Cleanup and improve `--check-cfg` implementation
This PR removes some indentation in the code, as well as preventing some bugs/misusages and fix a nit in the doc.
r? ```@petrochenkov``` (maybe)
When encountering sealed traits, point types that implement it
```
error[E0277]: the trait bound `S: d::Hidden` is not satisfied
--> $DIR/sealed-trait-local.rs:53:20
|
LL | impl c::Sealed for S {}
| ^ the trait `d::Hidden` is not implemented for `S`
|
note: required by a bound in `c::Sealed`
--> $DIR/sealed-trait-local.rs:17:23
|
LL | pub trait Sealed: self::d::Hidden {
| ^^^^^^^^^^^^^^^ required by this bound in `Sealed`
= note: `Sealed` is a "sealed trait", because to implement it you also need to implement `c::d::Hidden`, which is not accessible; this is usually done to force you to use one of the provided types that already implement it
= help: the following types implement the trait:
- c::X
- c::Y
```
The last `help` is new.
rustdoc: use JS to inline target type impl docs into alias
Preview docs:
- https://notriddle.com/rustdoc-html-demo-5/js-trait-alias/std/io/type.Result.html
- https://notriddle.com/rustdoc-html-demo-5/js-trait-alias-compiler/rustc_middle/ty/type.PolyTraitRef.html
This pull request also includes a bug fix for trait alias inlining across crates. This means more documentation is generated, and is why ripgrep runs slower (it's a thin wrapper on top of the `grep` crate, so 5% of its docs are now the Result type).
- Before, built with rustdoc 1.75.0-nightly (aa1a71e9e 2023-10-26), Result type alias method docs are missing: http://notriddle.com/rustdoc-html-demo-5/ripgrep-js-nightly/rg/type.Result.html
- After, built with this branch, all the methods on Result are shown: http://notriddle.com/rustdoc-html-demo-5/ripgrep-js-trait-alias/rg/type.Result.html
*Review note: This is mostly just reverting https://github.com/rust-lang/rust/pull/115201. The last commit has the new work in it.*
Fixes#115718
This is an attempt to balance three problems, each of which would
be violated by a simpler implementation:
- A type alias should show all the `impl` blocks for the target
type, and vice versa, if they're applicable. If nothing was
done, and rustdoc continues to match them up in HIR, this
would not work.
- Copying the target type's docs into its aliases' HTML pages
directly causes far too much redundant HTML text to be generated
when a crate has large numbers of methods and large numbers
of type aliases.
- Using JavaScript exclusively for type alias impl docs would
be a functional regression, and could make some docs very hard
to find for non-JS readers.
- Making sure that only applicable docs are show in the
resulting page requires a type checkers. Do not reimplement
the type checker in JavaScript.
So, to make it work, rustdoc stashes these type-alias-inlined docs
in a JSONP "database-lite". The file is generated in `write_shared.rs`,
included in a `<script>` tag added in `print_item.rs`, and `main.js`
takes care of patching the additional docs into the DOM.
The format of `trait.impl` and `type.impl` JS files are superficially
similar. Each line, except the JSONP wrapper itself, belongs to a crate,
and they are otherwise separate (rustdoc should be idempotent). The
"meat" of the file is HTML strings, so the frontend code is very simple.
Links are relative to the doc root, though, so the frontend needs to fix
that up, and inlined docs can reuse these files.
However, there are a few differences, caused by the sophisticated
features that type aliases have. Consider this crate graph:
```text
---------------------------------
| crate A: struct Foo<T> |
| type Bar = Foo<i32> |
| impl X for Foo<i8> |
| impl Y for Foo<i32> |
---------------------------------
|
----------------------------------
| crate B: type Baz = A::Foo<i8> |
| type Xyy = A::Foo<i8> |
| impl Z for Xyy |
----------------------------------
```
The type.impl/A/struct.Foo.js JS file has a structure kinda like this:
```js
JSONP({
"A": [["impl Y for Foo<i32>", "Y", "A::Bar"]],
"B": [["impl X for Foo<i8>", "X", "B::Baz", "B::Xyy"], ["impl Z for Xyy", "Z", "B::Baz"]],
});
```
When the type.impl file is loaded, only the current crate's docs are
actually used. The main reason to bundle them together is that there's
enough duplication in them for DEFLATE to remove the redundancy.
