BTreeMap navigation done safer & faster
It turns out that there was a faster way to do the tree navigation code bundled in #67073, by moving from edge to KV and from KV to next edge separately. It extracts most of the code as safe functions, and contains the duplication of handles within the short wrapper functions.
This somehow hits a sweet spot in the compiler because it reports boosts all over the board:
```
>cargo benchcmp pre3.txt posz4.txt --threshold 5
name pre3.txt ns/iter posz4.txt ns/iter diff ns/iter diff % speedup
btree::map::first_and_last_0 40 37 -3 -7.50% x 1.08
btree::map::first_and_last_100 58 44 -14 -24.14% x 1.32
btree::map::iter_1000 8,920 3,419 -5,501 -61.67% x 2.61
btree::map::iter_100000 1,069,290 411,615 -657,675 -61.51% x 2.60
btree::map::iter_20 169 58 -111 -65.68% x 2.91
btree::map::iter_mut_1000 8,701 3,303 -5,398 -62.04% x 2.63
btree::map::iter_mut_100000 1,034,560 405,975 -628,585 -60.76% x 2.55
btree::map::iter_mut_20 165 58 -107 -64.85% x 2.84
btree::set::clone_100 1,831 1,562 -269 -14.69% x 1.17
btree::set::clone_100_and_clear 1,831 1,565 -266 -14.53% x 1.17
btree::set::clone_100_and_into_iter 1,917 1,541 -376 -19.61% x 1.24
btree::set::clone_100_and_pop_all 2,609 2,441 -168 -6.44% x 1.07
btree::set::clone_100_and_remove_all 4,598 3,927 -671 -14.59% x 1.17
btree::set::clone_100_and_remove_half 2,765 2,551 -214 -7.74% x 1.08
btree::set::clone_10k 191,610 164,616 -26,994 -14.09% x 1.16
btree::set::clone_10k_and_clear 192,003 164,616 -27,387 -14.26% x 1.17
btree::set::clone_10k_and_into_iter 200,037 163,010 -37,027 -18.51% x 1.23
btree::set::clone_10k_and_pop_all 267,023 250,913 -16,110 -6.03% x 1.06
btree::set::clone_10k_and_remove_all 536,230 464,100 -72,130 -13.45% x 1.16
btree::set::clone_10k_and_remove_half 453,350 430,545 -22,805 -5.03% x 1.05
btree::set::difference_random_100_vs_100 1,787 801 -986 -55.18% x 2.23
btree::set::difference_random_100_vs_10k 2,978 2,696 -282 -9.47% x 1.10
btree::set::difference_random_10k_vs_100 111,075 54,734 -56,341 -50.72% x 2.03
btree::set::difference_random_10k_vs_10k 246,380 175,980 -70,400 -28.57% x 1.40
btree::set::difference_staggered_100_vs_100 1,789 951 -838 -46.84% x 1.88
btree::set::difference_staggered_100_vs_10k 2,798 2,606 -192 -6.86% x 1.07
btree::set::difference_staggered_10k_vs_10k 176,452 97,401 -79,051 -44.80% x 1.81
btree::set::intersection_100_neg_vs_10k_pos 34 32 -2 -5.88% x 1.06
btree::set::intersection_100_pos_vs_100_neg 30 27 -3 -10.00% x 1.11
btree::set::intersection_random_100_vs_100 1,537 613 -924 -60.12% x 2.51
btree::set::intersection_random_100_vs_10k 2,793 2,649 -144 -5.16% x 1.05
btree::set::intersection_random_10k_vs_10k 222,127 147,166 -74,961 -33.75% x 1.51
btree::set::intersection_staggered_100_vs_100 1,447 622 -825 -57.01% x 2.33
btree::set::intersection_staggered_100_vs_10k 2,606 2,382 -224 -8.60% x 1.09
btree::set::intersection_staggered_10k_vs_10k 143,620 58,790 -84,830 -59.07% x 2.44
btree::set::is_subset_100_vs_100 1,349 488 -861 -63.83% x 2.76
btree::set::is_subset_100_vs_10k 1,720 1,428 -292 -16.98% x 1.20
btree::set::is_subset_10k_vs_10k 135,984 48,527 -87,457 -64.31% x 2.80
```
The `first_and_last` ones are noise (they don't do iteration), the others seem genuine.
As always, approved by Miri.
