* know what I am doing here... Cc ``@workingjubilee`` ``@calebzulawski``
I didn't do anything for cranelift -- ``@bjorn3`` not sure if it's okay for that backend to temporarily break. I'm happy to cherry-pick a patch that adds cranelift support. :)
We may sometimes emit an `invoke` instead of a `call` for inline
assembly during the MIR -> LLVM IR lowering. But we failed to update
the IR builder's current basic block before writing the results to the
outputs. This would result in invalid IR because the basic block would
end in a `store` instruction, which isn't a valid terminator.
Since September, the toolchain has not been generating reliable DWARF
information for static variables when LTO is on. This has affected
projects in the embedded space where the use of LTO is typical. In our
case, it has kept us from bumping past the 2021-09-22 nightly toolchain
lest our debugger break. This has been a pretty dramatic regression for
people using debuggers and static variables. See #90357 for more info
and a repro case.
This commit is a mechanical revert of
d5de680e20 from PR #89041, which caused
the issue. (Note on that PR that the commit's author has requested it be
reverted.)
I have locally verified that this fixes#90357 by restoring the
functionality of both the repro case I posted on that bug, and debugger
behavior on real programs. There do not appear to be test cases for this
in the toolchain; if I've missed them, point me at 'em and I'll update
them.
Skip needless bitset for debuginfo
Found this while digging around looking at the inlining logic.
Seemed obvious enough so I decided to try to take care of it.
Is this what you had in mind, `@eddyb?`
Before this fix, the debuginfo for the fields was generated from the
struct defintion of Box<T>, but (at least at the moment) the compiler
pretends that Box<T> is just a (fat) pointer, so the fields need to be
`pointer` and `vtable` instead of `__0: Unique<T>` and `__1: Allocator`.
This is meant as a temporary mitigation until we can make sure that
simply treating Box as a regular struct in debuginfo does not cause too
much breakage in the ecosystem.
Fold aarch64 feature +fp into +neon
Arm's FEAT_FP and Feat_AdvSIMD describe the same thing on AArch64:
The Neon unit, which handles both floating point and SIMD instructions.
Moreover, a configuration for AArch64 must include both or neither.
Arm says "entirely proprietary" toolchains may omit floating point:
https://developer.arm.com/documentation/102374/0101/Data-processing---floating-point
In the Programmer's Guide for Armv8-A, Arm says AArch64 can have
both FP and Neon or neither in custom implementations:
https://developer.arm.com/documentation/den0024/a/AArch64-Floating-point-and-NEON
In "Bare metal boot code for Armv8-A", enabling Neon and FP
is just disabling the same trap flag:
https://developer.arm.com/documentation/dai0527/a
In an unlikely future where "Neon and FP" become unrelated,
we can add "[+-]fp" as its own feature flag.
Until then, we can simplify programming with Rust on AArch64 by
folding both into "[+-]neon", which is valid as it supersets both.
"[+-]neon" is retained for niche uses such as firmware, kernels,
"I just hate floats", and so on.
I am... pretty sure no one is relying on this.
An argument could be made that, as we are not an "entirely proprietary" toolchain, we should not support AArch64 without floats at all. I think that's a bit excessive. However, I want to recognize the intent: programming for AArch64 should be simplified where possible. For x86-64, programmers regularly set up illegal feature configurations because it's hard to understand them, see https://github.com/rust-lang/rust/issues/89586. And per the above notes, plus the discussion in https://github.com/rust-lang/rust/issues/86941, there should be no real use cases for leaving these features split: the two should in fact always go together.
- Fixesrust-lang/rust#95002.
- Fixesrust-lang/rust#95064.
- Fixesrust-lang/rust#95122.
Arm's FEAT_FP and Feat_AdvSIMD describe the same thing on AArch64:
The Neon unit, which handles both floating point and SIMD instructions.
Moreover, a configuration for AArch64 must include both or neither.
Arm says "entirely proprietary" toolchains may omit floating point:
https://developer.arm.com/documentation/102374/0101/Data-processing---floating-point
In the Programmer's Guide for Armv8-A, Arm says AArch64 can have
both FP and Neon or neither in custom implementations:
https://developer.arm.com/documentation/den0024/a/AArch64-Floating-point-and-NEON
In "Bare metal boot code for Armv8-A", enabling Neon and FP
is just disabling the same trap flag:
https://developer.arm.com/documentation/dai0527/a
In an unlikely future where "Neon and FP" become unrelated,
we can add "[+-]fp" as its own feature flag.
Until then, we can simplify programming with Rust on AArch64 by
folding both into "[+-]neon", which is valid as it supersets both.
"[+-]neon" is retained for niche uses such as firmware, kernels,
"I just hate floats", and so on.
Implement -Z oom=panic
This PR removes the `#[rustc_allocator_nounwind]` attribute on `alloc_error_handler` which allows it to unwind with a panic instead of always aborting. This is then used to implement `-Z oom=panic` as per RFC 2116 (tracking issue #43596).
Perf and binary size tests show negligible impact.
debuginfo: Refactor debuginfo generation for types
This PR implements the refactoring of the `rustc_codegen_llvm::debuginfo::metadata` module as described in MCP https://github.com/rust-lang/compiler-team/issues/482.
In particular it
- changes names to use `di_node` instead of `metadata`
- uniformly names all functions that build new debuginfo nodes `build_xyz_di_node`
- renames `CrateDebugContext` to `CodegenUnitDebugContext` (which is more accurate)
- removes outdated parts from `compiler/rustc_codegen_llvm/src/debuginfo/doc.md`
- moves `TypeMap` and functions that work directly work with it to a new `type_map` module
- moves enum related builder functions to a new `enums` module
- splits enum debuginfo building for the native and cpp-like cases, since they are mostly separate
- uses `SmallVec` instead of `Vec` in many places
- removes the old infrastructure for dealing with recursion cycles (`create_and_register_recursive_type_forward_declaration()`, `RecursiveTypeDescription`, `set_members_of_composite_type()`, `MemberDescription`, `MemberDescriptionFactory`, `prepare_xyz_metadata()`, etc)
- adds `type_map::build_type_with_children()` as a replacement for dealing with recursion cycles
- adds many (doc-)comments explaining what's going on
- changes cpp-like naming for C-Style enums so they don't get a `enum$<...>` name (because the NatVis visualizer does not apply to them)
- fixes detection of what is a C-style enum because some enums where classified as C-style even though they have fields
- changes cpp-like naming for generator enums so that NatVis works for them
- changes the position of discriminant debuginfo node so it is consistently nested inside the top-level union instead of, sometimes, next to it
The following could be done in subsequent PRs:
- add caching for `closure_saved_names_of_captured_variables`
- add caching for `generator_layout_and_saved_local_names`
- fix inconsistent handling of what is considered a C-style enum wrt to debuginfo
- rename `metadata` module to `types`
- move common generator fields to front instead of appending them
This PR is based on https://github.com/rust-lang/rust/pull/93644 which is not merged yet.
Right now, the changes are all done in one big commit. They could be split into smaller commits but hopefully the list of changes above makes it tractable to review them as a single commit too.
