Use `tracing` spans to trace the entire MIR interp stack
r? @RalfJung
While being very verbose, this allows really good tracking of what's going on. While I considered schemes like the previous indenter that we had (which we could get by using the `tracing-tree` crate), this will break down horribly with things like multithreaded rustc. Instead, we can now use `RUSTC_LOG` to restrict the things being traced. You could specify a filter in a way that only shows the logging of a specific frame.

If we lower the span's level to `debug`, then in `info` level logging we'd not see the frames, but in `debug` level we would see them. The filtering rules in `tracing` are super powerful, but I'm not sure if we can specify a filter so we do see `debug` level events, but *not* the `frame` spans. The documentation at https://docs.rs/tracing-subscriber/0.2.10/tracing_subscriber/struct.EnvFilter.html makes me think that we can only turn on things, not turn off things at a more precise level.
cc @hawkw
This commit improves the way build-manifest calculates the checksums
included in the manifest, speeding it up:
* Instead of calculating all the hashes beforehand and then using the
ones we need, the manifest is first generated with placeholder hashes,
and then a function walks through the manifest and calculates only the
needed checksums.
* Calculating the checksums is now done in parallel with rayon, to
better utilize all the available disk bandwidth.
* Calculating the checksums now uses the sha2 crate instead of the
sha256sum CLI tool: this avoids the overhead of calling another
process, but more importantly uses hardware acceleration whenever
available (the CLI tool doesn't support it at all).
Refactor versions detection in build-manifest
This PR refactors how `build-manifest` handles versions, making the following changes:
* `build-manifest` now detects the "package releases" on its own, without relying on rustbuild providing them through CLI arguments. This drastically simplifies calling the tool outside of `x.py`, and will allow to ship the prebuilt tool in a tarball in the future, with the goal of stopping to invoke `x.py` during `promote-release`.
* The `tar` command is not used to extract the version and the git hash from tarballs anymore. The `flate2` and `tar` crates are used instead. This makes detecting those pieces of data way faster, as the archive is decompressed just once and we stop parsing the archive once all the information is retrieved.
* The code to extract the version and the git hash now stores all the collected data dynamically, without requiring to add new fields to the `Builder` struct every time.
I tested the changes locally and it should behave the same as before.
r? `@Mark-Simulacrum`
Small improvements in liveness pass
* Remove redundant debug logging (`add_variable` already contains logging).
* Remove redundant fields for a number of live nodes and variables.
* Delay conversion from a symbol to a string until linting.
* Inline contents of specials struct.
* Remove unnecessary local variable exit_ln.
* Use newtype_index for Variable and LiveNode.
* Access live nodes directly through self.lnks[ln].
No functional changes intended (except those related to the logging).
Make `ensure_sufficient_stack()` non-generic, using cargo-llvm-lines
Inspired by [this blog post](https://blog.mozilla.org/nnethercote/2020/08/05/how-to-speed-up-the-rust-compiler-some-more-in-2020/) from `@nnethercote,` I used [cargo-llvm-lines](https://github.com/dtolnay/cargo-llvm-lines/) on the rust compiler itself, to improve it's compile time. This PR contains only one low-hanging fruit, but I also want to share some measurements.
The function `ensure_sufficient_stack()` was monomorphized 1500 times, and with it the `stacker` and `psm` crates, for a total of 1.5% of all llvm IR lines. With some trickery I convert the generic closure into a dynamic one, and thus all that code is only monomorphized once.
# Measurements
Getting these numbers took some fiddling with CLI flags and I [modified](https://github.com/Julian-Wollersberger/cargo-llvm-lines/blob/master/src/main.rs#L115) cargo-llvm-lines to read from a folder instead of invoking cargo. Commands I used:
```
./x.py clean
RUSTFLAGS="--emit=llvm-ir -C link-args=-fuse-ld=lld -Z self-profile=profile" CARGOFLAGS_BOOTSTRAP="-Ztimings" RUSTC_BOOTSTRAP=1 ./x.py build -i --stage 1 library/std
# Then manually copy all .ll files into a folder I hardcoded in cargo-llvm-lines in main.rs#L115
cd ../cargo-llvm-lines
cargo run llvm-lines
```
The result is this list (see [first 500 lines](https://github.com/Julian-Wollersberger/cargo-llvm-lines/blob/master/llvm-lines-rustc-before.txt) ), before the change:
```
Lines Copies Function name
----- ------ -------------
16894211 (100%) 58417 (100%) (TOTAL)
2223855 (13.2%) 502 (0.9%) rustc_query_system::query::plumbing::get_query_impl::{{closure}}
1331918 (7.9%) 1287 (2.2%) hashbrown::raw::RawTable<T>::reserve_rehash
774434 (4.6%) 12043 (20.6%) core::ptr::drop_in_place
294170 (1.7%) 499 (0.9%) rustc_query_system::dep_graph::graph::DepGraph<K>::with_task_impl
245410 (1.5%) 1552 (2.7%) psm::on_stack::with_on_stack
210311 (1.2%) 1 (0.0%) rustc_target::spec::load_specific
200962 (1.2%) 513 (0.9%) rustc_query_system::query::plumbing::get_query_impl
190704 (1.1%) 1 (0.0%) rustc_middle::ty::query::<impl rustc_middle::ty::context::TyCtxt>::alloc_self_profile_query_strings
180272 (1.1%) 468 (0.8%) rustc_query_system::query::plumbing::load_from_disk_and_cache_in_memory
177396 (1.1%) 114 (0.2%) rustc_query_system::query::plumbing::force_query_impl
161134 (1.0%) 445 (0.8%) rustc_query_system::dep_graph::graph::DepGraph<K>::with_anon_task
141551 (0.8%) 186 (0.3%) rustc_query_system::query::plumbing::incremental_verify_ich
110191 (0.7%) 7 (0.0%) rustc_middle::ty::context::_DERIVE_rustc_serialize_Decodable_D_FOR_TypeckResults::<impl rustc_serialize::serialize::Decodable<__D> for rustc_middle::ty::context::TypeckResults>::decode::{{closure}}
108590 (0.6%) 420 (0.7%) core::ops::function::FnOnce::call_once
88488 (0.5%) 21 (0.0%) rustc_query_system::dep_graph::graph::DepGraph<K>::try_mark_previous_green
86368 (0.5%) 1 (0.0%) rustc_middle::ty::query::stats::query_stats
85654 (0.5%) 3973 (6.8%) <&T as core::fmt::Debug>::fmt
84475 (0.5%) 1 (0.0%) rustc_middle::ty::query::Queries::try_collect_active_jobs
81220 (0.5%) 862 (1.5%) <hashbrown::raw::RawIterHash<T> as core::iter::traits::iterator::Iterator>::next
77636 (0.5%) 54 (0.1%) core::slice::sort::recurse
66484 (0.4%) 461 (0.8%) <hashbrown::raw::RawIter<T> as core::iter::traits::iterator::Iterator>::next
```
All `.ll` files together had 4.4GB. After my change they had 4.2GB. So a few percent less code LLVM has to process. Hurray!
