internal: remove spurious regex dependency
- replace tokio's env-filter with a smaller&simpler targets filter
- reshuffle logging infra a bit to make sure there's only a single place where we read environmental variables
- use anyhow::Result in rust-analyzer binary
- replace tokio's env-filter with a smaller&simpler targets filter
- reshuffle logging infra a bit to make sure there's only a single place
where we read environmental variables
- use anyhow::Result in rust-analyzer binary
Lower const params with a bad id
cc #7434
This PR adds an `InTypeConstId` which is a `DefWithBodyId` and lower const generic parameters into bodies using it, and evaluate them with the mir interpreter. I think this is the last unimplemented const generic feature relative to rustc stable.
But there is a problem: The id used in the `InTypeConstId` is the raw `FileAstId`, which changes frequently. So these ids and their bodies will be invalidated very frequently, which is bad for incremental analysis.
Due this problem, I disabled lowering for local crates (in library crate the id is stable since files won't be changed). This might be overreacting (const generic expressions are usually small, maybe it would be better enabled with bad performance than disabled) but it makes motivation for doing it in the correct way, and it splits the potential panic and breakages that usually comes with const generic PRs in two steps.
Other than the id, I think (at least I hope) other parts are in the right direction.
Properly format documentation for `SignatureHelpRequest`s
Properly formats function documentation instead of returning it raw when responding to `SignatureHelpRequest`s.
I added a test in `crates/rust-analyzer/tests/slow-tests/main.rs` -- not sure if this is the best location given the relevant code is in `crates/rust-analyzer` or if it's possible to test in a less heavyweight manner.
Closes#14958
Add span to group.
This appears to fix#14959, but I've never contributed to rust-analyzer before and there were some things that confused me:
- I had to add the `fn byte_range` method to get it to build. This was added to rust in [April](https://github.com/rust-lang/rust/pull/109002), so I don't understand why it wasn't needed until now
- When testing, I ran into the fact that rust recently updated its `METADATA_VERSION`, so I had to test this with nightly-2023-05-20. But then I noticed that rust has its own copy of `rust-analyzer`, and the metadata version bump has already been [handled there](60e95e76d0). So I guess I don't really understand the relationship between the code there and the code here.
Prioritize threads affected by user typing
To this end I’ve introduced a new custom thread pool type which can spawn threads using each QoS class. This way we can run latency-sensitive requests under one QoS class and everything else under another QoS class. The implementation is very similar to that of the `threadpool` crate (which is currently used by rust-analyzer) but with unused functionality stripped out.
I’ll have to rebase on master once #14859 is merged but I think everything else is alright :D
This code replaces the thread pool implementation we were using
previously (from the `threadpool` crate). By making the thread pool
aware of QoS, each job spawned on the thread pool can have a different
QoS class.
This commit also replaces every QoS class used previously with Default
as a temporary measure so that each usage can be chosen deliberately.
Specify thread types using Quality of Service API
<details>
<summary>Some background (in case you haven’t heard of QoS before)</summary>
Heterogenous multi-core CPUs are increasingly found in laptops and desktops (e.g. Alder Lake, Snapdragon 8cx Gen 3, M1). To maximize efficiency on this kind of hardware, it is important to provide the operating system with more information so threads can be scheduled on different core types appropriately.
The approach that XNU (the kernel of macOS, iOS, etc) and Windows have taken is to provide a high-level semantic API – quality of service, or QoS – which informs the OS of the program’s intent. For instance, you might specify that a thread is running a render loop for a game. This makes the OS provide this thread with as large a share of the system’s resources as possible. Specifying a thread is running an unimportant background task, on the other hand, is cause for it to be scheduled exclusively on high-efficiency cores instead of high-performance cores.
QoS APIs allows for easy configuration of many different parameters at once; for instance, setting QoS on XNU affects scheduling, timer latency, I/O priorities, and of course what core type the thread in question should run on. I don’t know any details on how QoS works on Windows, but I would guess it’s similar.
Hypothetically, taking advantage of these APIs would improve power consumption, thermals, battery life if applicable, etc.