The contents of a crate are a list of impl blocks, themselves
represented as lists. The first item in the sublist is the HTML block,
the second item is the name of the trait (which goes in the sidebar),
and all others are the names of type aliases that successfully match.
This way:
- There's no need to generate these files for types that have no aliases
in the current crate. If a dependent crate makes a type alias, it'll
take care of generating its own docs.
- There's no need to reimplement parts of the type checker in
JavaScript. The Rust backend does the checking, and includes its
results in the file.
- Docs defined directly on the type alias are dropped directly in the
HTML by `render_assoc_items`, and are accessible without JavaScript.
The JSONP file will not list impl items that are known to be part
of the main HTML file already.
[JSONP]: https://en.wikipedia.org/wiki/JSONP
Allow partially moved values in match
This PR attempts to unify the behaviour between `let _ = PLACE`, `let _: TY = PLACE;` and `match PLACE { _ => {} }`.
The logical conclusion is that the `match` version should not check for uninitialised places nor check that borrows are still live.
The `match PLACE {}` case is handled by keeping a `FakeRead` in the unreachable fallback case to verify that `PLACE` has a legal value.
Schematically, `match PLACE { arms }` in surface rust becomes in MIR:
```rust
PlaceMention(PLACE)
match PLACE {
// Decision tree for the explicit arms
arms,
// An extra fallback arm
_ => {
FakeRead(ForMatchedPlace, PLACE);
unreachable
}
}
```
`match *borrow { _ => {} }` continues to check that `*borrow` is live, but does not read the value.
`match *borrow {}` both checks that `*borrow` is live, and fake-reads the value.
Continuation of ~https://github.com/rust-lang/rust/pull/102256~ ~https://github.com/rust-lang/rust/pull/104844~
Fixes https://github.com/rust-lang/rust/issues/99180https://github.com/rust-lang/rust/issues/53114
Fix ICE: Restrict param constraint suggestion
When encountering an associated item with a type param that could be constrained, do not look at the parent item if the type param comes from the associated item.
Fix#117209, fix#89868.
Properly restore snapshot when failing to recover parsing ternary
If the recovery parsed an expression, then failed to eat a `:`, it would return `false` without restoring the snapshot. Fix this by always restoring the snapshot when returning `false`.
Draft for now because I'd like to try and improve this recovery further.
Fixes#117208
```
error[E0277]: the trait bound `S: d::Hidden` is not satisfied
--> $DIR/sealed-trait-local.rs:53:20
|
LL | impl c::Sealed for S {}
| ^ the trait `d::Hidden` is not implemented for `S`
|
note: required by a bound in `c::Sealed`
--> $DIR/sealed-trait-local.rs:17:23
|
LL | pub trait Sealed: self::d::Hidden {
| ^^^^^^^^^^^^^^^ required by this bound in `Sealed`
= note: `Sealed` is a "sealed trait", because to implement it you also need to implement `c::d::Hidden`, which is not accessible; this is usually done to force you to use one of the provided types that already implement it
= help: the following types implement the trait:
- c::X
- c::Y
```
The last `help` is new.
Lint overlapping ranges as a separate pass
This reworks the [`overlapping_range_endpoints`](https://doc.rust-lang.org/beta/nightly-rustc/rustc_lint_defs/builtin/static.OVERLAPPING_RANGE_ENDPOINTS.html) lint. My motivations are:
- It was annoying to have this lint entangled with the exhaustiveness algorithm, especially wrt librarification;
- This makes the lint behave consistently.
