Use small code model for UEFI targets
* Since the code model only applies to the code and not the data and the code model
only applies to functions you call through using `call`, `jmp` and data with `lea`, etc…
If you are calling functions using the function pointers from the UEFI structures the code
model does not apply in that case. It’s just related to the address space size of your own binary.
Since UEFI (uefi is all relocatable) uses relocatable PEs (relocatable code does not care about the
code model) so, we use the small code model here.
* Since applications don't usually take gigabytes of memory, setting the
target to use the small code model should result in better codegen (comparable
with majority of other targets).
Large code models are also known for generating horrible code, for
example 16 bytes of code to load a single 8-byte value.
Signed-off-by: Andy-Python-Programmer <andypythonappdeveloper@gmail.com>
Do not allow JSON targets to set is-builtin: true
Note that this will affect (and make builds fail for) all of the projects out there that have target files invalid in this way. Crater, however, does not really cover these kinds of the codebases, so it is quite difficult to measure the impact. That said, the target files invalid in this way can start causing build failures each time LLVM is upgraded, anyway, so it is probably a good opportunity to disallow this property, entirely.
Another approach considered was to simply not parse this field anymore, which would avoid making the builds explicitly fail, but it wasn't clear to me if `is-builtin` was always set unintentionally… In case this was the case, I'd expect people to file a feature request stating specifically for what purpose they were using `is-builtin`.
Fixes#86017
Implementation is based off fast-float-rust, with a few notable changes.
- Some unsafe methods have been removed.
- Safe methods with inherently unsafe functionality have been removed.
- All unsafe functionality is documented and provably safe.
- Extensive documentation has been added for simpler maintenance.
- Inline annotations on internal routines has been removed.
- Fixed Python errors in src/etc/test-float-parse/runtests.py.
- Updated test-float-parse to be a library, to avoid missing rand dependency.
- Added regression tests for #31109 and #31407 in core tests.
- Added regression tests for #31109 and #31407 in ui tests.
- Use the existing slice primitive to simplify shared dec2flt methods
- Remove Miri ignores from dec2flt, due to faster parsing times.
- resolves#85198
- resolves#85214
- resolves#85234
- fixes#31407
- fixes#31109
- fixes#53015
- resolves#68396
- closes https://github.com/aldanor/fast-float-rust/issues/15
* Since the code model only applies to the code and not the data and the code model
only applies to functions you call through using `call`, `jmp` and data with `lea`, etc…
If you are calling functions using the function pointers from the UEFI structures the code
model does not apply in that case. It’s just related to the address space size of your own binary.
Since UEFI (uefi is all relocatable) uses relocatable PEs (relocatable code does not care about the
code model) so, we use the small code model here.
* Since applications don't usually take gigabytes of memory, setting the
target to use the small code model should result in better codegen (comparable
with majority of other targets).
Large code models are also known for generating horrible code, for
example 16 bytes of code to load a single 8-byte value.
* Use the LLVM default code model for the architecture for the
x86_64-unknown-uefi targets. For reference small is the default
code model on x86 in LLVM: <7de2173c2a/llvm/lib/Target/X86/X86TargetMachine.cpp (L204)>
* Remove the comments too as they are not UEFI-specific and applies
to pretty much any target. I added them before as I was explicitily
setting the code model to small.
Signed-off-by: Andy-Python-Programmer <andypythonappdeveloper@gmail.com>
Add initial implementation of HIR-based WF checking for diagnostics
During well-formed checking, we walk through all types 'nested' in
generic arguments. For example, WF-checking `Option<MyStruct<u8>>`
will cause us to check `MyStruct<u8>` and `u8`. However, this is done
on a `rustc_middle::ty::Ty`, which has no span information. As a result,
any errors that occur will have a very general span (e.g. the
definintion of an associated item).
This becomes a problem when macros are involved. In general, an
associated type like `type MyType = Option<MyStruct<u8>>;` may
have completely different spans for each nested type in the HIR. Using
the span of the entire associated item might end up pointing to a macro
invocation, even though a user-provided span is available in one of the
nested types.