Also, a separate commit with some more benchmarks of mutable behaviour (which also benefit).
r? @cuviper
Canonicalize inputs to const eval where needed
Canonicalize inputs to const eval, so that they can contain inference variables. Which enables invoking const eval queries even if the current param env has inference variable within it, which can occur during trait selection.
This is a reattempt of #67717, in a far less invasive way.
Fixes#68477
r? @nikomatsakis
cc @eddyb
Rollup of 9 pull requests
Successful merges:
- #69379 (Fail on multiple declarations of `main`.)
- #69430 (librustc_typeck: remove loop that never actually loops)
- #69449 (Do not ping PR reviewers in toolstate breakage)
- #69491 (rustc_span: Add `Symbol::to_ident_string` for use in diagnostic messages)
- #69495 (don't take redundant references to operands)
- #69496 (use find(x) instead of filter(x).next())
- #69501 (note that find(f) is equivalent to filter(f).next() in the docs.)
- #69527 (Ignore untracked paths when running `rustfmt` on repository.)
- #69529 (don't use .into() to convert types into identical types.)
Failed merges:
r? @ghost
Ignore untracked paths when running `rustfmt` on repository.
This is a step towards resolving #69291
(It might be the only step necessary at the moment; I'm not yet sure.)
Fail on multiple declarations of `main`.
Closes#67946.
Previously, when inserting the entry function, we only checked for
duplicate _definitions_ of `main`. However, it's possible to cause
problems even only having a duplicate _declaration_. For example,
shadowing `main` using an extern block isn't caught by the current
check, and causes an assertion failure down the line in in LLVM code.
r? @pnkfelix
Revert "Mark attributes consumed by `check_mod_attrs` as normal"
This reverts commit d78b22f35e.
Those changes were incompatible with incremental compilation since the
effect `check_mod_attrs` has with respect to marking the attributes as
used is neither persisted nor recomputed.
Mark other variants as uninitialized after switch on discriminant
During drop elaboration, which builds the drop ladder that handles destruction during stack unwinding, we attempt to remove MIR `Drop` terminators that will never be reached in practice. This reduces the number of basic blocks that are passed to LLVM, which should improve performance. In #66753, a user pointed out that unreachable `Drop` terminators are common in functions like `Option::unwrap`, which move out of an `enum`. While discussing possible remedies for that issue, @eddyb suggested moving const-checking after drop elaboration. This would allow the former, which looks for `Drop` terminators and replicates a small amount of drop elaboration to determine whether a dropped local has been moved out, leverage the work done by the latter.
However, it turns out that drop elaboration is not as precise as it could be when it comes to eliminating useless drop terminators. For example, let's look at the code for `unwrap_or`.
```rust
fn unwrap_or<T>(opt: Option<T>, default: T) -> T {
match opt {
Some(inner) => inner,
None => default,
}
}
```
`opt` never needs to be dropped, since it is either moved out of (if it is `Some`) or has no drop glue (if it is `None`), and `default` only needs to be dropped if `opt` is `Some`. This is not reflected in the MIR we currently pass to codegen.
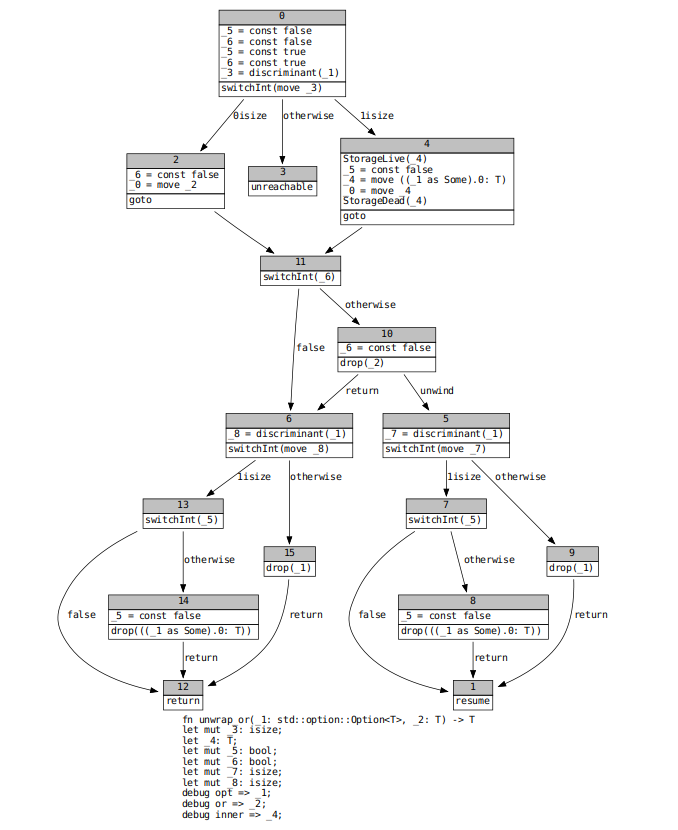
@eddyb also suggested the solution to this problem. When we switch on an enum discriminant, we should be marking all fields in other variants as definitely uninitialized. I implemented this on top of alongside a small optimization (split out into #68943) that suppresses drop terminators for enum variants with no fields (e.g. `Option::None`). This is the resulting MIR for `unwrap_or`.