Here's the consistency story. Take the following matches:
```rust
match (0u8, true) {
(0..=10, true) => {}
(10..20, true) => {}
(10..20, false) => {}
_ => {}
}
match (true, 0u8) {
(true, 0..=10) => {}
(true, 10..20) => {}
(false, 10..20) => {}
_ => {}
}
```
There are two semantically consistent options: option 1 we lint all overlaps between the ranges, option 2 we only lint the overlaps that could actually occur (i.e. the ones with `true`). Option 1 is what this PR does. Option 2 is possible but would require the exhaustiveness algorithm to track more things for the sake of the lint. The status quo is that we're inconsistent between the two.
Option 1 generates more false postives, but I prefer it from a maintainer's perspective. I do think the difference is minimal; cases where the difference is observable seem rare.
This PR adds a separate pass, so this will have a perf impact. Let's see how bad, it looked ok locally.
Rollup of 6 pull requests
Successful merges:
- #114998 (feat(docs): add cargo-pgo to PGO documentation 📝)
- #116868 (Tweak suggestion span for outer attr and point at item following invalid inner attr)
- #117240 (Fix documentation typo in std::iter::Iterator::collect_into)
- #117241 (Stash and cancel cycle errors for auto trait leakage in opaques)
- #117262 (Create a new ConstantKind variant (ZeroSized) for StableMIR)
- #117266 (replace transmute by raw pointer cast)
r? `@ghost`
`@rustbot` modify labels: rollup
Stash and cancel cycle errors for auto trait leakage in opaques
We don't need to emit a traditional cycle error when we have a selection error that explains what's going on but in more detail.
We may want to augment this error to actually point out the cycle, now that the cycle error is not being emitted. We could do that by storing the set of opaques that was in the `CyclePlaceholder` that gets returned from `type_of_opaque`.
r? `@oli-obk` cc `@estebank` #117235
Refactor some `char`, `u8` ASCII functions to be branchless
Extract conditions in singular `matches!` with or-patterns to individual `matches!` statements which enables branchless code output. The following functions were changed:
- `is_ascii_alphanumeric`
- `is_ascii_hexdigit`
- `is_ascii_punctuation`
Added codegen tests
---
Continued from https://github.com/rust-lang/rust/pull/103024.
Based on the comment from `@scottmcm` https://github.com/rust-lang/rust/pull/103024#pullrequestreview-1248697206.
The unmodified `is_ascii_*` functions didn't seem to benefit from extracting the conditions.
I've never written a codegen test before, but I tried to check that no branches were emitted.
Allow target specs to use an LLD flavor, and self-contained linking components
This PR allows:
- target specs to use an LLD linker-flavor: this is needed to switch `x86_64-unknown-linux-gnu` to using LLD, and is currently not possible because the current flavor json serialization fails to roundtrip on the modern linker-flavors. This can e.g. be seen in https://github.com/rust-lang/rust/pull/115622#discussion_r1321312880 which explains where an `Lld::Yes` is ultimately deserialized into an `Lld::No`.
- target specs to declare self-contained linking components: this is needed to switch `x86_64-unknown-linux-gnu` to using `rust-lld`
- adds an end-to-end test of a custom target json simulating `x86_64-unknown-linux-gnu` being switched to using `rust-lld`
- disables codegen backends from participating because they don't support `-Zgcc-ld=lld` which is the basis of mcp510.
r? `@petrochenkov:` if the approach discussed https://github.com/rust-lang/rust/pull/115622#discussion_r1329403467 and on zulip would work for you: basically, see if we can emit only modern linker flavors in the json specs, but accept both old and new flavors while reading them, to fix the roundtrip issue.
The backwards compatible `LinkSelfContainedDefault` variants are still serialized and deserialized in `crt-objects-fallback`, while the spec equivalent of e.g. `-Clink-self-contained=+linker` is serialized into a different json object (with future-proofing to incorporate `crt-objects-fallback` in the future).
