Structs and enums can both be non-exhaustive, with a very different
meaning. This PR splits `is_non_exhaustive` to 2 separate functions - 1
for structs, and another for enums, and fixes the places that got the
usage confused.
Fixes#53549.
Fix#50865: ICE on impl-trait returning functions reaching private items
Adds a test case as suggested in #50865, and implements @petrochenkov's suggestion. Fixes#50865.
Impl-trait-returning functions are marked under a new (low) access level, which they propagate rather than `AccessLevels::Reachable`. `AccessLevels::is_reachable` returns false for such items (leaving stability analysis unaffected), these items may still be visible to the lints phase however.
add modifier keyword spans to hir::Visibility; improve unreachable-pub, private-no-mangle lint suggestions
#50455 pointed out that the unreachable-pub suggestion for brace-grouped `use`s was bogus; #50476 partially ameliorated this by marking the suggestion as `Applicability::MaybeIncorrect`, but this is the actual fix.
Meanwhile, another application of having spans available in `hir::Visibility` is found in the private-no-mangle lints, where we can now issue a suggestion to use `pub` if the item has a more restricted visibility marker (this seems much less likely to come up in practice than not having any visibility keyword at all, but thoroughness is a virtue). While we're there, we can also add a helpful note if the item does have a `pub` (but triggered the lint presumably because enclosing modules were private).
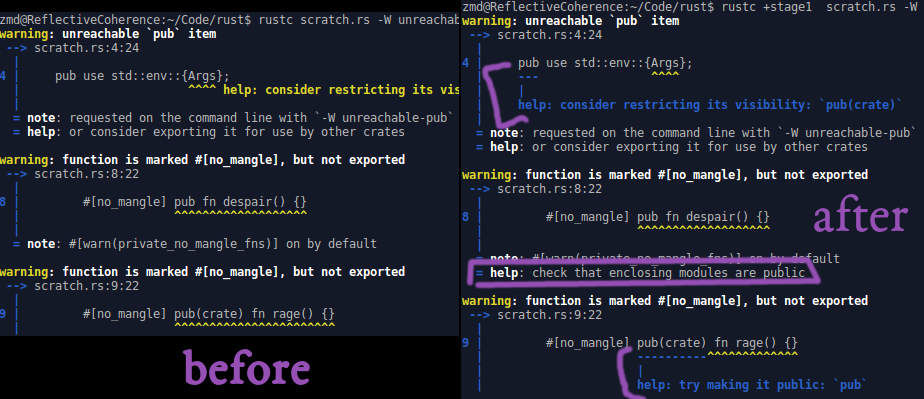
r? @nrc
cc @Manishearth
It was pointed out in review that the glob-exported
underscore-suffixed convention for `Spanned` HIR nodes is no longer
preferred: see February 2016's #31487 for AST's migration away from
this style towards properly namespaced NodeKind enums.
This concerns #51968.
Always check type_dependent_defs
Directly indexing into `type_dependent_defs` has caused multiple ICEs in the past (https://github.com/rust-lang/rust/issues/46771, https://github.com/rust-lang/rust/issues/49241, etc.) and is almost certainly responsible for #51798 too. This PR ensures we always check `type_dependent_defs` first, which should prevent any more of these (or at least make them easier to track down).
April 2016's Issue #33174 called out the E0446 diagnostics as
confusing. While adding the name of the restricted type to the message
(548e681f) clarified matters somewhat, Esteban Küber pointed out that we
could stand to place a secondary span on the restricted type.
Here, we differentiate between crate-visible, truly private, and
otherwise restricted types, and place a secondary span specifically on
the visibility modifier of the restricted type's declaration (which we
can do now that HIR visibilities have spans!).
At long last, this resolves#33174.
There are at least a couple (and plausibly even three) diagnostics that
could use the spans of visibility modifiers in order to be reliably
correct (rather than hacking and munging surrounding spans to try to
infer where the visibility keyword must have been).
