FragmentKind played two roles:
* entry point to the parser
* syntactic category of a macro call
These are different use-cases, and warrant different types. For example,
macro can't expand to visibility, but we have such fragment today.
This PR introduces `ExpandsTo` enum to separate this two use-cases.
I suspect we might further split `FragmentKind` into `$x:specifier` enum
specific to MBE, and a general parser entry point, but that's for
another PR!
9970: feat: Implement attribute input token mapping, fix attribute item token mapping r=Veykril a=Veykril
The token mapping for items with attributes got overwritten partially by the attributes non-item input, since attributes have two different inputs, the item and the direct input both.
This PR gives attributes a second TokenMap for its direct input. We now shift all normal input IDs by the item input maximum(we maybe wanna swap this see below) similar to what we do for macro-rules/def. For mapping down we then have to figure out whether we are inside the direct attribute input or its item input to pick the appropriate mapping which can be done with some token range comparisons.
Fixes https://github.com/rust-analyzer/rust-analyzer/issues/9867
Co-authored-by: Lukas Wirth <lukastw97@gmail.com>
We generally avoid "syntax only" helper wrappers, which don't do much:
they make code easier to write, but harder to read. They also make
investigations harder, as "find_usages" needs to be invoked both for the
wrapped and unwrapped APIs
9260: tree-wide: make rustdoc links spiky so they are clickable r=matklad a=lf-
Rustdoc was complaining about these while I was running with --document-private-items and I figure they should be fixed.
Co-authored-by: Jade <software@lfcode.ca>
8560: Escape characters in doc comments in macros correctly r=jonas-schievink a=ChayimFriedman2
Previously they were escaped twice, both by `.escape_default()` and the debug view of strings (`{:?}`). This leads to things like newlines or tabs in documentation comments being `\\n`, but we unescape literals only once, ending up with `\n`.
This was hard to spot because CMark unescaped them (at least for `'` and `"`), but it did not do so in code blocks.
This also was the root cause of #7781. This issue was solved by using `.escape_debug()` instead of `.escape_default()`, but the real issue remained.
We can bring the `.escape_default()` back by now, however I didn't do it because it is probably slower than `.escape_debug()` (more work to do), and also in order to change the code the least.
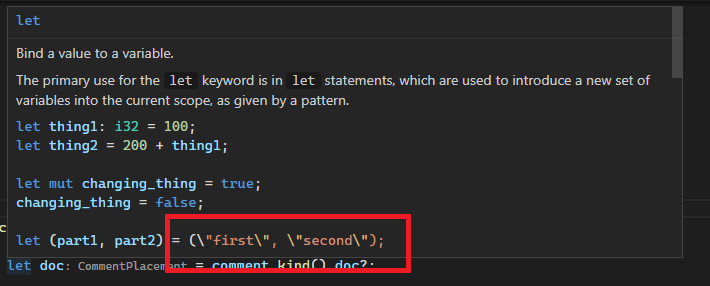
Example (the keyword and primitive docs are `include!()`d at https://doc.rust-lang.org/src/std/lib.rs.html#570-578, and thus originate from macro):
Before:
After:
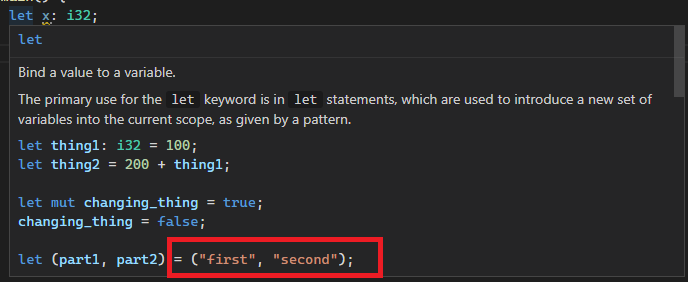
Co-authored-by: Chayim Refael Friedman <chayimfr@gmail.com>
Previously they were escaped twice, both by `.escape_default()` and the debug view of strings (`{:?}`). This leads to things like newlines or tabs in documentation comments being `\\n`, but we unescape literals only once, ending up with `\n`.
This was hard to spot because CMark unescaped them (at least for `'` and `"`), but it did not do so in code blocks.
This also was the root cause of #7781. This issue was solved by using `.escape_debug()` instead of `.escape_default()`, but the real issue remained.
We can bring the `.escape_default()` back by now, however I didn't do it because it is probably slower than `.escape_debug()` (more work to do), and also in order to change the code the least.
use vec![] instead of Vec::new() + push()
avoid redundant clones
use chars instead of &str for single char patterns in ends_with() and starts_with()
allocate some Vecs with capacity to avoid unneccessary resizing
{kind=link}
{kind=link}
{kind=link}