document when atomic loads are guaranteed read-only
Based on this [discussion in Zulip](https://rust-lang.zulipchat.com/#narrow/stream/136281-t-opsem/topic/Can.20.60Atomic*.3A.3Aload.60.20perform.20a.20write).
The values for x86 and x86_64 are complete guesswork on my side, and I have no clue what the values might be for other architectures. I hope we can get the right people to chime in to gather the required information. :)
I'll update Miri to respect these rules once we have more data.
This makes it so that all the matchers that match against paths use the
definition path instead of the export path. This removes all duplication
around `std`/`alloc`/`core`.
This is not necessarily optimal because we now depend on internal
implementation details like `core::ops::control_flow::ControlFlow`,
which is not very nice and probably not acceptable for a stable
`on_unimplemented`.
An alternative would be to just string-replace normalize away
`alloc`/`core` to `std` as a special case, keeping the export paths but
making it so that we're still fully standard library flavor agnostic.
Stabilize `{IpAddr, Ipv6Addr}::to_canonical`
Make `IpAddr::to_canonical` and `IpV6Addr::to_canonical` stable (+const), as well as const stabilize `Ipv6Addr::to_ipv4_mapped`.
Newly stable API:
```rust
impl IpAddr {
// Newly stable under `ip_to_canonical`
const fn to_canonical(&self) -> IpAddr;
}
impl Ipv6Addr {
// Newly stable under `ip_to_canonical`
const fn to_canonical(&self) -> IpAddr;
// Already stable, this makes it const stable under
// `const_ipv6_to_ipv4_mapped`
const fn to_ipv4_mapped(&self) -> Option<Ipv4Addr>
}
```
These stabilize a subset of the following tracking issues:
- https://github.com/rust-lang/rust/issues/27709
- https://github.com/rust-lang/rust/issues/76205
Stabilization of all methods under the `ip` gate was attempted once at https://github.com/rust-lang/rust/pull/66584 then again at https://github.com/rust-lang/rust/pull/76098. These were not successful because there are still unknowns about `is_documentation` `is_benchmarking` and similar; `to_canonical` is much more straightforward.
I have looked and could not find any known issues with `to_canonical`. These were added in 2021 in https://github.com/rust-lang/rust/pull/87708
cc implementor ``@the8472``
r? libs-api
``@rustbot`` label +T-libs-api +needs-fcp
impl Not, Bit{And,Or}{,Assign} for IP addresses
ACP: rust-lang/libs-team#235
Note: since these are insta-stable, these require an FCP.
Implements, where `N` is either `4` or `6`:
```rust
impl Not for IpvNAddr
impl Not for &IpvNAddr
impl BitAnd<IpvNAddr> for IpvNAddr
impl BitAnd<&IpvNAddr> for IpvNAddr
impl BitAnd<IpvNAddr> for &IpvNAddr
impl BitAnd<&IpvNAddr> for &IpvNAddr
impl BitAndAssign<IpvNAddr> for IpvNAddr
impl BitAndAssign<&IpvNAddr> for IpvNAddr
impl BitOr<IpvNAddr> for IpvNAddr
impl BitOr<&IpvNAddr> for IpvNAddr
impl BitOr<IpvNAddr> for &IpvNAddr
impl BitOr<&IpvNAddr> for &IpvNAddr
impl BitOrAssign<IpvNAddr> for IpvNAddr
impl BitOrAssign<&IpvNAddr> for IpvNAddr
```
Implement FusedIterator for DecodeUtf16 when the inner iterator does
I have just implemented an iterator that wraps `DecodeUtf16` and wanted to implement `FusedIterator` for my iterator when I noticed that `DecodeUtf16` currently doesn't implement `FusedIterator` at all.
A quick look at the code of `DecodeUtf16` revealed that `DecodeUtf16::next` only returns `None` when its inner iterator returns `None`:
3462f79e94/library/core/src/char/decode.rs (L45)
As a result, we can implement `FusedIterator` for `DecodeUtf16` when the inner iterator does.