</details>
# Relevance to rust-analyzer
From what I can tell the philosophy behind both the XNU and Windows QoS APIs is that _user interfaces should never stutter under any circumstances._ You can see this in the array of QoS classes which are available: the highest QoS class in both APIs is one intended explicitly for UI render loops.
Imagine rust-analyzer is performing CPU-intensive background work – maybe you just invoked Find Usages on `usize` or opened a large project – in this scenario the editor’s render loop should absolutely get higher priority than rust-analyzer, no matter what. You could view it in terms of “realtime-ness”: flight control software is hard realtime, audio software is soft realtime, GUIs are softer realtime, and rust-analyzer is not realtime at all. Of course, maximizing responsiveness is important, but respecting the rest of the system is more important.
# Implementation
I’ve tried my best to unify thread creation in `stdx`, where the new API I’ve introduced _requires_ specifying a QoS class. Different points along the performance/efficiency curve can make a great difference; the M1’s e-cores use around three times less power than the p-cores, so putting in this effort is worthwhile IMO.
It’s worth mentioning that Linux does not [yet](https://youtu.be/RfgPWpTwTQo) have a QoS API. Maybe translating QoS into regular thread priorities would be acceptable? From what I can tell the only scheduling-related code in rust-analyzer is Windows-specific, so ignoring QoS entirely on Linux shouldn’t cause any new issues. Also, I haven’t implemented support for the Windows QoS APIs because I don’t have a Windows machine to test on, and because I’m completely unfamiliar with Windows APIs :)
I noticed that rust-analyzer handles some requests on the main thread (using `.on_sync()`) and others on a threadpool (using `.on()`). I think it would make sense to run the main thread at the User Initiated QoS and the threadpool at Utility, but only if all requests that are caused by typing use `.on_sync()` and all that don’t use `.on()`. I don’t understand how the `.on_sync()`/`.on()` split that’s currently present was chosen, so I’ve let this code be for the moment. Let me know if changing this to what I proposed makes any sense.
To avoid having to change everything back in case I’ve misunderstood something, I’ve left all threads at the Utility QoS for now. Of course, this isn’t what I hope the code will look like in the end, but I figured I have to start somewhere :P
# References
<ul>
<li><a href="https://developer.apple.com/library/archive/documentation/Performance/Conceptual/power_efficiency_guidelines_osx/PrioritizeWorkAtTheTaskLevel.html">Apple documentation related to QoS</a></li>
<li><a href="67e155c940/include/pthread/qos.h">pthread API for setting QoS on XNU</a></li>
<li><a href="https://learn.microsoft.com/en-us/windows/win32/procthread/quality-of-service">Windows’s QoS classes</a></li>
<li>
<details>
<summary>Full documentation of XNU QoS classes. This documentation is only available as a huge not-very-readable comment in a header file, so I’ve reformatted it and put it here for reference.</summary>
<ul>
<li><p><strong><code>QOS_CLASS_USER_INTERACTIVE</code>: A QOS class which indicates work performed by this thread is interactive with the user.</strong></p><p>Such work is requested to run at high priority relative to other work on the system. Specifying this QOS class is a request to run with nearly all available system CPU and I/O bandwidth even under contention. This is not an energy-efficient QOS class to use for large tasks. The use of this QOS class should be limited to critical interaction with the user such as handling events on the main event loop, view drawing, animation, etc.</p></li>
<li><p><strong><code>QOS_CLASS_USER_INITIATED</code>: A QOS class which indicates work performed by this thread was initiated by the user and that the user is likely waiting for the results.</strong></p><p>Such work is requested to run at a priority below critical user-interactive work, but relatively higher than other work on the system. This is not an energy-efficient QOS class to use for large tasks. Its use should be limited to operations of short enough duration that the user is unlikely to switch tasks while waiting for the results. Typical user-initiated work will have progress indicated by the display of placeholder content or modal user interface.</p></li>
<li><p><strong><code>QOS_CLASS_DEFAULT</code>: A default QOS class used by the system in cases where more specific QOS class information is not available.</strong></p><p>Such work is requested to run at a priority below critical user-interactive and user-initiated work, but relatively higher than utility and background tasks. Threads created by <code>pthread_create()</code> without an attribute specifying a QOS class will default to <code>QOS_CLASS_DEFAULT</code>. This QOS class value is not intended to be used as a work classification, it should only be set when propagating or restoring QOS class values provided by the system.</p></li>