Sadly, I couldn't measure an actual wall-time improvement. Watching YouTube while compiling added to much noise...
Here is the top of the list after the change:
```
16460866 (100%) 58341 (100%) (TOTAL)
1903085 (11.6%) 504 (0.9%) rustc_query_system::query::plumbing::get_query_impl::{{closure}}
1331918 (8.1%) 1287 (2.2%) hashbrown::raw::RawTable<T>::reserve_rehash
777796 (4.7%) 12031 (20.6%) core::ptr::drop_in_place
551462 (3.4%) 1519 (2.6%) rustc_data_structures::stack::ensure_sufficient_stack::{{closure}}
```
Note that the total was reduced by 430 000 lines and `psm::on_stack::with_on_stack` has disappeared. Instead `rustc_data_structures::stack::ensure_sufficient_stack::{{closure}}` appeared. I'm confused about that one, but it seems to consist of inlined calls to `rustc_query_system::*` stuff.
Further note the other two big culprits in this list: `rustc_query_system` and `hashbrown`. These two are monomorphized many times, the query system summing to more than 20% of all lines, not even counting code that's probably inlined elsewhere.
Assuming compile times scale linearly with llvm-lines, that means a possible 20% compile time reduction.
Reducing eg. `get_query_impl` would probably need a major refactoring of the qery system though. _Everything_ in there is generic over multiple types, has associated types and passes generic Self arguments by value. Which means you can't simply make things `dyn`.
---------------------------------------
This PR is a small step to make rustc compile faster and thus make contributing to rustc less painful. Nonetheless I love Rust and I find the work around rustc fascinating :)
Add sample defaults for config.toml
- Allow including defaults in `src/bootstrap/defaults` using `profile = "..."`.
- Add default config files, with a README noting they're experimental and asking you to open an issue if you run into trouble. The config files have comments explaining why the defaults are set.
- Combine config files using the `merge` dependency.
This introduces a new dependency on `merge` that hasn't yet been vetted.
I want to improve the output when `include = "x"` isn't found:
```
thread 'main' panicked at 'fs::read_to_string(&file) failed with No such file or directory (os error 2) ("configuration file did not exist")', src/bootstrap/config.rs:522:28
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failed to run: /home/joshua/rustc/build/bootstrap/debug/bootstrap test tidy
Build completed unsuccessfully in 0:00:00
```
However that seems like it could be fixed in a follow-up.
Closes#76619
- Allow including defaults in `src/bootstrap/defaults` using `profile = "..."`
- Add default config files
- Combine config files using the merge dependency.
- Add comments to default config files
- Add a README asking to open an issue if the defaults are bad
- Give a loud error if trying to merge `.target`, since it's not
currently supported
- Use an exhaustive match
- Use `<none>` in config.toml.example to avoid confusion
- Fix bugs in `Merge` derives
Previously, it would completely ignore the profile defaults if there
were any settings in `config.toml`. I sent an email to the `merge` maintainer
asking them to make the behavior in this commit the default.
This introduces a new dependency on `merge` that hasn't yet been vetted.
I want to improve the output when `include = "x"` isn't found:
```
thread 'main' panicked at 'fs::read_to_string(&file) failed with No such file or directory (os error 2) ("configuration file did not exist")', src/bootstrap/config.rs:522:28
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failed to run: /home/joshua/rustc/build/bootstrap/debug/bootstrap test tidy
Build completed unsuccessfully in 0:00:00
```
However that seems like it could be fixed in a follow-up.
Upgrade libz-sys to 1.1.2
The current version has warnings that become errors on new versions of clang shipped in XCode:
```
warning: src/zlib/gzlib.c:214:15: error: implicitly declaring library function 'snprintf' with type 'int (char *, unsigned long, const char *, ...)' [-Werror,-Wimplicit-function-declaration]
warning: (void)snprintf(state->path, len + 1, "%s", (const char *)path);
warning: ^
warning: src/zlib/gzlib.c:214:15: note: include the header <stdio.h> or explicitly provide a declaration for 'snprintf'
warning: 1 error generated.
warning: src/zlib/gzwrite.c:428:11: error: implicitly declaring library function 'vsnprintf' with type 'int (char *, unsigned long, const char *, __builtin_va_list)' [-Werror,-Wimplicit-function-declaration
warning: len = vsnprintf(next, state->size, format, va);
warning: ^
warning: src/zlib/gzwrite.c:428:11: note: include the header <stdio.h> or explicitly provide a declaration for 'vsnprintf'
warning: 1 error generated.
```
r? `@Mark-Simulacrum`
/cc `@joshtriplett`
Issue 72408 nested closures exponential
This fixes#72408.
Nested closures were resulting in exponential compilation time.
This PR is enhancing asymptotic complexity, but also increasing the constant, so I would love to see perf run results.
This fixes#72408.
Nested closures were resulting in exponential compilation time.
As a performance optimization this change introduces MiniSet,
which is a simple small storage optimized set.
Auto-generate lint documentation.
This adds a tool which will generate the lint documentation in the rustc book automatically. This is motivated by keeping the documentation up-to-date, and consistently formatted. It also ensures the examples are correct and that they actually generate the expected lint. The lint groups table is also auto-generated. See https://github.com/rust-lang/compiler-team/issues/349 for the original proposal.
An outline of how this works:
- The `declare_lint!` macro now accepts a doc comment where the documentation is written. This is inspired by how clippy works.
- A new tool `src/tools/lint-docs` scrapes the documentation and adds it to the rustc book during the build.
- It runs each example and verifies its output and embeds the output in the book.
- It does a few formatting checks.
- It verifies that every lint is documented.
- Groups are collected from `rustc -W help`.
I updated the documentation for all the missing lints. I have also added an "Explanation" section to each lint providing a reason for the lint and suggestions on how to resolve it.
This can lead towards a future enhancement of possibly showing these docs via the `--explain` flag to make them easily accessible and discoverable.
Thanks to marcusklaas' hard work in https://github.com/raphlinus/pulldown-cmark/pull/469, this fixes a lot of rustdoc bugs!