I'm following the example of #96397 here and consider this change minor and non-controversial, which is why I haven't added an RFC. I have also added the required feature name (`"decode_utf16_fused_iterator"`), however without adding a chapter to the Rust Unstable book (same as #96397).
optimize zipping over array iterators
Fixes#115339 (somewhat)
the new assembly:
```asm
zip_arrays:
.cfi_startproc
vmovups (%rdx), %ymm0
leaq 32(%rsi), %rcx
vxorps %xmm1, %xmm1, %xmm1
vmovups %xmm1, -24(%rsp)
movq $0, -8(%rsp)
movq %rsi, -88(%rsp)
movq %rdi, %rax
movq %rcx, -80(%rsp)
vmovups %ymm0, -72(%rsp)
movq $0, -40(%rsp)
movq $32, -32(%rsp)
movq -24(%rsp), %rcx
vmovups (%rsi,%rcx), %ymm0
vorps -72(%rsp,%rcx), %ymm0, %ymm0
vmovups %ymm0, (%rsi,%rcx)
vmovups (%rsi), %ymm0
vmovups %ymm0, (%rdi)
vzeroupper
retq
```
This is still longer than the slice version given in the issue but at least it eliminates the terrible `vpextrb`/`orb` chain. I guess this is due to excessive memcpys again (haven't looked at the llvmir)?
The `TrustedLen` specialization is a drive-by change since I had to do something for the default impl anyway to be able to specialize the `TrustedRandomAccessNoCoerce` impl.
* Remove duplicate alignment note that mentioned `AtomicBool` with other
types
* Update safety requirements about when non-atomic operations are
allowed
Implement `slice::split_once` and `slice::rsplit_once`
Feature gate is `slice_split_once` and tracking issue is #112811. These are equivalents to the existing `str::split_once` and `str::rsplit_once` methods.
Fix generic bound of `str::SplitInclusive`'s `DoubleEndedIterator` impl
`str::SplitInclusive`'s `DoubleEndedIterator` implementation currently uses a `ReverseSearcher` bound for the corresponding searcher. A `DoubleEndedSearcher` bound should have been used instead.
`DoubleEndedIterator` requires that repeated `next_back` calls produce the same items as repeated `next` calls, in opposite order. `ReverseSearcher` lets you search starting from the back of a string, but it makes no guarantees about how its matches correspond to the matches found by a forward search. `DoubleEndedSearcher` is a subtrait of `ReverseSearcher` and does require that the same matches are found in both directions.
This bug fix is a breaking change. Calling `next_back` on `"a+++b".split_inclusive("++")` is currently accepted with repeated calls producing `"b"` and `"a+++"`, while forward iteration yields `"a++"` and `"+b"`. Also see https://github.com/rust-lang/rust/issues/100756#issuecomment-1221307166 for more details.
I believe that this is the only iterator that uses this bound incorrectly — other related iterators such as `str::Split` do have a `DoubleEndedSearcher` bound for their `DoubleEndedIterator` implementation. And `slice::SplitInclusive` doesn't face this problem at all because it doesn't use patterns, only a predicate.
cc `@SkiFire13`
Reuse existing `Some`s in `Option::(x)or`
LLVM still has trouble re-using discriminants sometimes when rebuilding a two-variant enum, so when we have the correct variant already built, just use it.
That's shorter in the Rust code, as well as simpler in MIR and the optimized LLVM, so might as well: <https://rust.godbolt.org/z/KhdE8eToW>
Thanks to `@veber-alex` for pointing out this opportunity in https://github.com/rust-lang/rust/issues/101210#issuecomment-1732470941
Fix a comment in std::iter::successors
The `unfold` function have since #58062 been renamed to `from_fn`.
(I'm not sure if this whole comment is still useful—it's not like there are many iterators that *can't* be based on `from_fn`. Anyway, in its current form this comment is not correct, and it sent me into a half-hour research of what happened to `unfold` function, so I want to do *something* with it 🙃 deleting these three lines is a perfectly fine alternative, in my opinion.)