<li><p><strong><code>QOS_CLASS_UTILITY</code>: A QOS class which indicates work performed by this thread may or may not be initiated by the user and that the user is unlikely to be immediately waiting for the results.</strong></p><p>Such work is requested to run at a priority below critical user-interactive and user-initiated work, but relatively higher than low-level system maintenance tasks. The use of this QOS class indicates the work should be run in an energy and thermally-efficient manner. The progress of utility work may or may not be indicated to the user, but the effect of such work is user-visible.</p></li>
<li><p><strong><code>QOS_CLASS_BACKGROUND</code>: A QOS class which indicates work performed by this thread was not initiated by the user and that the user may be unaware of the results.</strong></p><p>Such work is requested to run at a priority below other work. The use of this QOS class indicates the work should be run in the most energy and thermally-efficient manner.</p></li>
<li><p><strong><code>QOS_CLASS_UNSPECIFIED</code>: A QOS class value which indicates the absence or removal of QOS class information.</strong></p><p>As an API return value, may indicate that threads or pthread attributes were configured with legacy API incompatible or in conflict with the QOS class system.</p></li>
</ul>
</details>
</li>
</ul>
feat: Highlight closure captures when cursor is on pipe or move keyword
This runs into the same issue on vscode as exit points for `->`, where highlights are only triggered on identifiers, https://github.com/rust-lang/rust-analyzer/issues/9395
Though putting the cursor on `move` should at least work.
internal: Warn when loading sysroot fails to find the core library
Should help a bit more with user experience, before we only logged this now we show it in the status
Closes https://github.com/rust-lang/rust-analyzer/issues/11606
Drop support for non-syroot proc macro ABIs
This makes some bigger changes to how we handle the proc-macro-srv things, for one it is now an empty crate if built without the `sysroot-abi` feature, this simplifies some things dropping the need to put the feature cfg in various places. The cli wrapper now actually depends on the server, instead of being part of the server that is just exported, that way we can have a true dummy server that just errors on each request if no sysroot support was specified.
internal: Add config to specifiy lru capacities for all queries
Might help figuring out what queries should be limited by LRU by default, as currently we only limit `parse`, `parse_macro_expansion` and `macro_expand`.
fix: allow new, subsequent `rust-project.json`-based workspaces to get proc macro expansion
As detailed in https://github.com/rust-lang/rust-analyzer/issues/14417#issuecomment-1485336174, `rust-project.json` workspaces added after the initial `rust-project.json`-based workspace was already indexed by rust-analyzer would not receive procedural macro expansion despite `config.expand_proc_macros` returning true. To fix this issue:
1. I changed `reload.rs` to check which workspaces are newly added.
2. Spawned new procedural macro expansion servers based on the _new_ workspaces.
1. This is to prevent spawning duplicate procedural macro expansion servers for already existing workspaces. While the overall memory usage of duplicate procedural macro servers is minimal, this is more about the _principle_ of not leaking processes 😅.
3. Launched procedural macro expansion if any workspaces are `rust-project.json`-based _or_ `same_workspaces` is true. `same_workspaces` being true (and reachable) indicates that that build scripts have finished building (in Cargo-based projects), while the build scripts in `rust-project.json`-based projects have _already been built_ by the build system that produced the `rust-project.json`.
I couldn't really think of structuring this code in a better way without engaging with https://github.com/rust-lang/rust-analyzer/issues/7444.
Remove client side proc-macro version check
The server already verifies versions due to ABI picking now so there shouldn't be a need for the client side check anymore
fix: Do not retry inlay hint requests
Should close https://github.com/rust-lang/rust-analyzer/issues/13372, retrying the way its currently implemented is not ideal as we do not adjust offsets in the requests, but doing that is a major PITA, so this should at least work around one of the more annoying issues stemming from it.
Add Cargo-style project discovery for Buck and Bazel Users
This feature requires the user to add a command that generates a `rust-project.json` from a set of files. Project discovery can be invoked in two ways:
1. At extension activation time, which includes the generated `rust-project.json` as part of the linkedProjects argument in `InitializeParams`.