For now: r? `@ghost` (let's see if this affects compile times)
This commit
- changes names to use di_node instead of metadata
- uniformly names all functions that build new debuginfo nodes build_xyz_di_node
- renames CrateDebugContext to CodegenUnitDebugContext (which is more accurate)
- moves TypeMap and functions that work directly work with it to a new type_map module
- moves and reimplements enum related builder functions to a new enums module
- splits enum debuginfo building for the native and cpp-like cases, since they are mostly separate
- uses SmallVec instead of Vec in many places
- removes the old infrastructure for dealing with recursion cycles (create_and_register_recursive_type_forward_declaration(), RecursiveTypeDescription, set_members_of_composite_type(), MemberDescription, MemberDescriptionFactory, prepare_xyz_metadata(), etc)
- adds type_map::build_type_with_children() as a replacement for dealing with recursion cycles
- adds many (doc-)comments explaining what's going on
- changes cpp-like naming for C-Style enums so they don't get a enum$<...> name (because the NatVis visualizer does not apply to them)
- fixes detection of what is a C-style enum because some enums where classified as C-style even though they have fields
- changes the position of discriminant debuginfo node so it is consistently nested inside the top-level union instead of, sometimes, next to it
Improve `AdtDef` interning.
This commit makes `AdtDef` use `Interned`. Much of the commit is tedious
changes to introduce getter functions. The interesting changes are in
`compiler/rustc_middle/src/ty/adt.rs`.
r? `@fee1-dead`
This commit makes `AdtDef` use `Interned`. Much the commit is tedious
changes to introduce getter functions. The interesting changes are in
`compiler/rustc_middle/src/ty/adt.rs`.
Only emit pointer-like metadata for `Box<T, A>` when `A` is ZST
Basically copy the change in #94043, but for debuginfo.
r? ``@michaelwoerister``
Fixes#94725
Clarify `Layout` interning.
`Layout` is another type that is sometimes interned, sometimes not, and
we always use references to refer to it so we can't take any advantage
of the uniqueness properties for hashing or equality checks.
This commit renames `Layout` as `LayoutS`, and then introduces a new
`Layout` that is a newtype around an `Interned<LayoutS>`. It also
interns more layouts than before. Previously layouts within layouts
(via the `variants` field) were never interned, but now they are. Hence
the lifetime on the new `Layout` type.
Unlike other interned types, these ones are in `rustc_target` instead of
`rustc_middle`. This reflects the existing structure of the code, which
does layout-specific stuff in `rustc_target` while `TyAndLayout` is
generic over the `Ty`, allowing the type-specific stuff to occur in
`rustc_middle`.
The commit also adds a `HashStable` impl for `Interned`, which was
needed. It hashes the contents, unlike the `Hash` impl which hashes the
pointer.
r? `@fee1-dead`
`Layout` is another type that is sometimes interned, sometimes not, and
we always use references to refer to it so we can't take any advantage
of the uniqueness properties for hashing or equality checks.
This commit renames `Layout` as `LayoutS`, and then introduces a new
`Layout` that is a newtype around an `Interned<LayoutS>`. It also
interns more layouts than before. Previously layouts within layouts
(via the `variants` field) were never interned, but now they are. Hence
the lifetime on the new `Layout` type.
Unlike other interned types, these ones are in `rustc_target` instead of
`rustc_middle`. This reflects the existing structure of the code, which
does layout-specific stuff in `rustc_target` while `TyAndLayout` is
generic over the `Ty`, allowing the type-specific stuff to occur in
`rustc_middle`.
The commit also adds a `HashStable` impl for `Interned`, which was
needed. It hashes the contents, unlike the `Hash` impl which hashes the
pointer.
Introduce `ConstAllocation`.
Currently some `Allocation`s are interned, some are not, and it's very
hard to tell at a use point which is which.
This commit introduces `ConstAllocation` for the known-interned ones,
which makes the division much clearer. `ConstAllocation::inner()` is
used to get the underlying `Allocation`.
In some places it's natural to use an `Allocation`, in some it's natural
to use a `ConstAllocation`, and in some places there's no clear choice.
I've tried to make things look as nice as possible, while generally
favouring `ConstAllocation`, which is the type that embodies more
information. This does require quite a few calls to `inner()`.
The commit also tweaks how `PartialOrd` works for `Interned`. The
previous code was too clever by half, building on `T: Ord` to make the
code shorter. That caused problems with deriving `PartialOrd` and `Ord`
for `ConstAllocation`, so I changed it to build on `T: PartialOrd`,
which is slightly more verbose but much more standard and avoided the
problems.
r? `@fee1-dead`
Currently some `Allocation`s are interned, some are not, and it's very
hard to tell at a use point which is which.
This commit introduces `ConstAllocation` for the known-interned ones,
which makes the division much clearer. `ConstAllocation::inner()` is
used to get the underlying `Allocation`.
In some places it's natural to use an `Allocation`, in some it's natural
to use a `ConstAllocation`, and in some places there's no clear choice.
I've tried to make things look as nice as possible, while generally
favouring `ConstAllocation`, which is the type that embodies more
information. This does require quite a few calls to `inner()`.
The commit also tweaks how `PartialOrd` works for `Interned`. The
previous code was too clever by half, building on `T: Ord` to make the
code shorter. That caused problems with deriving `PartialOrd` and `Ord`
for `ConstAllocation`, so I changed it to build on `T: PartialOrd`,
which is slightly more verbose but much more standard and avoided the
problems.
This ensures that information about target features configured with
`-C target-feature=...` or detected with `-C target-cpu=native` is
retained for subsequent consumers of LLVM bitcode.
This is crucial for linker plugin LTO, since this information is not
conveyed to the plugin otherwise.
Add !align metadata on loads of &/&mut/Box
Note that this refers to the alignment of what the loaded value points
to, _not_ the alignment of the loaded value itself.
r? `@ghost` (blocked on #94158)
Remove LLVM attribute removal
This was necessary before, because `declare_raw_fn` would always apply
the default optimization attributes to every declared function.
Then `attributes::from_fn_attrs` would have to remove the default
attributes in the case of, e.g. `#[optimize(speed)]` in a `-Os` build.
(see [`src/test/codegen/optimize-attr-1.rs`](03a8cc7df1/src/test/codegen/optimize-attr-1.rs (L33)))
However, every relevant callsite of `declare_raw_fn` (i.e. where we
actually generate code for the function, and not e.g. a call to an
intrinsic, where optimization attributes don't [?] matter)
calls `from_fn_attrs`, so we can remove the attribute setting
from `declare_raw_fn`, and rely on `from_fn_attrs` to apply the correct
attributes all at once.
r? `@ghost` (blocked on #94221)
`@rustbot` label S-blocked
Direct users towards using Rust target feature names in CLI
This PR consists of a couple of changes on how we handle target features.
In particular there is a bug-fix wherein we avoid passing through features that aren't prefixed by `+` or `-` to LLVM. These appear to be causing LLVM to assert, which is pretty poor a behaviour (and also makes it pretty clear we expect feature names to be prefixed).
The other commit, I anticipate to be somewhat more controversial is outputting a warning when users specify a LLVM-specific, or otherwise unknown, feature name on the CLI. In those situations we request users to either replace it with a known Rust feature name (e.g. `bmi` -> `bmi1`) or file a feature request. I've a couple motivations for this: first of all, if users are specifying these features on the command line, I'm pretty confident there is also a need for these features to be usable via `#[cfg(target_feature)]` machinery. And second, we're growing a fair number of backends recently and having ability to provide some sort of unified-ish interface in this place seems pretty useful to me.