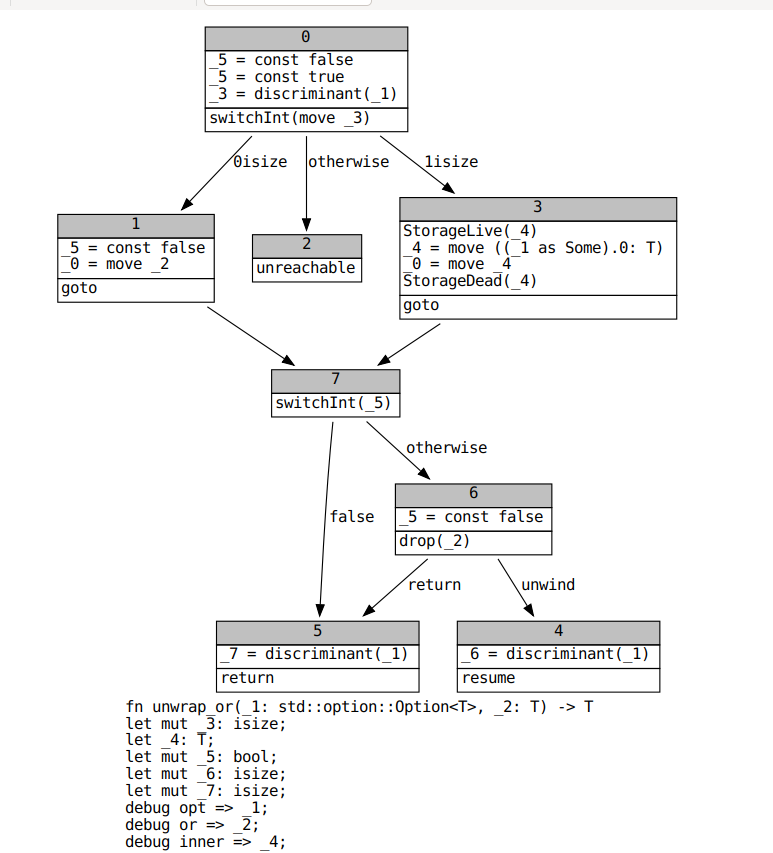
In concert with #68943, this change speeds up many [optimized and debug builds](https://perf.rust-lang.org/compare.html?start=d55f3e9f1da631c636b54a7c22c1caccbe4bf0db&end=0077a7aa11ebc2462851676f9f464d5221b17d6a). We need to carefully investigate whether I have introduced any miscompilations before merging this. Code that never drops anything would be very fast indeed until memory is exhausted.
Simplify the signature of par_for_each_in
Given `T: IntoIterator`/`IntoParallelIterator`, `T::Item` is
unambiguous, so we don't need the explicit trait casting.
resolve: `lifetimes.rs` -> `late/lifetimes.rs`
Lifetime resolution should ideally be merged into the late resolution pass, at least for named lifetimes.
Let's move it closer to it for a start.
Backport only: avoid ICE on bad placeholder type
#69148 has a proper fix, but it is too big to backport.
This change avoids the ICE by actually emitting an appropriate error. The
output will be duplicated in some cases, but that's better than the
avoidable ICE.
r? @Centril
The hash tests were written before the assert_ne macro was added to the standard library. The assert_ne macro provides better output in case of a failure.
This reverts commit d78b22f35e.
Those changes were incompatible with incremental compilation since the
effect `check_mod_attrs` has with respect to marking the attributes as
used is neither persisted nor recomputed.
Generalized article_and_description
r? @matthewjasper
The logic of finding the right word and article to print seems to be repeated elsewhere... this is an experimental method to unify this logic...
{kind=link}
{kind=link}