This PR adds a framework for HIR-based well formed checking. This check
is only run during error reporting, and is used to obtain a more precise
span for an existing error. This is accomplished by individually
checking each 'nested' type in the HIR for the type, allowing us to
find the most-specific type (and span) that produces a given error.
The majority of the changes are to the error-reporting code. However,
some of the general trait code is modified to pass through more
information.
Since this has no soundness implications, I've implemented a minimal
version to begin with, which can be extended over time. In particular,
this only works for HIR items with a corresponding `DefId` (e.g. it will
not work for WF-checking performed within function bodies).
During well-formed checking, we walk through all types 'nested' in
generic arguments. For example, WF-checking `Option<MyStruct<u8>>`
will cause us to check `MyStruct<u8>` and `u8`. However, this is done
on a `rustc_middle::ty::Ty`, which has no span information. As a result,
any errors that occur will have a very general span (e.g. the
definintion of an associated item).
This becomes a problem when macros are involved. In general, an
associated type like `type MyType = Option<MyStruct<u8>>;` may
have completely different spans for each nested type in the HIR. Using
the span of the entire associated item might end up pointing to a macro
invocation, even though a user-provided span is available in one of the
nested types.
This PR adds a framework for HIR-based well formed checking. This check
is only run during error reporting, and is used to obtain a more precise
span for an existing error. This is accomplished by individually
checking each 'nested' type in the HIR for the type, allowing us to
find the most-specific type (and span) that produces a given error.
The majority of the changes are to the error-reporting code. However,
some of the general trait code is modified to pass through more
information.
Since this has no soundness implications, I've implemented a minimal
version to begin with, which can be extended over time. In particular,
this only works for HIR items with a corresponding `DefId` (e.g. it will
not work for WF-checking performed within function bodies).
Rollup of 7 pull requests
Successful merges:
- #87107 (Loop over all opaque types instead of looking at just the first one with the same DefId)
- #87158 (Suggest full enum variant for local modules)
- #87174 (Stabilize `[T; N]::map()`)
- #87179 (Mark `const_trait_impl` as active)
- #87180 (feat(rustdoc): open sidebar menu when links inside it are focused)
- #87188 (Add GUI test for auto-hide-trait-implementations setting)
- #87200 (TAIT: Infer all inference variables in opaque type substitutions via InferCx)
Failed merges:
r? `@ghost`
`@rustbot` modify labels: rollup
Due to #20400 the corresponding TrustedLen impls need a helper trait
instead of directly adding `Item = &[T;N]` bounds.
Since TrustedLen is a public trait this in turn means
the helper trait needs to be public. Since it's just a workaround
for a compiler deficit it's marked hidden, unstable and unsafe.
TAIT: Infer all inference variables in opaque type substitutions via InferCx
The previous algorithm was correct for the example given in its
documentation, but when the TAIT was declared as a free item
instead of an associated item, the generic parameters were the
wrong ones.
cc `@spastorino`
r? `@nikomatsakis`
Loop over all opaque types instead of looking at just the first one with the same DefId
This exposed a bug in VecMap and is needed for https://github.com/rust-lang/rust/pull/86410 anyway
r? ``@spastorino``
cc ``@nikomatsakis``
The previous algorithm was correct for the example given in its
documentation, but when the TAIT was declared as a free item
instead of an associated item, the generic parameters were the
wrong ones.
Remove refs from Pat slices
Changes `PatKind::Or(&'hir [&'hir Pat<'hir>])` to `PatKind::Or(&'hir [Pat<'hir>])` and others. This is more consistent with `ExprKind`, saves a little memory, and is a little easier to use.
Remove refs from Pat slices
Changes `PatKind::Or(&'hir [&'hir Pat<'hir>])` to `PatKind::Or(&'hir [Pat<'hir>])` and others. This is more consistent with `ExprKind`, saves a little memory, and is a little easier to use.