Clarify example in docs of str::char_slice
Just a one word improvement.
“Last” can be misread as meaning the last (third) instead of the previous (first).
LLVM still has trouble re-using discriminants sometimes when rebuilding a two-variant enum, so when we have the correct variant already built, just use it.
That's simpler in LLVM *and* in MIR, so might as well: <https://rust.godbolt.org/z/KhdE8eToW>
docs: Correct terminology in std::cmp
This PR is the result of some discussions on URLO:
* [Traits in `std::cmp` and mathematical terminology](https://users.rust-lang.org/t/traits-in-std-cmp-and-mathematical-terminology/69887)
* [Are poker hands `Ord` or `PartialOrd`?](https://users.rust-lang.org/t/are-poker-hands-ord-or-partialord/82644)
Arguably, the documentation currently isn't very precise regarding mathematical terminology. This can lead to misunderstandings of what `PartialEq`, `Eq`, `PartialOrd`, and `Ord` actually do.
While I believe this PR doesn't give any new API guarantees, it expliclitly mentions that `PartialEq::eq(a, b)` may return `true` for two distinct values `a` and `b` (i.e. where `a` and `b` are not equal in the mathematical sense). This leads to the consequence that `Ord` may describe a weak ordering instead of a total ordering.
In either case, I believe this PR should be thoroughly reviewed, ideally by someone with mathematical background to make sure the terminology is correct now, and also to ensure that no unwanted new API guarantees are made.
In particular, the following problems are addressed:
* Some clarifications regarding used (mathematical) terminology:
* Avoid using the terms "total equality" and "partial equality" in favor of "equivalence relation" and "partial equivalence relation", which are well-defined and unambiguous.
* Clarify that `Ordering` is an ordering between two values (and not an order in the mathematical sense).
* Avoid saying that `PartialEq` and `Eq` are "equality comparisons" because the terminology "equality comparison" could be misleading: it's possible to implement `PartialEq` and `Eq` for other (partial) equivalence relations, in particular for relations where `a == b` for some `a` and `b` even when `a` and `b` are not the same value.
* Added a section "Strict and non-strict partial orders" to document that the `<=` and `>=` operators do not correspond to non-strict partial orders.
* Corrected section "Corollaries" in documenation of `Ord` in regard to `<` only describing a strict total order in cases where `==` conforms to mathematical equality.
* ~~Added a section "Weak orders" to explain that `Ord` may also describe a weak order or total preorder, depending on how `PartialEq::eq` has been implemented.~~ (Removed, see [comment](https://github.com/rust-lang/rust/pull/103046#issuecomment-1279929676))
* Made documentation easier to understand:
* Explicitly state at the beginning of `PartialEq`'s documentation comment that implementing the trait will provide the `==` and `!=` operators.
* Added an easier to understand rule when to implement `Eq` in addition to `PartialEq`: "if it’s guaranteed that `PartialEq::eq(a, a)` always returns `true`."
* Explicitly mention in documentation of `Eq` that the properties "symmetric" and "transitive" are already required by `PartialEq`.
core library: Disable fpmath tests for i586 ...
This patch disables the floating-point epsilon test for i586 since x87 registers are too imprecise and can't produce the expected results.
Some clarifications regarding used (mathematical) terminology:
* Avoid using the terms "total equality" and "partial equality" in favor
of "equivalence relation" and "partial equivalence relation", which
are well-defined and unambiguous.
* Clarify that `Ordering` is an ordering between two values (and not an
order in the mathematical sense).
* Avoid saying that `PartialEq` and `Eq` are "equality comparisons"
because the terminology "equality comparison" could be misleading:
it's possible to implement `PartialEq` and `Eq` for other (partial)
equivalence relations, in particular for relations where `a == b` for
some `a` and `b` even when `a` and `b` are not the same value.
* Added a section "Strict and non-strict partial orders" to document
that the `<=` and `>=` operators do not correspond to non-strict
partial orders.