- Get rid of unnecessary `RefCell`
- Fix duplicate warnings for broken implicit reference link
- Remove unnecessary copy of links
Tracing update
This does not bring the more significant changes that are coming down the pipeline, but since I've already prepared the PR leaving it up :)
See https://github.com/rust-lang/rust/pull/76210#issuecomment-685065938:
> Unfortunately, tracing 0.1.20 — which contained the change to reduce the amount of code generated by the tracing macros — had to be yanked, as it broke previously-compiling code for some downstream crates. I've not yet had the chance to fix this and release a new patch. So, in order to benefit from the changes to reduce generated code, you'll need to wait until there's a new version of tracing as well as tracing-attributes and tracing-core.
Add derive macro for specifying diagnostics using attributes.
Introduces `#[derive(SessionDiagnostic)]`, a derive macro for specifying structs that can be converted to Diagnostics using directions given by attributes on the struct and its fields. Currently, the following attributes have been implemented:
- `#[code = "..."]` -- this sets the Diagnostic's error code, and must be provided on the struct iself (ie, not on a field). Equivalent to calling `code`.
- `#[message = "..."]` -- this sets the Diagnostic's primary error message.
- `#[label = "..."]` -- this must be applied to fields of type `Span`, and is equivalent to `span_label`
- `#[suggestion(..)]` -- this allows a suggestion message to be supplied. This attribute must be applied to a field of type `Span` or `(Span, Applicability)`, and is equivalent to calling `span_suggestion`. Valid arguments are:
- `message = "..."` -- this sets the suggestion message.
- (Optional) `code = "..."` -- this suggests code for the suggestion. Defaults to empty.
`suggestion`also comes with other variants: `#[suggestion_short(..)]`, `#[suggestion_hidden(..)]` and `#[suggestion_verbose(..)]` which all take the same keys.
Within the strings passed to each attribute, fields can be referenced without needing to be passed explicitly into the format string -- eg, `#[error = "{ident} already declared"] ` will set the error message to `format!("{} already declared", &self.ident)`. Any fields on the struct can be referenced in this way.
Additionally, for any of these attributes, Option fields can be used to only optionally apply the decoration -- for example:
```rust
#[derive(SessionDiagnostic)]
#[code = "E0123"]
struct SomeKindOfError {
...
#[suggestion(message = "informative error message")]
opt_sugg: Option<(Span, Applicability)>
...
}
```
will not emit a suggestion if `opt_sugg` is `None`.
We plan on iterating on this macro further; this PR is a start.
Closes#61132.
r? `@oli-obk`
Support dataflow problems on arbitrary lattices
This PR implements last of the proposed extensions I mentioned in the design meeting for the original dataflow refactor. It extends the current dataflow framework to work with arbitrary lattices, not just `BitSet`s. This is a prerequisite for dataflow-enabled MIR const-propagation. Personally, I am skeptical of the usefulness of doing const-propagation pre-monomorphization, since many useful constants only become known after monomorphization (e.g. `size_of::<T>()`) and users have a natural tendency to hand-optimize the rest. It's probably worth exprimenting with, however, and others have shown interest cc `@rust-lang/wg-mir-opt.`
The `Idx` associated type is moved from `AnalysisDomain` to `GenKillAnalysis` and replaced with an associated `Domain` type that must implement `JoinSemiLattice`. Like before, each `Analysis` defines the "bottom value" for its domain, but can no longer override the dataflow join operator. Analyses that want to use set intersection must now use the `lattice::Dual` newtype. `GenKillAnalysis` impls have an additional requirement that `Self::Domain: BorrowMut<BitSet<Self::Idx>>`, which effectively means that they must use `BitSet<Self::Idx>` or `lattice::Dual<BitSet<Self::Idx>>` as their domain.
Most of these changes were mechanical. However, because a `Domain` is no longer always a powerset of some index type, we can no longer use an `IndexVec<BasicBlock, GenKillSet<A::Idx>>>` to store cached block transfer functions. Instead, we use a boxed `dyn Fn` trait object. I discuss a few alternatives to the current approach in a commit message.
The majority of new lines of code are to preserve existing Graphviz diagrams for those unlucky enough to have to debug dataflow analyses. I find these diagrams incredibly useful when things are going wrong and considered regressing them unacceptable, especially the pretty-printing of `MovePathIndex`s, which are used in many dataflow analyses. This required a parallel `fmt` trait used only for printing dataflow domains, as well as a refactoring of the `graphviz` module now that we cannot expect the domain to be a `BitSet`. Some features did have to be removed, such as the gen/kill display mode (which I didn't use but existed to mirror the output of the old dataflow framework) and line wrapping. Since I had to rewrite much of it anyway, I took the opportunity to switch to a `Visitor` for printing dataflow state diffs instead of using cursors, which are error prone for code that must be generic over both forward and backward analyses. As a side-effect of this change, we no longer have quadratic behavior when writing graphviz diagrams for backward dataflow analyses.
r? `@pnkfelix`
Update expect-test to 1.0
The only change is that `expect_file` now uses path relative to the
current file (same as `include!`). Before, it used paths relative to
the workspace root, which makes no sense.
The only change is that `expect_file` now uses path relative to the
current file (same as `include!`). Before, it used paths relative to
the workspace root, which makes no sense.
Rollup of 14 pull requests
Successful merges:
- #75832 (Move to intra-doc links for wasi/ext/fs.rs, os_str_bytes.rs…)
- #75852 (Switch to intra-doc links in `core::hash`)
- #75874 (Shorten liballoc doc intra link while readable)
- #75881 (Expand rustdoc theme chooser x padding)
- #75885 (Fix another clashing_extern_declarations false positive.)
- #75892 (Fix typo in TLS Model in Unstable Book)
- #75910 (Add test for issue #27130)
- #75917 (Move to intra doc links for core::ptr::non_null)
- #75975 (Allow --bess ing expect-tests in tools)
- #75990 (Add __fastfail for Windows on arm/aarch64)
- #76015 (Fix loading pretty-printers in rust-lldb script)
- #76022 (Clean up rustdoc front-end source code)
- #76029 (Move to intra-doc links for library/core/src/sync/atomic.rs)
- #76057 (Move retokenize hack to save_analysis)
Failed merges:
r? @ghost
Update compiler-builtins
Update the compiler-builtins dependency to include latest changes.
This allows for `aarch64-unknown-linux-musl` to pass all tests.
Fixes#57820 and fixes#46651
It's a unit-test in a sense that it only checks syntax highlighting.
However, the resulting HTML is written to disk and can be easily
inspected in the browser.
To update the test, run with `--bless` argument or set
`UPDATE_EXPEC=1` env var
Introduce expect snapshot testing library into rustc
Snapshot testing is a technique for writing maintainable unit tests.
Unlike usual `assert_eq!` tests, snapshot tests allow
to *automatically* upgrade expected values on test failure.