2. Through a new command titled "rust-analyzer: Add current file to workspace", which makes use of a new, rust-analyzer-specific LSP request that adds the workspace without erasing any existing workspaces. Note that there is no mechanism to _remove_ workspaces other than "quit the rust-analyzer server".
Few notes:
- I think that the command-running functionality _could_ merit being placed into its own extension (and expose it via extension contribution points) to provide build-system idiomatic progress reporting and status handling, but I haven't (yet) made an extension that does this nor does Buck expose this sort of functionality.
- This approach would _just work_ for Bazel. I'll try and get the tool that's responsible for Buck integration open-sourced soon.
- On the testing side of things, I've used this in around my employer's Buck-powered monorepo and it's a nice experience. That being said, I can't think of an open-source repository where this can be tested in public, so you might need to trust me on this one.
I'd love to get feedback on:
- Naming of LSP extensions/new commands. I'm not too pleased with how "rust-analyzer: Add current file to workspace" is named, in that it's creating a _new_ workspace. I think that this command being added should be gated on `rust-analyzer.discoverProjectCommand` on being set, so I can add this in sequent commits.
- My Typescript. It's not particularly good.
- Suggestions on handling folders with _both_ Cargo and non-Cargo build systems and if I make activation a bit better.
(I previously tried to add this functionality entirely within rust-analyzer-the-LSP server itself, but matklad was right—an extension side approach is much, much easier.)
This feature requires the user to add a command that generates a
`rust-project.json` from a set of files. Project discovery can be invoked
in two ways:
1. At extension activation time, which includes the generated
`rust-project.json` as part of the linkedProjects argument in
InitializeParams
2. Through a new command titled "Add current file to workspace", which
makes use of a new, rust-analyzer specific LSP request that adds
the workspace without erasing any existing workspaces.
I think that the command-running functionality _could_ merit being
placed into its own extension (and expose it via extension contribution
points), if only provide build-system idiomatic progress reporting and
status handling, but I haven't (yet) made an extension that does this.
Handle trait alias definitions
Part of #2773
This PR adds a bunch of structs and enum variants for trait aliases. Trait aliases should be handled as an independent item because they are semantically distinct from traits.
I basically started by adding `TraitAlias{Id, Loc}` to `hir_def::item_tree` and iterated adding necessary stuffs until compiler stopped complaining what's missing. Let me know if there's still anything I need to add.
I'm opening up this PR for early review and stuff. I'm planning to add tests for IDE functionalities in this PR, but not type-related support, for which I put FIXME notes.
Beginning of MIR
This pull request introduces the initial implementation of MIR lowering and interpreting in Rust Analyzer.
The implementation of MIR has potential to bring several benefits:
- Executing a unit test without compiling it: This is my main goal. It can be useful for quickly testing code changes and print-debugging unit tests without the need for a full compilation (ideally in almost zero time, similar to languages like python and js). There is a probability that it goes nowhere, it might become slower than rustc, or it might need some unreasonable amount of memory, or we may fail to support a common pattern/function that make it unusable for most of the codes.
- Constant evaluation: MIR allows for easier and more correct constant evaluation, on par with rustc. If r-a wants to fully support the type system, it needs full const eval, which means arbitrary code execution, which needs MIR or something similar.
- Supporting more diagnostics: MIR can be used to detect errors, most famously borrow checker and lifetime errors, but also mutability errors and uninitialized variables, which can be difficult/impossible to detect in HIR.
- Lowering closures: With MIR we can find out closure capture modes, which is useful in detecting if a closure implements the `FnMut` or `Fn` traits, and calculating its size and data layout.
But the current PR implements no diagnostics and doesn't support closures. About const eval, I removed the old const eval code and it now uses the mir interpreter. Everything that is supported in stable rustc is either implemented or is super easy to implement. About interpreting unit tests, I added an experimental config, disabled by default, that shows a `pass` or `fail` on hover of unit tests (ideally it should be a button similar to `Run test` button, but I didn't figured out how to add them). Currently, no real world test works, due to missing features including closures, heap allocation, `dyn Trait` and ... so at this point it is only useful for me selecting what to implement next.
The implementation of MIR is based on the design of rustc, the data structures are almost copy paste (so it should be easy to migrate it to a possible future stable-mir), but the lowering and interpreting code is from me.