* Corrected section "Corollaries" in documenation of Ord in regard to
`<` only describing a strict total order in cases where `==` conforms
to mathematical equality.
Made documentation easier to understand:
* Explicitly state at the beginning of `PartialEq`'s documentation
comment that implementing the trait will provide the `==` and `!=`
operators.
* Added an easier to understand rule when to implement `Eq` in addition
to `PartialEq`: "if it’s guaranteed that `PartialEq::eq(a, a)` always
returns `true`."
* Explicitly mention in documentation of `Eq` that the properties
"symmetric" and "transitive" are already required by `PartialEq`.
Works around #115199 by temporarily disabling CFI for core and std CFI
violations to allow the user rebuild and use both core and std with CFI
enabled using the Cargo build-std feature.
Adapt `todo!` documentation to mention displaying custom values
Resolves#116130.
I copied from the [existing documentation](https://doc.rust-lang.org/std/macro.unimplemented.html) for `unimplemented!` more or less directly, down to the example trait used. I also took the liberty of fixing some formatting and typographical errors that I noticed.
Add `must_use` on pointer equality functions
`ptr == ptr` (like all use of `==`) has a similar warning, and these functions are simple convenience wrappers over that.
Correct misleading std::fmt::Binary example (#116165)
Nothing too crazy...
- Add two to the width specifier (so all 32 bits are correctly displayed)
- Pad out the compared string so the assert passes
- Add `// Note` comment highlighting the need for the extra width when using the `#` flag.
The exact contents (and placement?) of the note are, of course, highly bikesheddable.
Partially outline code inside the panic! macro
This outlines code inside the panic! macro in some cases. This is split out from https://github.com/rust-lang/rust/pull/115562 to exclude changes to rustc.
Add "integer square root" method to integer primitive types
For every suffix `N` among `8`, `16`, `32`, `64`, `128` and `size`, this PR adds the methods
```rust
const fn uN::isqrt() -> uN;
const fn iN::isqrt() -> iN;
const fn iN::checked_isqrt() -> Option<iN>;
```
to compute the [integer square root](https://en.wikipedia.org/wiki/Integer_square_root), addressing issue #89273.
The implementation is based on the [base 2 digit-by-digit algorithm](https://en.wikipedia.org/wiki/Methods_of_computing_square_roots#Binary_numeral_system_(base_2)) on Wikipedia, which after some benchmarking has proved to be faster than both binary search and Heron's/Newton's method. I haven't had the time to understand and port [this code](http://atoms.alife.co.uk/sqrt/SquareRoot.java) based on lookup tables instead, but I'm not sure whether it's worth complicating such a function this much for relatively little benefit.
fix a comment about assert_receiver_is_total_eq
"a type implements #[deriving]" doesn't make any sense, so I assume they meant "implement `Eq`"? Also the attribute is called `derive`.
error: unresolved link to `std::fmt::Error`
--> library/core/src/fmt/mod.rs:115:52
|
115 | /// This function will return an instance of [`std::fmt::Error`] on error.
|
|
= note: `-D rustdoc::broken-intra-doc-links` implied by `-D warnings`
ConstParamTy: require Eq as supertrait
As discussed with `@BoxyUwu` [on Zulip](https://rust-lang.zulipchat.com/#narrow/stream/260443-project-const-generics/topic/.60ConstParamTy.60.20and.20.60Eq.60).
We want to say that valtree equality on const generic params agrees with `==`, but that only makes sense if `==` actually exists, hence we should have an appropriate bound. Valtree equality is an equivalence relation, so such a type can always be `Eq` and not just `PartialEq`.
Clarify example in `Pin::new_unchecked` docs
This example in the docs of `Pin::new_unchecked` puzzled me for a relatively long time. Now I understand that it comes down to the difference between dropping the `Pin` vs dropping the pinned value.
I have extended the explanation to highlight this difference. In my opinion it is clearer now, and I hope it helps others understand `Pin` better.