In a sense, snapshot tests are inline-version of our beloved
UI-tests.
Example:
A particular library we use, `expect_test` provides an `expect!`
macro, which creates a sort of self-updating string literal (by using
`file!` macro). Self-update is triggered by setting `UPDATE_EXPECT`
environmental variable (this info is printed during the test failure).
This library was extracted from rust-analyzer, where we use it for
most of our tests.
There are some other, more popular snapshot testing libraries:
* https://github.com/mitsuhiko/insta
* https://github.com/aaronabramov/k9
The main differences of `expect` are:
* first-class snapshot objects (so, tests can be written as functions,
rather than as macros)
* focus on inline-snapshots (but file snapshots are also supported)
* restricted feature set (only `assert_eq` and `assert_debug_eq`)
* no extra runtime (ie, no `cargo insta`)
See rust-analyzer/rust-analyzer#5101 for a
an extended comparison.
It is unclear if this testing style will stick with rustc in the long
run. At the moment, rustc is mainly tested via integrated UI tests.
But in the library-ified world, unit-tests will become somewhat more
important (that's why use use `rustc_lexer` library-ified library as
an example in this PR). Given that the cost of removal shouldn't be
too high, it probably makes sense to just see if this flies!
Snapshot testing is a technique for writing maintainable unit tests.
Unlike usual `assert_eq!` tests, snapshot tests allow
to *automatically* upgrade expected values on test failure.
In a sense, snapshot tests are inline-version of our beloved
UI-tests.
Example:

A particular library we use, `expect_test` provides an `expect!`
macro, which creates a sort of self-updating string literal (by using
`file!` macro). Self-update is triggered by setting `UPDATE_EXPECT`
environmental variable (this info is printed during the test failure).
This library was extracted from rust-analyzer, where we use it for
most of our tests.
There are some other, more popular snapshot testing libraries:
* https://github.com/mitsuhiko/insta
* https://github.com/aaronabramov/k9
The main differences of `expect` are:
* first-class snapshot objects (so, tests can be written as functions,
rather than as macros)
* focus on inline-snapshots (but file snapshots are also supported)
* restricted feature set (only `assert_eq` and `assert_debug_eq`)
* no extra runtime (ie, no `cargo insta`)
See https://github.com/rust-analyzer/rust-analyzer/pull/5101 for a
an extended comparison.
It is unclear if this testing style will stick with rustc in the long
run. At the moment, rustc is mainly tested via integrated UI tests.
But in the library-ified world, unit-tests will become somewhat more
important (that's why use use `rustc_lexer` library-ified library as
an example in this PR). Given that the cost of removal shouldn't be
too high, it probably makes sense to just see if this flies!
- Move the type parameter from `encode` and `decode` methods to
the trait.
- Remove `UseSpecialized(En|De)codable` traits.
- Remove blanket impls for references.
- Add `RefDecodable` trait to allow deserializing to arena-allocated
references safely.
- Remove ability to (de)serialize HIR.
- Create proc-macros `(Ty)?(En|De)codable` to help implement these new
traits.
Move platform support to the rustc book.
This moves the [Platform Support](https://forge.rust-lang.org/release/platform-support.html) page from the forge to the rustc book. There are several reasons for doing this:
* The forge is not really oriented towards end-users (it mostly contains infrastructure, governance and policy, internal team pages, etc.). This platform support page is useful to user to know which targets are supported.
* This page can now be updated in-sync with any PRs that add or remove a target, or change its status.
* This is now automatically checked on CI to verify the list does not get out of sync. Currently it only checks the presence/absence of an entry, but more sophisticated checks could be added in the future.
I'm not 100% certain this is the best location, but I think it fits. I'd like to see the rustc guide continue to grow, including things like linking information and more platform-specific details.
Avoid deleting temporary files on error
Previously if the compiler error'd, fatally, then temporary directories which
should be preserved by -Csave-temps would be deleted due to fatal compiler
errors being implemented as panics.
cc @infinity0
(Hopefully) fixes#75275, but I haven't tested
Previously if the compiler error'd, fatally, then temporary directories which
should be preserved by -Csave-temps would be deleted due to fatal compiler
errors being implemented as panics.
By moving `{known,used}_attrs` from `SessionGlobals` to `Session`. This
means they are accessed via the `Session`, rather than via TLS. A few
`Attr` methods and `librustc_ast` functions are now methods of
`Session`.
All of this required passing a `Session` to lots of functions that didn't
already have one. Some of these functions also had arguments removed, because
those arguments could be accessed directly via the `Session` argument.
`contains_feature_attr()` was dead, and is removed.
Some functions were moved from `librustc_ast` elsewhere because they now need
to access `Session`, which isn't available in that crate.
- `entry_point_type()` --> `librustc_builtin_macros`
- `global_allocator_spans()` --> `librustc_metadata`
- `is_proc_macro_attr()` --> `Session`
We store an `ImplicitCtxt` pointer in a thread-local value (TLV). This allows
implicit access to a `GlobalCtxt` and some other things.
We also store a `GlobalCtxt` pointer in `GCX_PTR`. This is always the same
`GlobalCtxt` as the one within the `ImplicitCtxt` pointer in TLV. `GCX_PTR`
is only used in the parallel compiler's `handle_deadlock()` function.
This commit does the following.
- It removes `GCX_PTR`.
- It also adds `ImplicitCtxt::new()`, which constructs an `ImplicitCtxt` from a
`GlobalCtxt`. `ImplicitCtxt::new()` + `tls::enter_context()` is now
equivalent to the old `tls::enter_global()`.
- Makes `tls::get_tlv()` public for the parallel compiler, because it's
now used in `handle_deadlock()`.
Update cargo
14 commits in aa6872140ab0fa10f641ab0b981d5330d419e927..974eb438da8ced6e3becda2bbf63d9b643eacdeb
2020-07-23 13:46:27 +0000 to 2020-07-29 16:15:05 +0000
- Fix O0 build scripts by default without `[profile.release]` (rust-lang/cargo#8560)
- Emphasize git dependency version locking behavior. (rust-lang/cargo#8561)
- Update lock file encodings on changes (rust-lang/cargo#8554)
- Fix sporadic lto test failures. (rust-lang/cargo#8559)
- build-std: Fix libraries paths following upstream (rust-lang/cargo#8558)
- Flag git http errors as maybe spurious (rust-lang/cargo#8553)
- Display builtin aliases with `cargo --list` (rust-lang/cargo#8542)
- Check manifest for requiring nonexistent features (rust-lang/cargo#7950)
- Clarify test name filter usage (rust-lang/cargo#8552)
- Revert Cargo Book changes for default edition (rust-lang/cargo#8551)
- Prepare for not defaulting to master branch for git deps (rust-lang/cargo#8522)
- Include `+` for crates.io feature requirements in the Cargo Book section on features (rust-lang/cargo#8547)
- Update termcolor and fwdansi versions (rust-lang/cargo#8540)
- Cargo book nitpick in Manifest section (rust-lang/cargo#8543)
This commit is a proof-of-concept for switching the standard library's
backtrace symbolication mechanism on most platforms from libbacktrace to
gimli. The standard library's support for `RUST_BACKTRACE=1` requires
in-process parsing of object files and DWARF debug information to
interpret it and print the filename/line number of stack frames as part
of a backtrace.
