9453: Add first-class limits. r=matklad,lnicola a=rbartlensky
Partially fixes#9286.
This introduces a new `Limits` structure which is passed as an input
to `SourceDatabase`. This makes limits accessible almost everywhere in
the code, since most places have a database in scope.
One downside of this approach is that whenever you query limits, you
essentially do an `Arc::clone` which is less than ideal.
Let me know if I missed anything, or would like me to take a different approach!
Co-authored-by: Robert Bartlensky <bartlensky.robert@gmail.com>
9567: remove unneded special case r=matklad a=matklad
bors r+
🤖
9568: feat: add 'for' postfix completion r=lnicola a=mahdi-frms
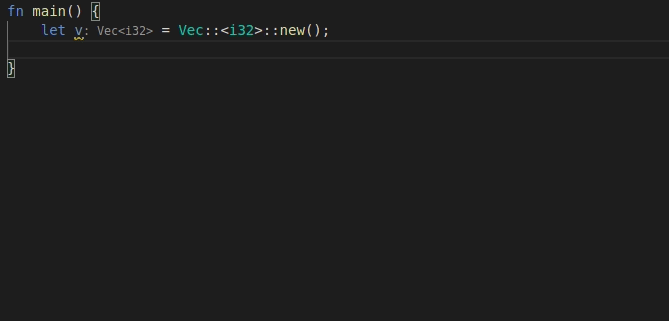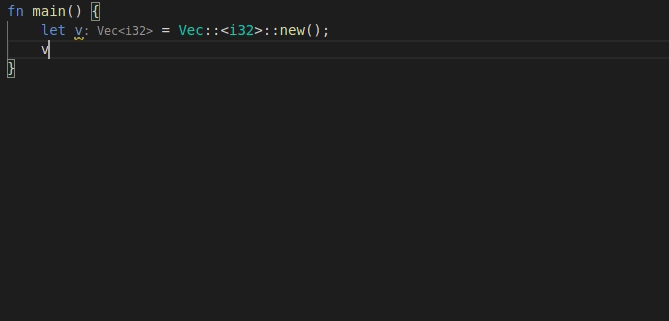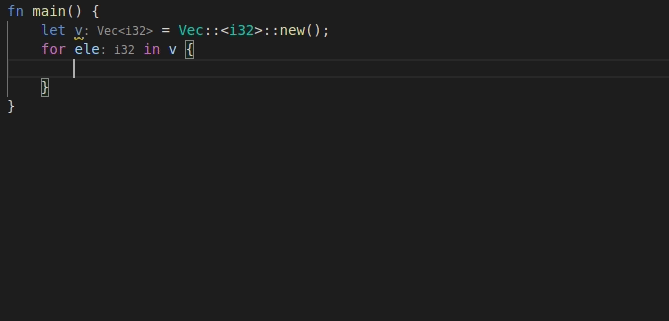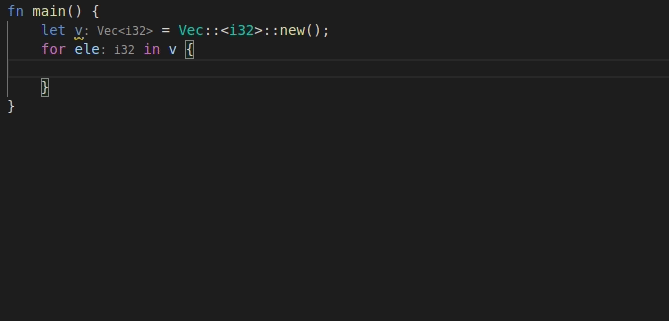
adds #9561
used ```ele``` as identifier for each element in the iteration
Co-authored-by: Aleksey Kladov <aleksey.kladov@gmail.com>
Co-authored-by: mahdi-frms <mahdif1380@outlook.com>
Note that, while we don't currently have a fuzzy-matching score, it
makes sense to special-case postfix templates -- it's very annoying when
`.not()` gets sorted before `.not`. We might want to move this infra to
fuzzy matching, once we have that!
Before this PR, SourceChange used a bool and CompletionItem used an enum
to signify if edit is a snippet. It makes sense to use the same pattern
in both cases. `bool` feels simpler, as there's only one consumer of
this API, and all producers are encapsulated anyway (we check the
capability at the production site).
* Keep codegen adjacent to the relevant crates.
* Remove codgen deps from xtask, speeding-up from-source installation.
This regresses the release process a bit, as it now needs to run the
tests (and, by extension, compile the code).
{kind=link}