Document panics on unsigned wrapping_div/rem calls (#116063)
Add missing `# Panics` sections to the `uint_impl!` macro, documenting that the `wrapping_rem/div` calls will panic if passed zero.
Call panic_display directly in const_panic_fmt.
`panic_str` just directly calls `panic_display`. The only reason `panic_str` exists, is for a lint to detect an expansion of `panic_2015!(expr)` (which expands to `panic_str`).
It is `panic_display` that is hooked by const-eval, which is the reason we call it here.
Part of https://github.com/rust-lang/rust/issues/116005
r? ``@oli-obk``
Rename BoxMeUp to PanicPayload.
"BoxMeUp" is not very clear. Let's rename that to a description of what it actually represents: a panic payload.
This PR also renames the structs that implement this trait to have more descriptive names.
Part of https://github.com/rust-lang/rust/issues/116005
r? `@oli-obk`
Make `IpAddr::to_canonical` and `IpV6Addr::to_canonical` stable, as well as
const stabilize `Ipv6Addr::to_ipv4_mapped`.
Newly stable API:
impl IpAddr {
// Now stable under `ip_to_canonical`
const fn to_canonical(&self) -> IpAddr;
}
impl Ipv6Addr {
// Now stable under `ip_to_canonical`
const fn to_canonical(&self) -> IpAddr;
// Already stable, this makes it const stable under
// `const_ipv6_to_ipv4_mapped`
const fn to_ipv4_mapped(&self) -> Option<Ipv4Addr>
}
These stabilize a subset of the following tracking issues:
- https://github.com/rust-lang/rust/issues/27709
- https://github.com/rust-lang/rust/issues/76205
get rid of duplicate primitive_docs
Having this duplicate makes editing that file very annoying. And at least locally the generated docs still look perfectly fine...
Add `minmax{,_by,_by_key}` functions to `core::cmp`
This PR adds the following functions:
```rust
// mod core::cmp
#![unstable(feature = "cmp_minmax")]
pub fn minmax<T>(v1: T, v2: T) -> [T; 2]
where
T: Ord;
pub fn minmax_by<T, F>(v1: T, v2: T, compare: F) -> [T; 2]
where
F: FnOnce(&T, &T) -> Ordering;
pub fn minmax_by_key<T, F, K>(v1: T, v2: T, mut f: F) -> [T; 2]
where
F: FnMut(&T) -> K,
K: Ord;
```
(they are also `const` under `#[feature(const_cmp)]`, I've omitted `const` stuff for simplicity/readability)
----
Semantically these functions are equivalent to `{ let mut arr = [v1, v2]; arr.sort(); arr }`, but since they operate on 2 elements only, they are implemented as a single comparison.
Even though that's basically a sort, I think "sort 2 elements" operation is useful on it's own in many cases. Namely, it's a common pattern when you have 2 things, and need to know which one is smaller/bigger to operate on them differently.
I've wanted such functions countless times, most recently in #109402, so I thought I'd propose them.
----
r? libs-api
Small wins for formatting-related code
This PR does two small wins in fmt code:
- Override `write_char` for `PadAdapter` to use inner buffer's `write_char`
- Override some `write_fmt` implementations to avoid avoid the additional indirection and vtable generated by the default impl.
make `Debug` impl for `ascii::Char` match that of `char`
# Objective
use a more recognisable format for the `Debug` impl on `ascii::Char` than the derived one based off the enum variants. The alogorithm used is the following:
- escape `ascii::Char::{Null, CharacterTabulation, CarraigeReturn, LineFeed, ReverseSolidus, Apostrophe}` to `'\0'`, `'\t'`, `'\r'`, `'\n'`, `'\\'` and `'\''` respectively. these are the same escape codes as `<char as Debug>::fmt` uses.
- if `u8::is_ascii_control` is false, print the character wrapped in single quotes.
- otherwise, print in the format `'\xAB'` where `A` and `B` are the hex nibbles of the byte. (`char` uses unicode escapes and this seems like the corresponding ascii format).