Historically this support in the standard library has come from a
library called "libbacktrace". The libbacktrace library seems to have
been extracted from gcc at some point and is written in C. We've had a
lot of issues with libbacktrace over time, unfortunately, though. The
library does not appear to be actively maintained since we've had
patches sit for months-to-years without comments. We have discovered a
good number of soundness issues with the library itself, both when
parsing valid DWARF as well as invalid DWARF. This is enough of an issue
that the libs team has previously decided that we cannot feed untrusted
inputs to libbacktrace. This also doesn't take into account the
portability of libbacktrace which has been difficult to manage and
maintain over time. While possible there are lots of exceptions and it's
the main C dependency of the standard library right now.
For years it's been the desire to switch over to a Rust-based solution
for symbolicating backtraces. It's been assumed that we'll be using the
Gimli family of crates for this purpose, which are targeted at safely
and efficiently parsing DWARF debug information. I've been working
recently to shore up the Gimli support in the `backtrace` crate. As of a
few weeks ago the `backtrace` crate, by default, uses Gimli when loaded
from crates.io. This transition has gone well enough that I figured it
was time to start talking seriously about this change to the standard
library.
This commit is a preview of what's probably the best way to integrate
the `backtrace` crate into the standard library with the Gimli feature
turned on. While today it's used as a crates.io dependency, this commit
switches the `backtrace` crate to a submodule of this repository which
will need to be updated manually. This is not done lightly, but is
thought to be the best solution. The primary reason for this is that the
`backtrace` crate needs to do some pretty nontrivial filesystem
interactions to locate debug information. Working without `std::fs` is
not an option, and while it might be possible to do some sort of
trait-based solution when prototyped it was found to be too unergonomic.
Using a submodule allows the `backtrace` crate to build as a submodule
of the `std` crate itself, enabling it to use `std::fs` and such.
Otherwise this adds new dependencies to the standard library. This step
requires extra attention because this means that these crates are now
going to be included with all Rust programs by default. It's important
to note, however, that we're already shipping libbacktrace with all Rust
programs by default and it has a bunch of C code implementing all of
this internally anyway, so we're basically already switching
already-shipping functionality to Rust from C.
* `object` - this crate is used to parse object file headers and
contents. Very low-level support is used from this crate and almost
all of it is disabled. Largely we're just using struct definitions as
well as convenience methods internally to read bytes and such.
* `addr2line` - this is the main meat of the implementation for
symbolication. This crate depends on `gimli` for DWARF parsing and
then provides interfaces needed by the `backtrace` crate to turn an
address into a filename / line number. This crate is actually pretty
small (fits in a single file almost!) and mirrors most of what
`dwarf.c` does for libbacktrace.
* `miniz_oxide` - the libbacktrace crate transparently handles
compressed debug information which is compressed with zlib. This crate
is used to decompress compressed debug sections.
* `gimli` - not actually used directly, but a dependency of `addr2line`.
* `adler32`- not used directly either, but a dependency of
`miniz_oxide`.
The goal of this change is to improve the safety of backtrace
symbolication in the standard library, especially in the face of
possibly malformed DWARF debug information. Even to this day we're still
seeing segfaults in libbacktrace which could possibly become security
vulnerabilities. This change should almost entirely eliminate this
possibility whilc also paving the way forward to adding more features
like split debug information.
Some references for those interested are:
* Original addition of libbacktrace - #12602
* OOM with libbacktrace - #24231
* Backtrace failure due to use of uninitialized value - #28447
* Possibility to feed untrusted data to libbacktrace - #21889
* Soundness fix for libbacktrace - #33729
* Crash in libbacktrace - #39468
* Support for macOS, never merged - ianlancetaylor/libbacktrace#2
* Performance issues with libbacktrace - #29293, #37477
* Update procedure is quite complicated due to how many patches we
need to carry - #50955
* Libbacktrace doesn't work on MinGW with dynamic libs - #71060
* Segfault in libbacktrace on macOS - #71397
Switching to Rust will not make us immune to all of these issues. The
crashes are expected to go away, but correctness and performance may
still have bugs arise. The gimli and `backtrace` crates, however, are
actively maintained unlike libbacktrace, so this should enable us to at
least efficiently apply fixes as situations come up.
revise RwLock for HermitCore
- current version is derived from the wasm implementation
- increasing the readability of `Condvar`
- simplify the interface to the libos
Revert libbacktrace -> gimli
This reverts 4cbd265c11028f8d7b8513db3cc1e8d7a36d8964 (and technically 79673d3009 but it's made empty by previous reverts).
The current plan is to land this PR as a temporary change, so that we can get a better handle on the regressions introduced by it. Trying to fix/examine them in master is difficult, and we want to be better able to evaluate them without impact to other PRs being landed in the mean time.
That said, it is currently *my* belief that gimli, in one form or another, will need to land sometime soon. I think it's quite likely that it may slip a week or two, but I would personally push for re-landing it then "regardless" of the regressions. We should try to focus efforts on understanding and removing as much of the performance impact as possible, as everyone pretty much agrees that it should be quite minimal (and entirely in the linker, basically).
r? @nnethercote
Generating the coverage map
@tmandry @wesleywiser
rustc now generates the coverage map and can support (limited)
coverage report generation, at the function level.