Rename `checkOnSave` settings to `check`
Now that flychecks can be triggered without saving the setting name doesn't make that much sense anymore. This PR renames it to just `check`, but keeps `checkOnSave` as the enabling setting.
feat: add the ability to limit the number of threads launched by `main_loop`
## Motivation
`main_loop` defaults to launch as many threads as cpus in one machine. When developing on multi-core remote servers on multiple projects, this will lead to thousands of idle threads being created. This is very annoying when one wants check whether his program under developing is running correctly via `htop`.
<img width="756" alt="image" src="https://user-images.githubusercontent.com/41831480/206656419-fa3f0dd2-e554-4f36-be1b-29d54739930c.png">
## Contribution
This patch introduce the configuration option `rust-analyzer.numThreads` to set the desired thread number used by the main thread pool.
This should have no effects on the performance as not all threads are actually used.
<img width="1325" alt="image" src="https://user-images.githubusercontent.com/41831480/206656834-fe625c4c-b993-4771-8a82-7427c297fd41.png">
## Demonstration
The following is a snippet of `lunarvim` configuration using my own build.
```lua
vim.list_extend(lvim.lsp.automatic_configuration.skipped_servers, { "rust_analyzer" })
require("lvim.lsp.manager").setup("rust_analyzer", {
cmd = { "env", "RA_LOG=debug", "RA_LOG_FILE=/tmp/ra-test.log",
"/home/jlhu/Projects/rust-analyzer/target/debug/rust-analyzer",
},
init_options = {
numThreads = 4,
},
settings = {
cachePriming = {
numThreads = 8,
},
},
})
```
## Limitations
The `numThreads` can only be modified via `initializationOptions` in early initialisation because everything has to wait until the thread pool starts including the dynamic settings modification support.
The `numThreads` also does not reflect the end results of how many threads is actually created, because I have not yet tracked down everything that spawns threads.
fix a bunch of clippy lints
fixes a bunch of clippy lints for fun and profit
i'm aware of this repo's position on clippy. The changes are split into separate commits so they can be reviewed separately
feat: Package Windows release artifacts as ZIP and add symbols file
Closes#13872Closes#7747
CC #10371
This allows us to ship a format that's easier to handle on Windows. As a bonus, we can also include the PDB, to get useful stack traces. Unfortunately, it adds a couple of dependencies to `xtask`, increasing the debug build times from 1.28 to 1.58 s (release from 1.60s to 2.20s) on my system.
This makes code more readale and concise,
moving all format arguments like `format!("{}", foo)`
into the more compact `format!("{foo}")` form.
The change was automatically created with, so there are far less change
of an accidental typo.
```
cargo clippy --fix -- -A clippy::all -W clippy::uninlined_format_args
```
Seems like these can be safely fixed. With one, I was particularly
surprised -- `Some(pats) => &**pats,` in body.rs?
```
cargo clippy --fix -- -A clippy::all -D clippy::explicit_auto_deref
```
I am not certain if this will improve performance,
but it seems having a .clone() without any need should be removed.
This was done with clippy, and manually reviewed:
```
cargo clippy --fix -- -A clippy::all -D clippy::redundant_clone
```
feat: Add an option to hide adjustment hints outside of `unsafe` blocks and functions
As the title suggests: this PR adds an option (namely `rust-analyzer.inlayHints.expressionAdjustmentHints.hideOutsideUnsafe`) that allows to hide adjustment hints outside of `unsafe` blocks and functions:
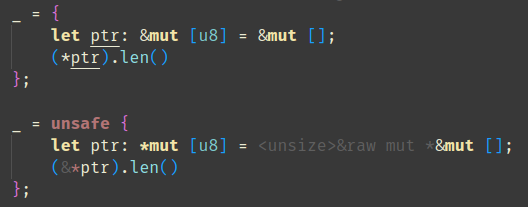
Requested by `@BoxyUwU` <3
Don't show runnable code lenses in libraries outside of the workspace
Addresses #13664. For now I'm just disabling runnable code lenses since the ones that display the number of references and implementations do work correctly with external code.
Also made a tiny TypeScript change to use the typed `sendNotification` overload.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}