---
I've been test-driving this in https://github.com/rust-lang/rust/pull/113382 to test actually switching `x86_64-unknown-linux-gnu` to `rust-lld` (and fix what needs to be fixed in CI, bootstrap, etc), and it seems to work fine.
Decompose singular `matches!` with or-patterns to individual `matches!`
statements to enable branchless code output. The following functions
were changed:
- `is_ascii_alphanumeric`
- `is_ascii_hexdigit`
- `is_ascii_punctuation`
Add codegen tests
Co-authored-by: George Bateman <george.bateman16@gmail.com>
Co-authored-by: scottmcm <scottmcm@users.noreply.github.com>
When expecting closure argument but finding block provide suggestion
Detect if there is a potential typo where the `{` meant to open the closure body was written before the body.
```
error[E0277]: expected a `FnOnce<({integer},)>` closure, found `Option<usize>`
--> $DIR/ruby_style_closure_successful_parse.rs:3:31
|
LL | let p = Some(45).and_then({|x|
| ______________________--------_^
| | |
| | required by a bound introduced by this call
LL | | 1 + 1;
LL | | Some(x * 2)
| | ----------- this tail expression is of type `Option<usize>`
LL | | });
| |_____^ expected an `FnOnce<({integer},)>` closure, found `Option<usize>`
|
= help: the trait `FnOnce<({integer},)>` is not implemented for `Option<usize>`
note: required by a bound in `Option::<T>::and_then`
--> $SRC_DIR/core/src/option.rs:LL:COL
help: you might have meant to open the closure body instead of placing a closure within a block
|
LL - let p = Some(45).and_then({|x|
LL + let p = Some(45).and_then(|x| {
|
```
Detect the potential typo where the closure header is missing.
```
error[E0277]: expected a `FnOnce<(&bool,)>` closure, found `bool`
--> $DIR/block_instead_of_closure_in_arg.rs:3:23
|
LL | Some(true).filter({
| _________________------_^
| | |
| | required by a bound introduced by this call
LL | |/ if number % 2 == 0 {
LL | || number == 0
LL | || } else {
LL | || number != 0
LL | || }
| ||_________- this tail expression is of type `bool`
LL | | });
| |______^ expected an `FnOnce<(&bool,)>` closure, found `bool`
|
= help: the trait `for<'a> FnOnce<(&'a bool,)>` is not implemented for `bool`
note: required by a bound in `Option::<T>::filter`
--> $SRC_DIR/core/src/option.rs:LL:COL
help: you might have meant to create the closure instead of a block
|
LL | Some(true).filter(|_| {
| +++
```
Partially address #27300. Fix#104690.
When encountering an associated item with a type param that could be
constrained, do not look at the parent item if the type param comes from
the associated item.
Fix#117209.
Rollup of 8 pull requests
Successful merges:
- #116905 (refactor(compiler/resolve): simplify some code)
- #117095 (Add way to differentiate argument locals from other locals in Stable MIR)
- #117143 (Avoid unbounded O(n^2) when parsing nested type args)
- #117194 (Minor improvements to `rustc_incremental`)
- #117202 (Revert "Remove TaKO8Ki from reviewers")
- #117207 (The value of `-Cinstrument-coverage=` doesn't need to be `Option`)
- #117214 (Quietly fail if an error has already occurred)
- #117221 (Rename type flag `HAS_TY_GENERATOR` to `HAS_TY_COROUTINE`)
r? `@ghost`
`@rustbot` modify labels: rollup
Add way to differentiate argument locals from other locals in Stable MIR
This PR resolvesrust-lang/project-stable-mir#47 which request a way to differentiate argument locals in a SMIR `Body` from other locals.