We follow the naming convention established by the other `Spanned` HIR
nodes: the "outer" type alias gets the "prime" node-type name, the
"inner" enum gets the name suffixed with an underscore, and the variant
names are prefixed with the prime name and `pub use` exported from here
(from HIR).
Thanks to veteran reviewer Vadim Petrochenkov for suggesting this
uniform approach. (A previous draft, based on the reasoning that
`Visibility::Inherited` should not have a span, tried to hack in a named
`span` field on `Visibility::Restricted` and a positional field on
`Public` and `Crate`. This was ... not so uniform.)
Add existential type definitions
Note: this does not allow creating named existential types, it just desugars `impl Trait` to a less (but still very) hacky version of actual `existential type` items.
r? @nikomatsakis
This leads to a lot of simplifications, as most code doesn't actually need to know about the specific lifetime/type data; rather, it's concerned with properties like name, index and def_id.
A high impact bug because a lot of common traits use a `Self`
substitution by default. Should be backported to beta.
There was a check for this which wasn't catching all cases, it was made
more robust.
Fixes#49376Fixes#50626
r? @petrochenkov
No longer parse it.
Remove AutoTrait variant from AST and HIR.
Remove backwards compatibility lint.
Remove coherence checks, they make no sense for the new syntax.
Remove from rustdoc.
The Generics now contain one Vec of an enum for the generic parameters,
rather than two separate Vec's for lifetime and type parameters.
Additionally, places that previously used Vec<LifetimeDef> now use
Vec<GenericParam> instead.
Replace hir::TyImplTrait with TyImplTraitUniversal and
TyImplTraitExistential.
Add an ImplTraitContext enum to rustc::hir::lowering to track the kind
and allowedness of an impl Trait.
Significantly alter lowering to thread ImplTraitContext and one other
boolean parameter described below throughought much of lowering.
The other parameter is for tracking if lowering a function is in a trait
impl, as there is not enough information to otherwise know this
information during lowering otherwise.
This change also removes the checks from ast_ty_to_ty for impl trait
allowedness as they are now all taking place in HIR lowering.
RFC 2008: Future-proofing enums/structs with #[non_exhaustive] attribute
This work-in-progress pull request contains my changes to implement [RFC 2008](https://github.com/rust-lang/rfcs/pull/2008). The related tracking issue is #44109.
As of writing, enum-related functionality is not included and there are some issues related to tuple/unit structs. Enum related tests are currently ignored.
WIP PR requested by @nikomatsakis [in Gitter](https://gitter.im/rust-impl-period/WG-compiler-middle?at=59e90e6297cedeb0482ade3e).
DefaultImpl is a highly confusing name for what we now call auto impls,
as in `impl Send for ..`. The name auto impl is not formally decided
but for sanity anything is better than `DefaultImpl` which refers
neither to `default impl` nor to `impl Default`.
This'll allow us to reconstruct query parameters purely from the `DepNode`
they're associated with. Some queries could move straight to `HirId` but others
that don't always have a correspondance between `HirId` and `DefId` moved to
two-level maps where the query operates over a `DefIndex`, returning a map,
which is then keyed off `ItemLocalId`.
Closes#44414
The main use of `CrateStore` *before* the `TyCtxt` is created is during
resolution, but we want to be sure that any methods used before resolution are
not used after the `TyCtxt` is created. This commit starts moving the methods
used by resolve to all be named `{name}_untracked` where the rest of the
compiler uses just `{name}` as a query.
During this transition a number of new queries were added to account for
post-resolve usage of these methods.
This map, like `trait_map`, is calculated in resolve, but we want to be sure to
track it for incremental compliation. Hide it behind a query to get more
refactorings later.
Use hir::ItemLocalId as keys in TypeckTables.
This PR makes `TypeckTables` use `ItemLocalId` instead of `NodeId` as key. This is needed for incremental compilation -- for stable hashing and for being able to persist and reload these tables. The PR implements the most important part of https://github.com/rust-lang/rust/issues/40303.