Example commands to generate a coverage report:
```shell
$ BUILD=$HOME/rust/build/x86_64-unknown-linux-gnu
$ $BUILD/stage1/bin/rustc -Zinstrument-coverage \
$HOME/rust/src/test/run-make-fulldeps/instrument-coverage/main.rs
$ LLVM_PROFILE_FILE="main.profraw" ./main
called
$ $BUILD/llvm/bin/llvm-profdata merge -sparse main.profraw -o main.profdata
$ $BUILD/llvm/bin/llvm-cov show --instr-profile=main.profdata main
```
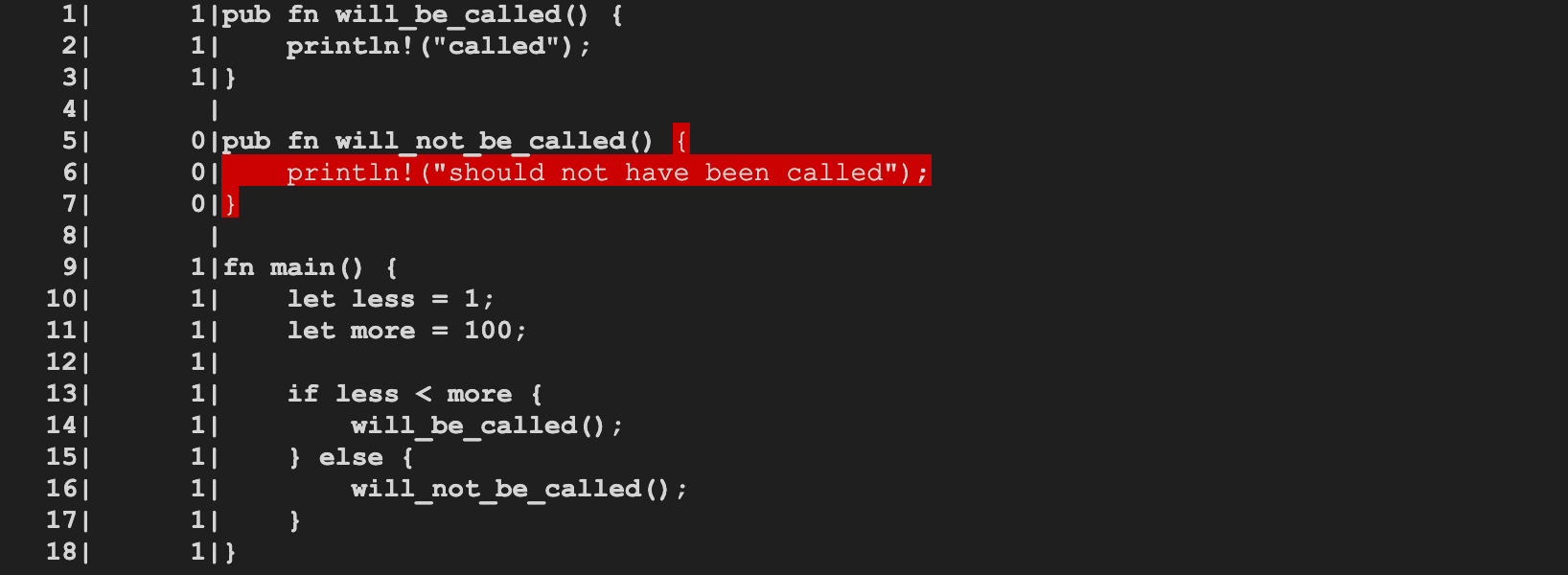
r? @wesleywiser
Rust compiler MCP rust-lang/compiler-team#278
Relevant issue: #34701 - Implement support for LLVMs code coverage instrumentation
std: Switch from libbacktrace to gimli
This commit is a proof-of-concept for switching the standard library's
backtrace symbolication mechanism on most platforms from libbacktrace to
gimli. The standard library's support for `RUST_BACKTRACE=1` requires
in-process parsing of object files and DWARF debug information to
interpret it and print the filename/line number of stack frames as part
of a backtrace.
Historically this support in the standard library has come from a
library called "libbacktrace". The libbacktrace library seems to have
been extracted from gcc at some point and is written in C. We've had a
lot of issues with libbacktrace over time, unfortunately, though. The
library does not appear to be actively maintained since we've had
patches sit for months-to-years without comments. We have discovered a
good number of soundness issues with the library itself, both when
parsing valid DWARF as well as invalid DWARF. This is enough of an issue
that the libs team has previously decided that we cannot feed untrusted
inputs to libbacktrace. This also doesn't take into account the
portability of libbacktrace which has been difficult to manage and
maintain over time. While possible there are lots of exceptions and it's
the main C dependency of the standard library right now.
For years it's been the desire to switch over to a Rust-based solution
for symbolicating backtraces. It's been assumed that we'll be using the
Gimli family of crates for this purpose, which are targeted at safely
and efficiently parsing DWARF debug information. I've been working
recently to shore up the Gimli support in the `backtrace` crate. As of a
few weeks ago the `backtrace` crate, by default, uses Gimli when loaded
from crates.io. This transition has gone well enough that I figured it
was time to start talking seriously about this change to the standard
library.
This commit is a preview of what's probably the best way to integrate
the `backtrace` crate into the standard library with the Gimli feature
turned on. While today it's used as a crates.io dependency, this commit
switches the `backtrace` crate to a submodule of this repository which
will need to be updated manually. This is not done lightly, but is
thought to be the best solution. The primary reason for this is that the
`backtrace` crate needs to do some pretty nontrivial filesystem
interactions to locate debug information. Working without `std::fs` is
not an option, and while it might be possible to do some sort of
trait-based solution when prototyped it was found to be too unergonomic.
Using a submodule allows the `backtrace` crate to build as a submodule
of the `std` crate itself, enabling it to use `std::fs` and such.
Otherwise this adds new dependencies to the standard library. This step
requires extra attention because this means that these crates are now
going to be included with all Rust programs by default. It's important
to note, however, that we're already shipping libbacktrace with all Rust
programs by default and it has a bunch of C code implementing all of
this internally anyway, so we're basically already switching
already-shipping functionality to Rust from C.
* `object` - this crate is used to parse object file headers and
contents. Very low-level support is used from this crate and almost
all of it is disabled. Largely we're just using struct definitions as
well as convenience methods internally to read bytes and such.
* `addr2line` - this is the main meat of the implementation for
symbolication. This crate depends on `gimli` for DWARF parsing and
then provides interfaces needed by the `backtrace` crate to turn an
address into a filename / line number. This crate is actually pretty
small (fits in a single file almost!) and mirrors most of what
`dwarf.c` does for libbacktrace.
* `miniz_oxide` - the libbacktrace crate transparently handles
compressed debug information which is compressed with zlib. This crate
is used to decompress compressed debug sections.
* `gimli` - not actually used directly, but a dependency of `addr2line`.
* `adler32`- not used directly either, but a dependency of
`miniz_oxide`.
The goal of this change is to improve the safety of backtrace
symbolication in the standard library, especially in the face of
possibly malformed DWARF debug information. Even to this day we're still
seeing segfaults in libbacktrace which could possibly become security
vulnerabilities. This change should almost entirely eliminate this
possibility whilc also paving the way forward to adding more features
like split debug information.
