get rid of duplicate primitive_docs
Having this duplicate makes editing that file very annoying. And at least locally the generated docs still look perfectly fine...
Add `minmax{,_by,_by_key}` functions to `core::cmp`
This PR adds the following functions:
```rust
// mod core::cmp
#![unstable(feature = "cmp_minmax")]
pub fn minmax<T>(v1: T, v2: T) -> [T; 2]
where
T: Ord;
pub fn minmax_by<T, F>(v1: T, v2: T, compare: F) -> [T; 2]
where
F: FnOnce(&T, &T) -> Ordering;
pub fn minmax_by_key<T, F, K>(v1: T, v2: T, mut f: F) -> [T; 2]
where
F: FnMut(&T) -> K,
K: Ord;
```
(they are also `const` under `#[feature(const_cmp)]`, I've omitted `const` stuff for simplicity/readability)
----
Semantically these functions are equivalent to `{ let mut arr = [v1, v2]; arr.sort(); arr }`, but since they operate on 2 elements only, they are implemented as a single comparison.
Even though that's basically a sort, I think "sort 2 elements" operation is useful on it's own in many cases. Namely, it's a common pattern when you have 2 things, and need to know which one is smaller/bigger to operate on them differently.
I've wanted such functions countless times, most recently in #109402, so I thought I'd propose them.
----
r? libs-api
Small wins for formatting-related code
This PR does two small wins in fmt code:
- Override `write_char` for `PadAdapter` to use inner buffer's `write_char`
- Override some `write_fmt` implementations to avoid avoid the additional indirection and vtable generated by the default impl.
make `Debug` impl for `ascii::Char` match that of `char`
# Objective
use a more recognisable format for the `Debug` impl on `ascii::Char` than the derived one based off the enum variants. The alogorithm used is the following:
- escape `ascii::Char::{Null, CharacterTabulation, CarraigeReturn, LineFeed, ReverseSolidus, Apostrophe}` to `'\0'`, `'\t'`, `'\r'`, `'\n'`, `'\\'` and `'\''` respectively. these are the same escape codes as `<char as Debug>::fmt` uses.
- if `u8::is_ascii_control` is false, print the character wrapped in single quotes.
- otherwise, print in the format `'\xAB'` where `A` and `B` are the hex nibbles of the byte. (`char` uses unicode escapes and this seems like the corresponding ascii format).
Tracking issue: https://github.com/rust-lang/rust/issues/110998
impl Step for IP addresses
ACP: rust-lang/libs-team#235
Note: since this is insta-stable, it requires an FCP.
Separating out from the bit operations PR since it feels logically disjoint, and so their FCPs can be separate.
Update doc for `alloc::format!` and `core::concat!`
Closes#115551.
Used comments instead of `assert!`s as [`std::fmt`](https://doc.rust-lang.org/std/fmt/index.html#usage) uses comments.
Should all the str-related macros (`format!`, `format_args!`, `concat!`, `stringify!`, `println!`, `writeln!`, etc.) references each others? For instance, [`concat!`](https://doc.rust-lang.org/core/macro.concat.html) mentions that integers are stringified, but don't link to `stringify!`.
`@rustbot` label +A-docs +A-fmt
Specialize count for range iterators
Since `size_hint` is already specialized, it feels apt to specialize `count` as well. Without any specialized version of `ExactSizeIterator::len` or `Step::steps_between`, this feels like a more reliable way of accessing this without having to rely on knowing that `size_hint` is correct.
In my case, this is particularly useful to access the `steps_between` implementation for `char` from the standard library without having to compute it manually.
I didn't think it was worth modifying the `Step` trait to add a version of `steps_between` that used native overflow checks since this is just doing one subtraction in most cases anyway, and so I decided to make the inclusive version use `checked_add` so it didn't have this lopsided overflow-checks-but-only-sometimes logic.
clarify that unsafe code must not rely on our safe traits
This adds a disclaimer to PartialEq, Eq, PartialOrd, Ord, Hash, Deref, DerefMut.
We already have a similar disclaimer in ExactSizeIterator (worded a bit differently):
```
/// Note that this trait is a safe trait and as such does *not* and *cannot*
/// guarantee that the returned length is correct. This means that `unsafe`
/// code **must not** rely on the correctness of [`Iterator::size_hint`]. The
/// unstable and unsafe [`TrustedLen`](super::marker::TrustedLen) trait gives
/// this additional guarantee.
```
If there are any other traits that should carry such a disclaimer, please let me know.
Fixes https://github.com/rust-lang/rust/issues/73682
Make useless_ptr_null_checks smarter about some std functions
This teaches the `useless_ptr_null_checks` lint that some std functions can't ever return null pointers, because they need to point to valid data, get references as input, etc.
This is achieved by introducing an `#[rustc_never_returns_null_ptr]` attribute and adding it to these std functions (gated behind bootstrap `cfg_attr`).
Later on, the attribute could maybe be used to tell LLVM that the returned pointer is never null. I don't expect much impact of that though, as the functions are pretty shallow and usually the input data is already never null.