Sponsored by: standard.ai
If they are trying to use features rustc doesn't yet know about,
request a feature request.
Additionally, also warn against using feature names without leading `+`
or `-` signs.
This was necessary before, because `declare_raw_fn` would always apply
the default optimization attributes to every declared function,
and then `attributes::from_fn_attrs` would have to remove the default
attributes in the case of, e.g. `#[optimize(speed)]` in a `-Os` build.
However, every relevant callsite of `declare_raw_fn` (i.e. where we
actually generate code for the function, and not e.g. a call to an
intrinsic, where optimization attributes don't [?] matter)
calls `from_fn_attrs`, so we can simply remove the attribute setting
from `declare_raw_fn`, and rely on `from_fn_attrs` to apply the correct
attributes all at once.
LLVM really dislikes this and will assert, saying something along the
lines of:
```
rustc: llvm/lib/MC/MCSubtargetInfo.cpp:60: void ApplyFeatureFlag(
llvm::FeatureBitset&, llvm::StringRef, llvm::ArrayRef<llvm::SubtargetFeatureKV>
): Assertion
`SubtargetFeatures::hasFlag(Feature) && "Feature flags should start with '+' or '-'"`
failed.
```
No branch protection metadata unless enabled
Even if we emit metadata disabling branch protection, this metadata may
conflict with other modules (e.g. during LTO) that have different branch
protection metadata set.
This is an unstable flag and feature, so ideally the flag not being
specified should act as if the feature wasn't implemented in the first
place.
Additionally this PR also ensures we emit an error if
`-Zbranch-protection` is set on targets other than the supported
aarch64. For now the error is being output from codegen, but ideally it
should be moved to earlier in the pipeline before stabilization.
debuginfo: Simplify TypeMap used during LLVM debuginfo generation.
This PR simplifies the TypeMap that is used in `rustc_codegen_llvm::debuginfo::metadata`. It was unnecessarily complicated because it was originally implemented when types were not yet normalized before codegen. So it did it's own normalization and kept track of multiple unnormalized types being mapped to a single unique id.
This PR is based on https://github.com/rust-lang/rust/pull/93503, which is not merged yet.
The PR also removes the arena used for allocating string ids and instead uses `InlinableString` from the [inlinable_string](https://crates.io/crates/inlinable_string) crate. That might not be the best choice, since that crate does not seem to be very actively maintained. The [flexible-string](https://crates.io/crates/flexible-string) crate would be an alternative.
r? `@ghost`
Use undef for (some) partially-uninit constants
There needs to be some limit to avoid perf regressions on large arrays
with undef in each element (see comment in the code).
Fixes: #84565
Original PR: #83698
Depends on LLVM 14: #93577
properly handle fat pointers to uninhabitable types
Calculate the pointee metadata size by using `tcx.struct_tail_erasing_lifetimes` instead of duplicating the logic in `fat_pointer_kind`. Open to alternatively suggestions on how to fix this.
Fixes#94149
r? ````@michaelwoerister```` since you touched this code last, I think!
Partially move cg_ssa towards using a single builder
Not all codegen backends can handle hopping between blocks well. For example Cranelift requires blocks to be terminated before switching to building a new block. Rust-gpu requires a `RefCell` to allow hopping between blocks and cg_gcc currently has a buggy implementation of hopping between blocks. This PR reduces the amount of cases where cg_ssa switches between blocks before they are finished and mostly fixes the block hopping in cg_gcc. (~~only `scalar_to_backend` doesn't handle it correctly yet in cg_gcc~~ fixed that one.)
`@antoyo` please review the cg_gcc changes.
Change `char` type in debuginfo to DW_ATE_UTF
Rust previously encoded the `char` type as DW_ATE_unsigned_char. The more appropriate encoding is `DW_ATE_UTF`.
Clang also uses the DW_ATE_UTF for `char32_t` in C++.
This fixes the display of the `char` type in the Windows debuggers. Without this change, the variable did not show in the locals window.
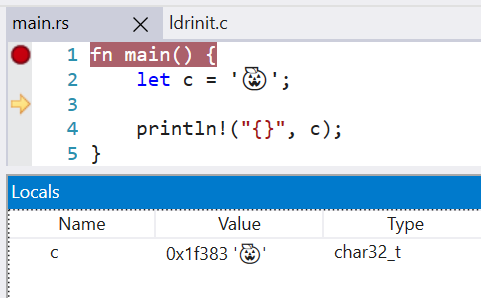
LLDB 13 is also able to display the char value, when before it failed with `need to add support for DW_TAG_base_type 'char' encoded with DW_ATE = 0x8, bit_size = 32`
r? `@wesleywiser`
Rust previously encoded the `char` type as DW_ATE_unsigned_char. The more
appropriate encoding is DW_ATE_UTF.
Clang uses this same debug encoding for char32_t.
This fixes the display of `char` types in Windows debuggers as well as LLDB.
The previous implementation was written before types were properly
normalized for code generation and had to assume a more complicated
relationship between types and their debuginfo -- generating separate
identifiers for debuginfo nodes that were based on normalized types.
Since types are now already normalized, we can use them as identifiers
for debuginfo nodes.
Improve `unused_unsafe` lint
I’m going to add some motivation and explanation below, particularly pointing the changes in behavior from this PR.
_Edit:_ Looking for existing issues, looks like this PR fixes#88260.
_Edit2:_ Now also contains code that closes#90776.
Main motivation: Fixes some issues with the current behavior. This PR is
more-or-less completely re-implementing the unused_unsafe lint; it’s also only
done in the MIR-version of the lint, the set of tests for the `-Zthir-unsafeck`
version no longer succeeds (and is thus disabled, see `lint-unused-unsafe.rs`).
On current nightly,
```rs
unsafe fn unsf() {}
fn inner_ignored() {
unsafe {
#[allow(unused_unsafe)]
unsafe {
unsf()
}
}
}
```
doesn’t create any warnings. This situation is not unrealistic to come by, the
inner `unsafe` block could e.g. come from a macro. Actually, this PR even
includes removal of one unused `unsafe` in the standard library that was missed
in a similar situation. (The inner `unsafe` coming from an external macro hides
the warning, too.)
The reason behind this problem is how the check currently works:
* While generating MIR, it already skips nested unsafe blocks (i.e. unsafe
nested in other unsafe) so that the inner one is always the one considered
unused
* To differentiate the cases of no unsafe operations inside the `unsafe` vs.
a surrounding `unsafe` block, there’s some ad-hoc magic walking up the HIR to
look for surrounding used `unsafe` blocks.
There’s a lot of problems with this approach besides the one presented above.
E.g. the MIR-building uses checks for `unsafe_op_in_unsafe_fn` lint to decide
early whether or not `unsafe` blocks in an `unsafe fn` are redundant and ought
to be removed.