Tracking issue: https://github.com/rust-lang/rust/issues/110998
impl Step for IP addresses
ACP: rust-lang/libs-team#235
Note: since this is insta-stable, it requires an FCP.
Separating out from the bit operations PR since it feels logically disjoint, and so their FCPs can be separate.
Update doc for `alloc::format!` and `core::concat!`
Closes#115551.
Used comments instead of `assert!`s as [`std::fmt`](https://doc.rust-lang.org/std/fmt/index.html#usage) uses comments.
Should all the str-related macros (`format!`, `format_args!`, `concat!`, `stringify!`, `println!`, `writeln!`, etc.) references each others? For instance, [`concat!`](https://doc.rust-lang.org/core/macro.concat.html) mentions that integers are stringified, but don't link to `stringify!`.
`@rustbot` label +A-docs +A-fmt
Specialize count for range iterators
Since `size_hint` is already specialized, it feels apt to specialize `count` as well. Without any specialized version of `ExactSizeIterator::len` or `Step::steps_between`, this feels like a more reliable way of accessing this without having to rely on knowing that `size_hint` is correct.
In my case, this is particularly useful to access the `steps_between` implementation for `char` from the standard library without having to compute it manually.
I didn't think it was worth modifying the `Step` trait to add a version of `steps_between` that used native overflow checks since this is just doing one subtraction in most cases anyway, and so I decided to make the inclusive version use `checked_add` so it didn't have this lopsided overflow-checks-but-only-sometimes logic.
clarify that unsafe code must not rely on our safe traits
This adds a disclaimer to PartialEq, Eq, PartialOrd, Ord, Hash, Deref, DerefMut.
We already have a similar disclaimer in ExactSizeIterator (worded a bit differently):
```
/// Note that this trait is a safe trait and as such does *not* and *cannot*
/// guarantee that the returned length is correct. This means that `unsafe`
/// code **must not** rely on the correctness of [`Iterator::size_hint`]. The
/// unstable and unsafe [`TrustedLen`](super::marker::TrustedLen) trait gives
/// this additional guarantee.
```
If there are any other traits that should carry such a disclaimer, please let me know.
Fixes https://github.com/rust-lang/rust/issues/73682
Make useless_ptr_null_checks smarter about some std functions
This teaches the `useless_ptr_null_checks` lint that some std functions can't ever return null pointers, because they need to point to valid data, get references as input, etc.
This is achieved by introducing an `#[rustc_never_returns_null_ptr]` attribute and adding it to these std functions (gated behind bootstrap `cfg_attr`).
Later on, the attribute could maybe be used to tell LLVM that the returned pointer is never null. I don't expect much impact of that though, as the functions are pretty shallow and usually the input data is already never null.
Follow-up of PR #113657Fixes#114442
Rework `no_coverage` to `coverage(off)`
As discussed at the tail of https://github.com/rust-lang/rust/issues/84605 this replaces the `no_coverage` attribute with a `coverage` attribute that takes sub-parameters (currently `off` and `on`) to control the coverage instrumentation.
Allows future-proofing for things like `coverage(off, reason="Tested live", issue="#12345")` or similar.
Clarify stability guarantee for lifetimes in enum discriminants
Since `std::mem::Discriminant` erases lifetimes, it should be clarified that changing the concrete value of a lifetime parameter does not change the value of an enum discriminant for a given variant. This is useful as it guarantees that it is safe to transmute `Discriminant<Foo<'a>>` to `Discriminant<Foo<'b>>` for any combination of `'a` and `'b`. This also holds for type-generics as long as the type parameters do not change, e.g. `Discriminant<Foo<T, 'a>>` can be transmuted to `Discriminant<Foo<T, 'b>>`.
Side note: Is what I've written actually enough to imply soundness (or rather codify it), or should it specifically be spelled out that it's OK to transmute in the above way?
Lint on invalid usage of `UnsafeCell::raw_get` in reference casting
This PR proposes to take into account `UnsafeCell::raw_get` method call for non-Freeze types for the `invalid_reference_casting` lint.