Specifically, this PR exposes the `arg_count` field from the MIR `Body`. However, I'm opening this as a draft PR because I think there are a few outstanding questions on how this information should be exposed and described. Namely:
- Is exposing `arg_count` the best way to surface this information to SMIR users? Would it be better to leave `arg_count` as a private field and add public methods (e.g. `fn arguments(&self) -> Iter<'_, LocalDecls>`) that may use the underlying `arg_count` info from the MIR body, but expose this information to users in a more convenient form? Or is it best to stick close to the current MIR convention?
- If the answer to the above point is to stick with the current MIR convention (`arg_count`), is it reasonable to also commit to sticking to the current MIR convention that the first local is always the return local, while the next `arg_count` locals are always the (in-order) argument locals?
- Should `Body` in SMIR only represent function bodies (as implied by the comment I added)? That seems to be the current case in MIR, but should this restriction always be the case for SMIR?
r? `@celinval`
r? `@oli-obk`
Never consider raw pointer casts to be trival
HIR typeck tries to figure out which casts are trivial by doing them as
coercions and seeing whether this works. Since HIR typeck is oblivious
of lifetimes, this doesn't work for pointer casts that only change the
lifetime of the pointee, which are, as borrowck will tell you, not
trivial.
This change makes it so that raw pointer casts are never considered
trivial.
This also incidentally fixes the "trivial cast" lint false positive on
the same code. Unfortunately, "trivial cast" lints are now never emitted
on raw pointer casts, even if they truly are trivial. This could be
fixed by also doing the lint in borrowck for raw pointers specifically.
fixes#113257
Rework negative coherence to properly consider impls that only partly overlap
This PR implements a modified negative coherence that handles impls that only have partial overlap.
It does this by:
1. taking both impl trait refs, instantiating them with infer vars
2. equating both trait refs
3. taking the equated trait ref (which represents the two impls' intersection), and resolving any vars
4. plugging all remaining infer vars with placeholder types
these placeholder-plugged trait refs can then be used normally with the new trait solver, since we no longer have to worry about the issue with infer vars in param-envs.
We use the **new trait solver** to reason correctly about unnormalized trait refs (due to deferred projection equality), since this avoid having to normalize anything under param-envs with infer vars in them.
This PR then additionally:
* removes the `FnPtr` knowable hack by implementing proper negative `FnPtr` trait bounds for rigid types.
---
An example:
Consider these two partially overlapping impls:
```
impl<T, U> PartialEq<&U> for &T where T: PartialEq<U> {}
impl<F> PartialEq<F> for F where F: FnPtr {}
```
Under the old algorithm, we would take one of these impls and replace it with infer vars, then try unifying it with the other impl under identity substitutions. This is not possible in either direction, since it either sets `T = U`, or tries to equate `F = &?0`.
Under the new algorithm, we try to unify `?0: PartialEq<?0>` with `&?1: PartialEq<&?2>`. This gives us `?0 = &?1 = &?2` and thus `?1 = ?2`. The intersection of these two trait refs therefore looks like: `&?1: PartialEq<&?1>`. After plugging this with placeholders, we get a trait ref that looks like `&!0: PartialEq<&!0>`, with the first impl having substs `?T = ?U = !0` and the second having substs `?F = &!0`[^1].
Then we can take the param-env from the first impl, and try to prove the negated where clause of the second.
We know that `&!0: !FnPtr` never holds, since it's a rigid type that is also not a fn ptr, we successfully detect that these impls may never overlap.
[^1]: For the purposes of this example, I just ignored lifetimes, since it doesn't really matter.
Store #[stable] attribute's `since` value in structured form
Followup to https://github.com/rust-lang/rust/pull/116773#pullrequestreview-1680913901.
Prior to this PR, if you wrote an improper `since` version in a `stable` attribute, such as `#[stable(feature = "foo", since = "wat.0")]`, rustc would emit a diagnostic saying **_'since' must be a Rust version number, such as "1.31.0"_** and then throw out the whole `stable` attribute as if it weren't there. This strategy had 2 problems, both fixed in this PR:
1. If there was also a `#[deprecated]` attribute on the same item, rustc would want to enforce that the stabilization version is older than the deprecation version. This involved reparsing the `stable` attribute's `since` version, with a diagnostic **_invalid stability version found_** if it failed to parse. Of course this diagnostic was unreachable because an invalid `since` version would have already caused the `stable` attribute to be thrown out. This PR deletes that unreachable diagnostic.