```rs
unsafe fn granular_disallow_op_in_unsafe_fn() {
unsafe {
#[deny(unsafe_op_in_unsafe_fn)]
{
unsf();
}
}
}
```
```
error: call to unsafe function is unsafe and requires unsafe block (error E0133)
--> src/main.rs:13:13
|
13 | unsf();
| ^^^^^^ call to unsafe function
|
note: the lint level is defined here
--> src/main.rs:11:16
|
11 | #[deny(unsafe_op_in_unsafe_fn)]
| ^^^^^^^^^^^^^^^^^^^^^^
= note: consult the function's documentation for information on how to avoid undefined behavior
warning: unnecessary `unsafe` block
--> src/main.rs:10:5
|
9 | unsafe fn granular_disallow_op_in_unsafe_fn() {
| --------------------------------------------- because it's nested under this `unsafe` fn
10 | unsafe {
| ^^^^^^ unnecessary `unsafe` block
|
= note: `#[warn(unused_unsafe)]` on by default
```
Here, the intermediate `unsafe` was ignored, even though it contains a unsafe
operation that is not allowed to happen in an `unsafe fn` without an additional `unsafe` block.
Also closures were problematic and the workaround/algorithms used on current
nightly didn’t work properly. (I skipped trying to fully understand what it was
supposed to do, because this PR uses a completely different approach.)
```rs
fn nested() {
unsafe {
unsafe { unsf() }
}
}
```
```
warning: unnecessary `unsafe` block
--> src/main.rs:10:9
|
9 | unsafe {
| ------ because it's nested under this `unsafe` block
10 | unsafe { unsf() }
| ^^^^^^ unnecessary `unsafe` block
|
= note: `#[warn(unused_unsafe)]` on by default
```
vs
```rs
fn nested() {
let _ = || unsafe {
let _ = || unsafe { unsf() };
};
}
```
```
warning: unnecessary `unsafe` block
--> src/main.rs:9:16
|
9 | let _ = || unsafe {
| ^^^^^^ unnecessary `unsafe` block
|
= note: `#[warn(unused_unsafe)]` on by default
warning: unnecessary `unsafe` block
--> src/main.rs:10:20
|
10 | let _ = || unsafe { unsf() };
| ^^^^^^ unnecessary `unsafe` block
```
*note that this warning kind-of suggests that **both** unsafe blocks are redundant*
--------------------------------------------------------------------------------
I also dislike the fact that it always suggests keeping the outermost `unsafe`.
E.g. for
```rs
fn granularity() {
unsafe {
unsafe { unsf() }
unsafe { unsf() }
unsafe { unsf() }
}
}
```
I prefer if `rustc` suggests removing the more-course outer-level `unsafe`
instead of the fine-grained inner `unsafe` blocks, which it currently does on nightly:
```
warning: unnecessary `unsafe` block
--> src/main.rs:10:9
|
9 | unsafe {
| ------ because it's nested under this `unsafe` block
10 | unsafe { unsf() }
| ^^^^^^ unnecessary `unsafe` block
|
= note: `#[warn(unused_unsafe)]` on by default
warning: unnecessary `unsafe` block
--> src/main.rs:11:9
|
9 | unsafe {
| ------ because it's nested under this `unsafe` block
10 | unsafe { unsf() }
11 | unsafe { unsf() }
| ^^^^^^ unnecessary `unsafe` block
warning: unnecessary `unsafe` block
--> src/main.rs:12:9
|
9 | unsafe {
| ------ because it's nested under this `unsafe` block
...
12 | unsafe { unsf() }
| ^^^^^^ unnecessary `unsafe` block
```
--------------------------------------------------------------------------------
Needless to say, this PR addresses all these points. For context, as far as my
understanding goes, the main advantage of skipping inner unsafe blocks was that
a test case like
```rs
fn top_level_used() {
unsafe {
unsf();
unsafe { unsf() }
unsafe { unsf() }
unsafe { unsf() }
}
}
```
should generate some warning because there’s redundant nested `unsafe`, however
every single `unsafe` block _does_ contain some statement that uses it. Of course
this PR doesn’t aim change the warnings on this kind of code example, because
the current behavior, warning on all the inner `unsafe` blocks, makes sense in this case.
As mentioned, during MIR building all the unsafe blocks *are* kept now, and usage
is attributed to them. The way to still generate a warning like
```
warning: unnecessary `unsafe` block
--> src/main.rs:11:9
|
9 | unsafe {
| ------ because it's nested under this `unsafe` block
10 | unsf();
11 | unsafe { unsf() }
| ^^^^^^ unnecessary `unsafe` block
|
= note: `#[warn(unused_unsafe)]` on by default
warning: unnecessary `unsafe` block
--> src/main.rs:12:9
|
9 | unsafe {
| ------ because it's nested under this `unsafe` block
...
12 | unsafe { unsf() }
| ^^^^^^ unnecessary `unsafe` block
warning: unnecessary `unsafe` block
--> src/main.rs:13:9
|
9 | unsafe {
| ------ because it's nested under this `unsafe` block
...
13 | unsafe { unsf() }
| ^^^^^^ unnecessary `unsafe` block
```
in this case is by emitting a `unused_unsafe` warning for all of the `unsafe`
blocks that are _within a **used** unsafe block_.
The previous code had a little HIR traversal already anyways to collect a set of
all the unsafe blocks (in order to afterwards determine which ones are unused
afterwards). This PR uses such a traversal to do additional things including logic
like _always_ warn for an `unsafe` block that’s inside of another **used**
unsafe block. The traversal is expanded to include nested closures in the same go,
this simplifies a lot of things.
The whole logic around `unsafe_op_in_unsafe_fn` is a little complicated, there’s
some test cases of corner-cases in this PR. (The implementation involves
differentiating between whether a used unsafe block was used exclusively by
operations where `allow(unsafe_op_in_unsafe_fn)` was active.) The main goal was
to make sure that code should compile successfully if all the `unused_unsafe`-warnings
are addressed _simultaneously_ (by removing the respective `unsafe` blocks)
no matter how complicated the patterns of `unsafe_op_in_unsafe_fn` being
disallowed and allowed throughout the function are.
--------------------------------------------------------------------------------
One noteworthy design decision I took here: An `unsafe` block
with `allow(unused_unsafe)` **is considered used** for the purposes of
linting about redundant contained unsafe blocks. So while
```rs
fn granularity() {
unsafe { //~ ERROR: unnecessary `unsafe` block
unsafe { unsf() }
unsafe { unsf() }
unsafe { unsf() }
}
}
```
warns for the outer `unsafe` block,
```rs
fn top_level_ignored() {
#[allow(unused_unsafe)]
unsafe {
#[deny(unused_unsafe)]
{
unsafe { unsf() } //~ ERROR: unnecessary `unsafe` block
unsafe { unsf() } //~ ERROR: unnecessary `unsafe` block
unsafe { unsf() } //~ ERROR: unnecessary `unsafe` block
}
}
}
```
warns on the inner ones.
Move ty::print methods to Drop-based scope guards
Primary goal is reducing codegen of the TLS access for each closure, which shaves ~3 seconds of bootstrap time over rustc as a whole.
Adopt let else in more places
Continuation of #89933, #91018, #91481, #93046, #93590, #94011.
I have extended my clippy lint to also recognize tuple passing and match statements. The diff caused by fixing it is way above 1 thousand lines. Thus, I split it up into multiple pull requests to make reviewing easier. This is the biggest of these PRs and handles the changes outside of rustdoc, rustc_typeck, rustc_const_eval, rustc_trait_selection, which were handled in PRs #94139, #94142, #94143, #94144.