Follow-up of PR #113657Fixes#114442
Rework `no_coverage` to `coverage(off)`
As discussed at the tail of https://github.com/rust-lang/rust/issues/84605 this replaces the `no_coverage` attribute with a `coverage` attribute that takes sub-parameters (currently `off` and `on`) to control the coverage instrumentation.
Allows future-proofing for things like `coverage(off, reason="Tested live", issue="#12345")` or similar.
Clarify stability guarantee for lifetimes in enum discriminants
Since `std::mem::Discriminant` erases lifetimes, it should be clarified that changing the concrete value of a lifetime parameter does not change the value of an enum discriminant for a given variant. This is useful as it guarantees that it is safe to transmute `Discriminant<Foo<'a>>` to `Discriminant<Foo<'b>>` for any combination of `'a` and `'b`. This also holds for type-generics as long as the type parameters do not change, e.g. `Discriminant<Foo<T, 'a>>` can be transmuted to `Discriminant<Foo<T, 'b>>`.
Side note: Is what I've written actually enough to imply soundness (or rather codify it), or should it specifically be spelled out that it's OK to transmute in the above way?
Lint on invalid usage of `UnsafeCell::raw_get` in reference casting
This PR proposes to take into account `UnsafeCell::raw_get` method call for non-Freeze types for the `invalid_reference_casting` lint.
The goal of this is to catch those kind of invalid reference casting:
```rust
fn as_mut<T>(x: &T) -> &mut T {
unsafe { &mut *std::cell::UnsafeCell::raw_get(x as *const _ as *const _) }
//~^ ERROR casting `&T` to `&mut T` is undefined behavior
}
```
r? `@est31`
Outline panicking code for `RefCell::borrow` and `RefCell::borrow_mut`
This outlines panicking code for `RefCell::borrow` and `RefCell::borrow_mut` to reduce code size.
RangeFull: Remove parens around .. in documentation snippet
I’ve removed unnecessary parentheses in a documentation snippet documenting `RangeFull`. It could’ve lead people to believe the parentheses were necessary.
Also stabilizes saturating_int_assign_impl, gh-92354.
And also make pub fns const where the underlying saturating_*
fns became const in the meantime since the Saturating type was
created.
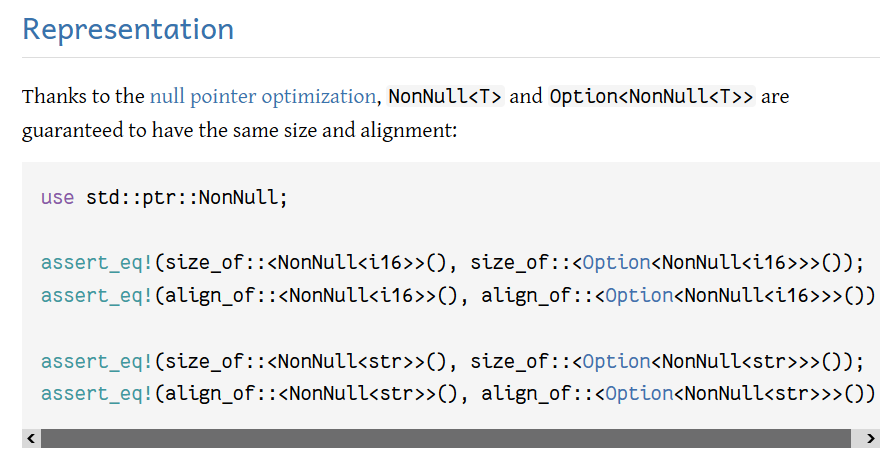
Add alignment to the NPO guarantee
This PR [changes](https://github.com/rust-lang/rust/pull/114845#discussion_r1294363357) "same size" to "same size and alignment" in the option module's null pointer optimization docs in <https://doc.rust-lang.org/std/option/#representation>.
As far as I know, this has been true for a long time in the actual rustc implementation, but it's not in the text of those docs, so I figured I'd bring this up to FCP it.
I also see no particular reason that we'd ever *want* to have higher alignment on these. In many of the cases it's impossible, as the minimum alignment is already the size of the type, but even if we *could* do things like on 32-bit we could say that `NonZeroU64` is 4-align but `Option<NonZeroU64>` is 8-align, I just don't see any value in doing that, so feel completely fine closing this door for the few things on which the NPO is already guaranteed. These are basically all primitives, and should end up with the same size & alignment as those primitives.
(There's no layout guarantee for something like `Option<[u8; 3]>`, where it'd be at least plausible to consider raising the alignment from 1 to 4 on, say, some hypothetical target that doesn't have efficient unaligned 4-byte load/stores. And even if we ever did start to offer some kind of guarantee around such a type, I doubt we'd put it under the "null pointer" optimization header.)
Screenshots for the new examples:

Implement Step for ascii::Char
This allows iterating over ranges of `ascii::Char`, similarly to ranges of `char`.
Note that `ascii::Char` is still unstable, tracked in #110998.