Some notes on the implementation:
* The PR adds the `HirId` to HIR nodes where needed (`Expr`, `Local`, `Block`, `Pat`) which obviates the need to store a `NodeId -> HirId` mapping in crate metadata. Thanks @eddyb for the suggestion! In the future the `HirId` should completely replace the `NodeId` in HIR nodes.
* Before something is read or stored in one of the various `TypeckTables` subtables, the entry's key is validated via the new `TypeckTables::validate_hir_id()` method. This makes sure that we are not mixing information from different items in a single table.
That last part could be made a bit nicer by either (a) new-typing the table-key and making `validate_hir_id()` the only way to convert a `HirId` to the new-typed key, or (b) just encapsulate sub-table access a little better. This PR, however, contents itself with not making things significantly worse.
Also, there's quite a bit of switching around between `NodeId`, `HirId`, and `DefIndex`. These conversions are cheap except for `HirId -> NodeId`, so if the valued reviewer finds such an instance in a performance critical place, please let me know.
Ideally we convert more and more code from `NodeId` to `HirId` in the future so that there are no more `NodeId`s after HIR lowering anywhere. Then the amount of switching should be minimal again.
r? @eddyb, maybe?
rustc: Rearchitect lints to be emitted more eagerly
In preparation for incremental compilation this commit refactors the lint
handling infrastructure in the compiler to be more "eager" and overall more
incremental-friendly. Many passes of the compiler can emit lints at various
points but before this commit all lints were buffered in a table to be emitted
at the very end of compilation. This commit changes these lints to be emitted
immediately during compilation using pre-calculated lint level-related data
structures.
Linting today is split into two phases, one set of "early" lints run on the
`syntax::ast` and a "late" set of lints run on the HIR. This commit moves the
"early" lints to running as late as possible in compilation, just before HIR
lowering. This notably means that we're catching resolve-related lints just
before HIR lowering. The early linting remains a pass very similar to how it was
before, maintaining context of the current lint level as it walks the tree.
Post-HIR, however, linting is structured as a method on the `TyCtxt` which
transitively executes a query to calculate lint levels. Each request to lint on
a `TyCtxt` will query the entire crate's 'lint level data structure' and then go
from there about whether the lint should be emitted or not.
The query depends on the entire HIR crate but should be very quick to calculate
(just a quick walk of the HIR) and the red-green system should notice that the
lint level data structure rarely changes, and should hopefully preserve
incrementality.
Overall this resulted in a pretty big change to the test suite now that lints
are emitted much earlier in compilation (on-demand vs only at the end). This in
turn necessitated the addition of many `#![allow(warnings)]` directives
throughout the compile-fail test suite and a number of updates to the UI test
suite.
Closes https://github.com/rust-lang/rust/issues/42511
In preparation for incremental compilation this commit refactors the lint
handling infrastructure in the compiler to be more "eager" and overall more
incremental-friendly. Many passes of the compiler can emit lints at various
points but before this commit all lints were buffered in a table to be emitted
at the very end of compilation. This commit changes these lints to be emitted
immediately during compilation using pre-calculated lint level-related data
structures.
Linting today is split into two phases, one set of "early" lints run on the
`syntax::ast` and a "late" set of lints run on the HIR. This commit moves the
"early" lints to running as late as possible in compilation, just before HIR
lowering. This notably means that we're catching resolve-related lints just
before HIR lowering. The early linting remains a pass very similar to how it was
before, maintaining context of the current lint level as it walks the tree.
Post-HIR, however, linting is structured as a method on the `TyCtxt` which
transitively executes a query to calculate lint levels. Each request to lint on
a `TyCtxt` will query the entire crate's 'lint level data structure' and then go
from there about whether the lint should be emitted or not.
The query depends on the entire HIR crate but should be very quick to calculate
(just a quick walk of the HIR) and the red-green system should notice that the
lint level data structure rarely changes, and should hopefully preserve
incrementality.
Overall this resulted in a pretty big change to the test suite now that lints
are emitted much earlier in compilation (on-demand vs only at the end). This in
turn necessitated the addition of many `#![allow(warnings)]` directives
throughout the compile-fail test suite and a number of updates to the UI test
suite.
{kind=link}