The goal of this is to catch those kind of invalid reference casting:
```rust
fn as_mut<T>(x: &T) -> &mut T {
unsafe { &mut *std::cell::UnsafeCell::raw_get(x as *const _ as *const _) }
//~^ ERROR casting `&T` to `&mut T` is undefined behavior
}
```
r? `@est31`
Outline panicking code for `RefCell::borrow` and `RefCell::borrow_mut`
This outlines panicking code for `RefCell::borrow` and `RefCell::borrow_mut` to reduce code size.
RangeFull: Remove parens around .. in documentation snippet
I’ve removed unnecessary parentheses in a documentation snippet documenting `RangeFull`. It could’ve lead people to believe the parentheses were necessary.
Also stabilizes saturating_int_assign_impl, gh-92354.
And also make pub fns const where the underlying saturating_*
fns became const in the meantime since the Saturating type was
created.
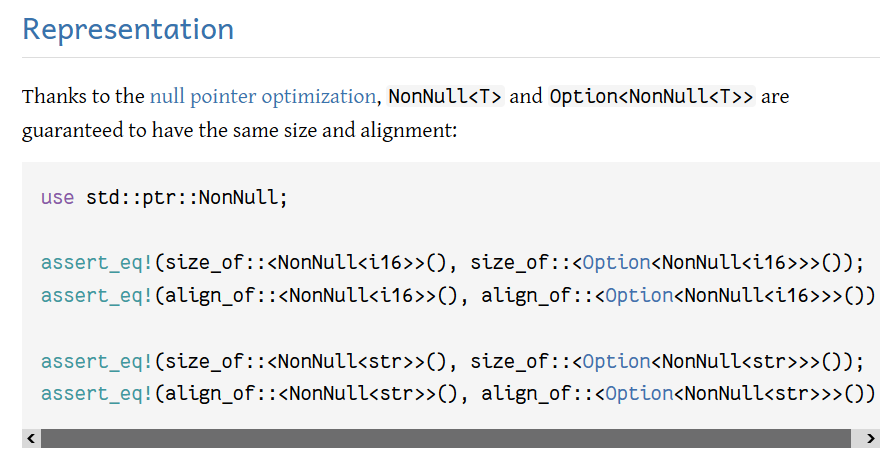
Add alignment to the NPO guarantee
This PR [changes](https://github.com/rust-lang/rust/pull/114845#discussion_r1294363357) "same size" to "same size and alignment" in the option module's null pointer optimization docs in <https://doc.rust-lang.org/std/option/#representation>.
As far as I know, this has been true for a long time in the actual rustc implementation, but it's not in the text of those docs, so I figured I'd bring this up to FCP it.
I also see no particular reason that we'd ever *want* to have higher alignment on these. In many of the cases it's impossible, as the minimum alignment is already the size of the type, but even if we *could* do things like on 32-bit we could say that `NonZeroU64` is 4-align but `Option<NonZeroU64>` is 8-align, I just don't see any value in doing that, so feel completely fine closing this door for the few things on which the NPO is already guaranteed. These are basically all primitives, and should end up with the same size & alignment as those primitives.
(There's no layout guarantee for something like `Option<[u8; 3]>`, where it'd be at least plausible to consider raising the alignment from 1 to 4 on, say, some hypothetical target that doesn't have efficient unaligned 4-byte load/stores. And even if we ever did start to offer some kind of guarantee around such a type, I doubt we'd put it under the "null pointer" optimization header.)
Screenshots for the new examples:

Implement Step for ascii::Char
This allows iterating over ranges of `ascii::Char`, similarly to ranges of `char`.
Note that `ascii::Char` is still unstable, tracked in #110998.
Currently, `CStr::from_ptr` contains its own implementation of `strlen`
that uses `const_eval_select` to either call libc's `strlen` or use a
naive Rust implementation. Refactor that into its own function so we can
use it elsewhere in the module.