Even if we emit metadata disabling branch protection, this metadata may
conflict with other modules (e.g. during LTO) that have different branch
protection metadata set.
This is an unstable flag and feature, so ideally the flag not being
specified should act as if the feature wasn't implemented in the first
place.
Additionally this PR also ensures we emit an error if
`-Zbranch-protection` is set on targets other than the supported
aarch64. For now the error is being output from codegen, but ideally it
should be moved to earlier in the pipeline before stabilization.
Rollup of 10 pull requests
Successful merges:
- #89892 (Suggest `impl Trait` return type when incorrectly using a generic return type)
- #91675 (Add MemTagSanitizer Support)
- #92806 (Add more information to `impl Trait` error)
- #93497 (Pass `--test` flag through rustdoc to rustc so `#[test]` functions can be scraped)
- #93814 (mips64-openwrt-linux-musl: correct soft-foat)
- #93847 (kmc-solid: Use the filesystem thread-safety wrapper)
- #93877 (asm: Allow the use of r8-r14 as clobbers on Thumb1)
- #93892 (Only mark projection as ambiguous if GAT substs are constrained)
- #93915 (Implement --check-cfg option (RFC 3013), take 2)
- #93953 (Add the `known-bug` test directive, use it, and do some cleanup)
Failed merges:
r? `@ghost`
`@rustbot` modify labels: rollup
Add MemTagSanitizer Support
Add support for the LLVM [MemTagSanitizer](https://llvm.org/docs/MemTagSanitizer.html).
On hardware which supports it (see caveats below), the MemTagSanitizer can catch bugs similar to AddressSanitizer and HardwareAddressSanitizer, but with lower overhead.
On a tag mismatch, a SIGSEGV is signaled with code SEGV_MTESERR / SEGV_MTEAERR.
# Usage
`-Zsanitizer=memtag -C target-feature="+mte"`
# Comments/Caveats
* MemTagSanitizer is only supported on AArch64 targets with hardware support
* Requires `-C target-feature="+mte"`
* LLVM MemTagSanitizer currently only performs stack tagging.
# TODO
* Tests
* Example
This should provide a small perf improvement for debug builds,
and should more than cancel out the regression from adding noundef,
which was only significant in debug builds.
Fix ICE when using Box<T, A> with pointer sized A
Fixes#78459
Note that using `Box<T, A>` with a more than pointer sized `A` or using a pointer sized `A` with a Box of a DST will produce a different ICE (#92054) which is not fixed by this PR.
Add support for control-flow protection
This change adds a flag for configuring control-flow protection in the LLVM backend. In Clang, this flag is exposed as `-fcf-protection` with options `none|branch|return|full`. This convention is followed for `rustc`, though as a codegen option: `rustc -Z cf-protection=<none|branch|return|full>`. Tracking issue for future work is #93754.
llvm: migrate to new parameter-bearing uwtable attr
In https://reviews.llvm.org/D114543 the uwtable attribute gained a flag
so that we can ask for sync uwtables instead of async, as the former are
much cheaper. The default is async, so that's what I've done here, but I
left a TODO that we might be able to do better.
While in here I went ahead and dropped support for removing uwtable
attributes in rustc: we never did it, so I didn't write the extra C++
bridge code to make it work. Maybe I should have done the same thing
with the `sync|async` parameter but we'll see.
Specifically, change `Ty` from this:
```
pub type Ty<'tcx> = &'tcx TyS<'tcx>;
```
to this
```
pub struct Ty<'tcx>(Interned<'tcx, TyS<'tcx>>);
```
There are two benefits to this.
- It's now a first class type, so we can define methods on it. This
means we can move a lot of methods away from `TyS`, leaving `TyS` as a
barely-used type, which is appropriate given that it's not meant to
be used directly.
- The uniqueness requirement is now explicit, via the `Interned` type.
E.g. the pointer-based `Eq` and `Hash` comes from `Interned`, rather
than via `TyS`, which wasn't obvious at all.
Much of this commit is boring churn. The interesting changes are in
these files:
- compiler/rustc_middle/src/arena.rs
- compiler/rustc_middle/src/mir/visit.rs
- compiler/rustc_middle/src/ty/context.rs
- compiler/rustc_middle/src/ty/mod.rs
Specifically:
- Most mentions of `TyS` are removed. It's very much a dumb struct now;
`Ty` has all the smarts.
- `TyS` now has `crate` visibility instead of `pub`.
- `TyS::make_for_test` is removed in favour of the static `BOOL_TY`,
which just works better with the new structure.
- The `Eq`/`Ord`/`Hash` impls are removed from `TyS`. `Interned`s impls
of `Eq`/`Hash` now suffice. `Ord` is now partly on `Interned`
(pointer-based, for the `Equal` case) and partly on `TyS`
(contents-based, for the other cases).
- There are many tedious sigil adjustments, i.e. adding or removing `*`
or `&`. They seem to be unavoidable.
In https://reviews.llvm.org/D114543 the uwtable attribute gained a flag
so that we can ask for sync uwtables instead of async, as the former are
much cheaper. The default is async, so that's what I've done here, but I
left a TODO that we might be able to do better.
While in here I went ahead and dropped support for removing uwtable
attributes in rustc: we never did it, so I didn't write the extra C++
bridge code to make it work. Maybe I should have done the same thing
with the `sync|async` parameter but we'll see.
This change adds a flag for configuring control-flow protection in the
LLVM backend. In Clang, this flag is exposed as `-fcf-protection` with
options `none|branch|return|full`. This convention is followed for
`rustc`, though as a codegen option: `rustc -Z
cf-protection=<none|branch|return|full>`.
Co-authored-by: BlackHoleFox <blackholefoxdev@gmail.com>
Apply noundef attribute to &T, &mut T, Box<T>, bool
This doesn't handle `char` because it's a bit awkward to distinguish it from `u32` at this point in codegen.
Note that this _does not_ change whether or not it is UB for `&`, `&mut`, or `Box` to point to undef. It only applies to the pointer itself, not the pointed-to memory.
Fixes (partially) #74378.
r? `@nikic` cc `@RalfJung`
Split `pauth` target feature
Per discussion on https://github.com/rust-lang/rust/issues/86941 we'd like to split `pauth` into `paca` and `pacg` in order to better support possible future environments that only have the keys available for address or generic authentication. At the moment LLVM has the one `pauth` target_feature while Linux presents separate `paca` and `pacg` flags for feature detection.
Because the use of [target_feature](https://rust-lang.github.io/rfcs/2045-target-feature.html) will "allow the compiler to generate code under the assumption that this code will only be reached in hosts that support the feature", it does not make sense to simply translate `paca` into the LLVM feature `pauth`, as it will generate code as if `pacg` is available.
To accommodate this we error if only one of the two features is present. If LLVM splits them in the future we can remove this restriction without making a breaking change.
r? ```@Amanieu```
debuginfo: Fix DW_AT_containing_type vtable debuginfo regression
This PR brings back the `DW_AT_containing_type` attribute for vtables after it has accidentally been removed in #89597.