Some references for those interested are:
* Original addition of libbacktrace - #12602
* OOM with libbacktrace - #24231
* Backtrace failure due to use of uninitialized value - #28447
* Possibility to feed untrusted data to libbacktrace - #21889
* Soundness fix for libbacktrace - #33729
* Crash in libbacktrace - #39468
* Support for macOS, never merged - ianlancetaylor/libbacktrace#2
* Performance issues with libbacktrace - #29293, #37477
* Update procedure is quite complicated due to how many patches we
need to carry - #50955
* Libbacktrace doesn't work on MinGW with dynamic libs - #71060
* Segfault in libbacktrace on macOS - #71397
Switching to Rust will not make us immune to all of these issues. The
crashes are expected to go away, but correctness and performance may
still have bugs arise. The gimli and `backtrace` crates, however, are
actively maintained unlike libbacktrace, so this should enable us to at
least efficiently apply fixes as situations come up.
---
I want to note that my purpose for creating a PR here is to start a conversation about this. I think that all the various pieces are in place that this is compelling enough that I think this transition should be talked about seriously. There are a number of items which still need to be addressed before actually merging this PR, however:
* [ ] `gimli` needs to be published to crates.io
* [ ] `addr2line` needs a publish
* [ ] `miniz_oxide` needs a publish
* [ ] Tests probably shouldn't recommend the `gimli` crate's traits for implementing
* [ ] The `backtrace` crate's branch changes need to be merged to the master branch (https://github.com/rust-lang/backtrace-rs/pull/349)
* [ ] The support for `libbacktrace` on some platforms needs to be audited to see if we should support more strategies in the gimli implementation - https://github.com/rust-lang/backtrace-rs/issues/325, https://github.com/rust-lang/backtrace-rs/issues/326, https://github.com/rust-lang/backtrace-rs/issues/350, https://github.com/rust-lang/backtrace-rs/issues/351
Most of the merging/publishing I'm not actively pushing on right now. It's a bit wonky for crates to support libstd so I'm holding off on pulling the trigger everywhere until there's a bit more discussion about how to go through with this. Namely https://github.com/rust-lang/backtrace-rs/pull/349 I'm going to hold off merging until we decide to go through with the submodule strategy.
In any case this is a pretty major change, so I suspect that the compiler team is likely going to be interested in this. I don't mean to force changes by dumping a bunch of code by any means. Integration of external crates into the standard library is so difficult I wanted to have a proof-of-concept to review while talking about whether to do this at all (hence the PR), but I'm more than happy to follow any processes needed to merge this. I must admit though that I'm not entirely sure myself at this time what the process would be to decide to merge this, so I'm hoping others can help me figure that out!
This commit is a proof-of-concept for switching the standard library's
backtrace symbolication mechanism on most platforms from libbacktrace to
gimli. The standard library's support for `RUST_BACKTRACE=1` requires
in-process parsing of object files and DWARF debug information to
interpret it and print the filename/line number of stack frames as part
of a backtrace.
Historically this support in the standard library has come from a
library called "libbacktrace". The libbacktrace library seems to have
been extracted from gcc at some point and is written in C. We've had a
lot of issues with libbacktrace over time, unfortunately, though. The
library does not appear to be actively maintained since we've had
patches sit for months-to-years without comments. We have discovered a
good number of soundness issues with the library itself, both when
parsing valid DWARF as well as invalid DWARF. This is enough of an issue
that the libs team has previously decided that we cannot feed untrusted
inputs to libbacktrace. This also doesn't take into account the
portability of libbacktrace which has been difficult to manage and
maintain over time. While possible there are lots of exceptions and it's
the main C dependency of the standard library right now.
For years it's been the desire to switch over to a Rust-based solution
for symbolicating backtraces. It's been assumed that we'll be using the
Gimli family of crates for this purpose, which are targeted at safely
and efficiently parsing DWARF debug information. I've been working
recently to shore up the Gimli support in the `backtrace` crate. As of a
few weeks ago the `backtrace` crate, by default, uses Gimli when loaded
from crates.io. This transition has gone well enough that I figured it
was time to start talking seriously about this change to the standard
library.
This commit is a preview of what's probably the best way to integrate
the `backtrace` crate into the standard library with the Gimli feature
turned on. While today it's used as a crates.io dependency, this commit
switches the `backtrace` crate to a submodule of this repository which
will need to be updated manually. This is not done lightly, but is
thought to be the best solution. The primary reason for this is that the
`backtrace` crate needs to do some pretty nontrivial filesystem
interactions to locate debug information. Working without `std::fs` is
not an option, and while it might be possible to do some sort of
trait-based solution when prototyped it was found to be too unergonomic.
Using a submodule allows the `backtrace` crate to build as a submodule
of the `std` crate itself, enabling it to use `std::fs` and such.
Otherwise this adds new dependencies to the standard library. This step
requires extra attention because this means that these crates are now
going to be included with all Rust programs by default. It's important
to note, however, that we're already shipping libbacktrace with all Rust
programs by default and it has a bunch of C code implementing all of
this internally anyway, so we're basically already switching
already-shipping functionality to Rust from C.
* `object` - this crate is used to parse object file headers and
contents. Very low-level support is used from this crate and almost
all of it is disabled. Largely we're just using struct definitions as
well as convenience methods internally to read bytes and such.
* `addr2line` - this is the main meat of the implementation for
symbolication. This crate depends on `gimli` for DWARF parsing and
then provides interfaces needed by the `backtrace` crate to turn an
address into a filename / line number. This crate is actually pretty
small (fits in a single file almost!) and mirrors most of what
`dwarf.c` does for libbacktrace.
* `miniz_oxide` - the libbacktrace crate transparently handles
compressed debug information which is compressed with zlib. This crate
is used to decompress compressed debug sections.
* `gimli` - not actually used directly, but a dependency of `addr2line`.
* `adler32`- not used directly either, but a dependency of
`miniz_oxide`.
The goal of this change is to improve the safety of backtrace
symbolication in the standard library, especially in the face of
possibly malformed DWARF debug information. Even to this day we're still
seeing segfaults in libbacktrace which could possibly become security
vulnerabilities. This change should almost entirely eliminate this
possibility whilc also paving the way forward to adding more features
like split debug information.
Some references for those interested are:
* Original addition of libbacktrace - #12602
* OOM with libbacktrace - #24231
* Backtrace failure due to use of uninitialized value - #28447
* Possibility to feed untrusted data to libbacktrace - #21889
* Soundness fix for libbacktrace - #33729
* Crash in libbacktrace - #39468
* Support for macOS, never merged - ianlancetaylor/libbacktrace#2
* Performance issues with libbacktrace - #29293, #37477
* Update procedure is quite complicated due to how many patches we
need to carry - #50955
* Libbacktrace doesn't work on MinGW with dynamic libs - #71060
* Segfault in libbacktrace on macOS - #71397
Switching to Rust will not make us immune to all of these issues. The
crashes are expected to go away, but correctness and performance may
still have bugs arise. The gimli and `backtrace` crates, however, are
actively maintained unlike libbacktrace, so this should enable us to at
least efficiently apply fixes as situations come up.