Rollup of 7 pull requests
Successful merges:
- #86983 (Add or improve natvis definitions for common standard library types)
- #87069 (ExprUseVisitor: Treat ByValue use of Copy types as ImmBorrow)
- #87138 (Correct invariant documentation for `steps_between`)
- #87145 (Make --cap-lints and related options leave crate hash alone)
- #87161 (RFC2229: Use the correct place type)
- #87162 (Fix type decl layout "overflow")
- #87167 (Fix sidebar display on small devices)
Failed merges:
r? `@ghost`
`@rustbot` modify labels: rollup
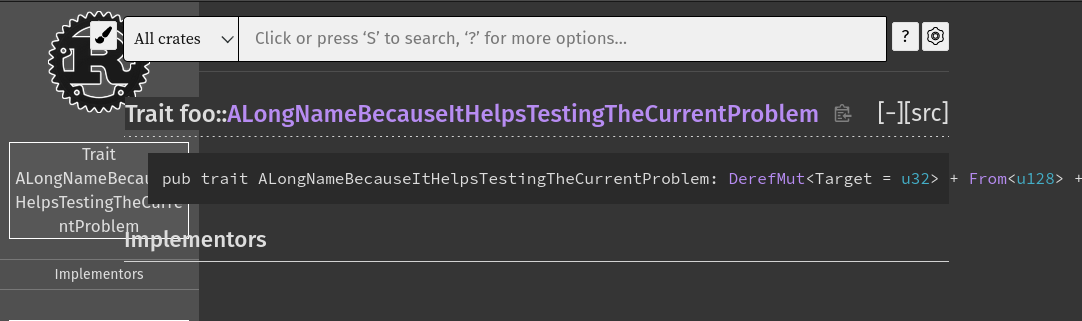
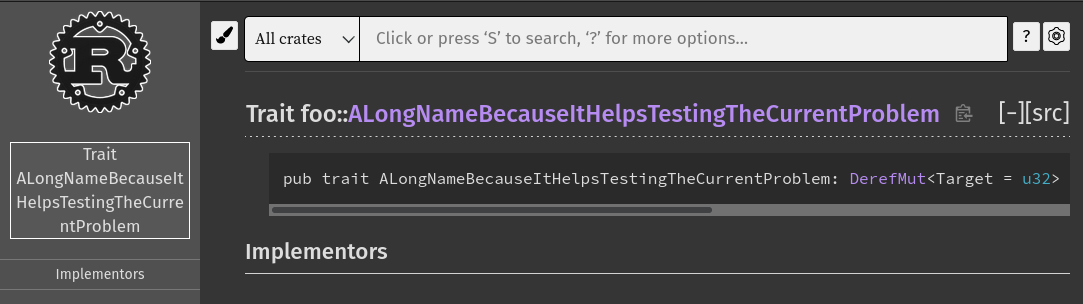
Fix sidebar display on small devices
Part of #87059.
Instead of hiding the sidebar on small devices, we instead move it out of the viewport so that it remains "visible" to our text only users.
Could you confirm it works for you `@ahicks92` and `@DataTriny` please? You can give it a try at [this URL](https://guillaume-gomez.fr/rustdoc-test/test_docs/index.html).
r? `@notriddle`
RFC2229: Use the correct place type
Closes https://github.com/rust-lang/rust/issues/87097
The ICE occurred because instead of looking at the type of the place after all the projections are applied, we instead looked at the `base_ty` of the Place to decide whether a discriminant should be read of not. This lead to two issues:
1. the kind of the type is not necessarily `Adt` since we only look at the `base_ty`, it could be instead `Ref` for example
2. if the kind of the type is `Adt` you could still be looking at the wrong variant to make a decision on whether the discriminant should be read or not
r? `@nikomatsakis`
Correct invariant documentation for `steps_between`
Given that the previous example involves stepping forward from A to B, the equivalent example on this line would make most sense as stepping backward from B to A.
I should probably add a caveat here that I’m fairly new to Rust, and this is my first contribution to this repo, so it’s very possible that I’ve misunderstood how this is supposed to work (either on a technical level or a social one). If this is the case, please do let me know.
fix dead link for method in trait of blanket impl from third party crate
fix#86620
* changes `href` method to raise the actual error it had instead of an `Option`
* set the href link correctly in case of an error
I did not manage to make a small reproducer, I think it happens in a situation where
* crate A expose a trait with a blanket impl
* crate B use the trait from crate A
* crate C use types from crate B
* building docs for crate C without dependencies
r? `@jyn514`
{kind=link}
{kind=link}