It also implements a more accurate description of vtables. Instead of describing them as an array of void pointers, the compiler will now emit a struct type description with a field for each entry of the vtable.
r? ``@wesleywiser``
This PR should fix issue https://github.com/rust-lang/rust/issues/93164.
~~The PR is blocked on https://github.com/rust-lang/rust/pull/93154 because both of them modify the `codegen/debug-vtable.rs` test case.~~
This doesn't handle `char` because it's a bit awkward to distinguish it
from u32 at this point in codegen.
Note that for some types (like `&Struct` and `&mut Struct`),
we already apply `dereferenceable`, which implies `noundef`,
so the IR does not change.
Stabilize `-Z instrument-coverage` as `-C instrument-coverage`
(Tracking issue for `instrument-coverage`: https://github.com/rust-lang/rust/issues/79121)
This PR stabilizes support for instrumentation-based code coverage, previously provided via the `-Z instrument-coverage` option. (Continue supporting `-Z instrument-coverage` for compatibility for now, but show a deprecation warning for it.)
Many, many people have tested this support, and there are numerous reports of it working as expected.
Move the documentation from the unstable book to stable rustc documentation. Update uses and documentation to use the `-C` option.
Addressing questions raised in the tracking issue:
> If/when stabilized, will the compiler flag be updated to -C instrument-coverage? (If so, the -Z variant could also be supported for some time, to ease migrations for existing users and scripts.)
This stabilization PR updates the option to `-C` and keeps the `-Z` variant to ease migration.
> The Rust coverage implementation depends on (and automatically turns on) -Z symbol-mangling-version=v0. Will stabilizing this feature depend on stabilizing v0 symbol-mangling first? If so, what is the current status and timeline?
This stabilization PR depends on https://github.com/rust-lang/rust/pull/90128 , which stabilizes `-C symbol-mangling-version=v0` (but does not change the default symbol-mangling-version).
> The Rust coverage implementation implements the latest version of LLVM's Coverage Mapping Format (version 4), which forces a dependency on LLVM 11 or later. A compiler error is generated if attempting to compile with coverage, and using an older version of LLVM.
Given that LLVM 13 has now been released, requiring LLVM 11 for coverage support seems like a reasonable requirement. If people don't have at least LLVM 11, nothing else breaks; they just can't use coverage support. Given that coverage support currently requires a nightly compiler and LLVM 11 or newer, allowing it on a stable compiler built with LLVM 11 or newer seems like an improvement.
The [tracking issue](https://github.com/rust-lang/rust/issues/79121) and the [issue label A-code-coverage](https://github.com/rust-lang/rust/labels/A-code-coverage) link to a few open issues related to `instrument-coverage`, but none of them seem like showstoppers. All of them seem like improvements and refinements we can make after stabilization.
The original `-Z instrument-coverage` support went through a compiler-team MCP at https://github.com/rust-lang/compiler-team/issues/278 . Based on that, `@pnkfelix` suggested that this needed a stabilization PR and a compiler-team FCP.
Windows: Disable LLVM crash dialog boxes.
This disables the crash dialog box on Windows. When LLVM hits an assertion, it will open a dialog box with Abort/Retry/Ignore. This is annoying on CI because CI will just hang until it times out (which can take hours).
Instead of opening a dialog box, it will print a message like this:
```
Assertion failed: isa<X>(Val) && "cast<Ty>() argument of incompatible type!", file D:\Proj\rust\rust\src\llvm-project\llvm\include\llvm/Support/Casting.h, line 255
```
Closes#92829
The "CI" environment var isn't universal (for example, I think Azure
uses TF_BUILD). However, we are mostly concerned with rust-lang/rust's
own CI which currently is GitHub Actions which does set "CI". And I
think most other providers use "CI" as well.
debuginfo: Make sure that type names for closure and generator environments are unique in debuginfo.
Before this change, closure/generator environments coming from different instantiations of the same generic function were all assigned the same name even though they were distinct types with potentially different data layout. Now we append the generic arguments of the originating function to the type name.
This commit also emits `{closure_env#0}` as the name of these types in order to disambiguate them from the accompanying closure function (which keeps being called `{closure#0}`). Previously both were assigned the same name.
NOTE: Changing debuginfo names like this can break pretty printers and other debugger plugins. I think it's OK in this particular case because the names we are changing were ambiguous anyway. In general though it would be great to have a process for doing changes like these.
Before this change, closure/generator environments coming from different
instantiations of the same generic function were all assigned the same
name even though they were distinct types with potentially different data
layout. Now we append the generic arguments of the originating function
to the type name.
This commit also emits '{closure_env#0}' as the name of these types in
order to disambiguate them from the accompanying closure function
'{closure#0}'. Previously both were assigned the same name.
Rollup of 10 pull requests
Successful merges:
- #92611 (Add links to the reference and rust by example for asm! docs and lints)
- #93158 (wasi: implement `sock_accept` and enable networking)
- #93239 (Add os::unix::net::SocketAddr::from_path)
- #93261 (Some unwinding related cg_ssa cleanups)
- #93295 (Avoid double panics when using `TempDir` in tests)
- #93353 (Unimpl {Add,Sub,Mul,Div,Rem,BitXor,BitOr,BitAnd}<$t> for Saturating<$t>)
- #93356 (Edit docs introduction for `std::cmp::PartialOrd`)
- #93375 (fix typo `documenation`)
- #93399 (rustbuild: Fix compiletest warning when building outside of root.)
- #93404 (Fix a typo from #92899)
Failed merges:
r? `@ghost`
`@rustbot` modify labels: rollup
Fix debuginfo for pointers/references to unsized types
This PR makes the compiler emit fat pointer debuginfo in all cases. Before, we sometimes got thin-pointer debuginfo, making it impossible to fully interpret the pointed to memory in debuggers. The code is actually cleaner now, especially around generation of trait object pointer debuginfo.
Fixes https://github.com/rust-lang/rust/issues/92718
~~Blocked on https://github.com/rust-lang/rust/pull/92729.~~
LLDB does not seem to see fields if they are marked with DW_AT_artificial
which breaks pretty printers that use these fields for decoding fat pointers.
Use error-on-mismatch policy for PAuth module flags.
This agrees with Clang, and avoids an error when using LTO with mixed
C/Rust. LLVM considers different behaviour flags to be a mismatch,
even when the flag value itself is the same.
This also makes the flag setting explicit for all uses of
LLVMRustAddModuleFlag.
----
I believe that this fixes#92885, but have only reproduced it locally on Linux hosts so cannot confirm that it fixes the issue as reported.
I have not included a test for this because it is covered by an existing test (`src/test/run-make-fulldeps/cross-lang-lto-clang`). It is not without its problems, though:
* The test requires Clang and `--run-clang-based-tests-with=...` to run, and this is not the case on the CI.
* Any test I add would have a similar requirement.
* With this patch applied, the test gets further, but it still fails (for other reasons). I don't think that affects #92885.
Work around missing code coverage data causing llvm-cov failures
If we do not add code coverage instrumentation to the `Body` of a
function, then when we go to generate the function record for it, we
won't write any data and this later causes llvm-cov to fail when
processing data for the entire coverage report.
I've identified two main cases where we do not currently add code
coverage instrumentation to the `Body` of a function:
1. If the function has a single `BasicBlock` and it ends with a
`TerminatorKind::Unreachable`.