Fix cross compilation of LLVM to aarch64 Windows targets
When cross-compiling, the LLVM build system recurses to build tools that need to run on the host system. However, since we pass cmake defines to set the compiler and target, LLVM still compiles these tools for the target system, rather than the host. The tools then fail to execute during the LLVM build.
This change sets defines for the tools that need to run on the host (llvm-nm, llvm-tablegen, and llvm-config), so that the LLVM build does not attempt to build them, and instead relies on the tools already built.
If compiling with clang-cl, adds the `--target` option to specify the target triple. MSVC compilers do not require this, since there is a separate compiler binary for each cross-compilation target.
Related issue: #72881
Requires LLVM change: rust-lang/llvm-project#67
When cross-compiling, the LLVM build system recurses to build tools
that need to run on the host system. However, since we pass cmake defines
to set the compiler and target, LLVM still compiles these tools for the
target system, rather than the host. The tools then fail to execute
during the LLVM build.
This change sets defines for the tools that need to run on the
host (llvm-nm, llvm-tablegen, and llvm-config), so that the LLVM build
does not attempt to build them, and instead relies on the tools already built.
If compiling with clang-cl, this change also adds the `--target` option
to specify the target triple. MSVC compilers do not require this, since there
is a separate compiler binary for cross-compilation.
This pulls in a fix for the install script on some tr(1) implementations,
as well as an update to use `anyhow` instead of `failure` for error
handling.
Update cargo, rls
## cargo
14 commits in c26576f9adddd254b3dd63aecba176434290a9f6..fede83ccf973457de319ba6fa0e36ead454d2e20
2020-06-23 16:21:21 +0000 to 2020-07-02 21:51:34 +0000
- Fix overflow error on 32-bit. (rust-lang/cargo#8446)
- Exclude the target directory from backups using CACHEDIR.TAG (rust-lang/cargo#8378)
- CONTRIBUTING.md: Link to Zulip rather than Discord (rust-lang/cargo#8436)
- Update built-in help for features (rust-lang/cargo#8433)
- Update core-foundation requirement from 0.7.0 to 0.9.0 (rust-lang/cargo#8432)
- Parse `# env-dep` directives in dep-info files (rust-lang/cargo#8421)
- Move string interning to util (rust-lang/cargo#8419)
- Expose built cdylib artifacts in the Compilation structure (rust-lang/cargo#8418)
- Remove unused serde_derive dependency from the crates.io crate (rust-lang/cargo#8416)
- Remove unused remove_dir_all dependency (rust-lang/cargo#8412)
- Improve git error messages a bit (rust-lang/cargo#8409)
- Improve the description of Config.home_path (rust-lang/cargo#8408)
- Improve support for non-`master` main branches (rust-lang/cargo#8364)
- Document that OUT_DIR in JSON messages is an absolute path (rust-lang/cargo#8403)
## rls
2020-06-19 15:36:00 +0200 to 2020-06-30 23:34:52 +0200
- Update cargo (rust-lang-nursery/rls#1686)
Update Chalk to 0.14
Not a ton here. Notable changes:
- Update to `0.14.0`
- New dependency on `tracing`, in `librustc_traits` only
- `FnAbi` from Chalk is `rustc_target::spec::abi::Abi`
- `Dynamic` actually lowers region
- Actually lower closures, with some tests. This doesn't 100% work, but can't confirm that's *only* because of closure lowering.
- Use `FxIndexSet` instead of `FxHashSet` in `chalk_fulfill`, which seems to have fixed the non-deterministic test error ordering. Guess we'll see on CI
- Actually implement `opaque_ty_data`, though I don't think this is sufficient for tests for them (I haven't added any)
- Uncomment some of the chalk tests that now work
r? @nikomatsakis
Implement mixed script confusable lint.
This implements the mixed script confusable lint defined in RFC 2457.
This is blocked on #72069 and https://github.com/unicode-rs/unicode-security/pull/13, and will need a Cargo.toml version bump after those are resolved.
The lint message warning is sub-optimal for now. We'll need a mechanism to properly output `AugmentScriptSet` to screen, this is to be added in `unicode-security` crate.
r? @Manishearth
Move remaining `NodeId` APIs from `Definitions` to `Resolver`
Implements https://github.com/rust-lang/rust/pull/73291#issuecomment-643515557
TL;DR: it moves all fields that are only needed during name resolution passes into the `Resolver` and keep the rest in `Definitions`. This effectively enforces that all references to `NodeId`s are gone once HIR lowering is completed.
After this, the only remaining work for #50928 should be to adjust the dev guide.
r? @petrochenkov
None of the tools seem to need syn 0.15.35, so we can just build syn
1.0.
This was causing an issue with clippy's `compile-test` program: since
multiple versions of `syn` would exist in the build directory, we would
non-deterministically pick one based on filesystem iteration order. If
the pre-1.0 version of `syn` was picked, a strange build error would
occur (see
https://github.com/rust-lang/rust/pull/73594#issuecomment-647671463)
To prevent this kind of issue from happening again, we now panic if we
find multiple versions of a crate in the build directly, instead of
silently picking the first version we find.
Upgrade Chalk
Things done in this PR:
- Upgrade Chalk to `0.11.0`
- Added compare-mode=chalk
- Bump rustc-hash in `librustc_data_structures` to `1.1.0` to match Chalk
- Removed `RustDefId` since the builtin type support is there
- Add a few more `FIXME(chalk)`s for problem spots I hit when running all tests with chalk
- Added some more implementation code for some newer builtin Chalk types (e.g. `FnDef`, `Array`)
- Lower `RegionOutlives` and `ObjectSafe` predicates
- Lower `Dyn` without the region
- Handle `Int`/`Float` `CanonicalVarKind`s
- Uncomment some Chalk tests that actually work now
- Remove the revisions in `src/test/ui/coherence/coherence-subtyping.rs` since they aren't doing anything different
r? @nikomatsakis
Diagnose use of incompatible sanitizers
Emit an error when incompatible sanitizer are configured through command
line options. Previously the last one configured prevailed and others
were silently ignored.
Additionally use a set to represent configured sanitizers, making it
possible to enable multiple sanitizers at once. At least in principle,
since currently all of them are considered to be incompatible with
others.
{kind=link}
{kind=link}
{kind=link}