2. By throwing out the `stable` attribute when `since` is invalid, you'd end up with a second diagnostic saying **_function has missing stability attribute_** even though your function is not missing a stability attribute. This PR preserves the `stable` attribute even when `since` cannot be parsed, avoiding the misleading second diagnostic.
Followups I plan to try next:
- Do the same for the `since` value of `#[deprecated]`.
- See whether it makes sense to also preserve `stable` and/or `unstable` attributes when they contain an invalid `feature`. What redundant/misleading diagnostics can this eliminate? What problems arise from not having a usable feature name for some API, in the situation that we're already failing compilation, so not concerned about anything that happens in downstream code?
Mark .rmeta files as /SAFESEH on x86 Windows.
Chrome links .rlibs with /WHOLEARCHIVE or -Wl,--whole-archive to prevent the linker from discarding static initializers. This works well, except on Windows x86, where lld complains:
error: /safeseh: lib.rmeta is not compatible with SEH
The fix is simply to mark the .rmeta as SAFESEH aware. This is trivially true, since the metadata file does not contain any executable code.
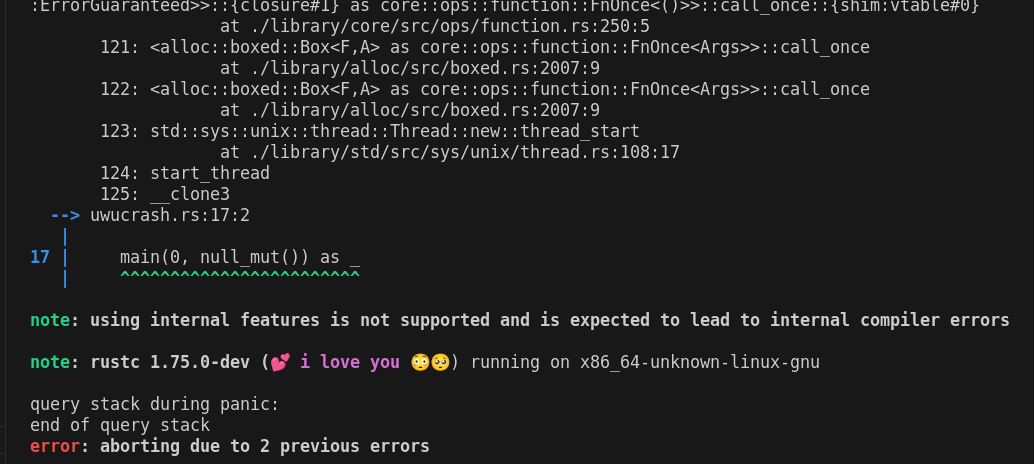
Stop telling people to submit bugs for internal feature ICEs
This keeps track of usage of internal features, and changes the message to instead tell them that using internal features is not supported.
I thought about several ways to do this but now used the explicit threading of an `Arc<AtomicBool>` through `Session`. This is not exactly incremental-safe, but this is fine, as this is set during macro expansion, which is pre-incremental, and also only affects the output of ICEs, at which point incremental correctness doesn't matter much anyways.
See [MCP 620.](https://github.com/rust-lang/compiler-team/issues/596)
The latest locals() method in stable MIR returns slices instead of vecs.
This commit also includes fixes to the existing tests that previously
referenced the private locals field.
Rename AsyncCoroutineKind to CoroutineSource
pulled out of https://github.com/rust-lang/rust/pull/116447
Also refactors the printing infra of `CoroutineSource` to be ready for easily extending it with a `Gen` variant for `gen` blocks