Fix implementation of `Duration::checked_div`
I ran across this while running some sanity checks on `time`. Quickcheck immediately found a bug, and as I'd modified the code from `std` I knew there was a bug here as well.
tl;dr this code fails ([playground](https://play.rust-lang.org/?version=stable&mode=debug&edition=2021&gist=1189a3efcdfc192c27d6d87815359353))
```rust
use std::time::Duration;
fn main() {
assert_eq!(
Duration::new(1, 1).checked_div(7),
Some(Duration::new(0, 142_857_143)),
);
}
```
The existing code determines that 1/7 = 0 (seconds), 1/7 = 0 (nanoseconds), 1 billion / 7 = 142,857,142 (extra nanoseconds). The billion comes from multiplying the remainder of the seconds (1) by the number of nanoseconds in a second. However, **this wrongly ignores any remaining nanoseconds**. This PR takes that into consideration, adds a test, and also changes the roundabout way of calculating the remainder into directly computing it.
Note: This is _not_ a rounding error. This result divides evenly.
`@rustbot` label +A-time +C-bug +S-waiting-on-reviewer +T-libs
Go into more detail about panicking in drop.
This patch was sitting around in my drafts. I don't recall the motivation, but I think it was someone expressing confusion over “will likely abort” (since, in fact, a panicking drop _not_ caused by dropping while panicking will predictably _not_ abort).
I hope that the new text will leave people well-informed about why not to panic and when it is reasonable to panic.
Make `rustc_on_unimplemented` std-agnostic for `alloc::rc`
See https://github.com/rust-lang/rust/issues/112923
Just a few lines related to `alloc:rc` for `Send` and `Sync`.
That seems to be all of the `... = "std::..."` issues found, but there a few notes with `std::` inside them still.
r? `@WaffleLapkin`
Add `suggestion` for some `#[deprecated]` items
Consider code:
```rust
fn main() {
let _ = ["a", "b"].connect(" ");
}
```
Currently it shows deprecated warning:
```rust
warning: use of deprecated method `std::slice::<impl [T]>::connect`: renamed to join
--> src/main.rs:2:24
|
2 | let _ = ["a", "b"].connect(" ");
| ^^^^^^^
|
= note: `#[warn(deprecated)]` on by default
```
This PR adds `suggestion` for `connect` and some other deprecated items, so the warning will be changed to this:
```rust
warning: use of deprecated method `std::slice::<impl [T]>::connect`: renamed to join
--> src/main.rs:2:24
|
2 | let _ = ["a", "b"].connect(" ");
| ^^^^^^^
|
= note: `#[warn(deprecated)]` on by default
help: replace the use of the deprecated method
|
2 | let _ = ["a", "b"].join(" ");
| ^^^^
```
custom_mir: change Call() terminator syntax to something more readable
I find our current syntax very hard to read -- I cannot even remember the order of arguments, and having the "next block" *before* the actual function call is very counter-intuitive IMO. So I suggest we use `Call(ret_val = function(v), next_block)` instead.
r? `@JakobDegen`
rustdoc: Add lint `redundant_explicit_links`
Closes#87799.
- Lint warns by default
- Reworks link parser to cache original link's display text
r? `@jyn514`
Inline strlen_rt in CStr::from_ptr
This enables LLVM to optimize this function as if it was strlen (LLVM knows what it does, and can avoid calling it in certain situations) without having to enable std-aware LTO. This is essentially doing what https://github.com/rust-lang/rust/pull/90007 did, except updated for this function being `const`.
Pretty sure it's safe to roll-up, considering last time I did make this change it didn't affect performance (`CStr::from_ptr` isn't really used all that often in Rust code that is checked by rust-perf).
When I was learning Rust I looked for “a modulo function” and couldn’t
find one, so thought I had to write my own; it wasn't at all obvious
that a function with “rem” in the name was the function I wanted.
Hopefully this will save the next learner from that.
However, it does have the disadvantage that the top results in rustdoc
for “mod” are now these aliases instead of the Rust keyword, which
probably isn't ideal.