Change return type of unstable `Waker::noop()` from `Waker` to `&Waker`.
The advantage of this is that it does not need to be assigned to a variable to be used in a `Context` creation, which is the most common thing to want to do with a noop waker. It also avoids unnecessarily executing the dynamically dispatched drop function when the noop waker is dropped.
If an owned noop waker is desired, it can be created by cloning, but the reverse is harder to do since it requires declaring a constant. Alternatively, both versions could be provided, like `futures::task::noop_waker()` and `futures::task::noop_waker_ref()`, but that seems to me to be API clutter for a very small benefit, whereas having the `&'static` reference available is a large reduction in boilerplate.
[Previous discussion on the tracking issue starting here](https://github.com/rust-lang/rust/issues/98286#issuecomment-1862159766)
Don't ICE when deducing future output if other errors already occurred
The situation can't really happen outside of erroneous code. What was interesting is that it ICEd before emitting any other diagnostics. This was because the other errors were silenced due to cycle_delay_bug cycle errors.
r? ```@compiler-errors```
fixes#119890
Silence some follow-up errors [3/x]
this is one piece of the requested cleanups from https://github.com/rust-lang/rust/pull/117449
Keep error types around, even in obligations.
These help silence follow-up errors, as we now figure out that some types (most notably inference variables) are equal to an error type.
But it also allows figuring out more types in the presence of errors, possibly causing more errors.
Wrap coroutine variant fields in MaybeUninit to indicate that they
might be uninitialized. Otherwise an uninhabited field will make
the entire variant uninhabited and introduce undefined behaviour.
The analogous issue in the prefix of coroutine layout was addressed by
6fae7f8071.
This is an extension of the previous commit. It means the output of
something like this:
```
stringify!(let a: Vec<u32> = vec![];)
```
goes from this:
```
let a: Vec<u32> = vec![] ;
```
With this PR, it now produces this string:
```
let a: Vec<u32> = vec![];
```
`tokenstream::Spacing` appears on all `TokenTree::Token` instances,
both punct and non-punct. Its current usage:
- `Joint` means "can join with the next token *and* that token is a
punct".
- `Alone` means "cannot join with the next token *or* can join with the
next token but that token is not a punct".
The fact that `Alone` is used for two different cases is awkward.
This commit augments `tokenstream::Spacing` with a new variant
`JointHidden`, resulting in:
- `Joint` means "can join with the next token *and* that token is a
punct".
- `JointHidden` means "can join with the next token *and* that token is a
not a punct".
- `Alone` means "cannot join with the next token".
This *drastically* improves the output of `print_tts`. For example,
this:
```
stringify!(let a: Vec<u32> = vec![];)
```
currently produces this string:
```
let a : Vec < u32 > = vec! [] ;
```
With this PR, it now produces this string:
```
let a: Vec<u32> = vec![] ;
```
(The space after the `]` is because `TokenTree::Delimited` currently
doesn't have spacing information. The subsequent commit fixes this.)
The new `print_tts` doesn't replicate original code perfectly. E.g.
multiple space characters will be condensed into a single space
character. But it's much improved.
`print_tts` still produces the old, uglier output for code produced by
proc macros. Because we have to translate the generated code from
`proc_macro::Spacing` to the more expressive `token::Spacing`, which
results in too much `proc_macro::Along` usage and no
`proc_macro::JointHidden` usage. So `space_between` still exists and
is used by `print_tts` in conjunction with the `Spacing` field.
This change will also help with the removal of `Token::Interpolated`.
Currently interpolated tokens are pretty-printed nicely via AST pretty
printing. `Token::Interpolated` removal will mean they get printed with
`print_tts`. Without this change, that would result in much uglier
output for code produced by decl macro expansions. With this change, AST
pretty printing and `print_tts` produce similar results.
The commit also tweaks the comments on `proc_macro::Spacing`. In
particular, it refers to "compound tokens" rather than "multi-char
operators" because lifetimes aren't operators.
recurse into refs when comparing tys for diagnostics
before:

after:
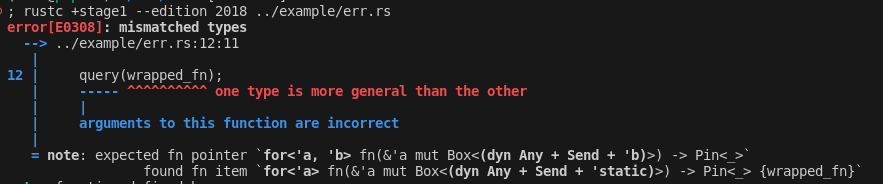
this diff from the test suite is also quite nice imo:
```diff
`@@` -4,8 +4,8 `@@` error[E0308]: mismatched types
LL | debug_assert_eq!(iter.next(), Some(value));
| ^^^^^^^^^^^ expected `Option<<I as Iterator>::Item>`, found `Option<&<I as Iterator>::Item>`
|
- = note: expected enum `Option<<I as Iterator>::Item>`
- found enum `Option<&<I as Iterator>::Item>`
+ = note: expected enum `Option<_>`
+ found enum `Option<&_>`
```
Suggest field typo through derefs
Take into account implicit dereferences when suggesting fields.
```
error[E0609]: no field `longname` on type `Arc<S>`
--> $DIR/suggest-field-through-deref.rs:10:15
|
LL | let _ = x.longname;
| ^^^^^^^^ help: a field with a similar name exists: `long_name`
```
CC https://github.com/rust-lang/rust/issues/78374#issuecomment-719564114
Remove asmjs
Fulfills [MCP 668](https://github.com/rust-lang/compiler-team/issues/668).
`asmjs-unknown-emscripten` does not work as-specified, and lacks essential upstream support for generating asm.js, so it should not exist at all.
Take into account implicit dereferences when suggesting fields.
```
error[E0609]: no field `longname` on type `Arc<S>`
--> $DIR/suggest-field-through-deref.rs:10:15
|
LL | let _ = x.longname;
| ^^^^^^^^ help: a field with a similar name exists: `long_name`
```
CC https://github.com/rust-lang/rust/issues/78374#issuecomment-719564114
Rename AsyncCoroutineKind to CoroutineSource
pulled out of https://github.com/rust-lang/rust/pull/116447
Also refactors the printing infra of `CoroutineSource` to be ready for easily extending it with a `Gen` variant for `gen` blocks
Merge `impl_wf_inference` (`check_mod_impl_wf`) check into coherence checking
Problem here is that we call `collect_impl_trait_in_trait_types` when checking `check_mod_impl_wf` which is performed before coherence. Due to the `tcx.sess.track_errors`, since we end up reporting an error, we never actually proceed to coherence checking, where we would be emitting a more useful impl overlap error.
This change means that we may report more errors in some cases, but can at least proceed far enough to leave a useful message for overlapping traits with RPITITs in them.
Fixes#116982
r? types
Avoid a `track_errors` by bubbling up most errors from `check_well_formed`
I believe `track_errors` is mostly papering over issues that a sufficiently convoluted query graph can hit. I made this change, while the actual change I want to do is to stop bailing out early on errors, and instead use this new `ErrorGuaranteed` to invoke `check_well_formed` for individual items before doing all the `typeck` logic on them.
This works towards resolving https://github.com/rust-lang/rust/issues/97477 and various other ICEs, as well as allowing us to use parallel rustc more (which is currently rather limited/bottlenecked due to the very sequential nature in which we do `rustc_hir_analysis::check_crate`)
cc `@SparrowLii` `@Zoxc` for the new `try_par_for_each_in` function