2. If the function is created using a proc macro of some kind.
For case 1, this is typically not important as this most often occurs as
a result of function definitions that take or return uninhabited
types. These kinds of functions, by definition, cannot even be called so
they logically should not be counted in code coverage statistics.
For case 2, I haven't looked into this very much but I've noticed while
testing this patch that (other than functions which are covered by case
1) the skipped function coverage debug message is occasionally triggered
in large crate graphs by functions generated from a proc macro. This may
have something to do with weird spans being generated by the proc macro
but this is just a guess.
I think it's reasonable to land this change since currently, we fail to
generate *any* results from llvm-cov when a function has no coverage
instrumentation applied to it. With this change, we get coverage data
for all functions other than the two cases discussed above.
Fixes#93054 which occurs because of uncallable functions which shouldn't
have code coverage anyway.
I will open an issue for missing code coverage of proc macro generated
functions and leave a link here once I have a more minimal repro.
r? ``@tmandry``
cc ``@richkadel``
This agrees with Clang, and avoids an error when using LTO with mixed
C/Rust. LLVM considers different behaviour flags to be a mismatch,
even when the flag value itself is the same.
This also makes the flag setting explicit for all uses of
LLVMRustAddModuleFlag.
If we do not add code coverage instrumentation to the `Body` of a
function, then when we go to generate the function record for it, we
won't write any data and this later causes llvm-cov to fail when
processing data for the entire coverage report.
I've identified two main cases where we do not currently add code
coverage instrumentation to the `Body` of a function:
1. If the function has a single `BasicBlock` and it ends with a
`TerminatorKind::Unreachable`.
2. If the function is created using a proc macro of some kind.
For case 1, this typically not important as this most often occurs as
the result of function definitions that take or return uninhabited
types. These kinds of functions, by definition, cannot even be called so
they logically should not be counted in code coverage statistics.
For case 2, I haven't looked into this very much but I've noticed while
testing this patch that (other than functions which are covered by case
1) the skipped function coverage debug message is occasionally triggered
in large crate graphs by functions generated from a proc macro. This may
have something to do with weird spans being generated by the proc macro
but this is just a guess.
I think it's reasonable to land this change since currently, we fail to
generate *any* results from llvm-cov when a function has no coverage
instrumentation applied to it. With this change, we get coverage data
for all functions other than the two cases discussed above.
Improve SIMD casts
* Allows `simd_cast` intrinsic to take `usize` and `isize`
* Adds `simd_as` intrinsic, which is the same as `simd_cast` except for saturating float-to-int conversions (matching the behavior of `as`).
cc `@workingjubilee`
Implement raw-dylib support for windows-gnu
Add support for `#[link(kind = "raw-dylib")]` on windows-gnu targets. Work around binutils's linker's inability to read import libraries produced by LLVM by calling out to the binutils `dlltool` utility to create an import library from a temporary .DEF file; this approach is effectively a slightly refined version of `@mati865's` earlier attempt at this strategy in PR #88801. (In particular, this attempt at this strategy adds support for `#[link_ordinal(...)]` as well.)
In support of #58713.
Avoid unnecessary monomorphization of inline asm related functions
This should reduce build time for codegen backends by avoiding duplicated monomorphization of certain inline asm related functions for each passed in closure type.
Remove LLVMRustMarkAllFunctionsNounwind
This was originally introduced in #10916 as a way to remove all landing
pads when performing LTO. However this is no longer necessary today
since rustc properly marks all functions and call-sites as nounwind
where appropriate.
In fact this is incorrect in the presence of `extern "C-unwind"` which
must create a landing pad when compiled with `-C panic=abort` so that
foreign exceptions are caught and properly turned into aborts.
Remove deprecated LLVM-style inline assembly
The `llvm_asm!` was deprecated back in #87590 1.56.0, with intention to remove
it once `asm!` was stabilized, which already happened in #91728 1.59.0. Now it
is time to remove `llvm_asm!` to avoid continued maintenance cost.
Closes#70173.
Closes#92794.
Closes#87612.
Closes#82065.
cc `@rust-lang/wg-inline-asm`
r? `@Amanieu`
This was originally introduced in #10916 as a way to remove all landing
pads when performing LTO. However this is no longer necessary today
since rustc properly marks all functions and call-sites as nounwind
where appropriate.
In fact this is incorrect in the presence of `extern "C-unwind"` which
must create a landing pad when compiled with `-C panic=abort` so that
foreign exceptions are caught and properly turned into aborts.
[code coverage] Fix missing dead code in modules that are never called
The issue here is that the logic used to determine which CGU to put the dead function stubs in doesn't handle cases where a module is never assigned to a CGU (which is what happens when all of the code in the module is dead).
The partitioning logic also caused issues in #85461 where inline functions were duplicated into multiple CGUs resulting in duplicate symbols.
This commit fixes the issue by removing the complex logic used to assign dead code stubs to CGUs and replaces it with a much simpler model: we pick one CGU to hold all the dead code stubs. We pick a CGU which has exported items which increases the likelihood the linker won't throw away our dead functions and we pick the smallest to minimize the impact on compilation times for crates with very large CGUs.
Fixes#91661Fixes#86177Fixes#85718Fixes#79622
r? ```@tmandry```
cc ```@richkadel```
This PR is not urgent so please don't let it interrupt your holidays! 🎄🎁
Store a `Symbol` instead of an `Ident` in `VariantDef`/`FieldDef`
The field is also renamed from `ident` to `name`. In most cases,
we don't actually need the `Span`. A new `ident` method is added
to `VariantDef` and `FieldDef`, which constructs the full `Ident`
using `tcx.def_ident_span()`. This method is used in the cases
where we actually need an `Ident`.
This makes incremental compilation properly track changes
to the `Span`, without all of the invalidations caused by storing
a `Span` directly via an `Ident`.
The field is also renamed from `ident` to `name. In most cases,
we don't actually need the `Span`. A new `ident` method is added
to `VariantDef` and `FieldDef`, which constructs the full `Ident`
using `tcx.def_ident_span()`. This method is used in the cases
where we actually need an `Ident`.
This makes incremental compilation properly track changes
to the `Span`, without all of the invalidations caused by storing
a `Span` directly via an `Ident`.
Consolidate checking for msvc when generating debuginfo
If the target we're generating code for is msvc, then we do two main
things differently: we generate type names in a C++ style instead of a
Rust style and we generate debuginfo for enums differently.
I've refactored the code so that there is one function
(`cpp_like_debuginfo`) which determines if we should use the C++ style
of naming types and other debuginfo generation or the regular Rust one.
r? ``@michaelwoerister``
This PR is not urgent so please don't let it interrupt your holidays! 🎄🎁
If the target we're generating code for is msvc, then we do two main
things differently: we generate type names in a C++ style instead of a
Rust style and we generate debuginfo for enums differently.
I've refactored the code so that there is one function
(`cpp_like_debuginfo`) which determines if we should use the C++ style
of naming types and other debuginfo generation or the regular Rust one.
In #79570, `-Z split-dwarf-kind={none,single,split}` was replaced by `-C
split-debuginfo={off,packed,unpacked}`. `-C split-debuginfo`'s packed
and unpacked aren't exact parallels to single and split, respectively.
On Unix, `-C split-debuginfo=packed` will put debuginfo into object
files and package debuginfo into a DWARF package file (`.dwp`) and
`-C split-debuginfo=unpacked` will put debuginfo into dwarf object files
and won't package it.
In the initial implementation of Split DWARF, split mode wrote sections
which did not require relocation into a DWARF object (`.dwo`) file which
was ignored by the linker and then packaged those DWARF objects into
DWARF packages (`.dwp`). In single mode, sections which did not require
relocation were written into object files but ignored by the linker and
were not packaged. However, both split and single modes could be
packaged or not, the primary difference in behaviour was where the
debuginfo sections that did not require link-time relocation were
written (in a DWARF object or the object file).
This commit re-introduces a `-Z split-dwarf-kind` flag, which can be
used to pick between split and single modes when `-C split-debuginfo` is
used to enable Split DWARF (either packed or unpacked).
Signed-off-by: David Wood <david.wood@huawei.com>
No functional changes intended.
The LLVM commit
ec501f15a8
removed the signed version of `createExpression`. This adapts the Rust
LLVM wrappers accordingly.
Continue supporting -Z instrument-coverage for compatibility for now,
but show a deprecation warning for it.
Update uses and documentation to use the -C option.
Move the documentation from the unstable book to stable rustc
documentation.
Mark drop calls in landing pads `cold` instead of `noinline`
Now that deferred inlining has been disabled in LLVM (#92110), this shouldn't cause catastrophic size blowup.
I confirmed that the test cases from https://github.com/rust-lang/rust/issues/41696#issuecomment-298696944 still compile quickly (<1s) after this change. ~Although note that I wasn't able to reproduce the original issue using a recent rustc/llvm with deferred inlining enabled, so those tests may no longer be representative. I was also unable to create a modified test case that reproduced the original issue.~ (edit: I reproduced it on CI by accident--the first commit timed out on the LLVM 12 builder, because I forgot to make it conditional on LLVM version)
r? `@nagisa`
cc `@arielb1` (this effectively reverts #42771 "mark calls in the unwind path as !noinline")
cc `@RalfJung` (fixes#46515)
edit: also fixes#87055
Allow loading LLVM plugins with both legacy and new pass manager
Opening a draft PR to get feedback and start discussion on this feature. There is already a codegen option `passes` which allow giving a list of LLVM pass names, however we currently can't use a LLVM pass plugin (as described here : https://llvm.org/docs/WritingAnLLVMPass.html), the only available passes are the LLVM built-in ones.
The proposed modification would be to add another codegen option `pass-plugins`, which can be set with a list of paths to shared library files. These libraries are loaded using the LLVM function `PassPlugin::Load`, which calls the expected symbol `lvmGetPassPluginInfo`, and register the pipeline parsing and optimization callbacks.
An example usage with a single plugin and 3 passes would look like this in the `.cargo/config`:
```toml
rustflags = [
"-C", "pass-plugins=/tmp/libLLVMPassPlugin",
"-C", "passes=pass1 pass2 pass3",
]
```
This would give the same functionality as the opt LLVM tool directly integrated in rust build system.
Additionally, we can also not specify the `passes` option, and use a plugin which inserts passes in the optimization pipeline, as one could do using clang.
Add codegen option for branch protection and pointer authentication on AArch64
The branch-protection codegen option enables the use of hint-space pointer
authentication code for AArch64 targets.
The issue here is that the logic used to determine which CGU to put the
dead function stubs in doesn't handle cases where a module is never
assigned to a CGU.
The partitioning logic also caused issues in #85461 where inline
functions were duplicated into multiple CGUs resulting in duplicate
symbols.
This commit fixes the issue by removing the complex logic used to assign
dead code stubs to CGUs and replaces it with a much simplier model: we
pick one CGU to hold all the dead code stubs. We pick a CGU which has
exported items which increases the likelihood the linker won't throw
away our dead functions and we pick the smallest to minimize the impact
on compilation times for crates with very large CGUs.
Fixes#86177Fixes#85718Fixes#79622
Remove `SymbolStr`
This was originally proposed in https://github.com/rust-lang/rust/pull/74554#discussion_r466203544. As well as removing the icky `SymbolStr` type, it allows the removal of a lot of `&` and `*` occurrences.
Best reviewed one commit at a time.
r? `@oli-obk`
rustc_codegen_llvm: Give each codegen unit a unique DWARF name on all platforms, not just Apple ones.
To avoid breaking split DWARF, we need to ensure that each codegen unit has a
unique `DW_AT_name`. This is because there's a remote chance that different
codegen units for the same module will have entirely identical DWARF entries
for the purpose of the DWO ID, which would violate Appendix F ("Split Dwarf
Object Files") of the DWARF 5 specification. LLVM uses the algorithm specified
in section 7.32 "Type Signature Computation" to compute the DWO ID, which does
not include any fields that would distinguish compilation units. So we must
embed the codegen unit name into the `DW_AT_name`.
Closes#88521.
Remove `in_band_lifetimes` from `rustc_codegen_llvm`
See #91867 for more information.
This one took a while. This crate has dozens of functions not associated with any type, and most of them were using in-band lifetimes for `'ll` and `'tcx`.
Apply path remapping to DW_AT_GNU_dwo_name when producing split DWARF
`--remap-path-prefix` doesn't apply to paths to `.o` (in case of packed) or `.dwo` (in case of unpacked) files in `DW_AT_GNU_dwo_name`. GCC also has this bug https://gcc.gnu.org/bugzilla/show_bug.cgi?id=91888
platforms, not just Apple ones.
To avoid breaking split DWARF, we need to ensure that each codegen unit has a
unique `DW_AT_name`. This is because there's a remote chance that different
codegen units for the same module will have entirely identical DWARF entries
for the purpose of the DWO ID, which would violate Appendix F ("Split Dwarf
Object Files") of the DWARF 5 specification. LLVM uses the algorithm specified
in section 7.32 "Type Signature Computation" to compute the DWO ID, which does
not include any fields that would distinguish compilation units. So we must
embed the codegen unit name into the `DW_AT_name`.
Closes#88521.
By changing `as_str()` to take `&self` instead of `self`, we can just
return `&str`. We're still lying about lifetimes, but it's a smaller lie
than before, where `SymbolStr` contained a (fake) `&'static str`!
Stabilize `iter::zip`
Hello all!
As the tracking issue (#83574) for `iter::zip` completed the final commenting period without any concerns being raised, I hereby submit this stabilization PR on the issue.
As the pull request that introduced the feature (#82917) states, the `iter::zip` function is a shorter way to zip two iterators. As it's generally a quality-of-life/ergonomic improvement, it has been integrated into the codebase without any trouble, and has been
used in many places across the rust compiler and standard library since March without any issues.
For more details, I would refer to `@cuviper's` original PR, or the [function's documentation](https://doc.rust-lang.org/std/iter/fn.zip.html).
Use `OutputFilenames` to generate output file for `-Zllvm-time-trace`
The resulting profile will include the crate name and will be stored in
the `--out-dir` directory.
This implementation makes it convenient to use LLVM time trace together
with cargo, in the contrast to the previous implementation which would
overwrite profiles or store them in `.cargo/registry/..`.
{kind=link}